







 超级会员免费看
超级会员免费看
 LiBai是OneFlow团队研发的模型库,旨在简化大模型的分布式训练,提供与PyTorch一致的API,并在性能上超越Megatron-LM和DeepSpeed。其特点包括自动分布式训练、兼容Hugging Face、模块化设计和高效性能。LiBai的易用性使其成为大模型训练的优选,降低了分布式训练的门槛。
LiBai是OneFlow团队研发的模型库,旨在简化大模型的分布式训练,提供与PyTorch一致的API,并在性能上超越Megatron-LM和DeepSpeed。其特点包括自动分布式训练、兼容Hugging Face、模块化设计和高效性能。LiBai的易用性使其成为大模型训练的优选,降低了分布式训练的门槛。
LiBai(李白)模型库覆盖了 Hugging Face、Megatron-LM、DeepSpeed、FairSeq 这些所有主流 Transformer 库的优点,让大模型训练飞入寻常百姓家。
大模型多了去了,告诉我怎么加速?自 2018 年 BERT 诞生,到 GPT-3、ViT 等拥有数以亿计的参数规模的模型不断涌现,AI 模型参数量的爆发式增长已不足为奇,让炼丹师无暇顾及甚至感到麻木。
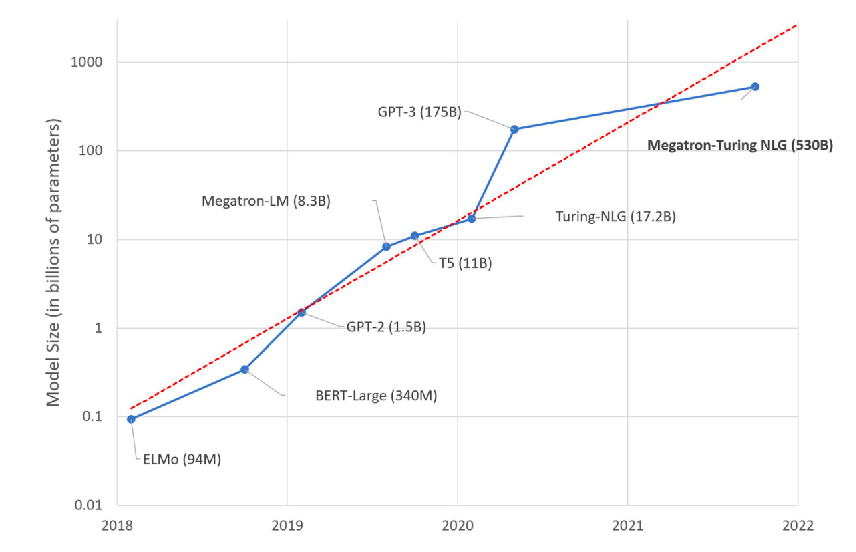
与此同时,大模型对计算和内存资源提出了巨大的挑战。训练成本急剧上升,比如用一块非常先进的 NVIDIA A100 GPU 训练千亿参数模型的 GPT-3,需要用时 100 多年。
大模型对显存的需求增长远超过 GPU 显存增长的速度,根据 OpenAI 的报告,模型大小的增长速度是每 3.5 月翻一倍,而 GPU 显存则需要 18 个月才能翻倍。受限于 GPU 显存,单个 GPU 无法再容纳大规模模型参数。
因此,业内不得不将计算扩展到多个 GPU 设备上,分布式训

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









