






执行摘要
生成性人工智能革命已经到来。随着各个领域对生成性人工智能用例的需求不断增长,这些用例具有不同的需求和计算负载,显然需要一种针对人工智能重新设计的计算架构。这种架构以从头开始为生成性人工智能设计的神经处理单元(NPU)为基础,同时利用中央处理单元(CPU)和图形处理单元(GPU)等异构处理器的组合。通过与 NPU 一起使用合适的处理器,异构计算最大化了应用程序性能、热效率和电池寿命,从而实现了新的和增强的生成性人工智能体验。
NPU 是从零开始构建的,旨在以低功耗加速人工智能推理,并随着新的人工智能用例、模型和需求的发展而不断演变。出色的 NPU 设计做出了正确的设计选择,并与人工智能行业的发展方向紧密对齐。
高通正在推动智能计算的普及。我们业界领先的 高通 Hexagon™ NPU 旨在以低功耗实现持续的高性能人工智能推理。我们 NPU 的独特之处在于我们的系统方法、定制设计和快速创新。通过定制设计 NPU 并控制指令集架构(ISA),我们可以快速演变和扩展设计,以解决瓶颈和优化性能。Hexagon NPU 是我们一流的异构计算架构 高通 AI Engine 中的一个关键处理器,该架构还包括 高通 Adreno™ GPU、高通 Kryo™ 或高通 Oryon™ CPU、高通 Sensing Hub 和内存子系统。这些处理器经过精心设计,可以协同工作,并在设备上快速高效地运行人工智能应用。我们在人工智能基准测试和真实的生成性人工智能应用中的行业领先表现证明了这一点。
我们还通过关注在全球数十亿设备上开发和部署的便捷性来帮助开发者,这些设备由 Qualcomm® 和 Snapdragon® 平台提供支持。使用 高通 AI Stack,开发者可以在我们的硬件上创建、优化和部署他们的人工智能应用,实现一次编写、跨不同产品和领域使用我们芯片解决方案进行部署。高通技术正在大规模实现设备上的生成性人工智能。
将处理器集成到 SoC 中带来的诸多好处
计算架构随着时间的推移而不断演变,这一过程受到用户需求增长、新应用和设备类别以及技术进步的推动。最初,中央处理单元(CPU)能够完成大部分处理任务,但随着计算需求的增加,对新处理器和加速器的需求应运而生。例如,早期智能手机系统由围绕 CPU 的分立芯片组成,用于 2D 图形、音频、图像信号处理、蜂窝调制解调器、GPS 等。随着时间的推移,这些芯片的功能已被集成到称为系统单芯片(SoC)的单一芯片中。
以现代智能手机、个人电脑和汽车 SoC 为例,它们集成了各种处理器——如 CPU、图形处理单元(GPU)和神经处理单元(NPU)。这种芯片设计的集成带来了许多好处,包括峰值性能、功率效率、每面积性能、芯片尺寸和成本的改善。
例如,在智能手机或笔记本电脑中,拥有一个独立的 GPU 或 NPU 将占用更多的板面空间并消耗更多的能量,影响工业设计和电池尺寸。这还会导致输入/输出引脚之间的数据传输增加,从而降低性能、增加额外的能耗,并由于更大的电路板和较少的共享内存效率而增加成本。集成对于需要在严格的功率和热约束条件下实现精致工业设计的智能手机、笔记本电脑和其他便携设备尤为必要。
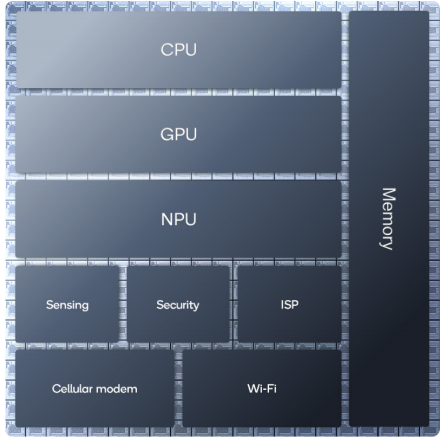
生成性人工智能需要多样化的处理器
在人工智能领域,集成专用处理器并不是新鲜事。智能手机的系统单芯片(SoCs)已经使用神经处理单元(NPUs)多个世代,以在后台提升日常体验——从卓越的摄影和音频到增强的连接性和安全性。不同的是,生成性人工智能应用场景的需求正在增长,这些场景在各个行业有着多样化的要求和计算需求。这些应用场景可以分为三类:
-
按需应用场景:由用户触发,需要立即响应,包括照片/视频捕获、图像生成/编辑、代码生成、音频录音转录/摘要以及文本(电子邮件、文档等)创建/摘要。这包括在手机上发短信时创建自定义图像、在电脑上生成会议摘要或在开车时用语音查找最近的加油站。
-
持续应用场景:运行时间较长,包括语音识别、游戏和视频超分辨率、视频通话音频/视频处理以及实时翻译。这包括在出国商务旅行时将手机用作实时对话翻译器,以及在 PC 上游戏时对每一帧进行超分辨率处理。
-
普遍应用场景:持续在后台运行,包括始终在线的预测性 AI 助手、基于上下文感知的 AI 个性化以及高级文本自动补全。这包括手机根据您的对话建议与同事开会,或您的电脑辅导助手根据您对问题的回答调整学习材料。
这些 AI 应用场景有两个共同的主要挑战。首先,它们对计算的需求多样且高,使用通用 CPU 或 GPU 的设备在功耗和热限制下难以满足这些需求,这些通用处理器需要同时满足多个平台上的需求。其次,它们不断发展,因此仅在固定功能硬件中实现它们可能不切实际。因此,具有处理多样性的异构计算架构使得可以利用每个处理器的优势,即以 AI 为中心的定制设计 NPU,以及 CPU 和 GPU。例如,每种处理器在不同的任务上表现出色:CPU 适用于顺序控制和即时性,GPU 适合流式并行数据,而 NPU 则专注于核心 AI 工作负载,处理标量、向量和张量数学运算。
CPU 和 GPU 是通用处理器。它们的设计注重灵活性,非常可编程,并且有“日常工作”,运行操作系统、游戏和其他应用,这限制了它们在任何时刻可用于 AI 工作负载的能力。NPU 则是专门为 AI 设计的——AI 是它的日常工作。它在编程便利性和高性能、能效、面积效率之间做出了一些权衡,以便处理机器学习所需的大量乘法、加法和其他运算。
通过使用适当的处理器,异构计算最大化应用性能、热效率和电池寿命,以支持新的和增强的生成性 AI 体验。
NPU 简介
NPU 是专门为低功耗加速 AI 推理而从零开始构建的,它随着新 AI 应用场景、模型和需求的发展而演变。NPU 的设计受整个 SoC 系统设计、内存访问模式和其他处理器架构在运行 AI 工作负载时的瓶颈分析的强烈影响。这些 AI 工作负载主要由计算神经网络层组成,包含标量、向量和张量数学运算,随后进行非线性激活函数。
2015 年早期的 NPU 设计用于基于简单卷积神经网络(CNN)的音频和语音 AI 应用场景,主要需要标量和向量数学。从 2016 年开始,摄影和视频 AI 应用场景日益流行,出现了新的更复杂的模型,如变换器、递归神经网络(RNN)、长短期记忆(LSTM)和更高维度的 CNN。这些工作负载需要大量的张量数学,因此 NPU 增加了张量加速器和卷积加速,以便实现更高效的处理。拥有大型共享内存配置和专用硬件进行张量乘法,不仅显著提高性能,还减少了内存带宽和能耗。例如,一个 NxN 矩阵与另一个 NxN 矩阵相乘,将读取 2N² 个值并执行 2N³ 次运算(单独的乘法和加法)。对于张量加速器而言,计算操作与内存访问的比率为 N:1,而对于标量和向量加速器则要小得多。
在 2023 年,由大型语言模型(LLMs)支持的生成性 AI,如 Meta 的 Llama 2-7B,以及大型视觉模型(LVMs),如 Stable Diffusion,显著增加了典型模型的大小,超过了一个数量级。在计算需求之外,这还需要显著的内存和系统设计考虑,以减少内存数据传输,提高性能和能效。未来,预计对更大模型和多模态模型的需求将继续增加。
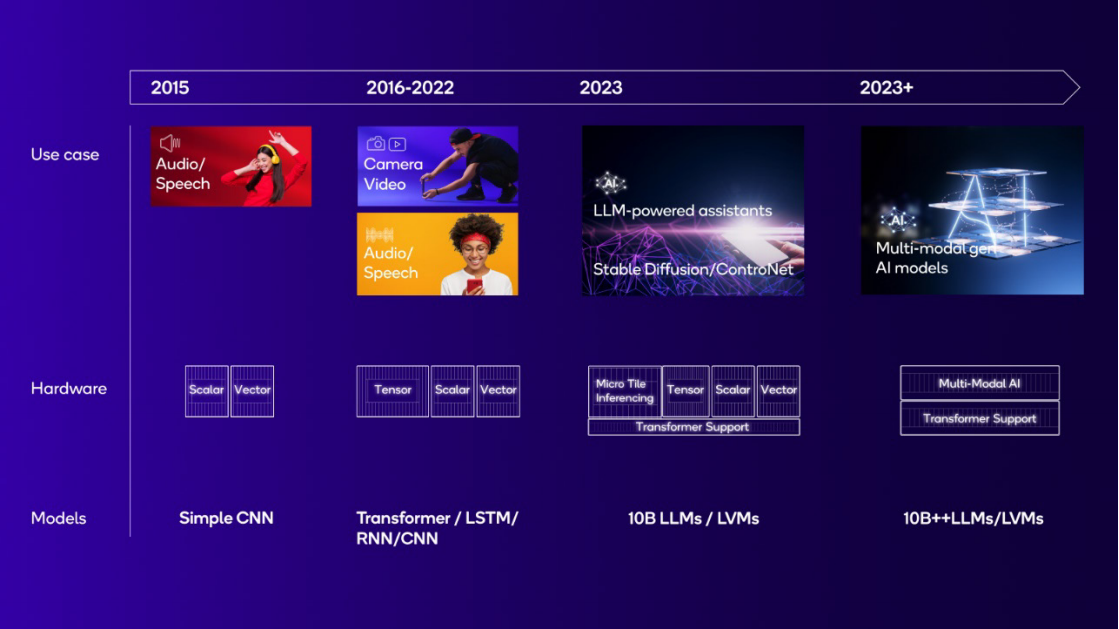
随着 AI 的快速发展,性能、功耗、效率、可编程性和面积之间的许多权衡必须得到平衡。专用的定制设计 NPU 做出了正确的选择,并与 AI 行业的发展方向紧密对齐。

















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









