







 超级会员免费看
超级会员免费看
请使用c++写一个bert模型结构?
有没有感觉自己要失业了?
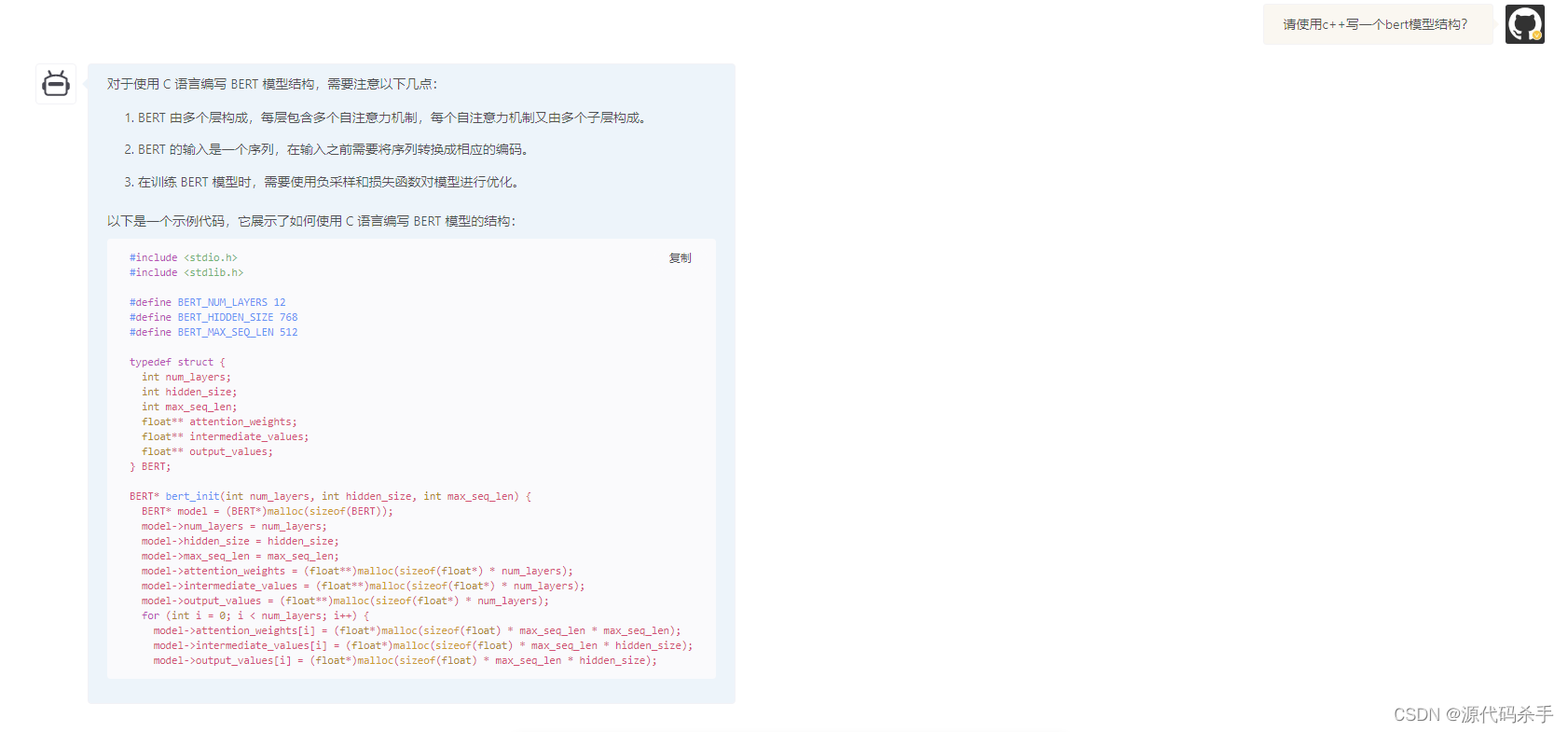
对于使用 C 语言编写 BERT 模型结构,需要注意以下几点:
BERT 由多个层构成,每层包含多个自注意力机制,每个自注意力机制又由多个子层构成。
BERT 的输入是一个序列,在输入之前需要将序列转换成相应的编码。
在训练 BERT 模型时,需要使用负采样和损失函数对模型进行优化。
以下是一个示例代码,它展示了如何使用 C 语言编写 BERT 模型的结构:
#include <stdio.h>
#include <stdlib.h>
#define<
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1962
1962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











