







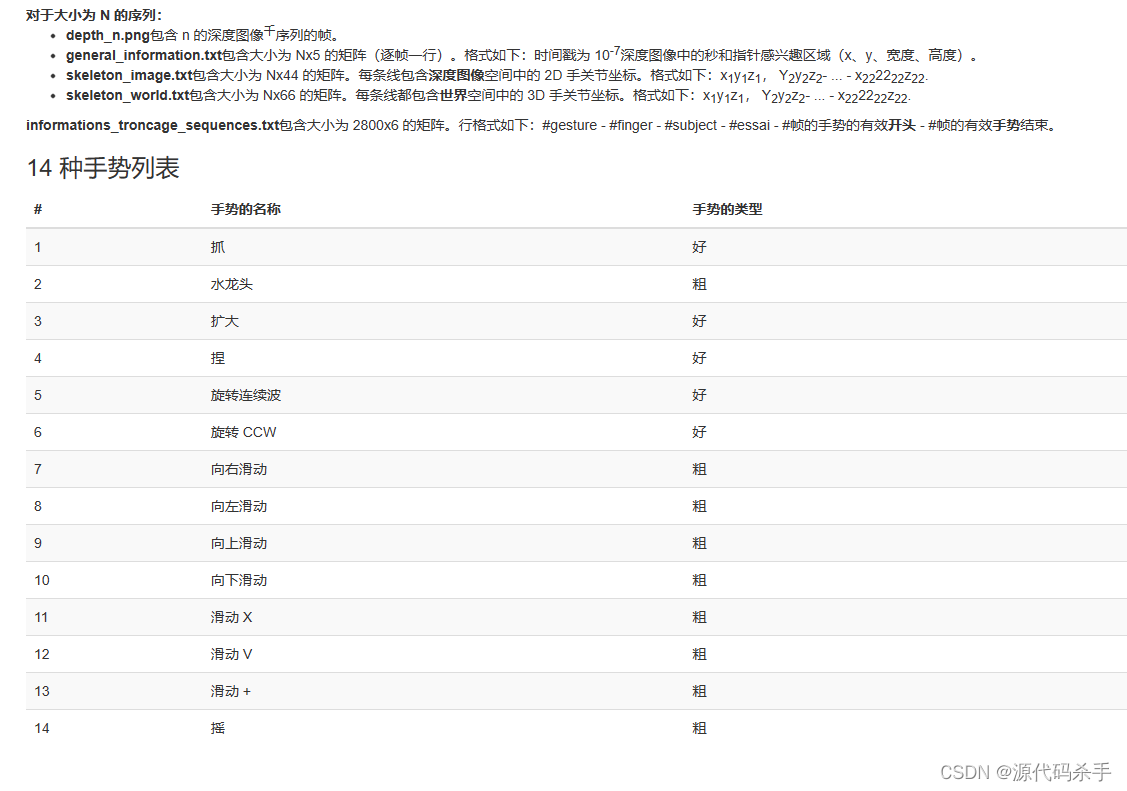
动态手势 14/28 数据集包含以两种方式执行的 14 个手势序列:使用一根手指和整只手。 每个手势由 5 名参与者以 20 种方式执行 2 次 - 如上所述 - 产生 2800 个序列。所有参与者都是右撇子。 序列根据其手势、使用的手指数量、表演者和试验进行标记。序列的每一帧都包含一个深度图像,即22D深度图像空间和2D世界空间中3个关节的坐标,形成一个完整的手骨架。 英特尔实感短距离深度摄像头用于收集我们的数据集。深度图像和手骨架以每秒30帧的速度捕获,深度图像的分辨率为640x480。示例手势的长度范围为 20 到 50 帧。

下载数据集:http://www-rech.telecom-lille.fr/DHGdataset/#gestures



















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











