







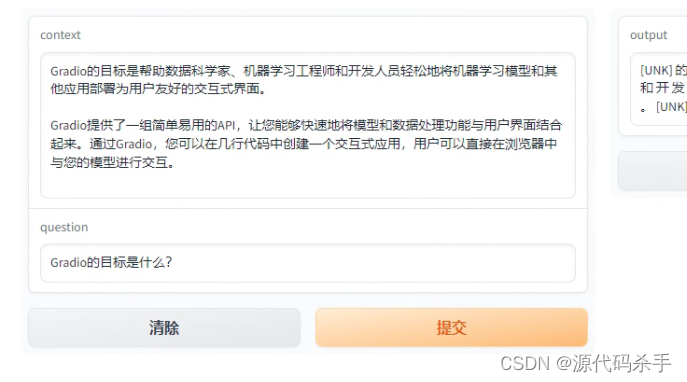
使用Gradio实现Question Answering交互式问答界面,首先你需要有一个已经训练好的Question Answering模型,这里你提到要使用bert-base-chinese模型。
Gradio支持PyTorch和TensorFlow模型,所以你需要将bert-base-chinese模型转换成PyTorch或TensorFlow格式,以便在Gradio中使用。
在这里,我将演示如何使用Hugging Face Transformers库(PyTorch版本)加载bert-base-chinese模型,并使用Gradio创建交互式问答界面。
确保已经安装了必要的库:
pip install gradio torch transformers
然后,可以使用以下代码实现交互式问答界面:
import gradio as gr
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
# 加载bert-base-chinese模型和分词器
model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForQuestionAnswering.from_pretrained(model_name)
def question_answering(context, question):
# 使用分词器对输入进行处理
inputs = tokenizer(question, context, return_tensors="pt")
# 调用模型进行问答
outputs = model(**inputs)
# 获取答案的起始和结束位置
start_scores = outputs.start_logits
end_scores = outputs.end_logits
# 获取最佳答案
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores) + 1
answer = tokenizer.decode(inputs["input_ids"][0][answer_start:answer_end])
return answer
# 创建Gradio界面
interface = gr.Interface(
fn=question_answering,
inputs=["text", "text"], # 输入分别为context和question
outputs="text", # 输出为答案
)
interface.launch()
运行以上代码后,Gradio将启动一个本地的交互式界面,你可以在界面的左侧输入文本,分别填入context和question,然后点击"Answer"按钮,右侧会显示模型的答案输出。请确保输入的context包含问题的相关信息,而question是你要问的问题。
终端输出:
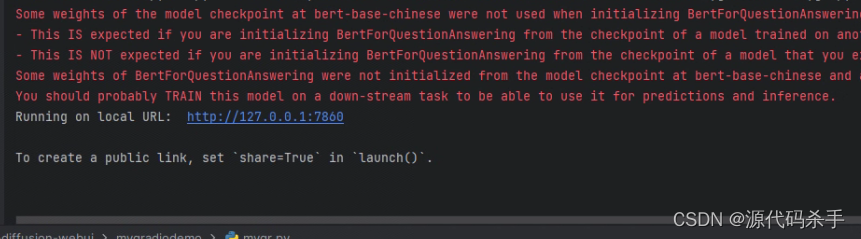
访问链接http://127.0.0.1:7860/,这样就可以在Gradio中实现一个基于bert-base-chinese模型的Question Answering交互式问答界面。

















 6537
6537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











