









基本信息
来源:IEEE TRANSACTIONS ON ROBOTICS, VOL. 41, 2025
学校:University of Hong Kong
摘要:本文介绍了 FAST-LIVO2,这是一种快速直接的 LiDAR 惯性视觉里程计框架,旨在在 SLAM 任务中进行准确和稳健的状态估计,从而实现实时机器人应用。FAST-LIVO2 通过高效的误差状态迭代卡尔曼滤波器 (ESIKF) 集成 IMU、LiDAR 和图像数据。为了解决 LiDAR 和图像测量之间的尺寸不匹配问题,我们采用了顺序更新策略。使用直接方法进行 LiDAR 和视觉数据融合,效率进一步提高:LiDAR 模块无需提取特征即可记录原始点,而视觉模块无需依赖特征提取即可最大限度地减少光度误差。LiDAR 和视觉测量都融合到一个统一的体素图中。LiDAR 模块构建几何结构,而视觉模块将图像块链接到 LiDAR 点,实现精确的图像对齐。来自 LiDAR 点的平面先验提高了对准精度,并在此过程中进行了动态优化。此外,按需光线投射作和实时图像曝光估计增强了稳健性。对基准和自定义数据集的广泛实验表明,FAST-LIVO2 在准确性、稳健性和效率方面优于最先进的系统。关键模块经过验证,我们展示了三个应用:突出实时功能的无人机导航、展示高精度的机载测绘,以及展示密集测绘适用性的 3D 模型渲染(基于网格和基于 NeRF)。
是否开源:https://github.com/hku-mars/FAST-LIVO2

引言
LIVO系统待解决的问题:
- LIVO 系统的任务是处理 LiDAR 测量,包括每秒数百到数千个点,以及高速、高分辨率的图像。充分利用如此大量的数据所面临的挑战,尤其是在机载资源有限的情况下,需要卓越的计算效率。
- LIO、VIO在退化场景下有效的特征提取难度大,需要针对性设计。
- 重建中稀疏的点云、稠密的高分辨率图像的联合地图管理仍是一个挑战。
- 对于高精密度的定位和重建算法,对硬同步设备要求非常高,此工作也开源了硬同步方案。
针对问题作出的改进:
- 算法提出ESIKF框架来解决激光、相机尺度不匹配和计算效率问题。
- 利用激光平面先验来提升精度,认为小的patch中的像素具有相同的深度值。
- 提出了一种参考补丁的策略,有效提升了图像对其的准确性。
- 曝光时间估算,来提高算法对场景光照变化的适应能力。
- 按需体素光线投射,以在没有由 LiDAR 近距离盲区引起的 LiDAR 点测量的情况下增强系统稳健性,
Method
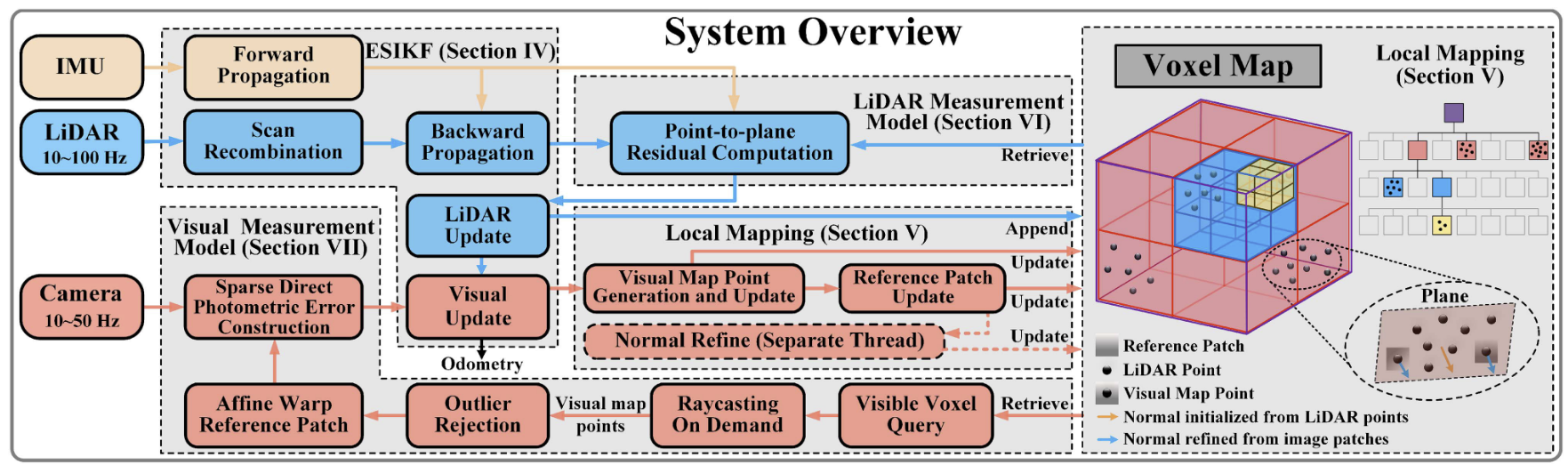
ESIKF WITH SEQUENTIAL STATE UPDATE
A. Notations and State Transition Model
本小节介绍了论文中的符号定义和状态转移模型,其中,规定IMU为body系,以第一帧body系作为世界坐标系。IMU运动模型的状态转移公式如下(1)。
![]()
Fastlivo2中的系统状态比Fastlivo中多了对相机曝光时间的估计。
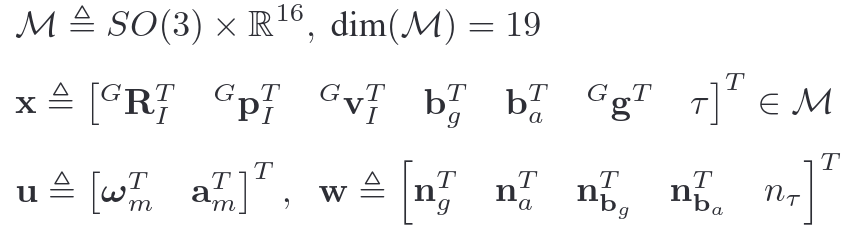
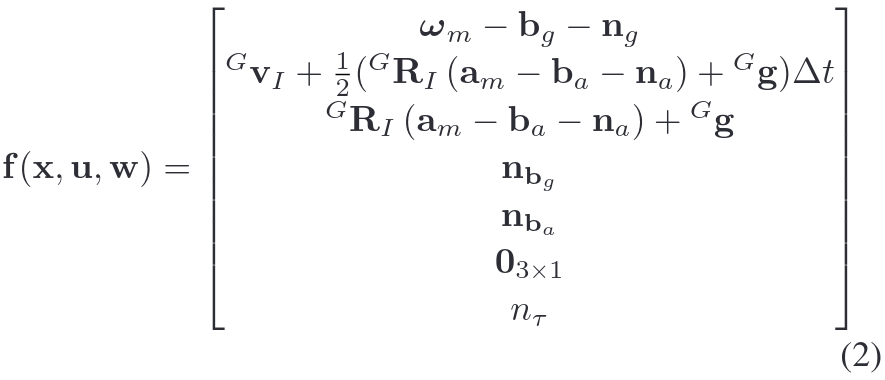
Fastlivo的IMU运动模型的状态空间:
f公式来源:
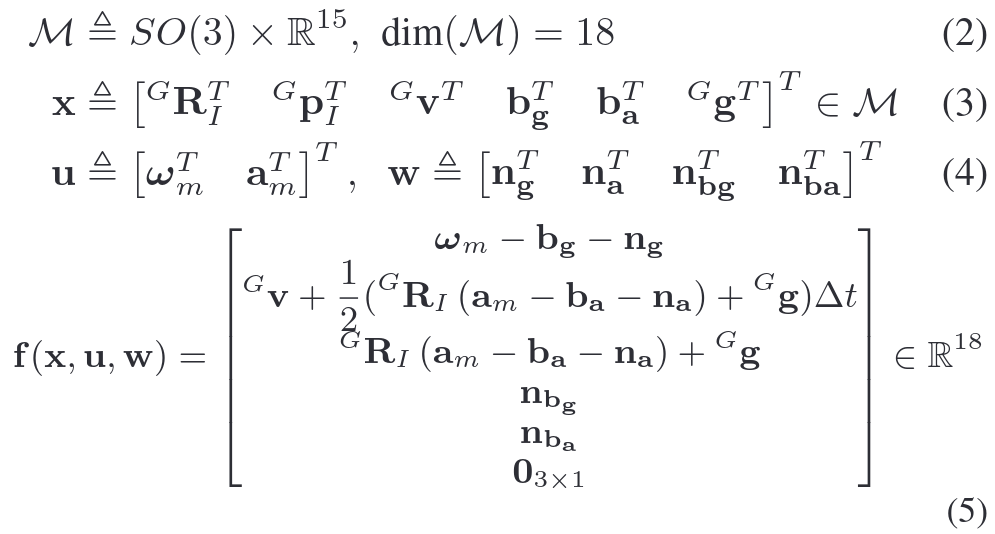
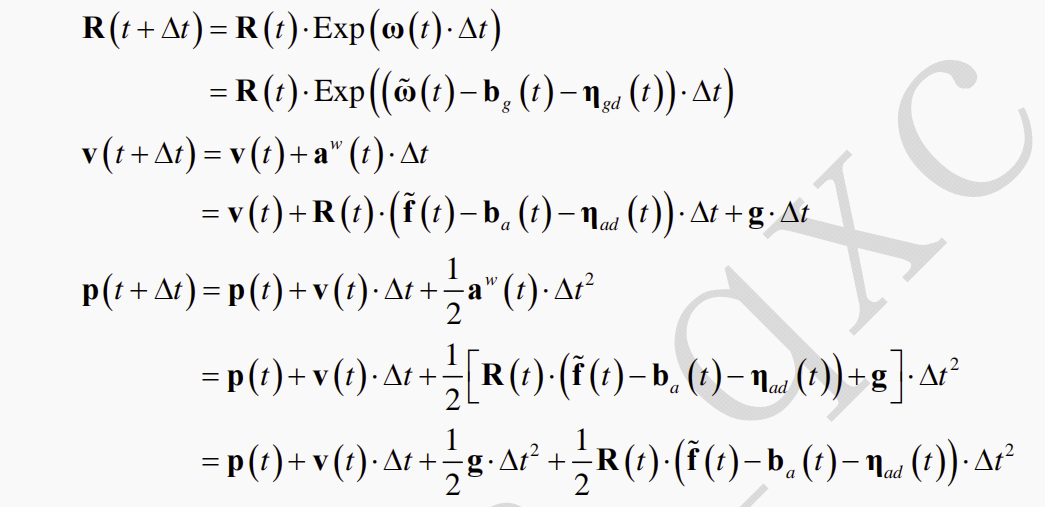
B. Scan Recombination
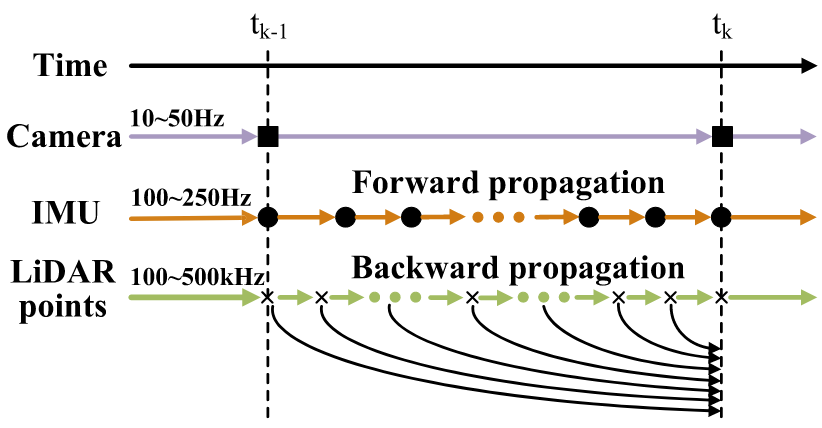
将激光点与相机帧对齐。这一步需要借助代码实现方便理解。虽然激光雷达包含msg,但是激光帧是以图像帧来划分的。将lidar msg的所有激光点保留之后,再根据图像时间二次划分激光帧。
// 当前相机的时间辍 = rosmsg的时间辍 + 待估计的曝光时间 // exposure_time_init = 0.0 double img_capture_time = img_time_buffer.front() + exposure_time_init; // 分割LiDAR点云到当前/下一帧 while (LiDAR帧头时间 <= img_capture_time) { for (点云中的每个点) { if (时间戳 < 阈值) 加入当前帧; else 加入下一帧; } pop LiDAR缓冲区; }
C. Propagation(预测阶段)
IMU状态预测和协方差更新,也被称为前向传播(Forward Propagation),此时将误差和噪声置零。此处公式与Fastlio中的前向传播一致。公式推导略,详见参考文献1。
前向传播具有两个功能:1.通过IMU积分估计下一时刻的状态。2.为Lidar提供运动畸变补偿
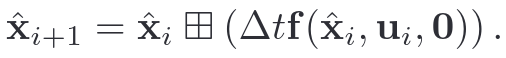
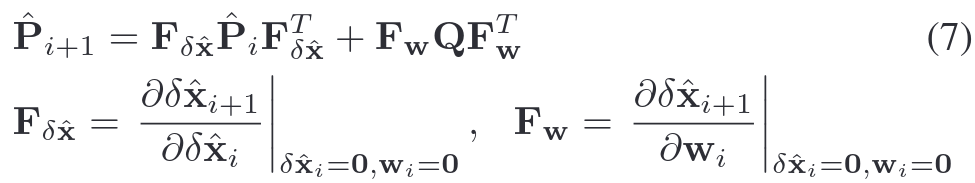
D. Sequential Update(更新阶段)
由于多传感器,EKF遵循顺序更新。推导过程略。
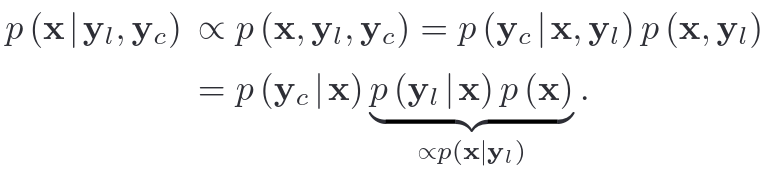
LOCAL MAPPING
A. Map Structure
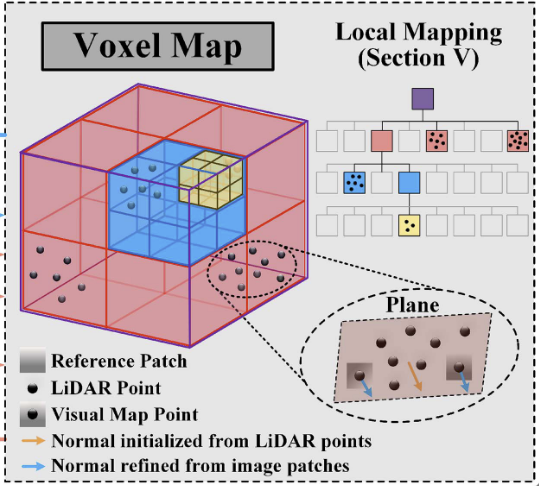
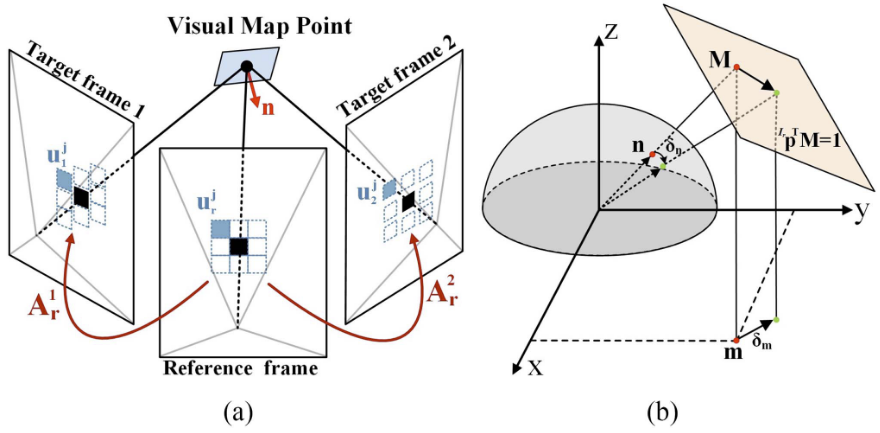
1.结合八叉树和哈希表,采用自适应体素结构,实现多分辨率环境建模。每个根体素为 0.5m × 0.5m × 0.5m 的立方体,通过哈希表快速定位根体素,键为空间坐标,值为对应的八叉树结构。叶体素存储拟合的局部平面参数(中心点、法向量、不确定性)、位于该平面上的LiDAR点、部分点附有8×8图像块。视觉地图点分为收敛点(如关键帧中的特征)和未收敛点(用于后续优化)。
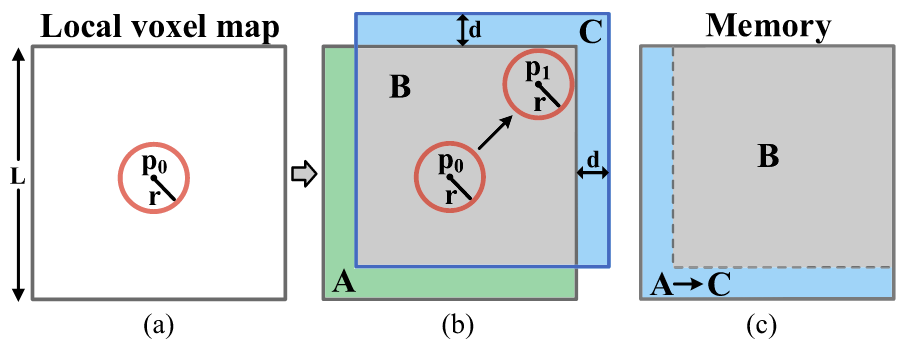
2.局部地图与内存管理,以LiDAR当前位置为中心,边长为L的立方体(避免内存爆炸)。当LiDAR移动至新位置(如p1),检测区域触及地图边界,地图沿移动方向平移距离d,移出部分的内存被重置(环形缓冲区策略)。
B. Geometry Construction and Update
当前ESIKF雷达更新结束后,将激光点转化到世界系,并存储到local map哈希地图上的根体素,若体素不存在则在体素地图中创建一个。
对于新创建的体素,通过SVD分解判断体素内的激光点云是否处于同一个平面。如果是,则进一步计算平面参数:平面中心点、法向量、平面的协方差。协方差用于衡量平面不确定性,由位姿估计的不确定性和点观测的不确定性影响。如果点云不能划分为平面,就进一步划分八叉树,直到所有点都存储在平面上。否则该叶节点的点云将被丢弃。
对于已有的地图,对新来的激光点云和体素原有的点计算平面参数,并判断参数是否收敛以判断平面是否成熟是否需要添加新点。收敛则删除新点,否则保留。成熟平面的参数将被固定。
平面上的激光点将在后续章节中用于生成可视化地图点。对于成熟平面,50个最近的LiDAR点是视觉地图点生成的候选点,而对于不成熟平面,所有的LiDAR点都是候选点。视觉地图点生成过程会将这些候选点中的一部分识别为视觉地图点,并将其与图像块贴合,用于图像对齐。
C. Visual Map Point Generation and Update
1.为了更新视觉地图点,在激光点云中筛选候选点,有两个要求,首先与相机具有相同的视野内,其次在当前图像中拥有最高的像素梯度。将这些候选激光点投影到当前图像中。并在每个体素中保留深度值最小的激光点。
2.将当前图像划分为若干网格(30x30 pixel)。如果当前网格不包含视觉地图点,就使用具有最大灰度梯度的候选激光点生成一个,并且把它和当前图像块(三层的图像块patch(如11×11像素),每层为前一层的1/2分辨率,形成多尺度金字塔)、当前机器人状态(位姿、相机曝光时间)、点云平面参数(局部法向量)等信息存储在一个数据结构中。目的是,强制视觉地图点在图像空间均匀分布,避免特征聚集。
若当前网格包含视觉地图点,则通过以下条件判断是否需要更新该地图点的信息。1.距离上次该视觉地图点添加patch超过20帧。2.当前投影位置与上次添加时的位置偏移超过40像素。满足其一则将当前图像块金字塔(三层)添加到现有视觉地图点,以捕捉不同视角下的外观变化,增强视角不变性。
D. Reference Patch Update
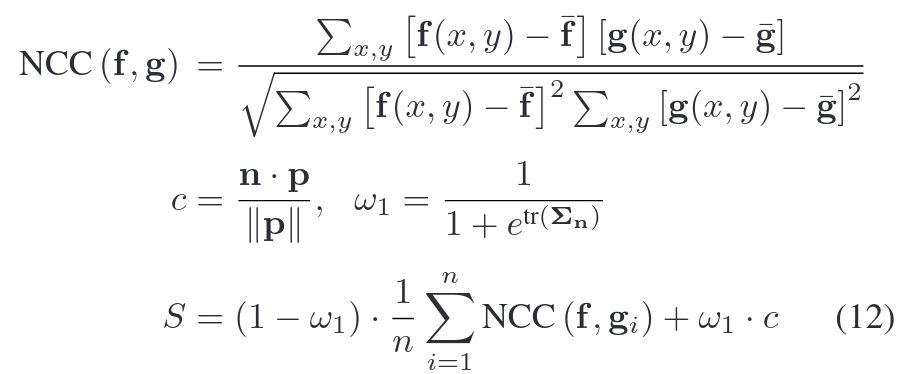
由于增加了新的图斑,一个可视地图点可以有多个图斑。在视觉更新中,我们需要选择一个参考块进行图像对齐。具体来说,我们根据光度相似性和视角对每个色块f进行如下评分。
patch图块的相似性指标用NCC(Normalized Cross-Correlation,归一化互相关)衡量 f 与其他所有图像块 g 的平均相似性。此处借鉴MVS中的技术,避免动态物体的影响。
视角相似性(cosine similarity)由平面法向量和视角方向的余弦函数决定。视角方向希望与平面正交以保证在高分辨率情况下保留纹理细节。
总的得分S的各项权重由平面法协方差的迹来调整。最高得分的patch作为参考patch。
对比FAST-LIVO,参考面片更新策略直接选择与当前帧视图方向差异最小的面片,导致选择的参考面片与当前帧非常接近,从而对当前位姿更新施加了较弱的约束。
E. Normal Refine
DSO、SVO、FAST-LIVO中均假设patch中的像素具有相同的深度,这种假设过强,大部分情况都不满足。本工作采用激光点来获得更准确的平面参数,平面法向量对于在视觉更新过程中执行仿射变形进行图像对齐是至关重要的。为了进一步提高仿射变换的精度,平面法向量可以在视觉地图点的patch中得到优化。具体来说,对于某一个visual map point通过最小化reference patch和其他patch的光度误差来优化reference patch中的平面法向量。
1)仿射变换 Affine Warping
仿射变换用于将reference patch(source patch)的像素坐标映射到其他frames(target patch),考虑局部平面几何与相机位姿。
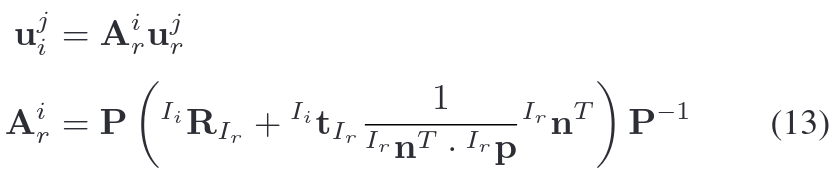
仿射变换推导过程
公式13的推导源于针孔相机模型下平面单应性变换(Planar Homography)的扩展,结合了局部平面几何与仿射近似。以下是详细推导步骤:
1. 针孔相机投影模型回顾
设相机内参矩阵为
,世界点
在相机坐标系下的坐标为
,投影到图像平面的像素坐标为:
.
2. 平面约束与单应性变换
假设所有点位于局部平面,其法向量为
,中心点
(参考帧坐标系下)。平面方程为:
.
目标帧
相对于参考帧
的位姿为
,则目标帧坐标系下的点坐标为:
3. 平面单应性矩阵推导
4.与经典单应性矩阵的关系


2)法向量优化 Normal Optimization
通过最小化参考块与其他块的光度误差,优化平面法向量。通过光度误差反向传播,调整法向量使仿射变形后的图像块对齐更精确。τr,τi:参考帧与目标帧的逆曝光时间(用于光度补偿)。Ir,Ii:参考帧与目标帧的图像强度值。
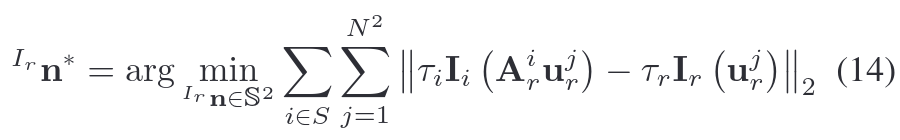
3)优化变量变换矩阵Optimization Variable Transformation
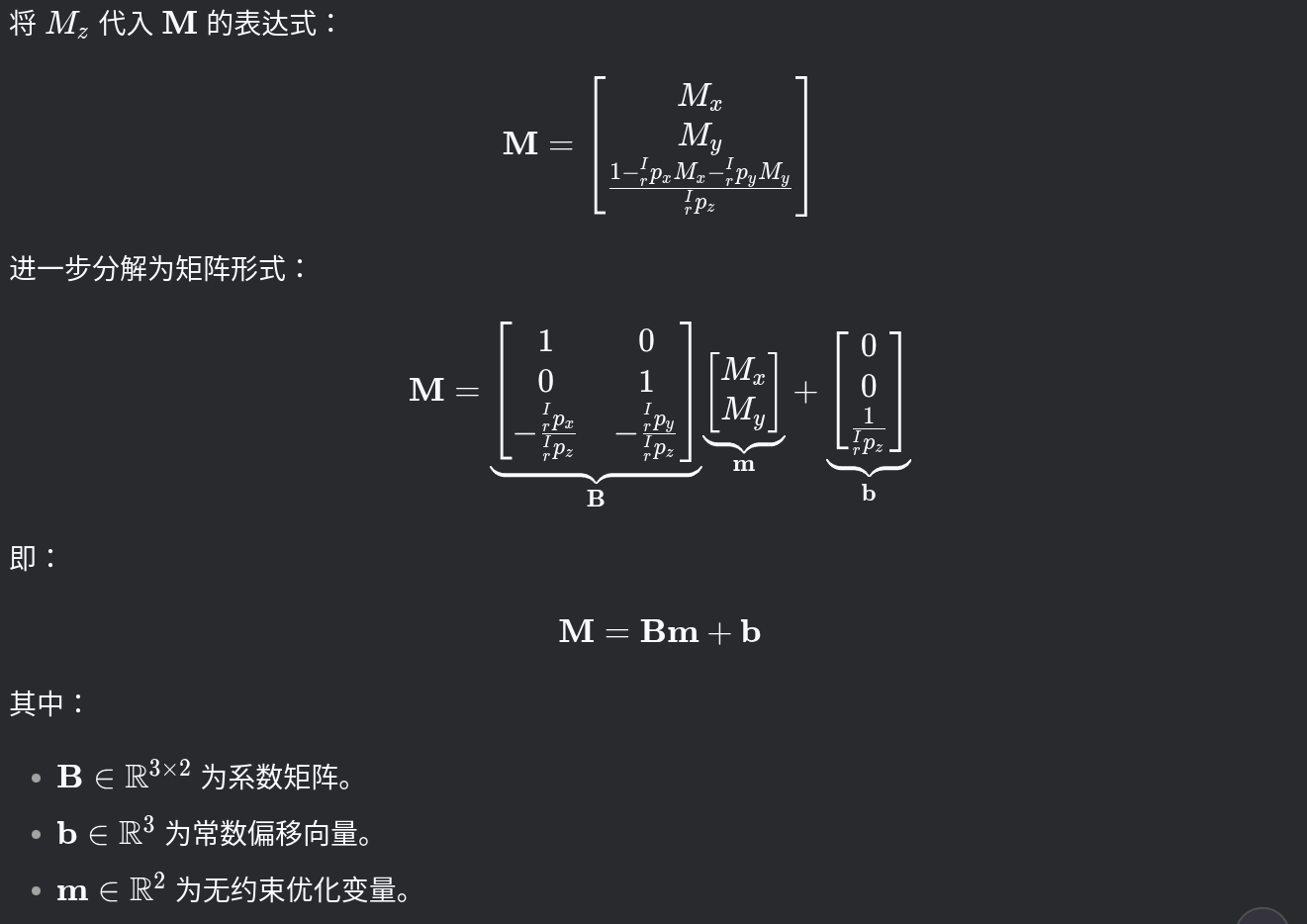
为了提高公式(14)中的计算效率,对其进行重新参数化。注意到待优化变量n,只出现在(13),。优化以M向量形式进行,且满足
,得如下参数化:优化 m 时无需额外约束条件,可直接使用无约束优化算法(如高斯-牛顿法)。这种优化可以在单独的线程中执行,以避免阻塞主要的里程计线程。优化后的参数m *可用于恢复最优法向量。一旦平面法线收敛,该视觉映射点的参考面片和法向量将被固定,而不需要进一步细化,所有其他面片将被删除。
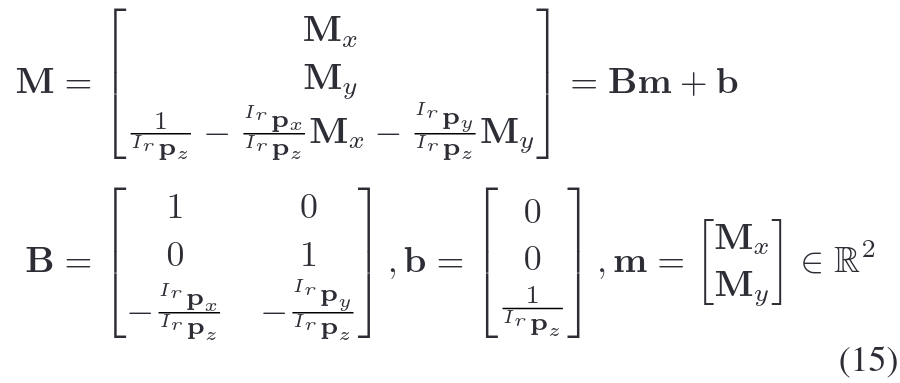
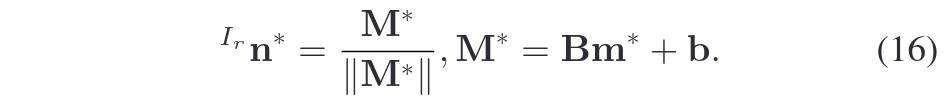
参数化过程推导
公式(15)的参数化过程通过引入约束条件
,将三维向量 M 转换为二维无约束变量 m。以下是详细的推导步骤:
1. 约束条件与变量分解
2. 参数化表达

LIDAR MEASUREMENT MODEL
A. Point-to-Plane LiDAR Measurement Model
首先将当前去畸变的激光点云,投影到世界系下:
![]()
判断该点Gp的体素是否在哈希地图中,并判断该体素是否含有平面,没有的话则抛弃该点。如果有平面,则为该激光点构建观测方程——假设该激光点位于该体素内的平面中。
![]()
此处p^gt就是pj。构建成误差状态表示:

B. LiDAR Measurement Noise With Beam Divergence
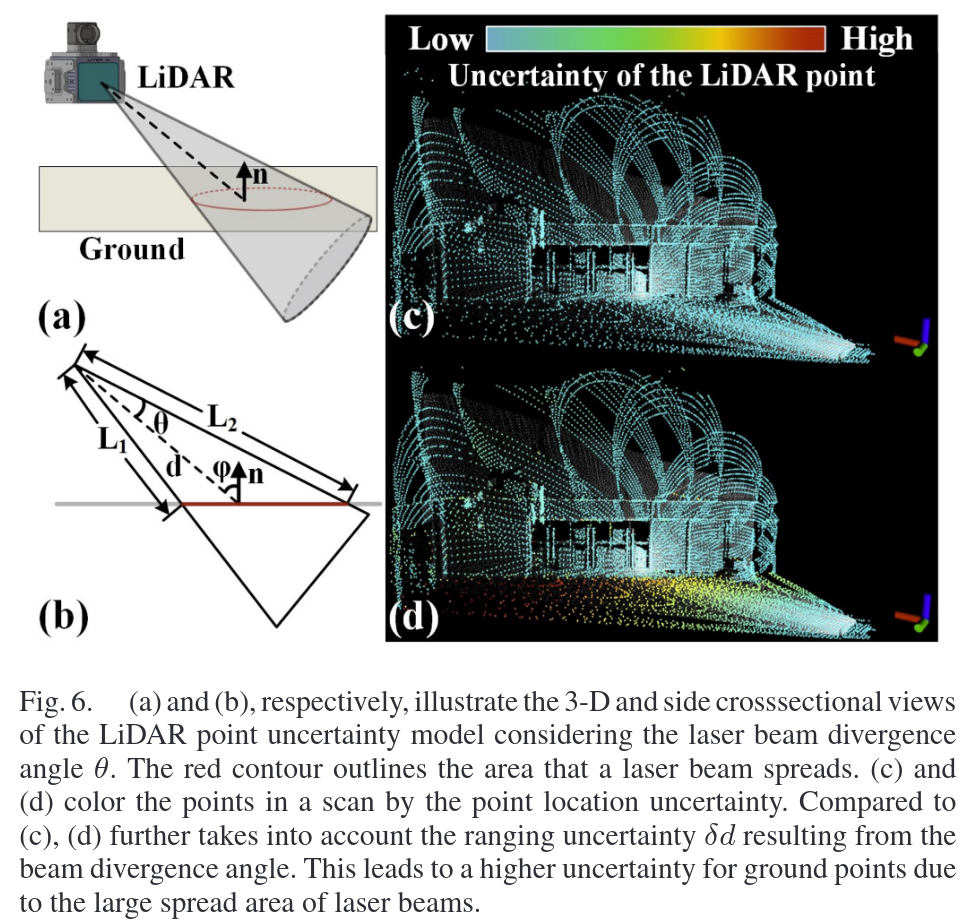
根据激光入射角度定义了观测的不确定度。
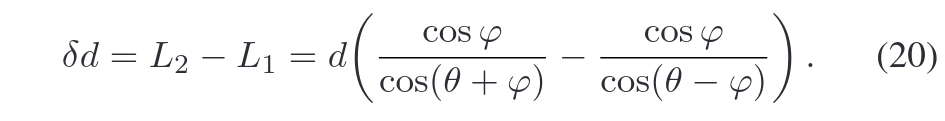
激光入射角如何导致测距不确定度
1. 物理背景与几何模型
激光雷达(LiDAR)通过发射激光束并接收反射信号来测量距离。实际测量中,激光束存在发散角(θ),导致光束覆盖一个微小的锥形区域(见图6)。当激光束以入射角φ(与物体表面法线的夹角)射向物体时,发散角会使激光束的两个边缘光线(θ+φ和θ-φ方向)在不同位置接触物体表面,导致测距误差。
6. 实际应用意义
地面与墙面点云的优势:地面和墙面通常具有较大的法向量与激光束夹角(φ较大),传统方法忽略发散角影响时误差显著。公式20通过显式建模φ与θ的耦合效应,修正了这些场景下的测距误差,从而提升定位精度。
系统优化:在SLAM或定位算法中,优先选择φ较小的点(如垂直入射点)或通过公式20补偿φ较大的点,可有效降低整体误差。


VISUAL MEASUREMENT MODEL
A. Visual Map Point Selection
为了在视觉更新中执行sparse image alignment,我们首先选择合适的视觉地图点。我们首先提取当前相机FoV中可见的地图点集(称为视觉submap),使用体素和raycasting queries。然后,从该子地图中选择视觉地图点并剔除离群点。这一过程产生了精化的视觉地图点集,为在视觉测量模型中构建视觉光度误差做好准备。
1) Visible Voxel Query
需要确定当前视角下哪些世界坐标系下的体素是可以被看到的。
-
输入:当前帧LiDAR点云、上一帧可见体素、相机参数。
-
步骤:
-
LiDAR点关联体素:对当前激光帧中被hit的体素进行轮询,该过程可通过哈希表加速查找。假设相机与LiDAR视野大部分重叠,命中体素内的地图点可能位于当前相机视野内。
-
历史可见体素继承:继承上一帧通过体素查询与射线投射标记为可见的体素。假设连续帧间视野重叠度高,避免重复计算。
-
合并与视野校验:最后,合并上述两类体素内的地图点,当前的视觉子图可以作为包含在这两类体素中的映射点获得,然后进行FoV检查,剔除实际不可见的点。
-
2) Raycasting on Demand
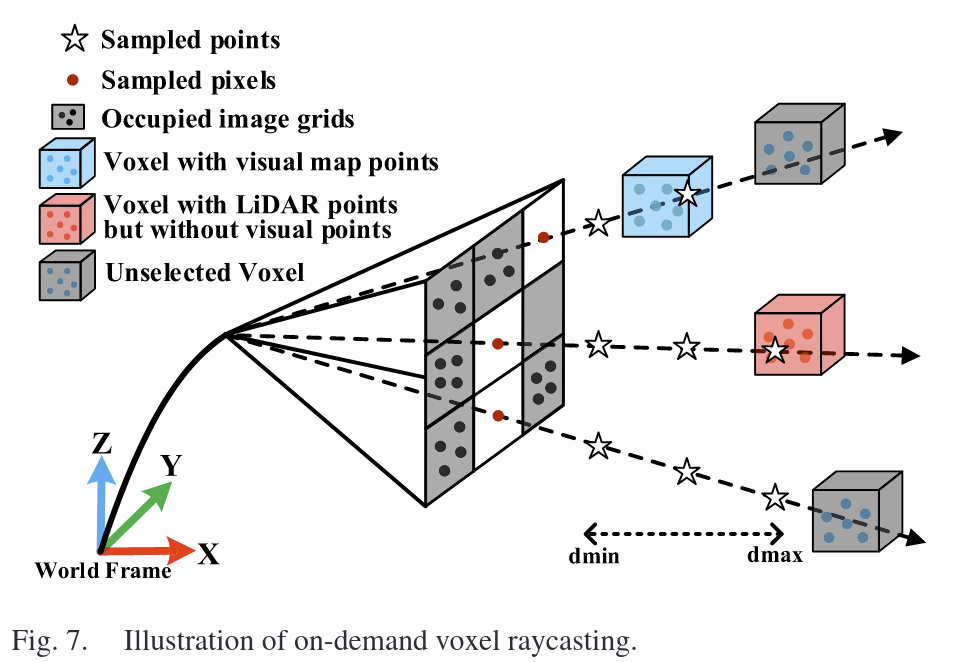
上述方法可以提取出大部分的可见体素,但也会存在特殊情况。1.若距离太近,可能会进入lidar盲区,没有任何点返回。2.相机FOV可能和激光FOV不重合。
1.我们将图像划分为均匀的网格单元,每个网格单元有30 × 30个像素,并将体素查询得到的视觉地图点投影到网格单元上。
2.对于没有视觉地图点的网格,沿着中心像素向后投射一条射线,其中样本点在深度方向从dmin到dmax沿射线均匀分布。为了减少计算量,预先计算了摄像机主体框架中每条射线上采样点的位置。
3.对于每个采样点,我们评估对应体素的状态:如果该体素包含投影后位于该网格单元中的映射点,我们将这些映射点合并到视觉子图中,并停止该射线。统计现有可见地图点的投影分布,标记空网格。
填补LiDAR盲区与相机扩展视野的空洞,确保地图点均匀覆盖图像。
3) Outlier Rejection
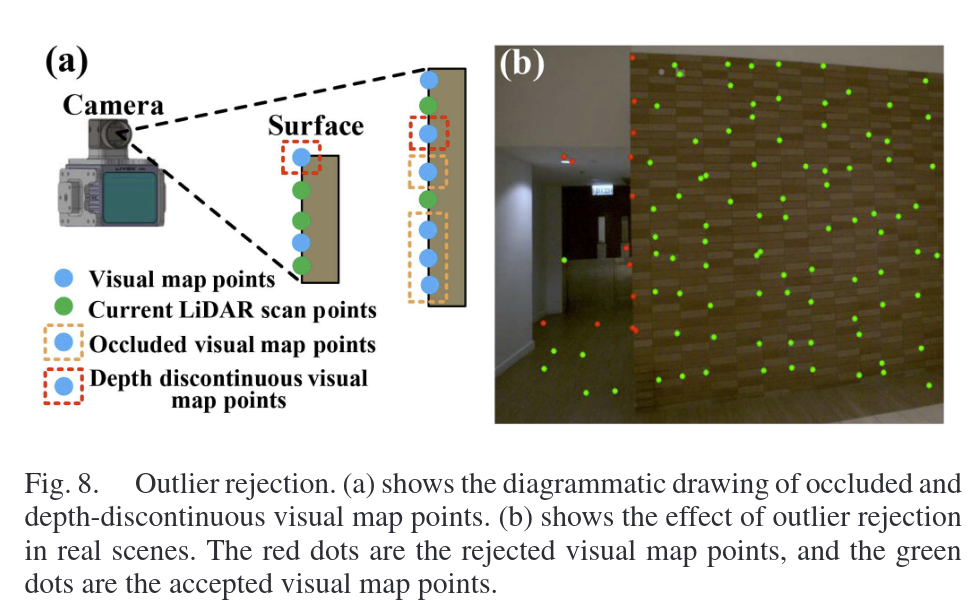
经过Visible Voxel Query和Raycasting,我们得到当前帧FoV中的所有视觉地图点。然而,这些视觉地图点可能在当前帧中被遮挡,深度不连续,其参考块在大视角下拍摄,或者在当前帧中具有大入射角,这些都会严重降低图像对齐精度。
对上述三个问题的解决方案如下:
1.将子图内所有地图点投影至当前帧后。在每个30×30网格中保留深度最小的点(最靠近相机的可见点)。
2.将当前LiDAR点云投影生成深度图。对每个地图点,检查其9×9邻域内的深度差异,若邻域深度差异超过阈值,判定为深度不连续或遮挡,剔除。
3.计算参考块与当前块的视角夹角(法向量与视线方向夹角)。剔除夹角超过80°的点(大视角导致纹理拉伸或模糊)。
B. Sparse-Direct Visual Measurement Model
1.构建光度误差
- 输入:视觉地图点 {pi}、当前图像 Ik、参考图像块 Ir、相机状态(位姿 Tc、曝光时间 τk,τr)。
- 在无噪声情况下,地图点投影到当前图像的光度值应与参考块一致。将视觉地图点在当前帧的图块与参考图块构建光度误差,理想形式如下
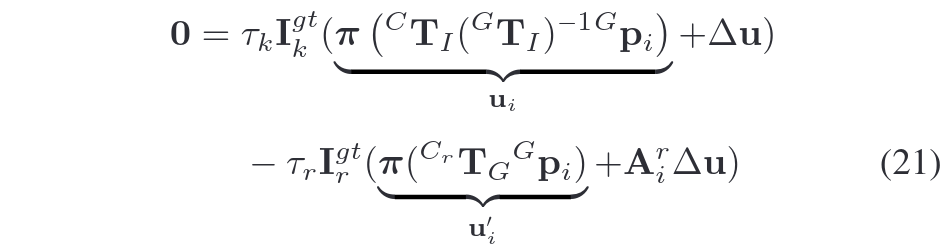
- 但是实际情况建模时包含相机噪声(如散粒噪声、ADC噪声)。优化yc状态参数(位姿、曝光时间)。 vc为观测噪声 (δIk, δIr),
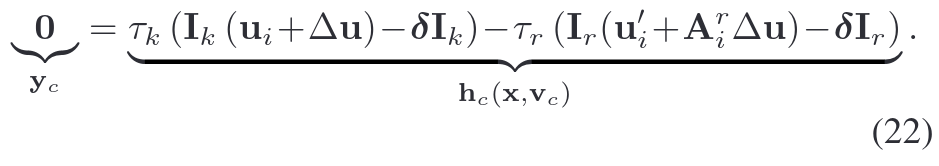
2.Inverse Compositional Formulation
- 为了提高计算效率,采用SVO中的处理方法。将位姿增量 δT 从当前帧移至参考帧,减少雅可比矩阵重复计算。用李群Exp(δT) 表示位姿增量(6自由度,旋转+平移)。
![]()
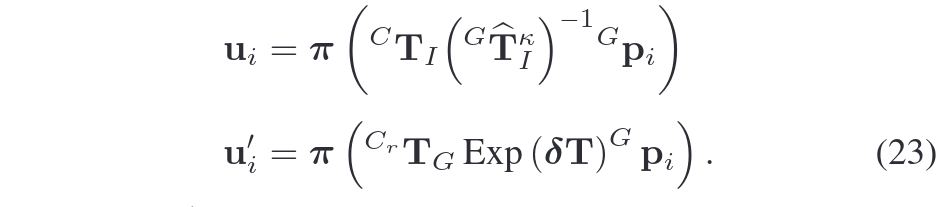
3.曝光时间估计
若所有逆曝光时间 ττ 为零,模型不可解。为避免退化问题:
-
固定首帧逆曝光时间 τ0=1
-
后续帧的 τk相对于首帧估计(如 τk=1.2表示曝光时间为首帧的 1/1.2 倍)。
参考文献
- 激光slam学习笔记5---ubuntu2004部署运行fastlivo踩坑记录_fast-livo部署-CSDN博客
- 《IMU预积分总结与公式推导》邱笑晨
- 《自动驾驶与机器人中的SLAM技术:从理论到实践》高翔


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











