






介绍

今天我们来说一个小技巧,就是对PDF文件大小的压缩。那么这个问题是怎么来的呢,我们在系统上传PDF文件的时候,由于系统限制,PDF大小受到了限制,我们需要对PDF进行压缩小一点进行上传,才能满足系统的要求。那么下来就看看,怎么进行操作吧!
软件
福昕阅读器

下载
这个软件在360软件管家就有,免费的,大家可以自行下载
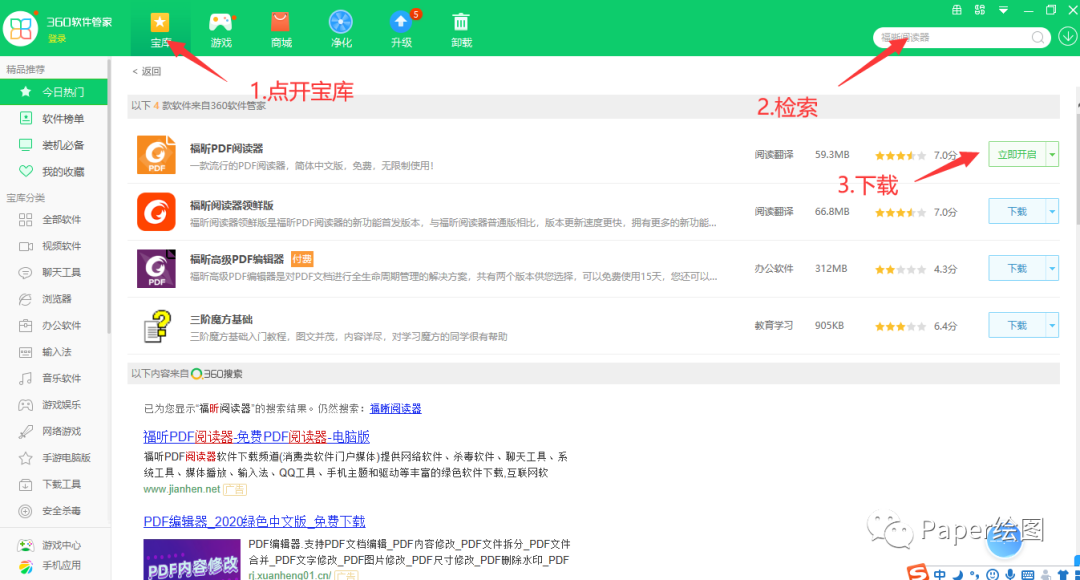
图文教程
1. 使用福昕阅读器打开我们的原本的PDF论文,点击菜单栏-文件,选择打印
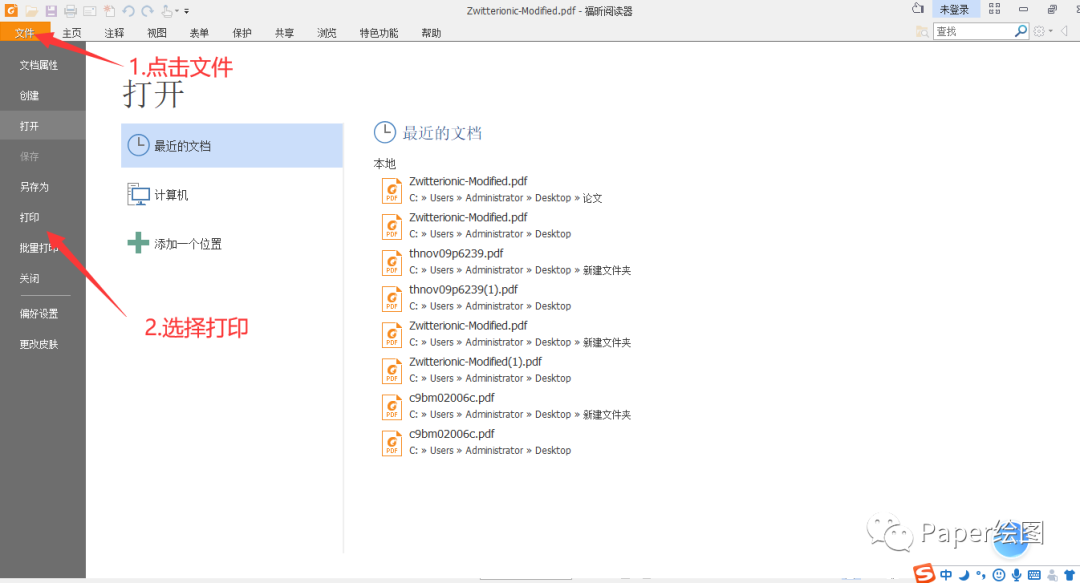
2. 选择福昕阅读器进行打印
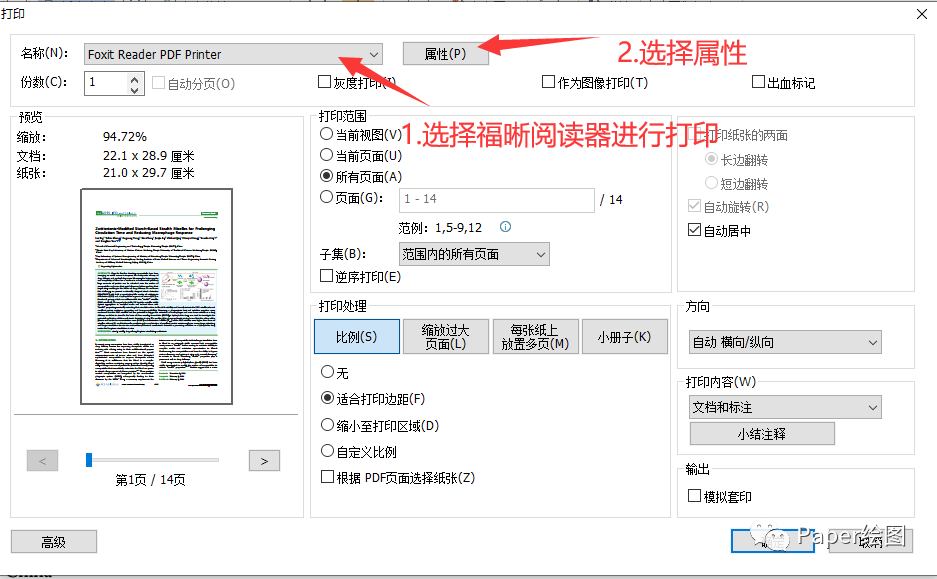
3. 设置打印参数,降低图片的分辨率。这里有很多层次的分辨率,分辨率越高,文件的内存就越大,所以选择自己适合的分辨率就好。

4. 选择确定
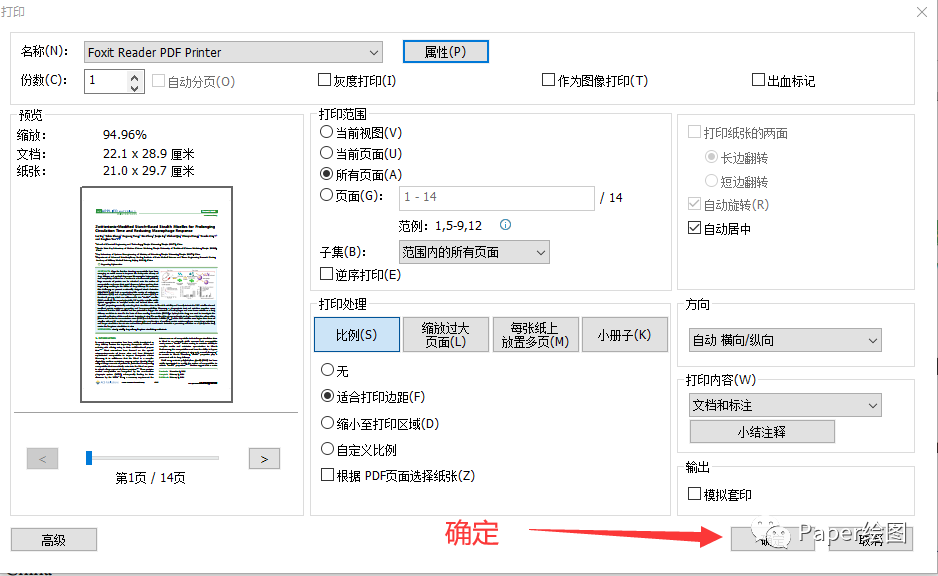
5. 进行打印
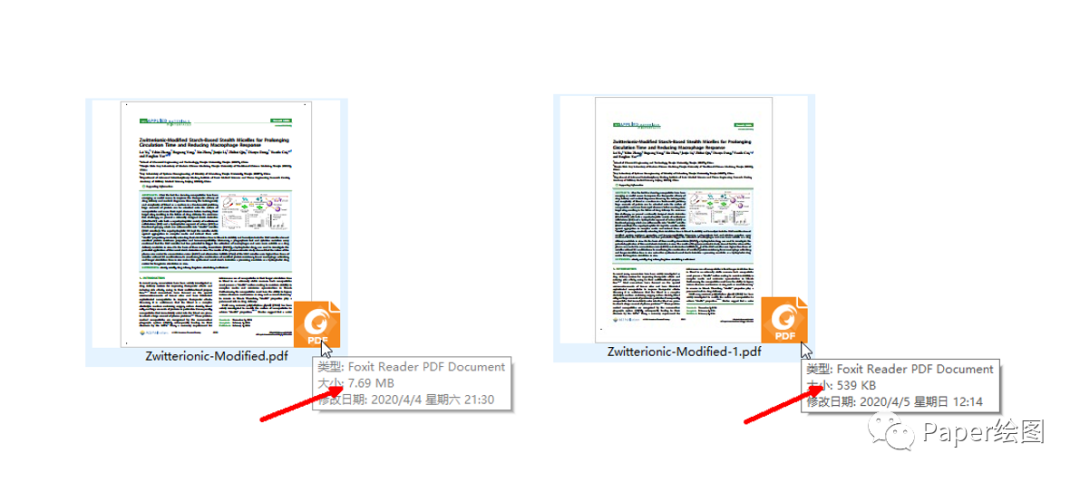
6. 打印完成比较一下大小,看看是不是变化了,那么此时已经从7.69MB变成了539k,已经缩小到了1MB,足够你上传系统了。
7. 怎么样,学会了吗?这么好的技巧赶紧来试试吧!
注:测试结果,有的文件有明显变小(有位图),但有的文件也会不变或明显变大(如矢量图找多时)。没有万能的方法,此法不行可尝试其它方法。如把PDF拆分成单页,找出体积大的单页,将矢量图单图压缩或转换成低质量图片,再合成新的图片。
猜你喜欢
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature Cell专刊 肠道指挥大脑
文献阅读 热心肠 SemanticScholar Geenmedical
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外5000+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。PI请明示身份,另有海内外微生物相关PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。

学习16S扩增子、宏基因组科研思路和分析实战,关注“宏基因组”
 点击阅读原文,跳转最新文章目录阅读
点击阅读原文,跳转最新文章目录阅读
https://mp.weixin.qq.com/s/5jQspEvH5_4Xmart22gjMA

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









