







如果神经网络的初值选取的不好的话,往往会陷入局部最小值。实际应用表明,如果把 RBM 训练得到的权值矩阵和 bias 作为 BP 神经网络的初始值,得到的结果会非常好。其实,RBM 最主要的用途还是用来降维。
(1)RBM 属于 unsupervised learning
用于非监督学习的神经网络主要有以下三个:
- RBM
- Autoencoders
- sparse coding model
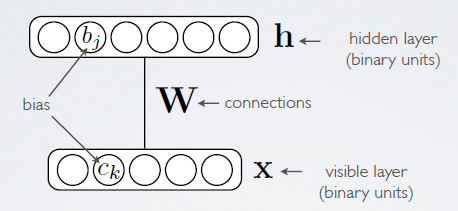
(2)RBM 网络共有两层,Visible Layer ⇔ Hidden Layer
(3)deep learning 中一个重要网络结构 DBN,便是由 RBM 网络叠加而成(Autoencoder ⇒ Stacked Autoencoder),
就像模拟退火算法,RBM 也是一个受物理学启发而提出的模型。
一个事物有相应的稳态,如在一个碗内的小球会停留在碗底,即使受到扰动偏离了碗底,在扰动消失后,它会回到碗底。学过物理的人都知道,稳态是它势能最低的状态。因此稳态对应与某一种能量的最低状态。将这种概念引用到 Hopfield 网络中去,Hopfield 为此构造了一种能量函数的定义。这是他所作的一大贡献。引进能量函数概念可以进一步加深对这一类动力系统性质的认识,可以把求稳态变成一个求极值与优化的问题,从而为 Hopfield 网络找到一个解优化问题的应用。
RBM网络共有 2 层,
- 其中第一层称为可视层(visible units),一般来说是输入层,
- 另一层是隐含层(hidden units),也就是我们一般指的特征提取层。
在一般的文章中,都把这2层的节点看做是二值(binary)的,也就是只能取0或1,当然了,RBM中节点是可以取实数值的,这里取二值只是为了更好的解释各种公式而已。设计一个网络结构后,接下来就应该想方设法来求解网络中的参数值。而这又一般是通过最小化损失函数值来解得的。那么在RBM网络中,
- 我们的损失函数的表达式是什么呢,
- 损失函数的偏导函数又该怎么求呢?
energy function
(1)Energy function
E(x,h)=−hTWx−cTx−bTh(2)distribution
p(x,h)=e−E(x,h)Z=ehTWxecTxebTh/Z
inference
(1) p(h|x)
p(h|x)=∏jp(hj|x)p(hj|x)=11+exp(−(bj+Wj⋅x))=sigm(bj+Wj⋅x)
(2) p(x|h)
p(x|h)=∏kp(xk|h)p(xk|h)=11+exp(−(ck+hTWk))=sigm(ck+hTWk)
Free Energy
F(x) 即为 Free Energy;
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











