







 NICE-SLAM是结合神经隐式解码器与分层场景表示的RGB-D SLAM系统,适用于大规模场景。通过层次特征网格和预训练的神经网络,它实现了高效局部更新,增强了场景重建的细节和跟踪质量。论文在多个数据集上展示了其在跟踪和重建方面的优秀性能,尤其是在处理动态对象和帧丢失时的鲁棒性。
NICE-SLAM是结合神经隐式解码器与分层场景表示的RGB-D SLAM系统,适用于大规模场景。通过层次特征网格和预训练的神经网络,它实现了高效局部更新,增强了场景重建的细节和跟踪质量。论文在多个数据集上展示了其在跟踪和重建方面的优秀性能,尤其是在处理动态对象和帧丢失时的鲁棒性。
1. 总结
NICE-SLAM一种结合了神经隐式表示和分层场景表示的密集RGB-D SLAM系统。该方法在保持神经隐式表示的表示能力的同时,通过引入分层场景表示来实现可扩展性和效率。具体来说,场景的几何和颜色信息由四个特征网格及其相应的解码器联合编码,这些网格在不同的空间分辨率上进行优化。在测试时,通过最小化重新渲染的损失,只优化当前视锥体内的特征,从而实现高效的局部更新。并在多个具有挑战性的数据集上进行了方法评估,结果表明NICE-SLAM在重建效果好和跟踪质量高。
2. 论文
相机跟踪和地图构建是NICE-SLAM算法的两个主要步骤。以下是这两个步骤的详细过程和对应的数学推导:
2. 1 算法核心流程小姐
-
相机跟踪:
相机跟踪的目标是估计当前帧的相机位姿。假设我们有一系列的历史关键帧{K1, K2, …, Kt},以及当前帧It的深度图Dt和相机内参矩阵Kc。我们可以用一个优化问题来描述相机跟踪的过程:
min R,t ∑m=1:M L(Dm, ˆDm)
其中,R和t是相机的旋转和平移矩阵,Dm是第m个关键帧的深度图,ˆDm是通过当前帧的相机位姿投影到第m个关键帧的深度图。L(·)是一个光度误差损失函数,常用的有平方损失或者Huber损失。
为了求解这个优化问题,NICE-SLAM使用了Levenberg-Marquardt算法。这个算法是一种非线性最小二乘优化算法,它结合了梯度下降和牛顿法的优点,能够在保证收敛速度的同时,对初始值和噪声具有较好的鲁棒性。
-
地图构建:
地图构建的目标是优化场景的几何表示。假设我们选择了K个关键帧 K 1 , K 2 , . . . , K t {K1, K2, ..., Kt} K1,K2,...,Kt,以及对应的深度图 D 1 , D 2 , . . . , D t {D1, D2, ..., Dt} D1,D2,...,Dt和相机位姿 R 1 , R 2 , . . . , R t , t {R1, R2, ..., Rt, t} R1,R2,...,Rt,t。我们可以用一个优化问题来描述地图构建的过程:
m i n θ , R i , t i ∑ i = 1 : K ( L p i + L g i ) min θ,Ri,ti ∑i=1:K (Lpi + Lgi) minθ,Ri,ti∑i=1:K(Lpi+Lgi)
其中,θ是特征网格的参数,Ri和ti是第i个关键帧的相机位姿。Lpi是光度误差,Lgi是几何误差。这两个误差的定义如下:
L p i = ∑ m = 1 : M w p i , m L p , m Lpi = ∑m=1:M wpi,m Lp,m Lpi=∑m=1:Mwpi,mLp,m
L g i = ∑ m = 1 : M w g i , m L g , m Lgi = ∑m=1:M wgi,m Lg,m Lgi=∑m=1:Mwgi,mLg,m
其中,M是采样的像素点数量, w p i , m wpi,m wpi,m和 w g i , m wgi,m wgi,m是权重, L p , m Lp,m Lp,m和 L g , m Lg,m Lg,m分别是第 m m m个像素点的光度误差和几何误差。
为了求解这个优化问题,NICE-SLAM使用了一种交替优化策略。具体来说,它首先固定特征网格的参数θ,然后优化关键帧的相机位姿{Ri, ti}。这一步可以通过求解一个非线性最小二乘问题来完成。然后,它固定相机位姿,优化特征网格的参数θ。这一步可以通过梯度下降来完成。这个过程会迭代进行,直到收敛。
提出了NICE-SLAM,这是一个结合神经隐式解码器和分层网格表示的密集RGB-D SLAM系统,可应用于大型场景。
2.2 论文摘要

图2
神经隐式表示最近在各个领域显示出了令人鼓舞的结果,包括在同时定位和地图构建(SLAM)方面取得了令人期待的进展。然而,现有方法产生了过于平滑的场景重建,并且难以扩展到大型场景。这些局限主要是由于它们简单的全连接网络架构,没有结合观测中的局部信息。在本文中,我们提出了NICE-SLAM,这是一个密集的SLAM系统,通过引入分层场景表示,结合了多级局部信息。通过利用预训练的几何先验优化这种表示,能够对大型室内场景进行详细重建。与最近的神经隐式SLAM系统相比,我们的方法更具可扩展性、效率和鲁棒性。对五个具有挑战性的数据集进行的实验表明,NICE-SLAM在地图构建和跟踪质量上具有竞争力的结果。
2.3 Dataset result
2.3.1 Replica Dataset result
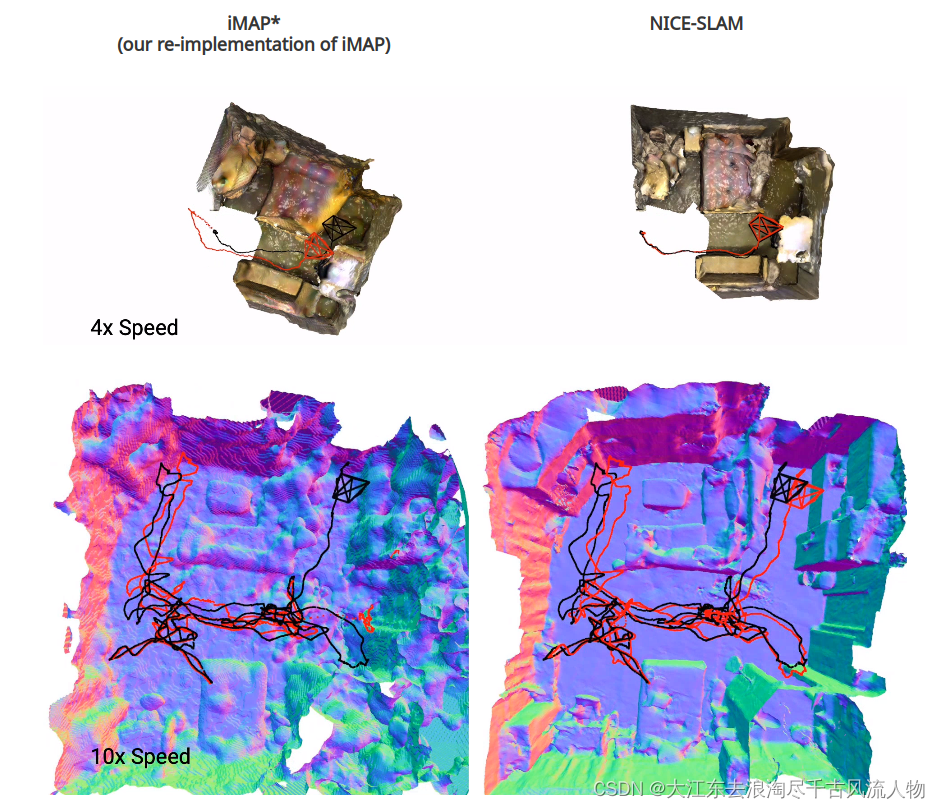
2.3.2 ScanNet Dataset result
As can be observed, our NICE-SLAM produces sharper and cleaner geometry. Also, unlike the global update as shown in iMAP, our system can update locally thanks to the grid-based hierarchical representation.
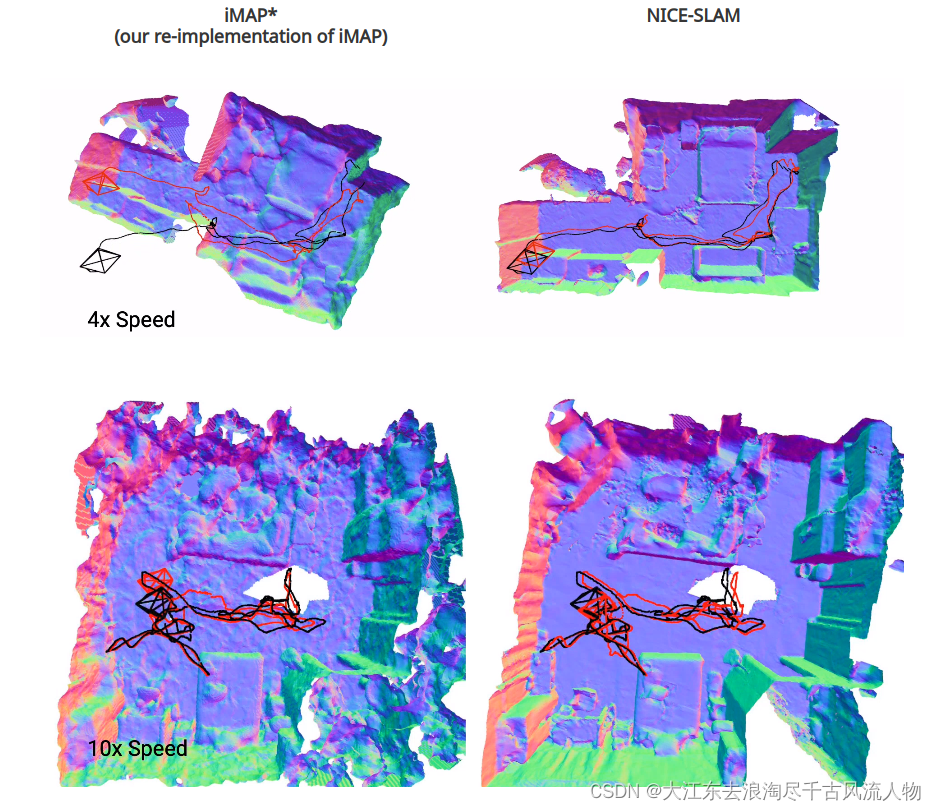
2.3.3 Multi-room Apartment result
To further evaluate the scalability of our method we capture a sequence in a large apartment with multiple rooms.

2.3.4 Co-fusion Dataset (Robustness to Dynamic Objects) result
NICE-SLAM is able to handle dynamic objects . Note that the airship and toy car is not wrongly reconstructed.
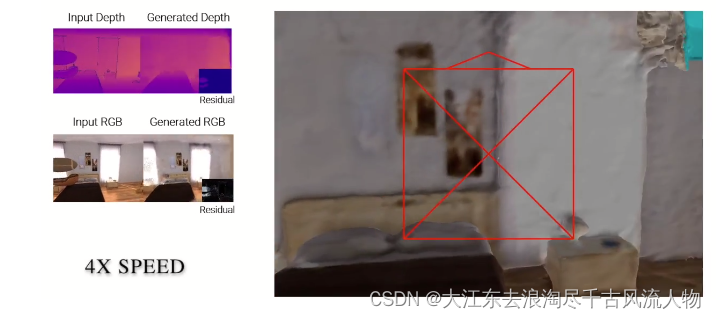
2.3.5 Robustness to Frame Loss
Here, we simulate large frame lost. The video show current tracking camera pose as well as rendered images for each tracking iteration. The ground truth camera is shown in black, the current tracking camera is shown in red. We can notice that NICE-SLAM is able to fast recover the camera pose thanks to the prediction from the coarse-level (shown in cyan).
一句话:跟踪实时且准确

这里机几组数据对比之下可以显示出这个模型的有点:
尺度准确性比较高;隐士表示,局部优化效果比较干净,平滑,低噪点;可以很好的处理手持动态数据场景;跟踪实时且准确
3. 论文翻译
3.1.摘要:见 1. 总结
3.2. 引言
稠密视觉SLAM是3D计算机视觉的一个基础问题,在自动驾驶、室内机器人、混合现实等领域有着广泛的应用。为了使SLAM系统在实际应用程序中真正有用,以下属性是必不可少的。首先,我们希望SLAM系统能够是实时的。接下来,该系统应该有能力对没有观测的区域做出合理的预测。此外,该系统应该能够扩展到大型场景。最后,对有噪声或观测缺失的情况具有鲁棒性是至关重要的。
在实时稠密视觉SLAM系统的范围内,近几年RGB-D相机已经引入了许多方法。传统的稠密视觉SLAM系统满足实时需求,可以用于大规模场景,但他们无法对未观测到的区域做出合理的几何估计。另一方面,基于学习的SLAM方法获得一定水平的预测能力,因为它们通常在特定任务的数据集上进行训练。此外,基于学习的方法往往能更好地处理噪声和异常值。然而,这些方法通常只在具有多个对象的小场景中工作。最近,Sucar等人在实时稠密SLAM系统(称为iMAP)中应用了神经隐式表示(neural implicit representation),他们对房间大小的数据集显示了良好的跟踪和建图结果。然而,当扩展到更大的场景时,例如,一个由多个房间组成的公寓,在稠密重建和相机跟踪精度方面都可以观察到显著的性能下降。
iMAP的关键限制因素源于它使用了一个单一的多层感知器(MLP)来表示整个场景,它只能随着每一个新的、潜在的部分场景而进行全局更新RGB-D观测。相比之下,最近的工作证明,建立基于多级网格特征可以帮助保存几何细节和重建复杂的场景,但这些都是没有实时功能的离线方法。
在这项工作中,我们试图结合分层场景表征(hierarchical scene representation)和神经隐式表征(neural implicit representation)的优势,以完成稠密RGB-D SLAM的任务。为此,我们引入了NICE-SLAM,这是一种稠密的RGB-D SLAM系统,可以应用于大规模场景,同时保持预测能力。我们的关键思想是用层次特征网格来表示场景的几何形状和外观,并结合在不同空间分辨率下预训练的神经隐式解码器的归纳偏差(inductive biases)。通过从占用率和彩色解码器输出中得到的渲染后的深度和彩色图像,我们可以通过最小化重渲染损失(re-rendering losses),只在可视范围内优化特征网格。我们对各种室内RGB-D序列进行了广泛的评估,并证明了我们的方法的可扩展性和预测能力。总的来说,我们做出了以下贡献:
我们提出了NICE-SLAM,一个稠密的RGB-DSLAM系统,对于各种具有挑战性的场景具有实时能力、可扩展性、可预测性以及鲁棒性。
NICE-SLAM的核心是一个层次化的、基于网格的神经隐式编码。与全局神经场景编码相比,这种表示允许局部更新,这是针对大规模方法的先决条件。
我们对各种数据集进行了广泛的评估,从而证明了在建图和跟踪方面的竞争性能。
3.3 相关工作
稠密视觉SLAM。大多数现代的视觉SLAM方法都遵循了Klein等人的开创性工作中引入的整体架构,将任务分解为建图和跟踪。地图表示通常可以分为两类:以视图为中心(view-centric)和以世界为中心(world-centric)。第一个是将三维几何图形锚定到特定的关键帧上,通常在密集的设置中表示为深度图。这类产品早期的例子之一是DTAM。由于其简单性,DTAM已被广泛应用于最近许多基于学习的SLAM系统。例如,DeepV2D在回归深度和姿态估计之间交替,但使用了测试时间优化。BA-Net和DeepFactor通过使用一组基础深度图简化了优化问题。还有一些方法,如CodeSLAM、Scene和NodeSLAM,它们可以优化一个可解码成关键帧或对象深度图的潜在表示。Droid-SLAM使用回归光流来定义几何残差进行细化。TANDEM结合了多视图立体几何和DSO的实时稠密SLAM系统。另一方面,以世界为中心的地图表示将三维几何图形固定在统一的世界坐标中,可以进一步划分为表面(surfels)和体素网格(voxel grids),通常存储占用概率或TSDF值。体素网格已广泛应用于RGB-D SLAM,例如Kinect-Fusion。在我们提出的管道中,我们也采用了体素网格表示。与以前的SLAM方法相比,我们存储几何的隐式潜在编码,并在建图过程中直接优化它们。这种更丰富的表示方式允许我们在较低的网格分辨率下实现更精确的几何图形。
神经隐式表示。最近,神经隐式表示在对象几何表示、场景补全、新视图合成还有生成模型方面显示出了很好的结果。最近的几篇论文试图用RGB-(D)输入来预测场景级的几何形状,但它们都假设了给定的相机姿态。另一组工作解决了相机姿态优化的问题,但它们需要一个相当长的优化过程,这并不适合实时应用。与我们的方法最相关的工作是iMAP。给定一个RGB-D序列,他们引入了一个实时稠密SLAM系统,该系统使用一个单一的多层感知器(MLP)来紧凑地表示完整的场景。然而,由于单个MLP多层感知机模型容量有限,iMAP不能产生详细的场景几何形状和精确的摄像机跟踪,特别是对于较大的场景。相比之下,我们提供了一个类似于iMAP的可扩展的解决方案,它结合了可学习的潜在嵌入和一个预先训练的连续隐式解码器。通过这种方式,我们的方法可以重建复杂的几何形状和为更大的室内场景预测详细的纹理,同时保持更少的计算和更快的收敛。值得注意的是,[17,38]还将传统的网格结构与学习到的特征表示结合起来,以实现可扩展性,但它们都不是实时的。此外,DI-Fusion也优化了给定RGB-D序列的特征网格,但它们的重建通常包含孔洞,它们的相机跟踪对纯表面渲染损失没有鲁棒性。
3.4 具体方法
我们在图2中概述了我们的方法。以RGB-D图像流作为输入,并输出相机姿态和学习到的分层特征网格形式的场景表示。从右到左的pipeline可解释为一个生成模型,它从给定的场景表示和相机姿态中呈现深度和彩色图像。在测试时,通过可微渲染器(从左到右)我们通过反向传播图像和深度重建损失来求解反问题来估计场景表示和相机姿态。这两个实体都是在一个交替的优化过程中进行估计的:建图:反向传播仅更新层次场景表示;跟踪:反向传播仅更新摄像机姿态。为了更好的可读性,我们将相同大小的颜色网格加入了几何编码的精细网格,并将它们显示为具有两个属性(红色和橙色)的一个网格。
使用四个特征网格及其相应的解码器来表示场景的几何形状和外观。我们使用估计的相机标定来跟踪每个像素的视射线。通过沿着视射线进行采样点并查询网络,我们可以渲染该射线的深度和颜色值。对于选择的关键帧,通过最小化深度和颜色损失,我们能够以交替的方式,同时优化相机位姿和场景几何。
3.4.1 Hierarchical Scene Representation 分层场景表示
我们现在介绍我们的分层场景表示,它将多层次的网格特征与预训练的解码器结合起来,用于占据预测。几何形状被编码成三个特征网格 ϕ θ l ϕ^l_θ ϕθ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











