







 本文深入解析Unity HLOD系统的工作原理与应用技巧,涵盖Shader LOD、LOD Bias概念,以及HLOD System的特性、架构与流程。通过实例演示如何优化场景渲染效率,减少Draw Call,提升大型游戏场景性能。
本文深入解析Unity HLOD系统的工作原理与应用技巧,涵盖Shader LOD、LOD Bias概念,以及HLOD System的特性、架构与流程。通过实例演示如何优化场景渲染效率,减少Draw Call,提升大型游戏场景性能。
///
Shader LOD
- 这个是另外一种控制细节级别的技术
- 在一个Shader当中,可以给不同的subshader指定不同的LOD属性,例如:
SubShader {
LOD 200
Pass {
//insert shader pass here
}
}
SubShader {
LOD 100
Pass {
//insert shader pass here
}
SubShader {
LOD 0
Pass {
//insert shader pass here
}
}
然后,就可以在脚本代码中指定一次全局Shader.globalMaximumLOD值,该值是LOD所执行的最大值,也就是说所有shader中的subshader的LOD值小于该全局值,该subshader才被执行。当然,也可以单独设置Shader.maximumLOD控制个别shader(??这里有疑问)
参考:Unity Technologies - jonas echterhoff What is Shader Level of Detail - Unity Forum
LOD Bias
- 执行unity编辑器菜单:Edit > Project Settings > Quality,会打开Quality Setting窗口
- 参考 : 官方文档 Quality Setting
- LOD Bias主要控制根据物体才屏幕中的百分比来控制LOD的变化,表现用大白话描述即是:如果该值小那么,摄像机离物体距离稍微有些变化,不同细节物体即会切换,该值大,那么摄像机需要与物体有很大的距离才会切换。
- 目的:就是控制整个场景的细节。当应用运行的平台比较好,会倾向使用较高级别的画质,这时就把离摄像机虽然很远(相对来说)的物体也让他以好的级别渲染,这样整体画质更好;反之,设备较差,那么,会希望离摄像机最近时才展示最好级别的物体对象,具体稍微远(相对来说)立马切换成稍差级别的物体。这样在整体画质级别不变的情况下,保持流畅。
注意,这里的 LOD 精度设置,里面填的数值是偏移数值,类似于缓冲。
数值越大,缓冲越大,当摄像机与模型距离,到达了需要切换到 低模的时候,不会立马切换,而是过了这个缓冲值再切换。
//
Unity HLOD
1.1 HLOD System简介
首先,HLOD System主要的目标是为了减少Draw Call。然后,进行更多的Batch批处理,从而大大提高渲染性能,减少面数和纹理,这样我们相应地节省了内存,并提升了加载时间。
HLOD System只针对当前所在的地方进行加载,它会流式加载网格和纹理,在后台进行异步的操作。
本次HLOD是基于官方AutoLOD代码的扩展和改进制作出来的,链接:https://github.com/Unity-Technologies/AutoLOD,链接是AutoLOD的文章,可以先看看。下面将详细介绍HLOD原理和实现。
1.2 HLOD与LOD对比

2.1 系统支持
BVH划分LOD Group
根据BVH划分进行合并模型和贴图
HLOD CULL系统
2.2 系统概述
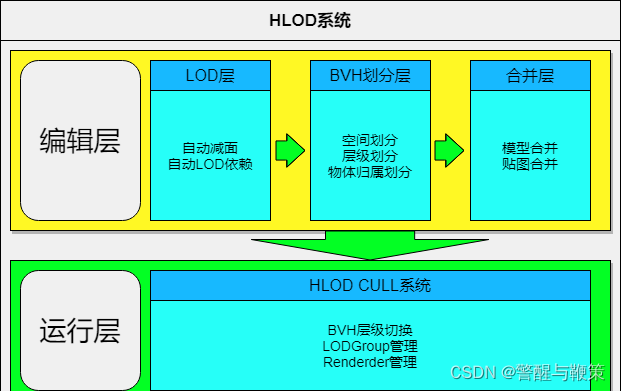
1.系统架构
系统主要由编辑层和运行层组成,编辑层负责每个预制体的LODGroup生成、BVH划分、网格、贴图合并,同时自动做好运行层所需要的关联。运行层负责该系统中Renderder、LODGroup管理及BVH层级切换,系统架构如图所示。
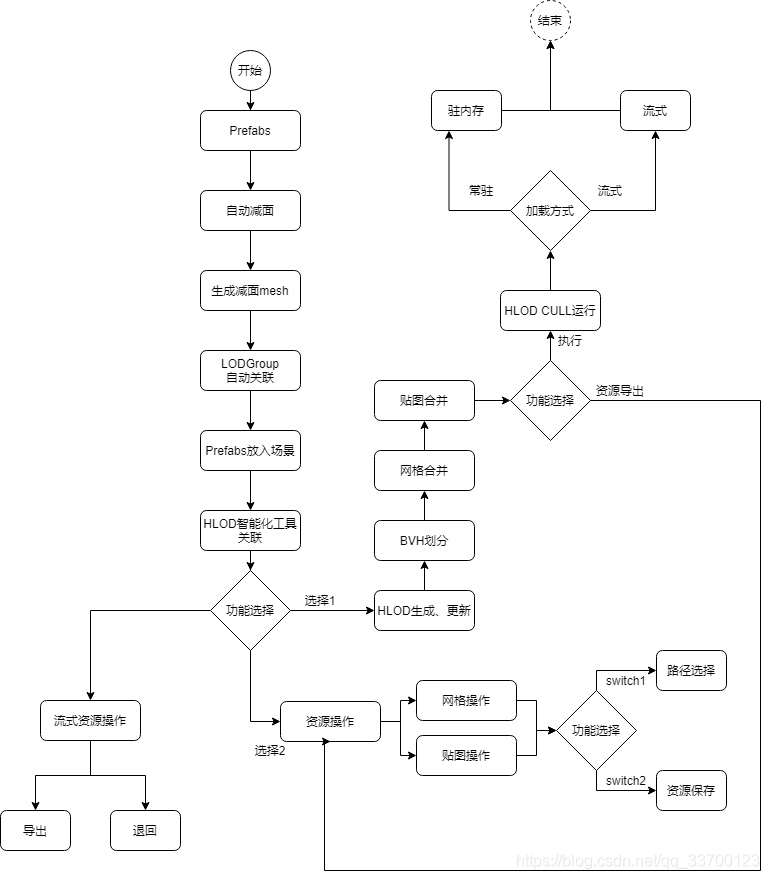
2.系统流程
本套系统拥有一条完整流程,其系统流程如图所示。
2.3 BVH划分LOD Group
八叉树对LOD Group进行划分到各个区域,划分条件由每个区域超过n个mesh开始划分,划分依据由LOD Group中心点作为划分点,可设置剔除实际包围盒超过指定大小的mesh,划分规则如图2-4所示。
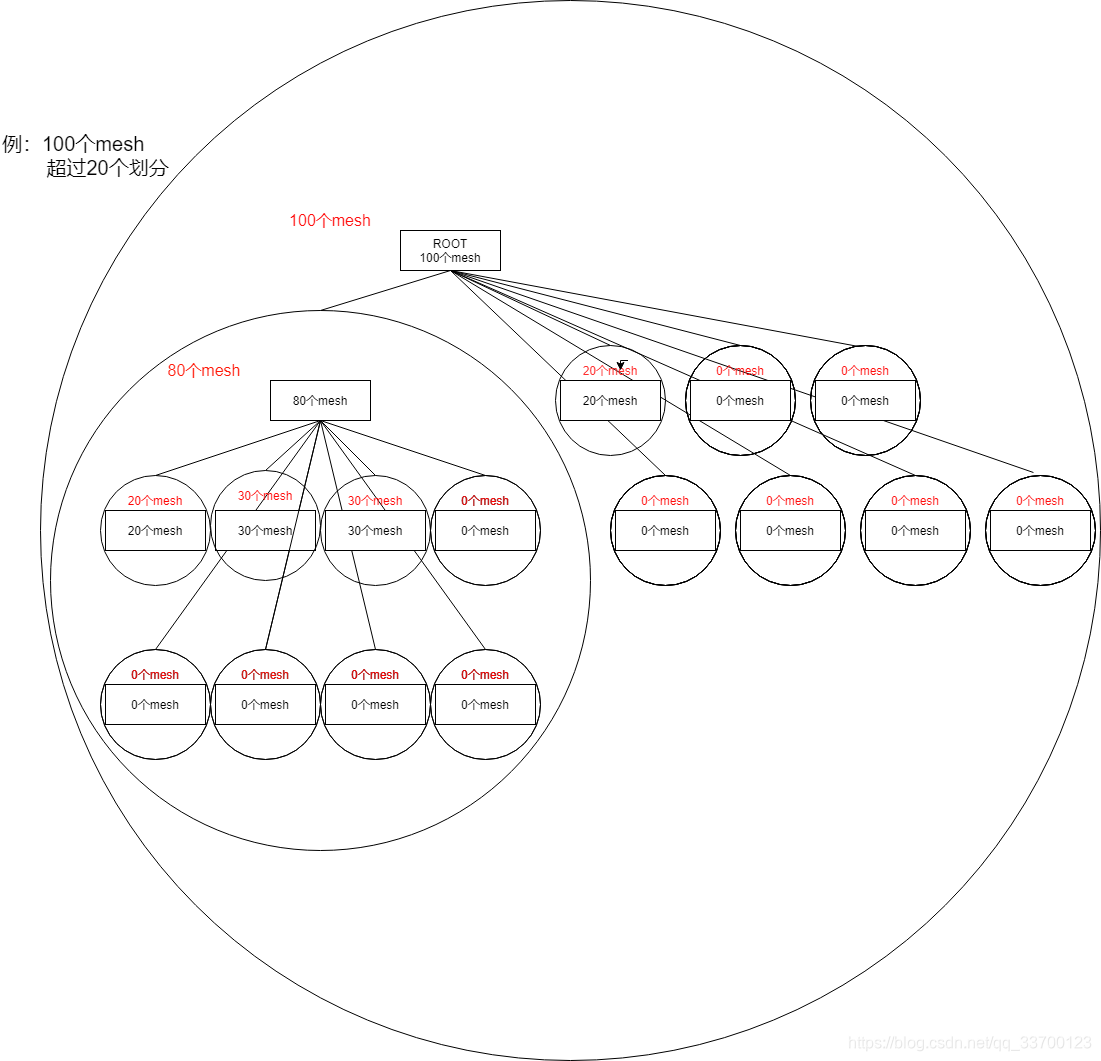
划分后效果如图所示。

这里划分方式对AutoLOD进行了改进,AutoLOD划分方式如下图所示,下图是BVH划分的同一级别中其中的4个区域,圈内是一组LodGroup,AutoLOD在进行BVH划分规则是只要该组LodGroup有任何模型与区域接触,那么该组LodGroup就会被算入该区域,图中4角星与2、3、4区域同时有相交,因此在模型合并的时候这3个区域都会将该组LodGroup下的模型合并。假设HLOD切换到了该层级且同时显示2、3、4节点的合并模型,那么这个LodGroup合并的模型就会被显示了3份,这样的效果是不允许的,解决办法就是同一个层级每个区域不能出现相同的LodGroup。
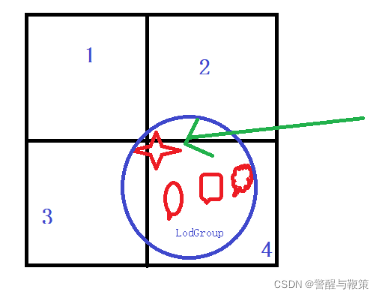
本次HLOD采用的解决办法是使用LodGroup的中心点进行划分,这样就可以保证一个LodGroup最多能被一个区域包含,如下图所示,箭头指向的点就是LodGroup的中心点,它只有4这个区域包含。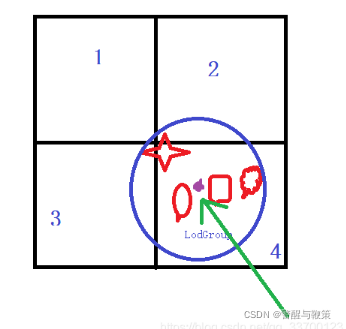
2.4 根据BVH划分进行合并模型和贴图
1.合并原理
根据2.3的划分,可以设置合并几层的模型(从最底下开始计算),如下图所示的为合并2层,其中第一层(最底层)有三个区域合并,第二层有两个区域合并。这里节点比2.3少了,是因为没用的节点会被剔除掉,如果这里设置只合并一层也就是最底层,那么上面两层也会被剔除掉。
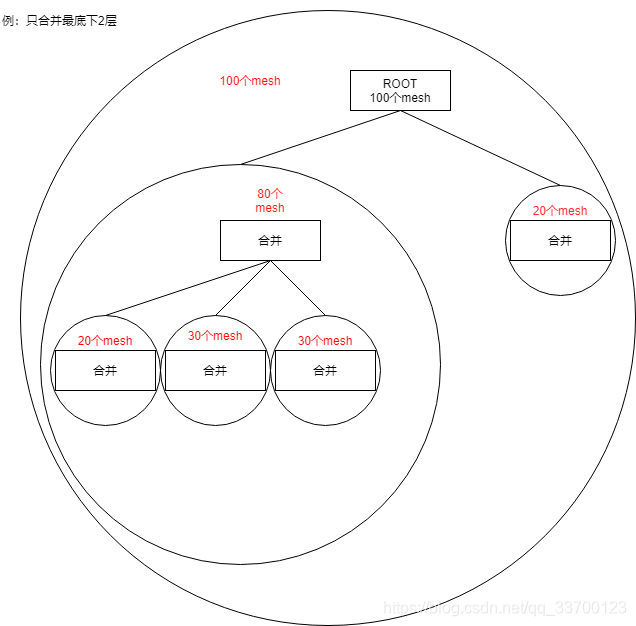
2.合并的网格
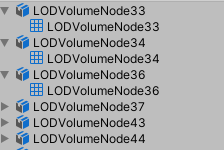
网格每生成一层就会多一倍以上磁盘大小,如果重复的模型多了,那么合并后的网格磁盘大小将会成倍增加,合并后的网格如下图所示。
例如:(300*300M场景),原始网格6M磁盘空间,合并原始网格两层后多出20M空间(fbx)。
3.合并的贴图
如下图,贴图目前只保留了MainTex贴图,默认使用Standard物理光照shader(带阴影),支持GPU Instancing。
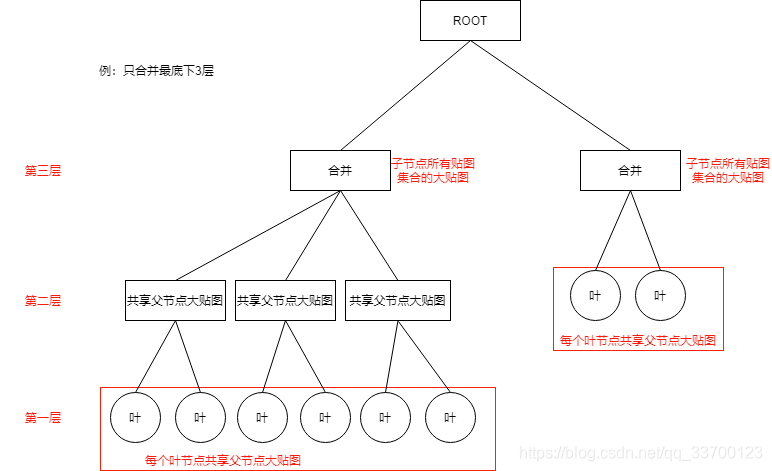
贴图合并规则如下图所示,设置合并层次,比如图中设置3层,那么第三层是所有子节点合集的大贴图(不重复)。
例如:300*300M场景,原始贴图大小26M,合并原始网格两层后多出50M,多出这么多主要是因为把整个场景合并,原始贴图很多是共用的,导致合并后内存上升问题,所以合并时选择模型和贴图复用性低的模型合并比较好。
2.6 HLOD CULL系统
1.如何工作
当上述步骤做好后,在BVH的根节点上会有个HLOD CULL脚本,用于控制当前管理的HLOD的切换。
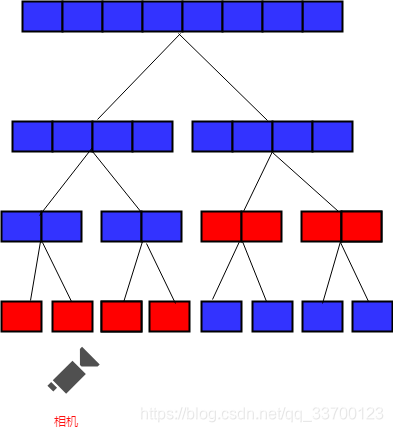
当摄像机靠近部分精细模型时,HLOD切换状态如图2-10所示(红色为当前显示的层级,蓝色为不显示层级)。

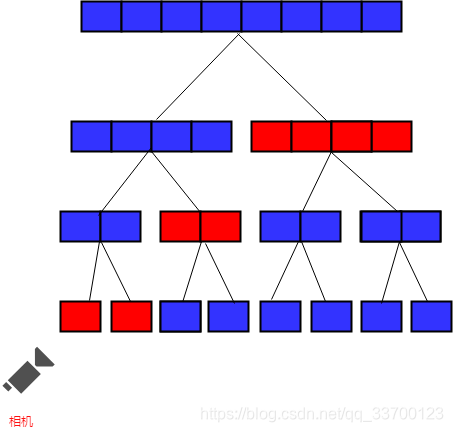
当摄像机靠近少部分精细模型时,HLOD切换状态如下图所示。

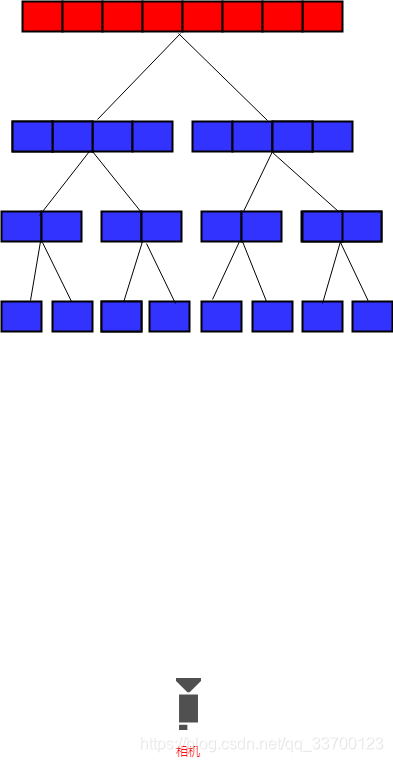
当摄像机距离精细模型比较远时,HLOD切换状态如图2-12所示。

2.计算原理
首先是精细度模型是否需要显示计算,根据距离LOD Group的距离、屏幕占比与摄像机FieldOfView计算出relativeHeight,这个数值对应如图2-14所示的摄像机位置,如果这个数值不指向最精细模型,那么就显示合批模型。size取物体在世界坐标下所有物体叫起来包围盒大小。
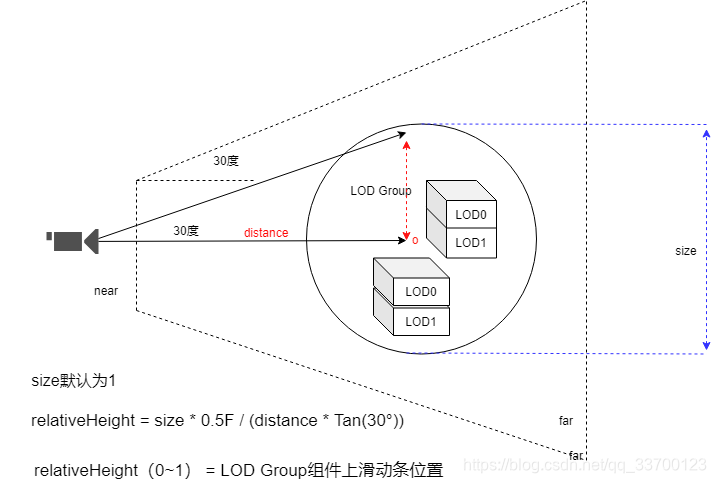
relativeHeight表示
3.工作原理
如图2-15所示,LODGroup的计算只会计算最精细的模型,只要有一个精细模型被激活那么该节点的精细模型都会被激活,父节点的所有HLOD被dirty并隐藏。如果精细模型不激活,那么直到找到父节点被dirty或已经是最顶层情况激活当前层HLOD。
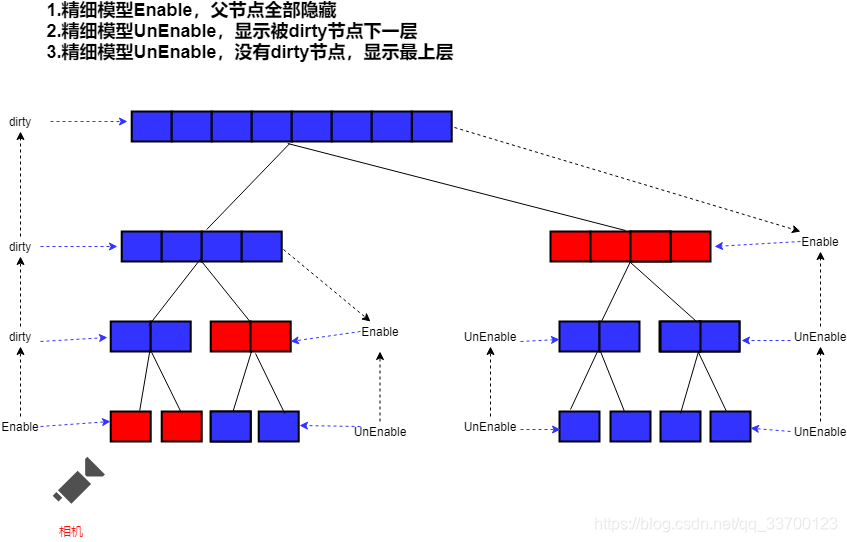
HLOD流式加载
3.1 流式系统设计
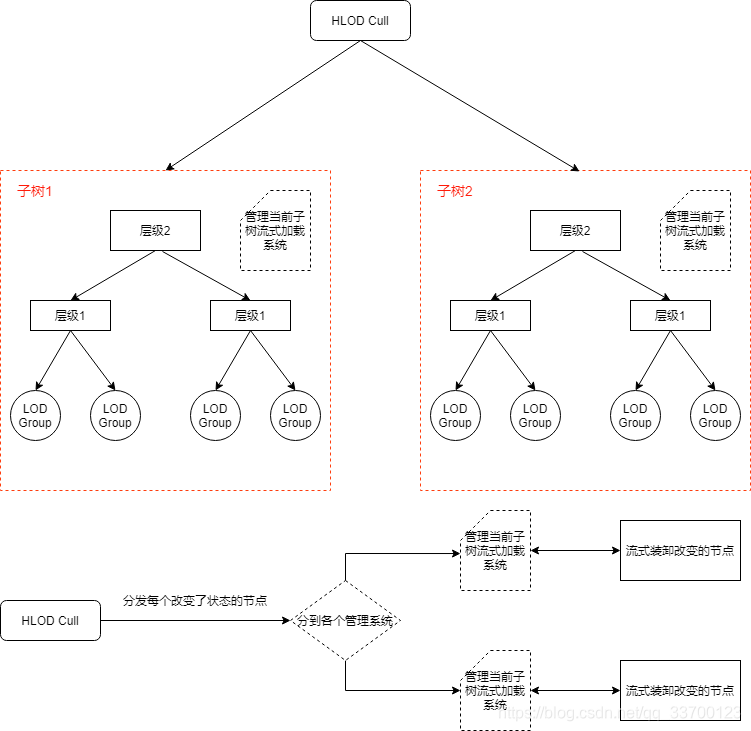
流式加载的设计主要针对移动端内存占用过高问题,利用流式加载可以做到极大降低移动端运行常驻的内存。设计如图3-1所示。
首先,一个HLOD System里面有多颗子树,每颗子树都会带有一个流式管理器,该管理器负责当前子树的所有节点流式加载,而HLOD Cull系统负责通知每颗子树哪些节点状态出现了变动。
3.2 流式资源加载设计
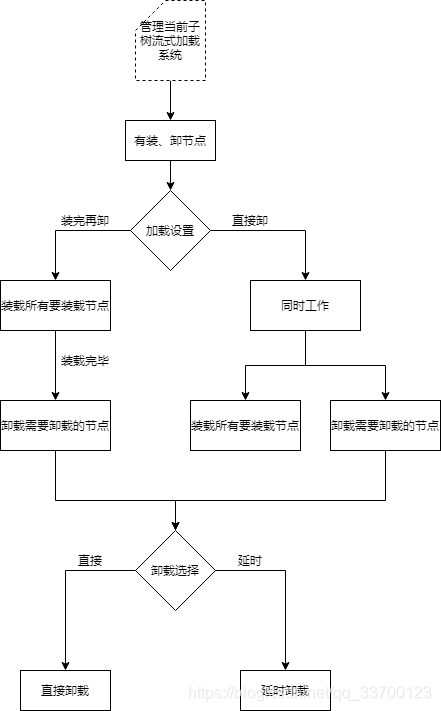
如下图,流式加载有两种模式,经过大量测试,总结出了各自优缺点。
1.装完再卸载
当前子树下,所有需要加载的节点加载完毕后再卸载需要卸载的。
优点:可以保证模型常在视区
缺点:经常会出现内存峰值,经常会卡帧
2.直接卸
当前子树下,卸载不等待其他节点加载完就卸载
优点:极大避免卡帧问题,少许出现内存峰值问题。
缺点:不可保证模型常在视区,加载的模型内存大可能会出现闪烁现象。
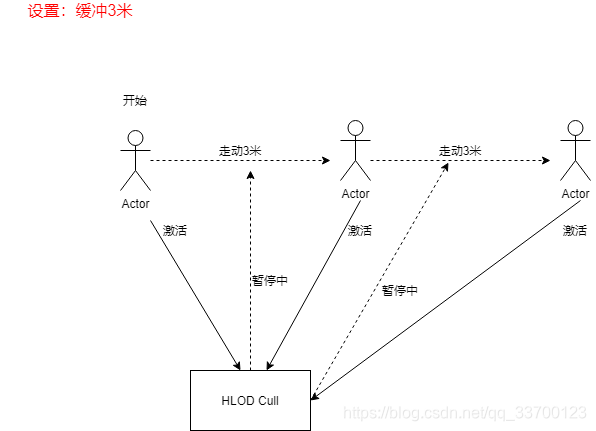
3.3 流式加载距离缓冲设计
经常会出现玩家在加载边沿处来回走动,这会造成资源不断的来回装卸,因此加入距离缓冲策列。
设定一定距离的缓冲,当触发流式切换后,要再次激活流式切换需要走出设定的缓冲距离才会切换,设计如图3-3所示。
四、适用
HLOD Stream应用场景:
1.大城镇,很多房屋需要处理很多Bathces的情况
2.需要看得远,远处看得见轮科且数量较多的情况使用
3.物件密集并且无法使用GPU Instancing的地方使用
4.只要有很多Batches的地方而无法优化掉的都可以考虑使用
五、问题
1.贴图合并只保留MainTex贴图,默认使用Standard物理光照shader(带阴影),支持GPU Instancing。
2.相同的预制体的网格合并时内存会翻倍(这个跟静、动态合批一样)
3.每生成一层HLOD所需要的网格内存会多一倍以上
4.不同子树相同贴图会出现重复贴图合并现象。
5.没有实现按照材质球合并
///
Unity HLOD System(官方插件)详细解析
源码链接:https://github.com/Unity-Technologies/HLODSystem
未来官方HLOD会出现在Package Manager上,官方说的。
二、功能与支持
模式
常规HLOD:简单合并、按照材质球分类合并
TerrainHLOD:针对地形生成HLOD
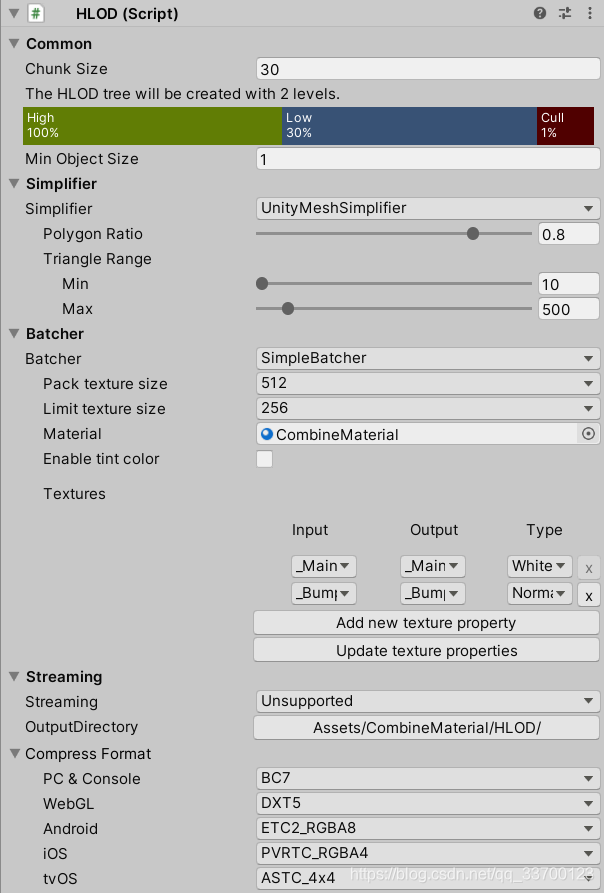
HLOD管理脚本如图
ChunckSize:模型划分时区域模型数量超过时分割子节点
The HLOD treew will be created with 2 levels:生成时设置运行时切换点
MinObjectSize:剔除小于该值的物体加入HLOD System
Simplifier:在生成HLOD节点的时候会减面,见面会根据HLOD层级递增
Batcher:
Batcher:SimpleBatcher(简单合并)、MaterrialPreservingBathcer(按材质球合并)
Streaming:
Streaming:Unsupported(默认常驻内存)、AddressableStreaming(使用新AB方式进行流式加载)
CompressFormat:合并的大贴图将会设置的格式。
简单合并
作者上篇文章自己写的hlod是只有简单合并的功能,简单合并就是将模型根据4或8叉树分割,然后根据分割的每个部位合并,不同材质球不同贴图将会被合并成一张大贴图供一个材质球使用,所以简单合并会多出合并的大贴图和新创建的材质球,大贴图是增加内存的主要原因。
按照材质球合并
与简单合并不同的是,在对每个HLOD节点合并的时候,会将该节点相同材质的模型合并成一个模型,这样合并后的模型不需要创建材质球和贴图就可以直接用已有的材质球,每个节点会出现合并的模型1到n个。
TerrainHLOD
BoderVertexCount:地形按照多大的尺寸切割
针对地形H官方用了另外一个脚本管理,官方是将地形切割成多块并转成Mesh,然后原理与简单合并一样进行。

三、技术解析
技术主要点:mesh划分、mesh合并、如何运行、流式加载。
我会按照顺序从生成到运行一一解析。
Mesh划分
首先划分是以四叉树进行划分,划分的物体类型分为两种:单纯的mesh、LodGroup,
单程的mesh计算单位就是它的包围盒大小,LodGroup计算单位就是将所有mesh作为一个整体生成一个刚好把它们包围的包围盒作为计算单位。
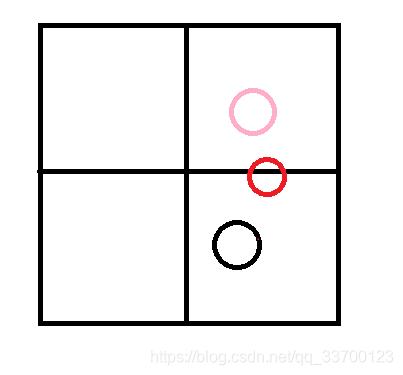
在划分的时候首先将所有有效mesh作为一个整体生成一个最大的包围盒,然后将被完全被这个包围盒包裹的单位添加进去,当数量超过设定的最大值时四叉树分割子节点,以此类推不断递归直到分完。
如图,粉红色和黑色圈因为完全被各自区域包裹所以被加入到该节点,因为父节点是这4个节点的集合大小,理所当然所有父节点也包含了它们。红色的这种其实已经被父节点包裹了,在子节点下是不可能有任何节点会完全包裹住它,所有红色的在出现与节点交叉的时候注定不会再被分到之后的子节点。
Mesh合并
在mesh被划分好后就对每个区域进行合并。
简单合并:将区域里所有模型合并成一个大模型作为这个节点的模型,贴图也合并成一张大贴图并创建一个新的材质球,在这里如果设置了减面,那么合并的模型将会被相对减面。
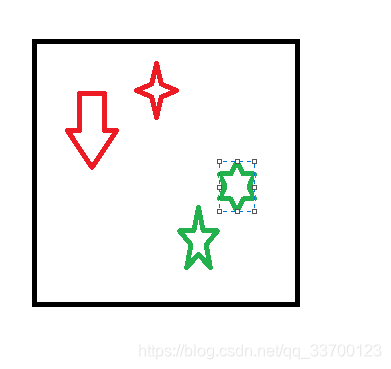
按照材质球合并:如图两个圈分别是分别是质球的模型,那么就合并成2个大的mesh,并将旧的材质球分别赐予,这种合并节省了内存。
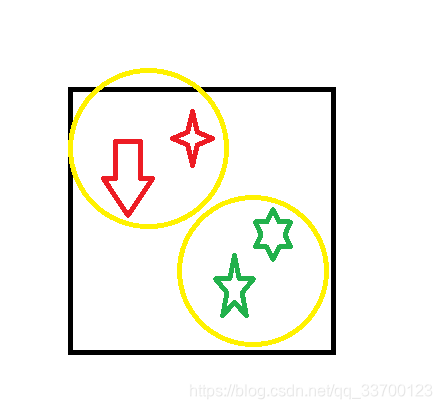
如何运行
在上述mesh生成的时候,在每个节点生成后会计算该节点的包围盒大小并设置成该层切换大小。

在运行的时候,HLOD会从根节点计算,如果超过上图High 100%那么就切换成子节点(这种计算依据跟LodGroup一样,算法也一样),在区间则显示本层,如果小于30%区间将会显示父节点,小于1%只有最大的节点才有效,因其他节点都有父节点,当到30%的时候就已经切换了父节点,而最大的节点没有父节点就不会切换,直到Cull。
如下图:
第一层已经完全超过了100%,因此往下递归
第二层右边由于相机离得远还没有超过100%因此不切换显示本层
第二层左边相机靠得比较近,最左侧一直递归直到递归到了根节点,右侧在倒数第二层由于该节点的包围盒计算的时候没有超过100%,因此截至到该层。
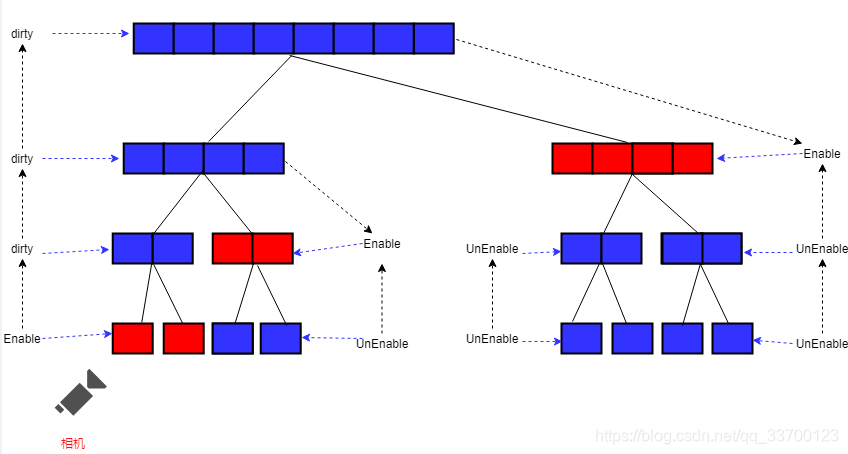
流式加载
流式加载运行计算与上述一样,区别在于资源全部都是使用Addressables在异步做着资源的不断流式切换。
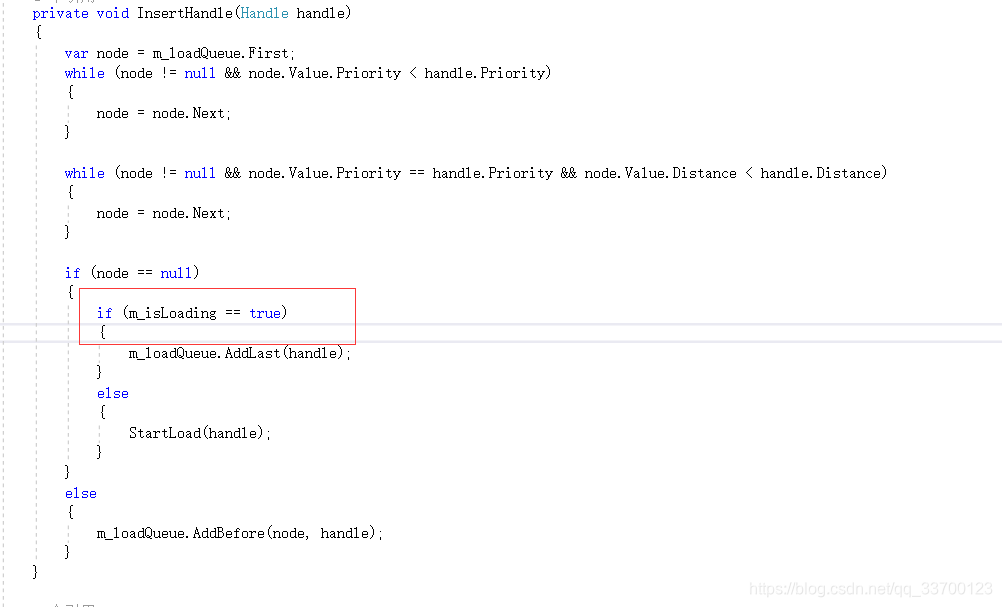
流式切换的时候由于加载资源需要一些时间,因此官方做了在资源完全加载出来后才能切换,保证不会出现闪烁,且官方考虑到一次性大量切换导致卡顿问题,因此官方限制了只能一个一个加载,一次性加载多少数量并没开放,从代码中可以看到在加载一个资源的时候m_isLoading被设置成false,直到加载完才设置成true,在true的时候其他资源先在队列里等待。

三、实际使用种的扩展
资源
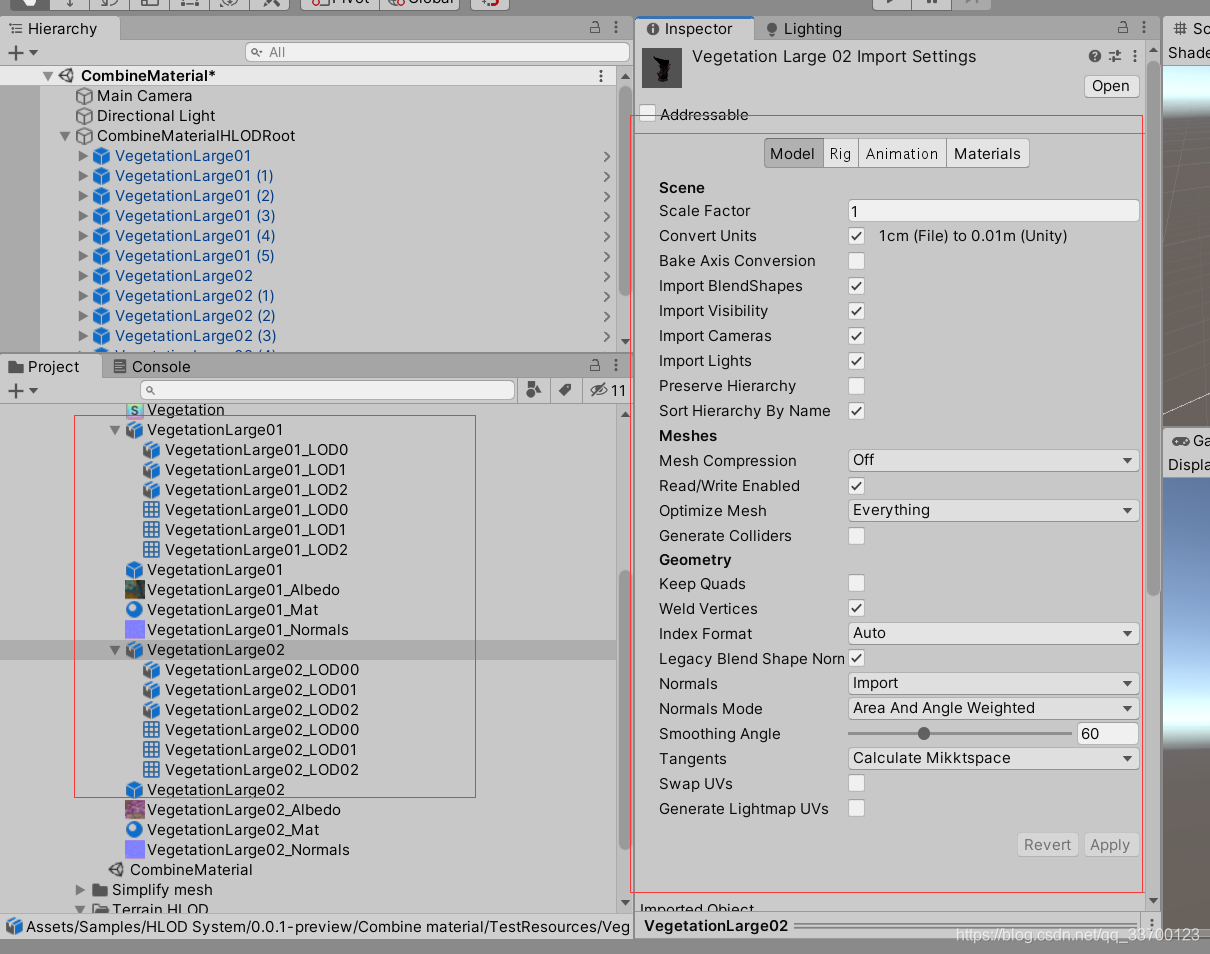
这里就要提到官方生成出来的资源到底长得什么妖魔鬼怪了,如图所示。
作者:大吃一惊,我。。。,二个月前生成出来的还是原始mesh,现在竟然改成了fbx,本人费劲九猫二鼠之力才改成fbx的,现在官方竟然也改了,我不服啊(提示:这里官方没修改,是作者本地自己修改了忘了还原以为是官方的,作者已转UE4,也不做本章博客更新了。。)。
之前官方没改的时候由于是原生mesh没经过压缩,因此会很占用磁盘空间的哦。
流式加载方式
作者还是留了一手,这是官方没有做的哈哈哈。
官方的流式加载是需要Addressables支持的,在实际项目很多有自己的资源管理方式,比如传统的AB模式,因此呀,我这就介绍下如何魔改扩展。
1、复制粘贴这个脚本改名成自己的名字

2、在这个脚本上看到了流式资源加载的来源地方,只要把这个资源来源换掉就好啦。
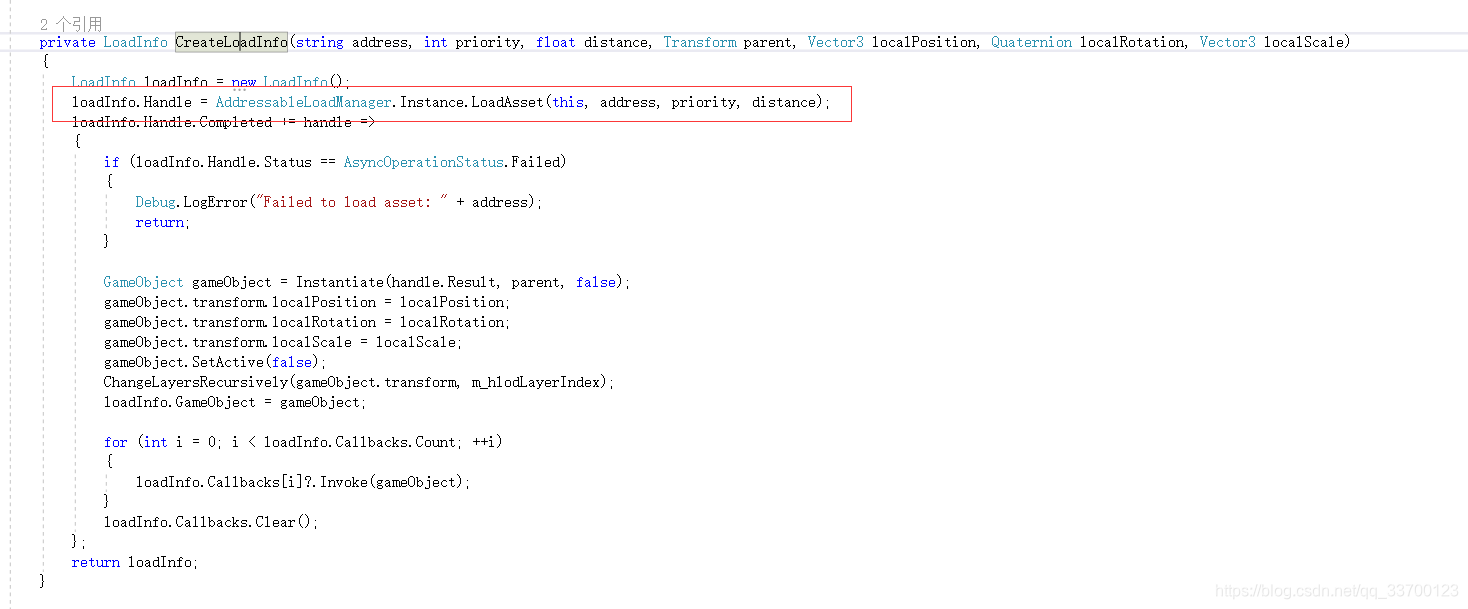
3、为了让unity的代码不要浪费,我就继续套娃下去,进去看看这个脚本在做什么。

4、这不是之前贴过的代码嘛,没错,就是的。这里上面有一点没有说,在每个资源被加进来时候都会根据自身的权重与队列里的所有等候者权重对比,权重越靠近0的越先被加载,因此怎么添加如代码所示。
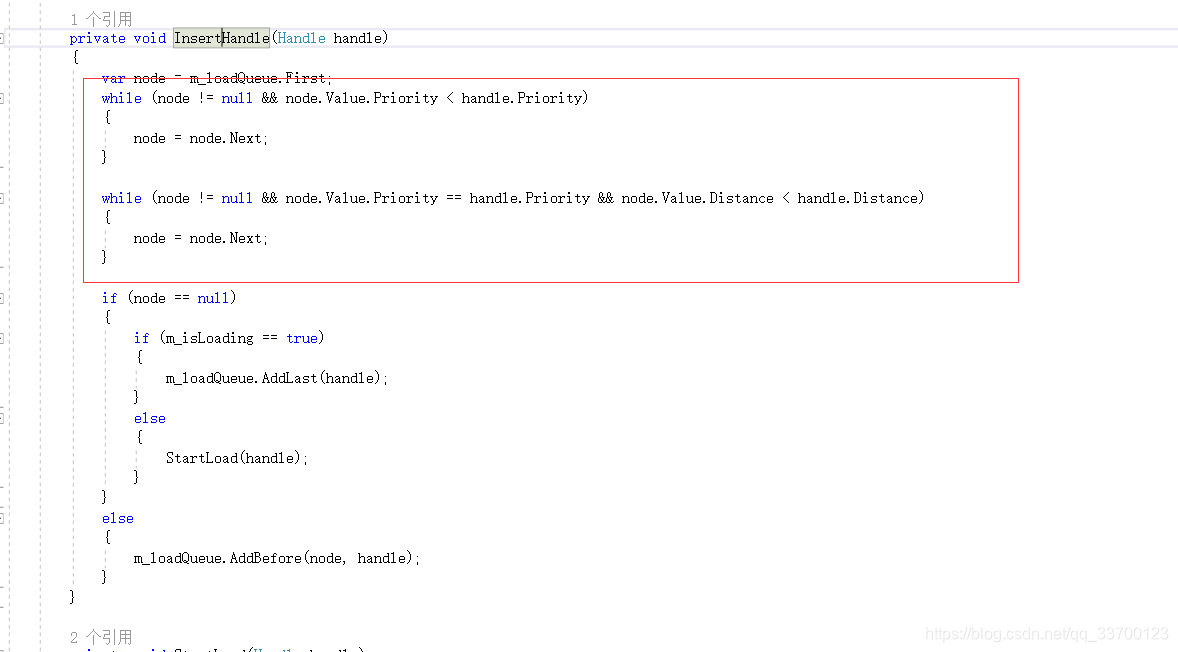
5、还是在当前脚本,找到如下代码,这里就是Addressables加载资源的根处,我们只要把这个改成自己加载资源的接口,这样就ok啦。

6、在生成HLOD的时候,设置的一些相关属性的时候会将数据设置到这个脚本。

当自己复制了这个脚本做了自定义的时候把它的Editor脚本也相应自定义,在这个脚本上对应一下这个脚本修改,当然官方的Addressables有很多操作是将资源加入Addressables Groups里以便运行能正确加载,代码都在这个脚本Build方法里,这里就需要将这些操作改成将资源地址写入到运行脚本上,这里操作比较多我就不再赘述了,思路说出来了就ok。
五、改进的地方
1、官方HLOD每颗HLOD树都是所有节点都会合并,这就导致一个场景要分很多HLOD树。而作者的HLOD是可以整个场景生成一个HLOD,设置合并层,假设设置合并最底层3层,那么最终只会合并最底下3层,相当于官方HLOD创建了N颗树。
2、由于每颗树都是在不断遍历,因此可以适当加点条件,比如移动了,相机转动了才计算,可以把递归改成非递归
3、如果场景HLOD树的量很大,就像作者的那样,一颗大树生成下面有好多的子树,由于HLOD计算的算法都是一毛一样,这样那么多树是可以并行计算的,那么就可以试着把并行计算改到JobSystem上计算,这样这部分计算消耗就不用担心了。

















 2433
2433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









