










关于主成分分析(Principal Component Analysis PCA)的简介:
PCA主要是用来进行数据降维的。
将N维数据(有着N个列的表格)转换为有N个成分的数据(也是一个N个列的表格)。
这里的每个成分都有一个特征值,特征值越大的成分,对数据信息的包含性越高。一般将特征值最高(方差最大)的前几位称为主成分。
对经过模拟的体系轨迹进行PCA,得到PC可以表现体系经历的一些运动,PC1(特征值最大的主成分)可以表示体系经历的主要运动。
需要记住的重要一点是,虽然PCA有助于深入了解系统的动态特性,但在整个仿真过程中,系统的实际运动几乎总是各个PC的组合。因此,虽然单个PC的运动可能会显示一个转变,但这通常并不是系统如何经历这种转变的。
1.计算轨迹坐标的协方差矩阵(covariance matrix):
关于协方差矩阵:
对于一个有1000个原子的构象,得到其100帧的轨迹,计算得到的协方差就是一个1000*1000的矩阵。
向cpptraj中导入top和nc:
#打开cpptraj:
[f@FF tyr]$ cpptraj
CPPTRAJ: Trajectory Analysis. V5.1.0
___ ___ ___ ___
| \/ | \/ | \/ |
_|_/\_|_/\_|_/\_|_
| Date/time: 06/13/22 22:30:18
| Available memory: 86.155 MB
#导入top,赋予标签p1:
> parm tyr.prmtop [p1]
#导入轨迹,让轨迹对应标签为p1的top文件:
> trajin tyr.trr parm [p1]
消除转动和平动,对齐构象:
由于在模拟过程中会出现一些转动和平动,这些是不必要的信息,我们要将结构帧对齐,去掉这些存在的平动和转动。用轨迹的第一帧(first)为对齐参考文件,进行对称:
好像用rms命令进行对齐后保存的轨迹也不会对齐耶(是我的操作有误吗???)
amber20手册中rms命令的介绍:
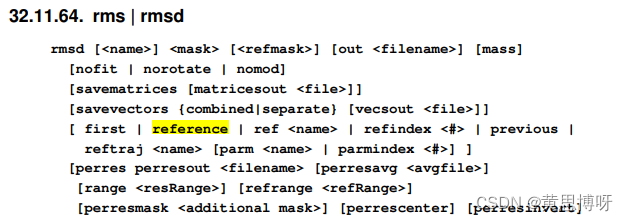
#这个轨迹有264个残基
#计算rms,同时参考坐标为轨迹第1帧first,对齐1~264残基中非H的原子,输出为数据集rms-data:
> rms rms-data :1-264&!@H= first计算轨迹的平均构象:
amber20中对average命令的介绍:

#采取轨迹中所有frame,计算轨迹的平均构象,将其保存为数据集average-dat
> average crdset tyr-average-dataset
> run 建立轨迹坐标数据集,利用平均构象的数据集对前者进行对齐:
#建立一个坐标数据集,里面整合导入的轨迹文件数据:
createcrd tyr-trajectories-dataset
#不加上run,就不会将frame读到数据集里,下一步的crdaction就不能进行:
run
#利用之前得到的平均结构数据集进行对齐:
crdaction tyr-trajectories-dataset \
rms ref tyr-average-dataset :1-264&!@H=
计算协方差矩阵:
amber20手册中对matrix命令的介绍:
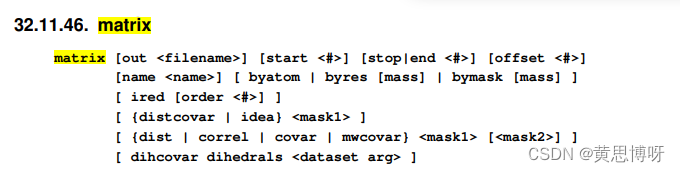
#计算协方差矩阵,样本从第1帧到到第100帧,隔5帧取一帧
#输出到文件covar.dat中,保存为数据集covar-dataset
> crdaction tyr-trajectories-dataset \
matrix out covar.dat start 0 end 99 offset 5 name covar-dataset covar :1-264&!@H=2.计算对角线相关性矩阵得到前3个特征向量以及特征值(eigenvectors and eigenvalues):
关于命令diagmatrix的介绍:
diagmatrix命令可以从输入的matrix数据中计算出需要的特征值和特征向量

#利用生成的covar-dat数据集,计算前3个主成分
#保存为数据文件evecs.dat,保存为内存数据集evecs-dat
#nmwiz输出的文件可以用于VMD插件进行可视化:
> crdaction tyr-trajectories-dataset \
runanalysis diagmatrix covar-dat out evecs.dat vecs 3 name evecs-dat \
nmwiz nmwizvecs 3 nmwizfile tyr.nmd nmwizmask :1-264&!@H=这样,我们得到一个包含前三个特征值和特征向量的数据文件evecs.dat
evecs.dat文件的格式:
Eigenvector file: <Type> nmodes <#> width <width>
<# Avg Coords> <Eigenvector Size>
<Average Coordinates> #记录的结构平均构象的笛卡尔坐标数据 N*3个
**** #不同数据区域的分隔符号
<Eigenvector#> <Eigenvalue> #特征值的序号及特征值
<Eigenvector Coordinates> #特征向量坐标数据 N*3个
...3.diagmatrix命令中选项reduce的作用:
一个有N个原子的构象,得到一个N*N的协方差矩阵,这里的每个原子都有在X,Y,Z三个方向上的坐标分量。算出一个特征值和特征向量E,这里的E=(E1,E2...En),n=N。这里的每个Ei都要考虑坐标分量,添加reduce选项,Ei=Xi^2+Yi^2+Zi^2,最终的Ei只有一个数据。若是不加上reduce,Ei=(Xi,Yi,Zi),最终的Ei是有三个数据,一个特征向量的数据量有N*3个
简单的说,reduce,就是多添加了Ei=Xi^2+Yi^2+Zi^2这一步。
利用nmwiz+VMD,将主成分映射到轨迹上,捕捉轨迹中的主要运动
利用diagmatrix命令中的nmwiz选项,我们得到一个tyr.nmd文件,用vmd的【Analysis】中的【Normal Mode Wizard】打开这个文件,可以得到根据前3个PC映射在原来轨迹后得到的结构的主要运行动画
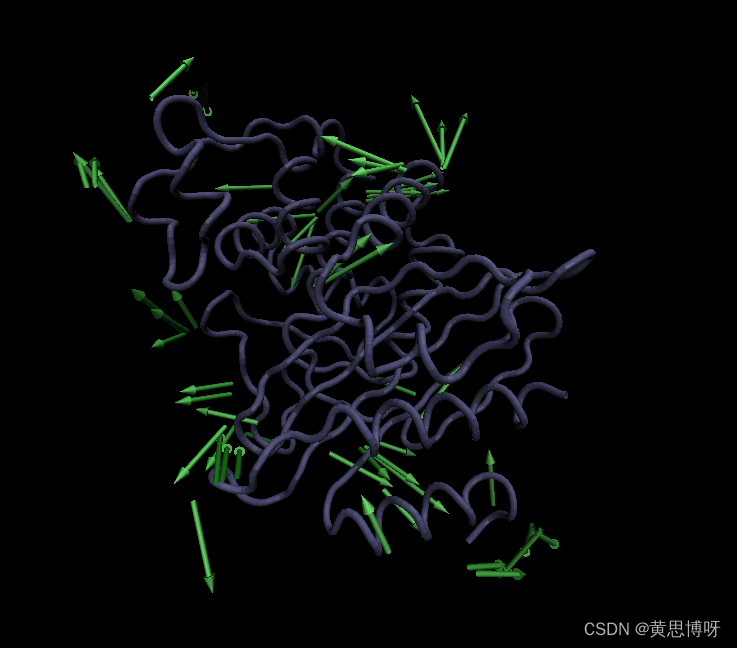
4.绘制反映各个PC匹配轨迹运动程度的分布图:
我们可以沿着PCs投影轨迹坐标(估计就是将每个PC单独投射到轨迹里,得到数量和PC数一样的轨迹),以查看每个帧的坐标沿着每个主分量“匹配”了多少。我们可以对原始单个轨迹的帧进行这样的操作,这将允许我们比较各个单个轨迹的运动匹配程度(原理是啥不懂,估计就是绘制的直方图里成分的X轴覆盖越广,运动匹配程度越高)。
#对主成分的特征向量投影到轨迹中
> crdaction tyr-trajectories-dataset \
projection TYR modes myEvecs beg 1 end 3 :1-36&!@H= crdframes 1,100
#绘制标准直方图:
> hist TRY:1 bins 100 out tyr-hist.agr norm name PC-1
> hist TYR:2 bins 100 out tyr-hist.agr norm name PC-2
> hist TYR:3 bins 100 out tyr-hist.agr norm name PC-3
#运行:
> run运行计算后得到一个包含前三个主成分的分布统计数据文件tyr-hist.agr
用xmgrace打开这个tyr-hist.agr绘制图像,保存为png格式
在[print_setup]里的[device]设置图片的输出格式:
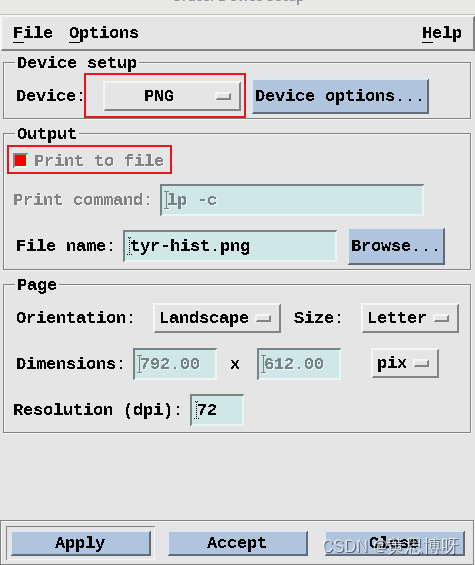
效果如下:
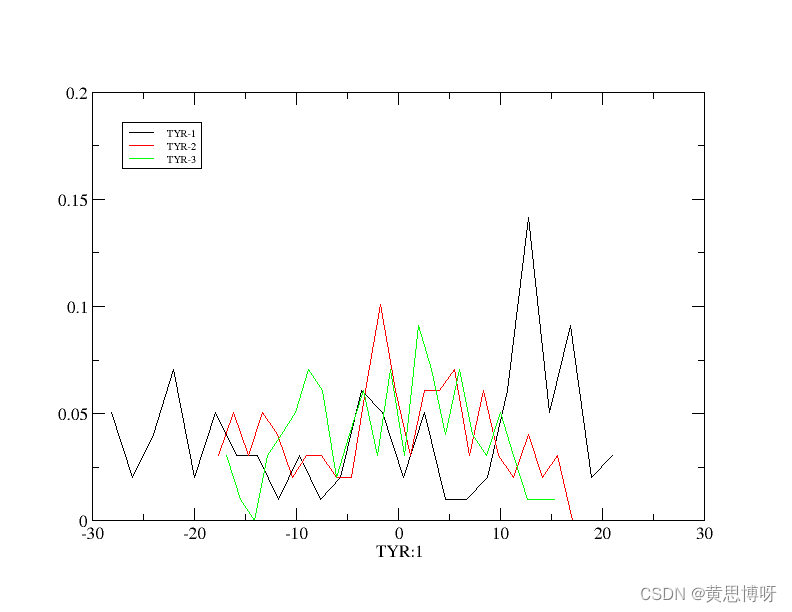
因为数据比较少,绘制的曲线不太好看,但还是可以看出图中PC1覆盖的范围最大(大概是-28到22),其次是PC2,最小是PC3。
5.输出沿PC1映射的轨迹:
除去多余的水分子和残基上的H,生成沿PC1信息运动的轨迹文件
#将所有的文件内存都清除:
clear all
#读取磁盘保存的特征向量和特征值的数据:
readdata evecs.dat name evecs
parm tyr.prmtop [p]
#除去对应tag为[p]的拓扑中水和残基里的H的信息,之后保存:
parmstrip !(:1-264&!@H=) parm [p]
parmwrite parm [p] out notwat.protmp
#具体的pcmin和pcmax查看pc的正态分布曲线的范围:
runanalysis modes name evecs trajout tyr_pc1.nc \
pcmin -28 pcmax 21 tmode 1 trajoutmask :1-264&!@H= trajoutfmt netcdf得到轨迹文件tyr_pc1.nc


















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











