







1.背景
2022年,C Zhong受到自然界白鲸行为启发,提出了白鲸优化算法(Beluga Whale Optimization, BWO)。


2.算法原理
2.1算法思想
BWO算法模拟了白鲸的行为,如游泳、捕食和鲸鱼坠落。BWO包含探索阶段和开发阶段。探索阶段通过随机选择白鲸来保证设计空间的全局搜索能力,开发阶段控制设计空间的局部搜索能力。
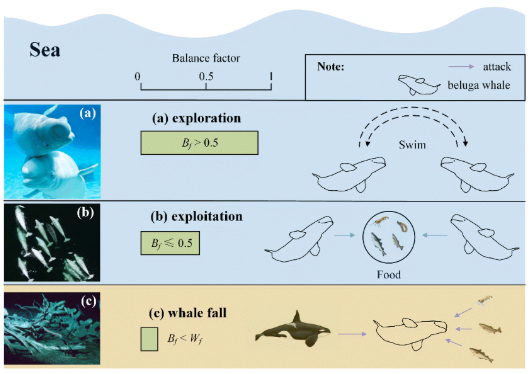
2.2算法过程
BWO算法可以根据平衡因子Bf从探索过渡到开发:
B
f
=
B
0
(
1
−
T
/
2
T
m
a
x
)
(1)
B_f=B_0(1-T/2T_{max})\tag{1}
Bf=B0(1−T/2Tmax)(1)
探索阶段
BWO的探索阶段是通过考虑白鲸的游泳行为来建立:
{
X
i
,
j
T
+
1
=
X
i
,
p
j
T
+
(
X
r
,
p
1
T
−
X
i
,
p
j
T
)
(
1
+
r
1
)
sin
(
2
π
r
2
)
,
j
=
e
v
e
n
X
i
,
j
T
+
1
=
X
i
,
p
j
T
+
(
X
r
,
p
1
T
−
X
i
,
p
j
T
)
(
1
+
r
1
)
cos
(
2
π
r
2
)
,
j
=
o
d
d
(2)
\begin{cases}X_{i,j}^{T+1}=X_{i,p_{j}}^{T}+\left(X_{r,p_{1}}^{T}-X_{i,p_{j}}^{T}\right)(1+r_{1})\sin\left(2\pi r_{2}\right),&j=even\\X_{i,j}^{T+1}=X_{i,p_{j}}^{T}+\left(X_{r,p_{1}}^{T}-X_{i,p_{j}}^{T}\right)(1+r_{1})\cos\left(2\pi r_{2}\right),&j=odd\end{cases}\tag{2}
⎩
⎨
⎧Xi,jT+1=Xi,pjT+(Xr,p1T−Xi,pjT)(1+r1)sin(2πr2),Xi,jT+1=Xi,pjT+(Xr,p1T−Xi,pjT)(1+r1)cos(2πr2),j=evenj=odd(2)
其中,sin(2πr2)和cos(2πr2)表示镜像白鲸的鳍朝向水面,根据奇数和偶数选择的维度,更新后的位置反映了白鲸在游泳或潜水时的同步或镜像行为。
开发阶段
BWO的开发阶段灵感来自于白鲸的捕食行为,白鲸可以根据附近白鲸的位置合作觅食和移动:
X
i
T
+
1
=
r
3
X
b
e
s
t
T
−
r
4
X
i
T
+
C
1
⋅
L
F
⋅
(
X
r
T
−
X
i
T
)
(3)
X_{i}^{T+1}=r_{3}X_{best}^{T}-r_{4}X_{i}^{T}+C_{1}\cdot L_{F}\cdot\left(X_{r}^{T}-X_{i}^{T}\right)\tag{3}
XiT+1=r3XbestT−r4XiT+C1⋅LF⋅(XrT−XiT)(3)
其中,LF是莱维飞行步长。
鲸落行为
少数白鲸坠落深海,滋养生物,形成“鲸鱼坠落”现象。鲨鱼和无脊椎动物聚集食用尸体,吸引毛甲壳类动物。骨骼最终被细菌和珊瑚分解。模拟鲸鱼掉落行为,选择掉落概率模拟微小变化。确保种群数量不变,通过白鲸位置和鲸落步长更新位置:
X
i
T
+
1
=
r
5
X
i
T
−
r
6
X
r
T
+
r
7
X
s
t
e
p
(4)
X_i^{T+1}=r_5X_i^T-r_6X_r^T+r_7X_{step}\tag{4}
XiT+1=r5XiT−r6XrT+r7Xstep(4)
其中r5, r6, r7为(0,1)之间的随机数,Xstep为鲸鱼下降的步长:
X
s
t
e
p
=
(
u
b
−
l
b
)
exp
(
−
C
2
T
/
T
max
)
(5)
X_{step}=(u_b-l_b)\exp{(-C_2T/T_{\max})}\tag{5}
Xstep=(ub−lb)exp(−C2T/Tmax)(5)
其中,C2为与鲸鱼下降概率和种群规模相关的阶跃因子(C2 = 2Wf×n),鲸鱼坠落的概率(Wf)计算为线性函数:
W
f
=
0.1
−
0.05
T
/
T
max
(6)
W_f=0.1-0.05T/T_{\max}\tag{6}
Wf=0.1−0.05T/Tmax(6)
流程图

伪代码

3.结果展示
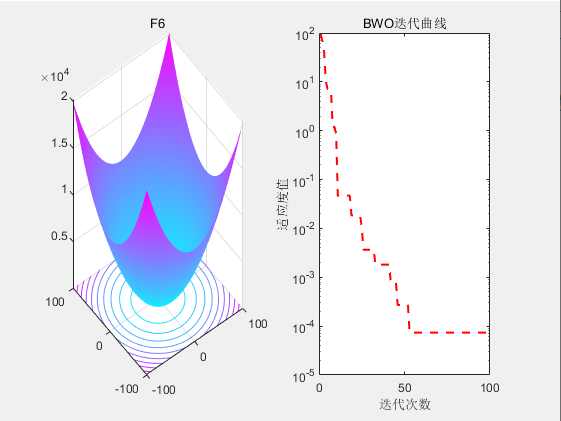
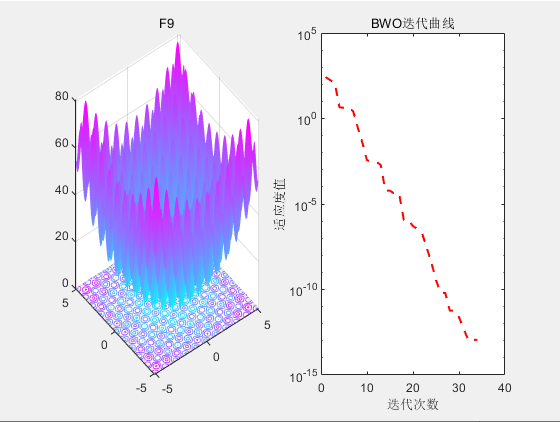
4.参考文献
[1] Zhong C, Li G, Meng Z. Beluga whale optimization: A novel nature-inspired metaheuristic algorithm[J]. Knowledge-Based Systems, 2022, 251: 109215.


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











