











1.摘要
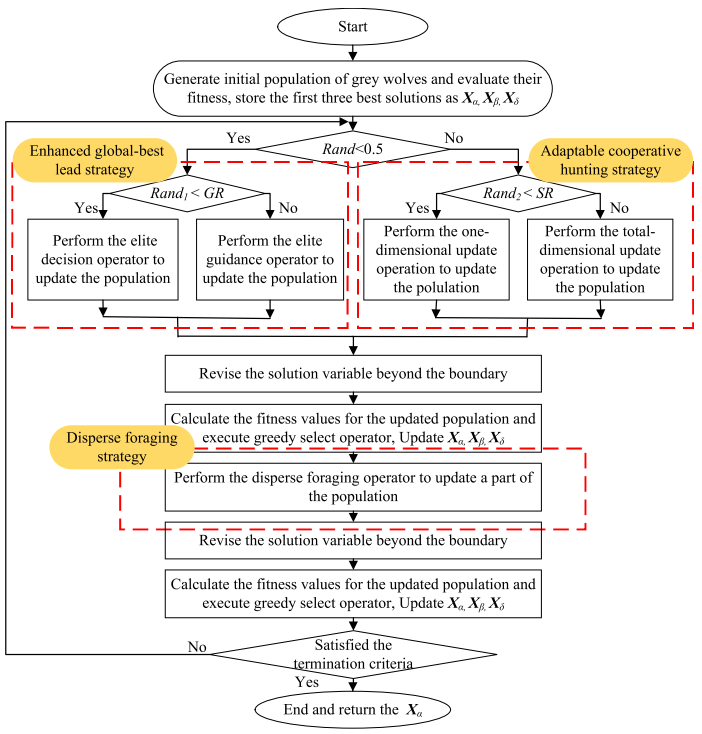
本文提出了一种多策略集成灰狼优化算法(MEGWO),用于克服传统灰狼优化算法(GWO)在解决各种函数优化问题时所面临的单一搜索策略的局限性。MEGWO算法结合了三种不同的搜索策略:1.增强全局最佳引导策略通过全面探索当前最佳解周围的搜索空间,增强了局部搜索能力;2.可适应的协同策略通过将一维更新操作融入GWO框架,提升了种群的多样性,从而加强了全局搜索能力;3.分散觅食策略则通过自适应参数引导部分搜索个体探索有前景的区域,优化了开发与探索之间的平衡。
PS:主要复现MEGWO算法~
2.灰狼算法GWO原理
3.改进策略
增强全局最佳引导策略
本文提出了一种增强全局最佳引领策略,灵感来自全局最佳和谐搜索(GHS)中的全局最佳策略。在GHS中,最佳和谐被视为全局最佳解,音调调整步骤通过随机选择最佳和谐向量中的一个元素来改进局部搜索能力:
X
i
,
d
t
+
1
=
{
X
α
,
j
a
n
d
t
,
r
a
n
d
1
<
G
R
X
α
,
d
t
+
2
⋅
φ
⋅
r
3
⋅
(
X
m
,
d
t
−
X
n
,
d
t
)
,
o
t
h
e
r
w
i
s
e
\left.X_{i,d}^{t+1}=\left\{ \begin{array} {ll}X_{\alpha,j_{and}}^t, & rand_1<GR \\ X_{\alpha,d}^t+2\cdot\varphi\cdot r_3\cdot(X_{m,d}^t-X_{n,d}^t), & \mathrm{otherwise} \end{array}\right.\right.
Xi,dt+1={Xα,jandt,Xα,dt+2⋅φ⋅r3⋅(Xm,dt−Xn,dt),rand1<GRotherwise
其中,
G
R
GR
GR表示全局最佳引导率,为[0,1]之间的常数。

适应性合作狩猎策略
灰狼优化算法(GWO)通过全维更新操作在优化非可分函数时表现良好,但对于多峰和可分函数可能无法获得高质量解。相比之下,人工蜂群算法(ABC)的单维更新操作增强了全局搜索能力,特别适用于多峰和可分函数。受此启发,本文将一维更新操作引入GWO,形成适应性合作狩猎策略。在该策略中,搜索个体根据概率SR交替采用一维和全维更新操作,从而平衡开发和探索:
S
R
=
S
R
m
a
x
−
(
S
R
m
a
x
−
S
R
m
i
n
)
⋅
t
/
L
SR=SR_{\mathrm{max}}-(SR_{\mathrm{max}}-SR_{\mathrm{min}})\cdot t/L
SR=SRmax−(SRmax−SRmin)⋅t/L

分散觅食策略
在灰狼群体栖息地发生食物短缺时,部分狼群会分散到新的区域觅食以求生存,这种分散行为增加了灰狼迁移到食物丰富区域的可能性,从而提高了在恶劣环境中的生存能力。本文提出了分散觅食策略,部分搜索个体根据分散率(DR)重新定位到搜索空间中有潜力的区域,并更新其位置:
X
i
,
d
t
+
1
=
X
i
,
d
t
+
ρ
⋅
Δ
i
,
d
t
⋅
B
i
,
d
t
Δ
i
,
d
t
=
(
X
m
,
d
t
−
X
n
,
d
t
)
\begin{aligned} & \boldsymbol{X}_{i,d}^{t+1}=\boldsymbol{X}_{i,d}^t+\rho\cdot\boldsymbol{\Delta}_{i,d}^t\cdot\boldsymbol{B}_{i,d}^t \\ & \boldsymbol{\Delta}_{i,d}^t=(\boldsymbol{X}_{m,d}^t-\boldsymbol{X}_{n,d}^t) \end{aligned}
Xi,dt+1=Xi,dt+ρ⋅Δi,dt⋅Bi,dtΔi,dt=(Xm,dt−Xn,dt)
其中,参数表述为:
B
i
,
d
t
=
{
1
,
r
a
n
d
3
>
D
R
0
,
o
t
h
e
r
w
i
s
e
\left.\boldsymbol{B}_{i,d}^t=\left\{ \begin{array} {cl}1, & rand_3>DR \\ 0, & \mathrm{otherwise} \end{array}\right.\right.
Bi,dt={1,0,rand3>DRotherwise
流程图
4.结果展示





5.参考文献
[1] Tu Q, Chen X, Liu X. Multi-strategy ensemble grey wolf optimizer and its application to feature selection[J]. Applied Soft Computing, 2019, 76: 16-30.


















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











