







在自然语言任务上取得前所未有的成功之后,Transformer已被成功应用于多个计算机视觉问题,取得了最先进的结果,并促使研究人员重新考虑卷积神经网络(CNNs)作为事实上标准操作符的优势地位。利用计算机视觉领域的这些进展,医学影像领域也见证了对Transformer日益增长的兴趣,Transformer相比具有局部感受野的CNN可以捕捉全局上下文。受这一转变的启发,在这项调研中,我们试图对Transformer在医学影像中的应用进行全面综述,涵盖从最近提出的架构设计到未解决问题等各个方面。具体而言,我们调研了Transformer在医学图像分割、检测、分类、恢复、合成、配准、临床报告生成和其他任务中的应用。特别是,对于每一种应用,我们制定了分类法,确定了特定应用的挑战以及提供解决这些挑战的见解,并强调了最新趋势。此外,我们对该领域的当前整体状况进行了批判性讨论,包括识别关键挑战、开放问题,并概述了有前景的未来方向。我们希望这项调研将在社区中激发进一步的兴趣,并为研究人员提供关于Transformer模型在医学影像中应用的最新参考。最后,为了应对该领域的快速发展,我们打算定期更新相关的最新论文及其开源实现。本文发表在Medical Image Analysis杂志。
亮点
• 这是第一个全面涵盖Transformer在医学影像领域应用的综述,覆盖了125多篇相关论文。
• 调查了Transformer在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的应用。
• 对于每个应用,我们制定了分类法,强调了特定任务的挑战,并基于所回顾的文献提供了解决这些挑战的见解。此外,我们对该领域的当前整体状态进行了批判性讨论,并指出了有前景的未来研究方向。
关键词:Transformer、医学图像分析、视觉Transformer、深度神经网络、临床报告生成
1.引言
卷积神经网络(CNNs)(Goodfellow等,2016; LeCun等,1989; Krizhevsky等,2012; Liu等,2022b)由于其以数据驱动的方式学习高度复杂表示的能力,对医学影像领域产生了重大影响。自其复兴以来,CNN在众多医学成像模式上展现出显著的改进,包括x光照相(Lakhani和Sundaram,2017)、内窥镜检查(Min等,2019)、计算机断层扫描(CT)(Würfl等,2016; Lell和Kachelrieß,2020)、乳房X线摄影(MG)(Hamidinekoo等,2018)、超声图像(Liu等,2019)、磁共振成像(MRI)(Lundervold和Lundervold,2019; Akkus等,2017)和正电子发射断层扫描(PET)(Reader等,2020)等。CNN中的主力是卷积运算符,它在局部操作并提供平移等变性。虽然这些特性有助于开发高效且可推广的医学成像解决方案,但卷积操作中的局部感受野限制了捕捉长程像素关系的能力。此外,卷积滤波器具有固定的权重,在推理时不会根据给定的输入图像内容进行调整。
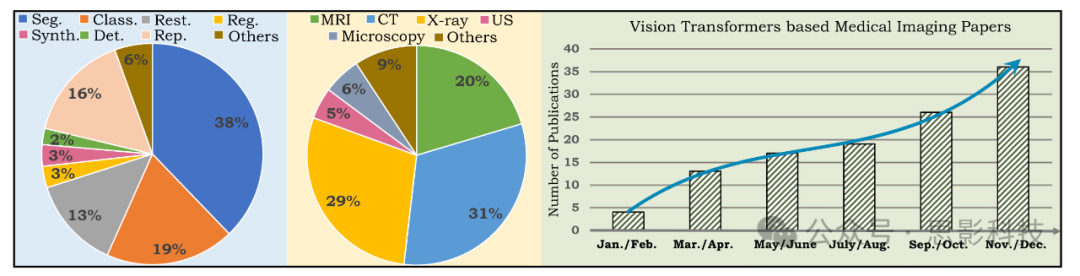
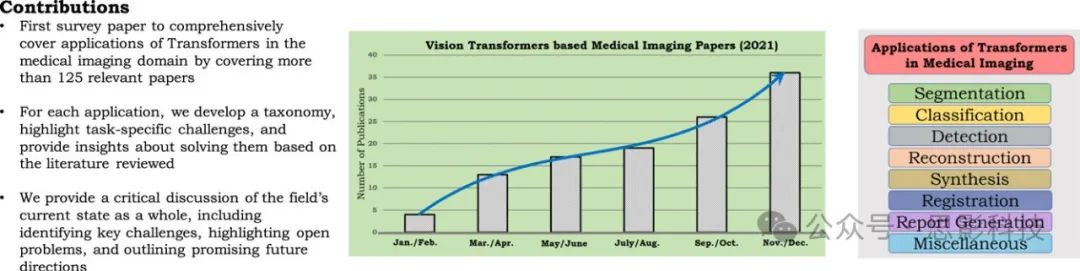
图1. (左)饼图显示了本调查中包含的论文按医学成像问题设置和数据模式的统计数据。最右侧的图显示了近期文献的持续增长(2021年)。
Seg:分割,Class:分类,Rest:修复,Reg:配准,Synth:合成,Det:检测,Rep:报告生成,US:超声。
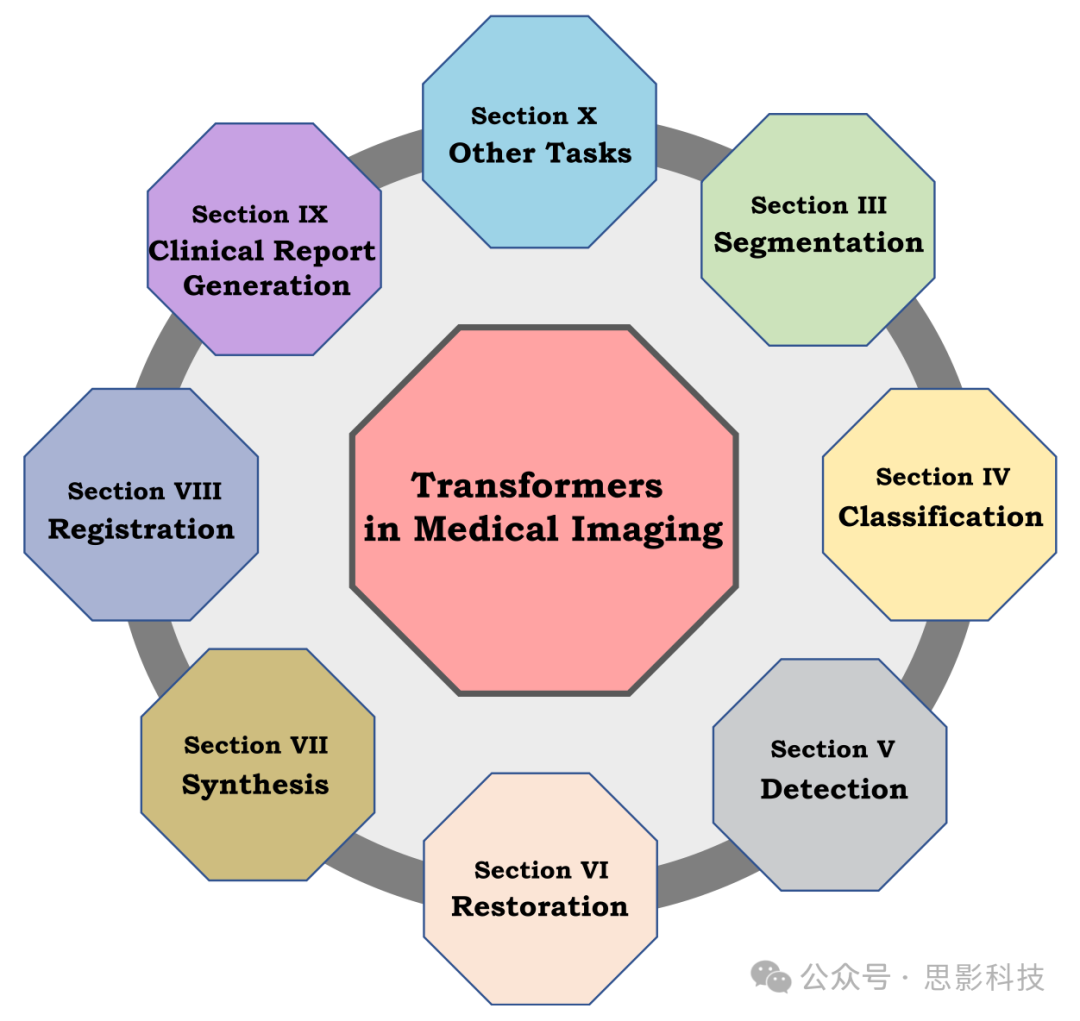
图2. 本调查涵盖的Transformer在医学成像中的多种应用领域。
同时,视觉社区已经做出了重大研究努力,将注意力机制(Vaswani等,2017; Devlin等,2018; Fedus等,2021)整合到受CNN启发的架构中(Wang等,2018b; Yin等,2020; Ramachandran等,2019; Bello等,2019; Vaswani等,2021; Dosovitskiy等,2020)。这些基于注意力的"Transformer"模型由于其编码长程依赖关系和学习高效特征表示的能力而成为一种有吸引力的解决方案(Chaudhari等,2019)。最近的工作表明,这些Transformer模块可以通过对一系列图像块进行操作,完全取代深度神经网络中的标准卷积,从而产生视觉Transformer(ViTs)(Dosovitskiy等,2020)。自问世以来,ViT模型已被证明在众多视觉任务中推动了最先进的技术,包括图像分类(Dosovitskiy等,2020)、目标检测(Zhu等,2020)、语义分割(Zheng等,2021b)、图像着色(Kumar等,2021)、低层视觉(Chen等,2021j)和视频理解(Arnab等,2021)等。此外,最近的研究表明,ViT(视觉Transformer)的预测误差比CNN更接近人类的误差(Naseer等,2021a; Portelance等,2021; Geirhos等,2021; Tuli等,2021)。ViT的这些理想特性激发了医学界极大的兴趣,将其应用于医学成像应用,从而缓解CNN固有的归纳偏差(Matsoukas等,2021)。
动机和贡献:近期,医学影像界见证了基于Transformer技术数量的指数级增长,尤其是在ViT(视觉Transformer)问世之后(见图1)。这个主题现在正在医学影像界获得更多关注,由于论文的快速涌入,越来越难以跟上最新进展。因此,对现有相关工作进行调查是及时的,以全面介绍这一新兴领域的新方法。为此,我们提供了Transformer模型在医学影像中应用的整体概述。我们希望这项工作能为研究人员提供进一步探索该领域的路线图。我们的主要贡献包括:
• 这是第一篇全面涵盖Transformer在医学影像领域应用的综述论文,从而在这一快速发展的领域中弥合了视觉和医学影像社区之间的差距。具体而言,我们对125多篇相关论文进行了全面概述,以涵盖最新进展。
• 我们根据论文在医学影像中的应用对其进行分类,如图2所示,提供了该领域的详细覆盖。对于每种应用,我们制定了分类法,突出了特定任务的挑战,并根据所回顾的文献提供了解决这些挑战的见解。
• 最后,我们对该领域的当前整体状况进行了批判性讨论,包括识别关键挑战、突出开放问题,并概述了有前景的未来方向。
• 尽管本调查的主要重点是视觉Transformer,但我们也是自原始Transformer问世以来约五年来,首次广泛涵盖其在临床报告生成任务中的语言建模能力(见第9节)。
论文组织。本文的其余部分组织如下。在第2节中,我们提供了该领域的背景,重点介绍了Transformer的显著概念。从第3节到第10节,我们全面涵盖了Transformer在几个医学影像任务中的应用,如图2所示。特别是,对于每个任务,我们制定了分类法并识别了特定任务的挑战。第11节介绍了该领域整体的开放问题和未来方向。最后,在第12节中,我们提出了应对该领域快速发展的建议,并总结了本文。
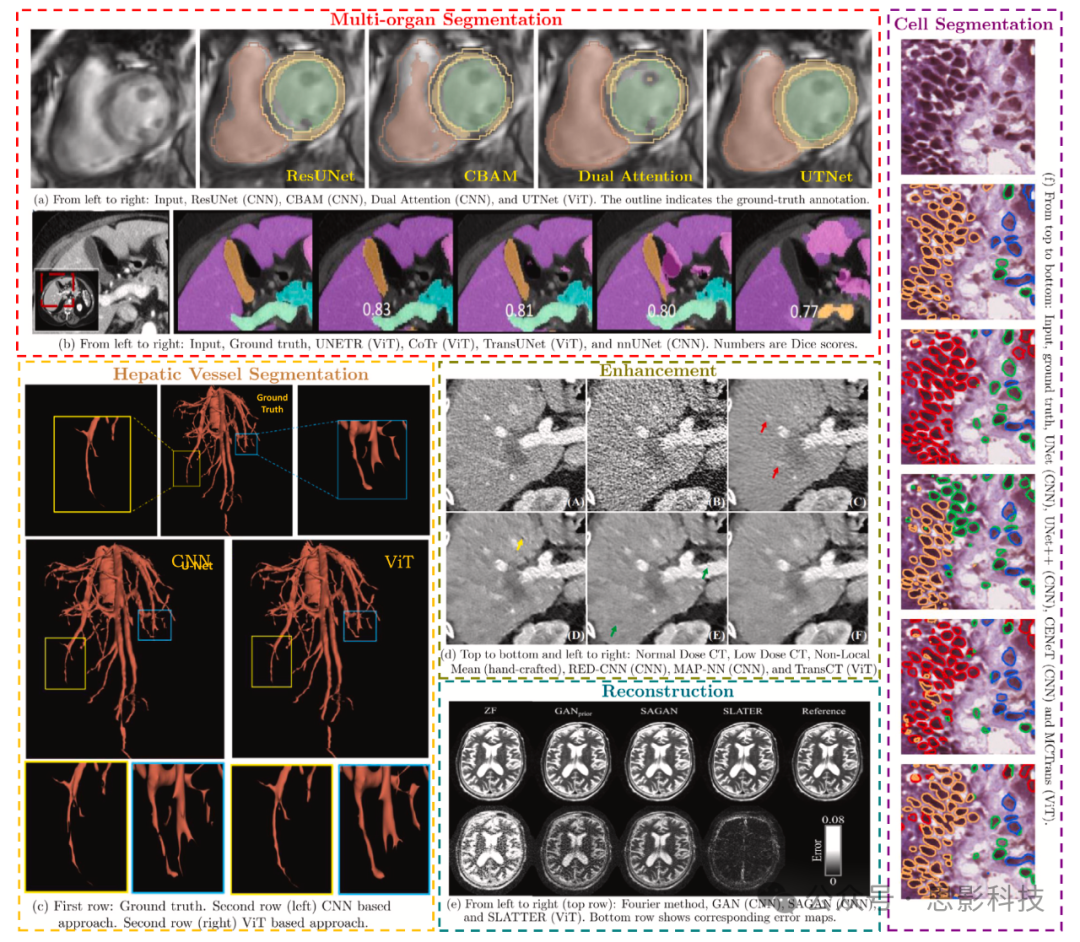
图3. ViT(视觉Transformer)在各种医学影像问题中的应用以及基于CNN的基线方法。由于能够模拟全局上下文,基于ViT的方法比基于CNN的方法表现更优。图片来源:(a) Gao等(2021c),(b) Hatamizadeh等(2021),(c) Wu等(2021c),(d) Zhang等(2021h),(e) Korkmaz等(2021a),(f) Ji等(2021)。
2.背景
医学影像方法在过去几十年里取得了重大进展。在本节中,我们简要介绍这些进展的背景,并将它们大致分为基于CNN和基于ViT(视觉Transformer)的方法。对于基于CNN的方法,我们描述了其基本工作原理以及在医学影像领域的主要优势和缺点。对于基于ViT的方法,我们强调了其成功背后的核心概念,并将进一步细节推迟到后面的章节。
2.1. 基于CNN的方法
CNN在学习判别性特征和从大规模医学数据集中提取可泛化先验方面非常有效,因此在医学影像任务上表现出色,成为现代基于AI的医学影像系统的一个重要组成部分。CNN的进步主要由新颖的架构设计、更好的优化程序、特殊硬件(如GPU)的可用性和专门构建的开源软件库(Gibson等,2018; Pérez-García等,2021; Beers等,2021)推动。我们建议感兴趣的读者参阅与CNN在医学影像应用相关的综合调查论文(Yi等,2019; Litjens等,2017; Greenspan等,2016; Zhou等,2017; Shen等,2017; Cheplygina等,2019; Hesamian等,2019; Duncan等,2019; Haskins等,2020; Zhou等,2021a)。尽管性能有了显著提升,但CNN对大型标记数据集的依赖限制了它们在医学影像任务全谱上的适用性。此外,基于CNN的方法通常更难解释,往往被视为黑盒解决方案。因此,医学影像社区越来越努力将手工制作和基于CNN的方法的优势结合起来,产生了先验信息引导的CNN模型(Shlezinger等,2020)。这些混合方法包含特殊的领域特定层,包括展开优化(Monga等,2021)、生成模型(Ongie等,2020)和基于学习去噪器的方法(Ahmad等,2020)。尽管有这些架构和算法上的进步,CNN成功的决定性因素主要归因于它们在处理尺度不变性和建模局部视觉结构方面的图像特定归纳偏差。虽然这种内在的局部性(有限的感受野)为CNN带来了效率,但它损害了它们捕捉输入图像中长程空间依赖关系的能力,从而使性能停滞不前(Matsoukas等,2021)(见图3)。这要求一种能够建模长程像素关系以实现更好表示学习的替代架构设计。
2.2. Transformer
Transformer由Vaswani等(2017)引入,作为机器翻译的新型注意力驱动构建块。具体来说,这些注意力块是聚合整个输入序列信息的神经网络层(Bahdanau等,2014)。自问世以来,这些模型在几个自然语言处理(NLP)任务上展示了最先进的性能,从而成为替代循环模型的默认选择。在本节中,我们将关注视觉Transformer(ViTs)(Dosovitskiy等,2020),它们是基于原始Transformer模型(Vaswani等,2017)构建的,通过级联多个transformer层来捕捉输入图像的全局上下文。具体而言,Dosovitskiy等(2020)将图像解释为一系列patch,并通过NLP(自然语言处理)中使用的标准transformer编码器进行处理。这些ViT模型延续了从模型中移除手工制作的视觉特征和归纳偏差的长期趋势,以利用更大数据集的可用性和增加的计算能力。ViT在医学影像社区引起了极大的兴趣,最近提出了许多基于ViT的方法。我们在算法1中以逐步方式突出了ViT在医学图像分类中的工作原理(也见图4)。
下面,我们简要描述了ViT(视觉Transformer)成功背后的核心组件:自注意力和多头自注意力。对于更深入分析众多ViT架构和应用,我们建议感兴趣的读者参考最近相关的调查论文(Chaudhari等,2019; Han等,2020; Khan等,2021; Tay等,2020; Lin等,2021b)。
| 算法1:ViT工作原理 |
|---|
| 1: 将医学图像分割成固定大小的块 |
| 2: 通过展平操作将图像块向量化 |
| 3: 通过可训练的线性层从向量化的块创建低维线性嵌入 |
| 4: 向低维线性嵌入添加位置编码 |
| 5: 将序列输入到ViT编码器,如图4所示 |
| 6: 在大规模图像数据集上预训练ViT模型 |
| 7: 在下游医学图像分类任务上微调 |
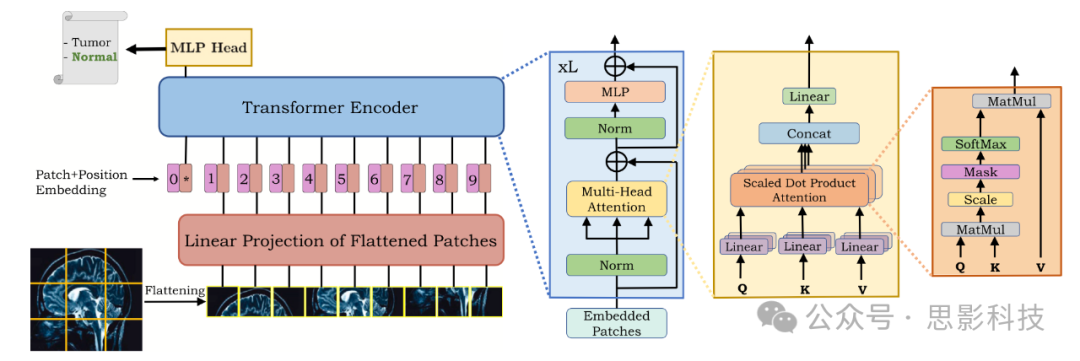
图4. 视觉Transformer的架构(左侧)和视觉Transformer编码器块的细节(右侧)。视觉Transformer首先将输入图像分割成块,并将它们(在展平后)投影到一个特征空间中,在此空间中,Transformer编码器处理这些块以产生最终的分类输出。
2.2.1. 自注意力
Transformer模型的成功广泛归因于自注意力(SA)机制,因为它能够模拟长距离依赖关系。SA机制背后的关键思想是学习自对齐,即确定单个词元(patch嵌入)相对于序列中所有其他词元的相对重要性(Bahdanau等,2014)。对于2D图像,我们首先将图像
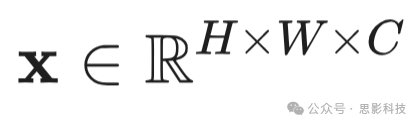
重塑为一系列展平的2D patches
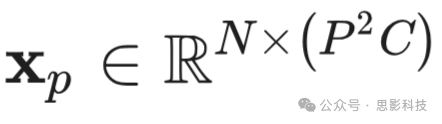
,其中H和W分别表示原始图像的高度和宽度,C是通道数,P×P是每个图像patch的分辨率,

是结果patch数量。这些展平的patches通过可训练的线性投影层投影到D维度,可以用矩阵形式表示为
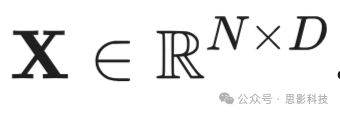
。自注意力的目标是捕捉所有这N个嵌入之间的交互ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









