







继lift-splat-shoot之后,旷视科技的BEVDepth 最近在低算力平台部署看到供应商有很多的落地了。基于 View-transformation 主流算法方法包括 LSS(Lift,Splat 和 Shoot)和 Transfomer 等:
- Transformer 方案:使用 Transformer 的注意力机制将 2D 特征融合为 BEV 视角下的 3D 特征。
- 基于 LSS 的方案:使用深度估计和相机内外参,将 2D 特征映射至 3D 空间。
综合部署难度,基于 LSS 会友好很多,很多还是卷积操作(不知道理解有没有错误)。我们今天就来看看这个可以工程化部署的方案。先从论文开始,然后看看代码。
论文信息:
repo:https://github.com/Megvii-BaseDetection/BEVDepth
paper:https://arxiv.org/pdf/2206.10092
来源:旷视
概述
提出了四个部分内容,包括:
- 深度估计模块、
- 深度微调模块去解决不精确的特征非投影所带来的副作用,
- Voxel 池化(这个应该是核心的部分:关于如何进行View Transformation)
- 多帧机制。
A camera-awareness depth estimation module is also introduced to facilitate the depth predicting capability. Besides, we design a novel Depth Refinement Module to counter the side effects carried by imprecise feature unpro-jection. Aided by customized Efficient Voxel Pooling and multi-frame mechanism,
1 介绍
BEV 表示非常重要,因为它不仅支持多输入摄像头系统的端到端训练方案,而且还为各种下游任务(例如 BEV 分割、对象检测)提供统一的空间和运动规划。
LSS(Philion 和 Fidler 2020)很好地解决了使用多视图相机进行 3D 感知的可行性。 他们首先使用估计深度将多视图特征“提升”到 3D 平截头体,然后将平截头体“splat”到参考平面上,通常是鸟瞰图 (BEV) 中的平面。
They first “lift” multi-view features to 3D frustums using estimated depth, then “splat” frustums onto a reference plane, usually being a plane in Bird’s-Eye-View (BEV).
然而,尽管基于 LSS 的感知算法取得了成功,学习深度却很少被研究。 我们问——这些检测器中学习深度的质量真的满足精确 3D 物体检测的要求吗?
我们首先尝试通过可视化基于 Lift-splat 的探测器中的估计深度(图 1)来定性地回答这个问题。 尽管检测器在 nuScenes(Caesar et al. 2020)基准上达到了 30 mAP,但其深度却出奇的差。 只有少数特征区域可以预测合理的深度并有助于后续任务(参见图 1 中的虚线框),而大多数其他区域则不然。
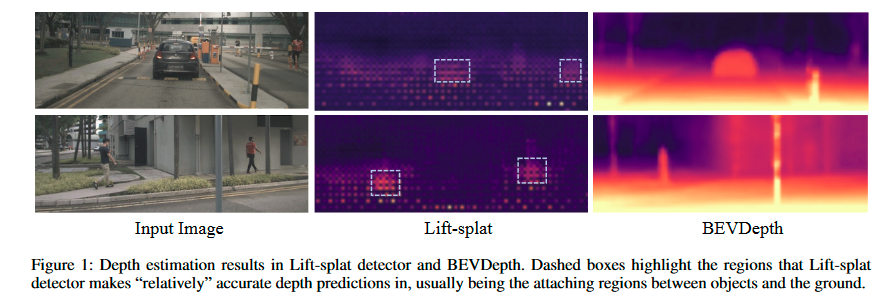
基于这一观察,我们指出现有Lift-splat中的深度学习机制带来了三个缺陷:
- 深度间接监督,质量差
- 大多数像素无法预测合理的深度,这意味着它们在学习阶段没有得到适当的训练。 这让我们对深度模块的泛化能力产生怀疑。
- 深度较差导致只有部分特征投影到正确的 BEV 位置,从而导致 BEV 语义不精确
此外,我们通过用点云数据生成的地面实况替换 Lift-splat 中的学习深度,揭示了提高深度的巨大潜力。 结果,mAP 和 NDS 均提升了近 20%。 平移误差 (mATE) 也下降,从 0.768 降至 0.393。 这一现象清楚地表明,增强深度是高性能相机 3D 检测的关键。 因此,在这项工作中,我们引入了 BEVDepth,一种新的多视图 3D 检测器,它利用源自点云的深度监督来指导深度学习。 我们是第一个对深度质量如何影响整个系统进行彻底分析的团队。 同时,我们创新性地提出将相机内部和外部编码到深度学习模块中,以便检测器对各种相机设置具有鲁棒性。 最后,进一步引入深度细化模块来细化学习的深度。
为了验证 BEVDepth 的强大功能,我们在 nuScenes(Caesar et al. 2020)数据集(3D 检测领域众所周知的基准)上对其进行了测试。 借助我们定制的高效体素池和多帧融合技术,BEVDepth 在 nuScenes 测试集上实现了 60.9% NDS,在这一具有挑战性的基准测试中达到了新的最先进水平,同时仍然保持了高效率
2 相关工作
2.3 深度估计
常见的是:
- Fu et al. (Fu et al. 2018) employ a regression method to predict the depth of an image using dilated convolu-
tion and a scene understanding module. - Monodepth (Go-dard, Mac Aodha, and Brostow 2017) predicts depth without supervision using disparity and reconstruction.
- Monodepth2 (Godard et al. 2019) uses a combination of depthestimation and pose estimation networks to forecast depth in a single frame
一些方法通过构建成本量来预测深度。
MVSNet(Yao et al. 2018)首先将成本体积引入深度估计领域。
基于MVSNet,RMVSNet(Yao et al. 2019)使用GRU来降低内存成本,
MVSCRF(Xue et al. 2019)添加CRF模块,
Cas-cade MVSNet(Gu et al. 2020)将MVSNet改为级联结构。
(Wang et al. 2021a)使用多尺度融合生成深度预测,并引入自适应模块,同时提高性能并减少内存消耗。
(Bae、Budvytis 和 Cipolla 2022)将单视图图像与多视图图像融合,并引入深度采样以降低计算成本。
2 深度LSS整体结构
在本节中,我们首先回顾一下基于 Lift-splat 构建的基线 3D 探测器的整体结构。 然后我们在基础探测器上进行了一个简单的实验,以揭示为什么我们观察到先前的现象。 最后,我们讨论了该探测器的三个缺陷,并指出了可能的解决方案。
2.1 基于 Lift-splat 构建的基线 3D 探测器的整体结构
去掉LSS 的分割头,替换成CenterPoint的检测头,就完成了整个检测器基线。由 图像编码器提前特征,深度网络估计深度(尺度是R×H×W,R 是离散距离)和图像转换(A View Transformer 实现 2D–>3D–> BEV特征 ),以及头(A 3D Detection Head predicting the class, 3D box offset and other attributes.)
2.2 简单的实验,以揭示为什么我们观察到先前的现象
我们将 Lift-splat 的成功归因于部分合理的学习深度。 现在,我们进一步研究该管道的本质,用随机初始化的张量替换深度预测的结果,并在训练和测试阶段冻结它。
结果如表 1 所示。我们惊讶地发现,用随机软值替换 Dpred 后,mAP 仅下降了 3.7%(从 28.2% 到 24.5%)。这也太惊人了吧,深度学习的网络自己有很强的修复能力,或者是这个部分的影响不是很大。
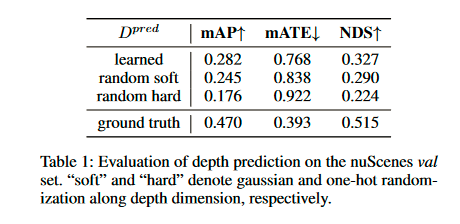
如果深度估计的模块损坏了,必然影响反投影的特征从2D->3D,如果我们采用soft 深度分布仍然可以将部分特征正确投影,但是同时也会引入很多噪声。
我们替换 soft 随机深度,采用硬随机深度(单点激活),mAP下降了6.9,验证了我们的猜想。
这说明只要正确位置的深度有激活,探测头就可以工作。 这也解释了为什么图1中大部分区域的学习深度较差,但检测mAP仍然合理。
2.3 我们讨论了该探测器的三个缺陷,并指出了可能的解决方案
包括:深度不准确(因为间接监督)、深度模块过度拟合(深度估计效果差)以及 BEV (分割)语义不精确。
为了更清楚地展示我们的想法,我们比较了两个基线——一个是基于 LSS 的简单检测器,称为 Base Detector,另一个使用基于点云数据导出的额外深度监督。
深度不准确
在 Base Detector 中,深度模块上的梯度源自检测损失,这是间接的。
因此,我们使用常用的深度估计指标(Eigen,Puhrsch和Fergus 2014)评估nuScenes val上的学习深度,包括尺度不变对数算术误差(SILog),平均绝对相对误差(Abs Rel),平均值 相对误差平方 (Sq Rel) 和均方根误差 (RMSE)。
我们在两种不同的协议下评估两个探测器:
1)每个对象的所有像素
2) 每个对象的最佳预测像素。
结果如表 2 所示。在评估所有前景区域时,Base Detector 仅达到 3.03 AbsRel,这比现有的深度估计算法差很多(Li et al. 2022a;Bhat、Alhashim 和 Wonka 2021)。 然而,对于Enhanced Detector来说,AbsRel从3.03大幅降低到0.23,成为一个更合理的值。
值得一提的是,最佳匹配协议下的Base Detector 的性能几乎与全区域协议下的 Enhanced Detector 相当。
It is worth men-tioning that performance of Base Detector under the bestmatching protocol is almost comparable to the Enhanced Detector under all-region protocol.
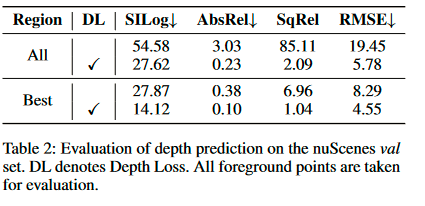
这验证了我们在第 1 节中的假设,即当检测器在没有深度损失的情况下进行训练时(就像 Lift-splat 一样),它仅通过学习部分深度来检测对象。 在最佳匹配协议上应用深度损失后,学习深度进一步提高。 所有这些结果都表明隐式学习的深度是不准确的并且远远不能令人满意
Depth Module Over-fitting
看到 基础检测器只学会了部分区域的深度,我们担心,这个深度学习模块是不是泛化能力很弱?
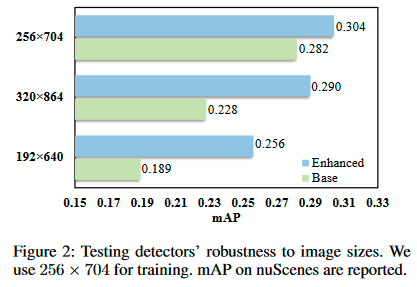
具体来说,这种方式的检测器学习深度可能对图像大小、相机参数等超参数非常敏感。为了验证这一点,我们选择“图像大小”作为变量,并进行以下实验 为了研究模型的泛化能力:我们首先使用输入大小 256×704 训练基本检测器和增强检测器。 然后我们分别使用 192×640、256×704 和 320×864 尺寸对其进行测试。 如图 2 所示,当测试图像大小与训练图像大小不一致时,基础检测器会损失更多准确度。 增强检测器的性能损失要少得多。 这种现象意味着没有深度损失的模型具有较高的过拟合风险,因此也可能对相机内参、外参或其他超参数中的噪声敏感。
Imprecise BEV Semantics
将图像通过学习深度,投影到截锥体特征,然后采用 Vox-el/Pillar Pooling 操作将它们聚合为 BEV。池化操作仅聚合部分语义信息。
图 3 显示,在没有深度监督的情况下,图像特征无法正确投影。增强型检测器在这种情况下表现更好。 我们假设深度不足对分类任务有害。 然后,我们使用两个模型的分类热图并评估它们的 TP / (TP + FN) 作为比较指标,其中 TP 表示被指定为正样本并被 CenterPoint 正确分类的锚点/特征 head而FN代表相反的意思。 参见表3,增强型检测器在不同的正阈值下始终优于其他检测器。
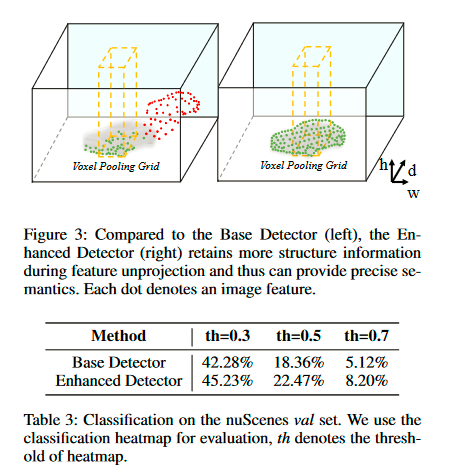
4 BEVDepth
BEVDepth is a new multi-view 3D detector with reliable depth. It leverages Explicit Depth Supervision on a Camera-aware Depth Prediction Module (DepthNet) with a novel Depth Refinement Module on unprojected frustum features to achieve this.
重点是利用lidar的点云显式深度监督、深度微调、利用cuda实现了高效的体素池化操作、考虑相机外参可能会对结果进行干扰(增加一个网络来学习相机参数作为注意力权重作用于图像和深度特征)、
对比,基线LSS 自底向上方法的会显示的估计每个特征点的距离,但是这些距离是隐式学习的。
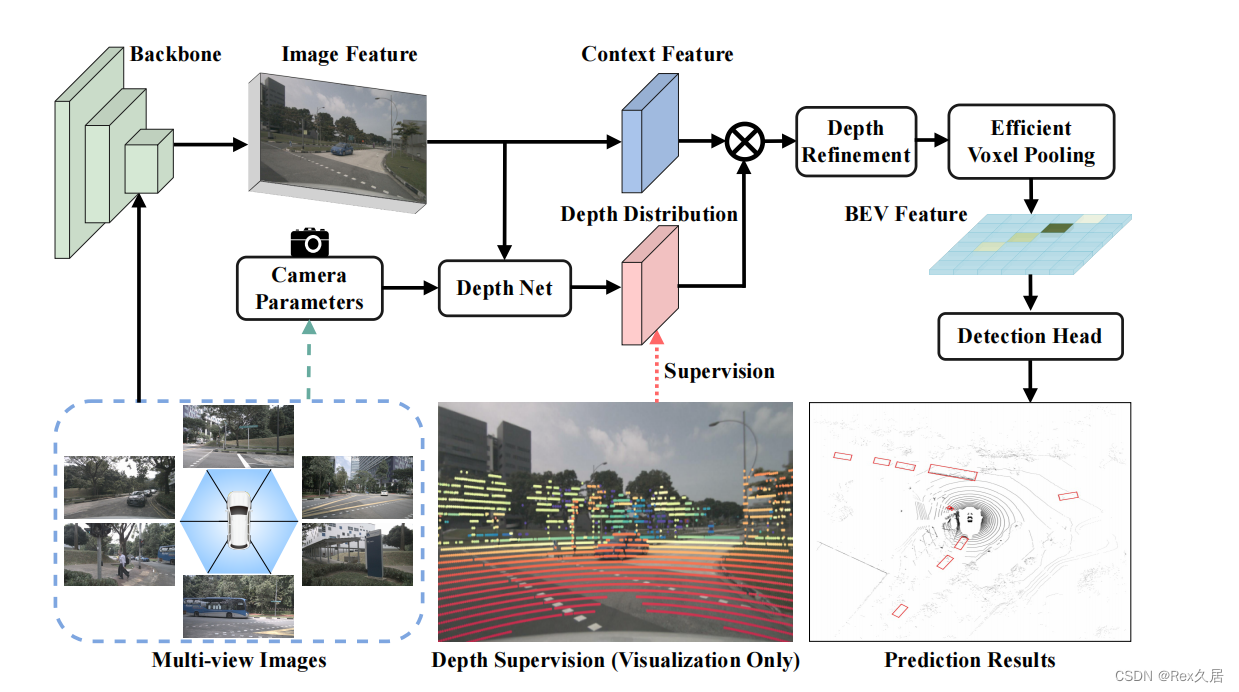
Explicit Depth Supervision
在Base Detector中,深度模块的唯一监督来自于检测损失。 然而,由于单目深度估计的困难,单独的检测损失远远不足以监督深度模块。 因此,我们建议使用从点云数据导出的地面实况来监督中间深度预测
步骤是这样的,首先激光数据转换为2.5D坐标(u,v,d),其中u和v表示像素坐标中的坐标,d是深度。如果某个点云的2.5D投影没有落入第i个视图,我们就直接丢弃它。

然后,为了对齐投影点云和预测深度之间的形状,在激光数据上采用a min pooling 和 a one hot。
对于深度损失L深度,我们采用二元交叉熵BCE。
Camera-aware Depth Prediction
根据经典相机模型,估计深度与相机内在特性相关,这意味着将相机内在特性建模到 DepthNet 中并非易事。 当相机可能具有不同的 FOV(例如 nuScenes 数据集)时,这在多视图 3D 数据集中尤其重要。 因此,我们建议利用相机内在作为深度网络的输入之一。
具体来说,首先使用 MLP 层将相机内在的维度放大到特征。 然后,它们被用来通过挤压和激励(Hu、Shen 和 Sun 2018)模块重新加权图像特征 F 2di。
最后,我们将相机的外部参数与其内部参数连接起来,以帮助 DepthNet 了解特征F在自我坐标系统中的空间位置。
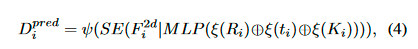
ψ as the original DepthNet
ξ denotes the Flatten operation
现有的一项工作(Park et al. 2021b)也利用了相机感知。 他们根据相机 intrinsics 来缩放回归目标,这使得他们的方法很难适应具有复杂相机。
另一方面&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3678
3678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











