







有此需求,便有此设计与实现。
我们对如下情形的网络拓扑结构进行新节点的配置
| 主机名 | 属性 |
|---|---|
| hadoop0 | namenode, jobtracker |
| hadoop1 | datanode, secondarynamenode, tasktracker |
| hadoop2 | datanode, tasktracker |
一、 配置新节点的环境
不是一般性的,我们不妨将主节点作为新节点(datanode,或者tasktracker)加入到当前网络拓扑结构中,这句话包含的一层意思是主节点也可以作为从节点使用。对主节点使用jps查看java进程数:
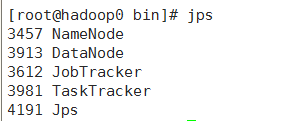
这里的需配置的地方如下:
jdk和hadoop的安装,并从主节点拷贝一份hadoop的配置文件conf/*,以及配置环境变量
主机名和ip地址的统一管理;
主节点向该节点的ssh免密码登录;
详细信息可参看hadoop完全分布式集群搭建。
二、 把新节点的主机名(hostname)加入到主节点的slaves中
vim conf/slaveshadoop0三、 在新节点中,启动datanode和tasktracker
如果已将hadoop/bin目录添加进环境变量,可在任意路经下执行:
hadoop-damen.sh start datanode
hadoop-damen.sh start tasktracker四、 在主节点中,刷新集群拓扑结构
hadoop dfsadmin -refreshNodes五、查看与验证
start-all.sh 使用jps命令,查看主节点(既作为主节点,又作为从节点)的java进程数:
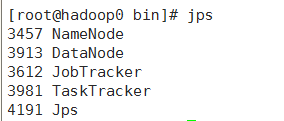
浏览器端查看
在浏览器地址栏输入hadoop0:50070:
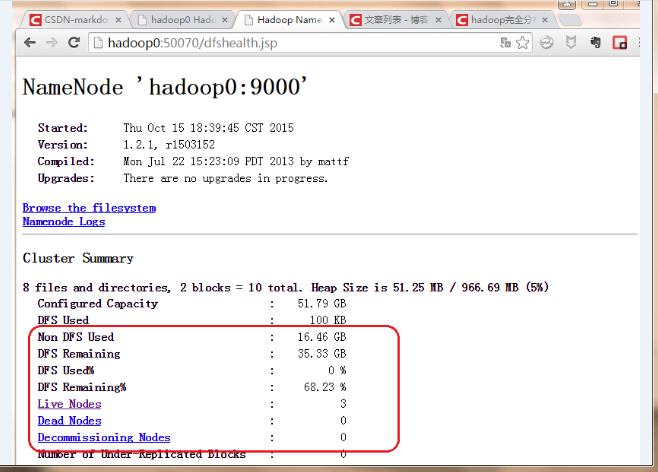
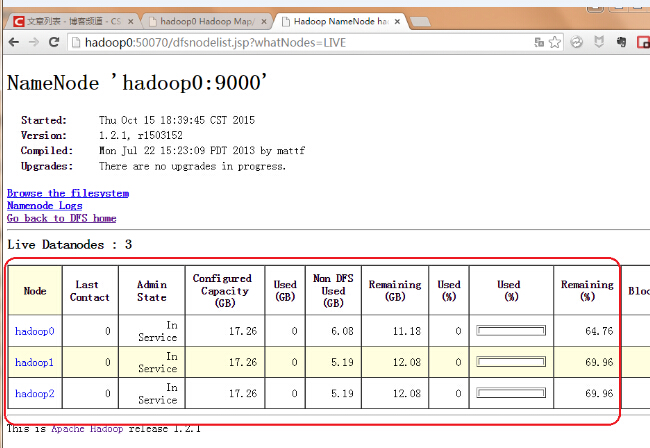
六、 关于下架
只需对新节点执行:
kill -9 datanode的进程ID号我们进入浏览器端会发现hadoop与系统与该节点的last contact的数值一直在增加:
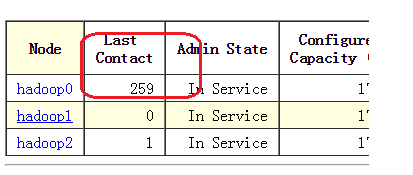
当该数值增大到一定阈值,live nodes值会变为2,dead nodes变为1.
当namenode检测到某个节点宕机之后,会利用hadoop文件的副本机制,重新拷贝一份宕机节点的数据到另外一个节点以维持设定的副本数。
















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











