









reconstruction error
x→y→z
,
y
是被污染的
重构误差可通过多种方式进行度量,度量方式的选择取决于给定映射(也即编码code)下关于输入的分布的假设。
传统的平方误差:
L(x,z)=∥x−z∥2 cross-entropy
LH(x,z)=−∑k=1dxklog(zk)+(1−xk)log(1−zk)常见向量导数
对于一个 p 维向量
x∈Rp ,函数 y=f(x)=f(x1,…,xp)∈R (比如向量的内积运算),则 y 关于x 的导数为:
∇xf(x)=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂f∂x1∂f∂x2⋮∂f∂xp⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥∈Rp对于一个 p 维向量
x∈Rp ,函数 y=f(x)=f(x1,x2,…,xp)∈Rq (如 (Aq×pxp×1)q×1 )∇xf(x)=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢∂f1∂x1⋮∂f1∂xp∂f2∂x1⋮∂f2xp⋯⋱⋯∂fq∂x1⋮∂fqxp⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥∈Rp×q所以有:
∂Ax∂x=⎡⎣⎢⎢⎢⎢⎢βT1βT2⋮βTm⎤⎦⎥⎥⎥⎥⎥x=⎡⎣⎢⎢⎢⎢⎢βT1xβT2x⋮βTmx⎤⎦⎥⎥⎥⎥⎥=[β1,β2,…,βm]=AT∂xTA∂x=xT[α1,α2,…,αn]=[xTα1,xTα2,…,xTαn]=[α1,α2,…,αn]范数求导
线性回归(linear regression)的损失函数(loss function):
L=minw12∥Y−Xw∥22其中 YN×1,XN×(d+1),w(d+1)×1 ,想求得最小化时的权值向量 w ,此时需要求解损失函数
L 对权值向量 w 的导数:
∂L∂w=XT(Y−Xw) 从形式上看,对二范数的平方(一个标量)求导得一个向量。最优权值向量 w ,也即是
∂L∂w=0 时的 w ,也即wLin=(XTX)−1XTY=X†Y 。其实范数的本质是一个函数,也即是一种矢量向标量的映射,例如,我们可以将其看做 12f(x)2 ,其对 x 的导数为
f′(x)f(x) 按位运算,值到值映射的求导
给定一个函数 f(x) 的输入是标量 x ,对于一组
K 个标量 x1,x2,…,xK ,通过 f(x) 得到另外一组 K 个标量z1,z2,…,zK ,zk=f(xk),∀k=1,2,⋯,K为简单起见,我们定义 x=[x1,x2,⋯,xK]T,z=[z1,z2,⋯,zK]T ,
z=f(x),
f(x) 是按位(element-wise)运算,即 (f(x))i=f(xi)如果将 f(x) 的导数记为 f′(x) ,当这个函数的输入为 K 维向量
x=[x1,x2,…,xK] 时,其导数为一个对角矩阵:
∂f(x)∂x=[∂f(xj)∂xi]K×K=⎡⎣⎢⎢⎢⎢⎢f′(x1)0⋮00f′(x2)⋮0⋯⋯⋱⋯00⋮f′(xk)⎤⎦⎥⎥⎥⎥⎥比如RNN网络, ht=f(Uht−1+Wxt+b) , ∂hi∂hi−1=UTdiag[f′(hi−1)]
softmax
P(Y=i|x,W,b)=softmaxi(Wx+b)=eWix+bi∑jeWjx+bj这里 P(Y=i|x,W,b) 表达的是class-membership probabilities(这种类属概念只在多分类问题multi-class classification中才会出现)。其中 Wn_in×n_out 表示权值矩阵, Wj 表示权值矩阵的每一列( 1≤j≤n_out ),这里得到的 Y=i ( i 表示类别)与输入样本的真实的样本label值无关,这里纯做预测。所以有:
ypred=argmaxiP(Y=i|x,W,b) 对应的代码形式为:
self.p_y_given_x = T.nnet.softmax(T.dot(self.input, self.W)+self.b) # self.p_y_given_x:当前输入x下的x属于各个类别的概率 # self.input => (n*n_in) # self.W => (n_in*n_out) # self.b => (n_out) # 所以当做完矩阵乘法的动作,然后进行相加时((n*n_out)+(n_out,)) # 会对self.b进行broadcast,也即在列的方向上,拷贝拓展n份,构成一个(n*n_out)的矩阵,然后进行的相加 self.p_pred = T.argmax(self.p_y_given_x, axis=1)对数似然函数
L(θ={W,b},D)=∑i=0|D|log(p(Y=y(i)|x(i),W,b))ℓ(θ={W,b},D)=−L(θ={W,d},D)θ={W,b} 表示参数集, D 表示样本集, |D| 表示样本集的基数(cardinal number,也即样本的个数,
X.shape[0](numpy))。上式表示多分类问题的对数似然函数。下式是作为损失函数(loss function)的似然函数(negative log likelihood)。
反映在代码中,其实十分简洁:
def loss_function(self, y): return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])在取和式的同时顺便又一个取均值的动作。
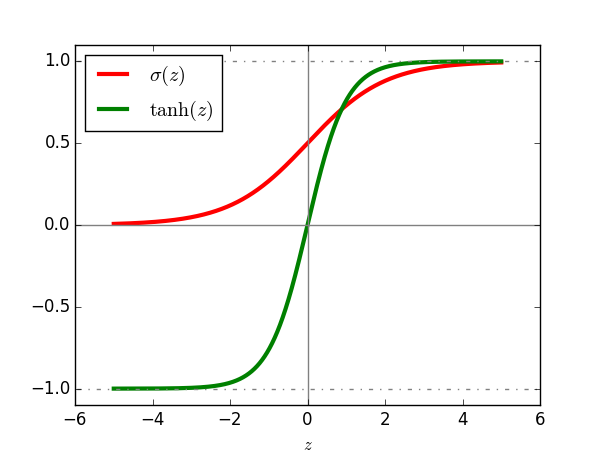
sigmoid
sigmoid系(Logistic-Sigmoid、Tanh-Sigmoid)被视为神经网络的核心所在:
σ(z)=11+exp(−z)=1+tanh(z/2)2
tanh(z)=exp(z)−exp(−z)exp(z)+exp(−z)=2σ(2z)−1
值域分别是 σ(z)∈(0,1)tanh(z)∈(−1,1)
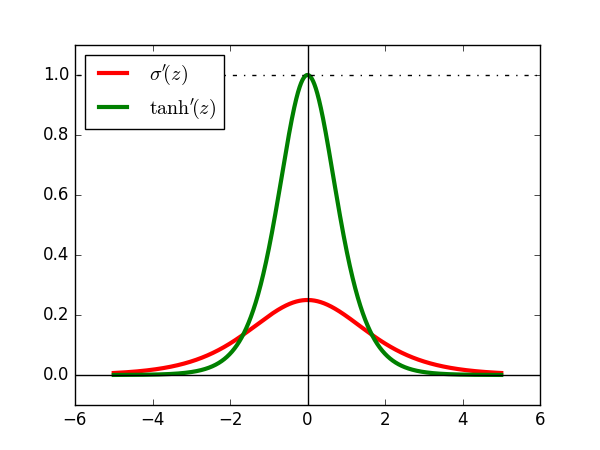
它们各自的导数分别为:
σ′(z)=σ(z)(1−σ(z))tanh′(z)=1−(tanh(z))2
值域分别是: σ′(z)∈(0,0.25],tanh′(z)∈(0,1]源代码请见sigmoid_tanh_prime
softmax
数学上,输入向量 x 属于类别
i 的概率,记为随机变量 Y ,其数学形式如下:
P(Y=i|x,w,b)=softmaxi(Wx+b)=eWxi+b∑jeWxj+b
与之相对应的模型进行类别的预测时:
y_pred=argmaxiP(Y=i|x,w,b)多元高斯密度函数(Multivariate Gaussian Density)
p(x⃗ )∝exp[−12(x⃗ −μ⃗ )TΣ−1(x⃗ −μ⃗ )]where μ⃗ is an N -dimensional vector position of(注意这里的通用表达) the mean of the density and
Σ 是 N×N 的协方差矩阵。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











