








原文请见:Load Balancing and the Power of Hashing
如果你参加一次软件工程师的面试并你被问到一个很难的有关算法的题目,那么你最好考虑使用散列函数(hash tables)?更简洁地说吧:谷歌喜欢散列函数(and BAT)。要想知道为什么散列函数如此有用,你多少应该知道它里面的数学。
一些概念术语的阐述
load factor(装填因子)
n keys, m slots(键与槽) ⇒ α=nm , average # keys per slot
Expected unsuccessful search time(失败搜索(搜索的数据不在表中)的时间期望)
Θ(1+α)=Θ(1+nm)
1:hash and accessing the slot
α :the cost of the searching the list.
Expected search time == Θ(1) if n==Θ(m) (不会超过 m 的整数倍)
division method:
h(k)=kmodm multiplication method:
m=2r , w 表示计算机的位数(之所以更推荐乘法,是因为计算机更擅长乘法,此时考虑计算机的位数,可见这时就牵涉计算机硬件体系结构的问题了)
h(k)=(A⋅kmod2w)>>(w−r) A 是位于
[2w−r,2w] 之间的一个奇数,且不接近于 2w−1 或者 2w 。我们不妨来分析这一hash函数式, A⋅kmod2w 共保留 w 位,再右移
w−r ,保留中间的 w−(w−r)==r 位,也正是最终得到的槽(slots)的个数,这一切都很convenient,对计算机而言。我们来举一个实例,取 r=3,w=7,A=0b1011001 (7位的计算机,:-D),当 k=0b1101011 时, A⋅k=0b10010100110011 ,再进行取模运算,也即保留最后的 w=7 位, A⋅kmod2w 得 0b0110011 ,最后右移 w−r=7−3=4 位,即保留 0b011=3 ,也即 h(k)=3 。
开地址法的分析
首先我们需要一个均匀哈希的假设(Assumption of uniform hashing):each key equally likely to have any one of the m! perms as its probe seq,independence of other keys.
Theorem: E[#probes]≤11−α ,if α<1 (也即 n<m )
Pf (unsucc search):
1 probe always necessary with prob
nm
collision, ⇒ 2nd probe necessary,
n−1m−1
collision ⇒ 3nd,
n−2m−2
注意到 n−im−i<nm=α
当 α<1 且为常数时,共需要 Θ(1) 次探测;
- α=0.5 ⇒ 2次
- α=0.9 ⇒ 10次
α 不能太大,也即 hash table 不能太稠密;
universal hashing(全局哈希)
Idea is:choose hash function at random independen t from keys,这正是所谓的 universal hashing(全域hash)
Def:
U
为键的全域(a universe of key)
H
is universal if
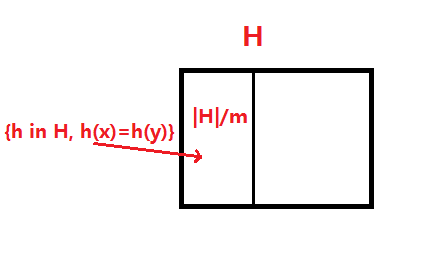
则从
H
中随机地选择一个 hash function
Thm. Choose
h
randomly from
Pf. Let
Cx
be r.v. denoting total(概率分析中常用到的一种手段,将某个total型的随机变量转换为一系列指标随机变量的总和) collisions of keys in T with
x
, 定义如下的指标随机变量:
E(Cxy)=Pr(h(x)=h(y))=1m
,
Cx=∑y=T−{x}Cxy
:
构造全局哈希
此构造对
m
为质数时有效,将键 m进制表示)
构造我们的随机化策略(randomized strategy)。
随机化的对象是对哈希函数的选择。
选择
最终,我们定义
Thm:此时的
H
是全域的。也即需证明
证明:
分别将
x,y
分解,得
x=<x0,x1,…,xr>
,
y=<y0,y1,…,yr>
,
x
与
也即:
因为
x0≠y0
,所以
x0−y0
的逆元,也即
(x0−y0)−1
一定存在,所以:
也即, a0 完全由 ai,i=1,…,ar 决定,或者说任何 ai,i=1,2,…,r 都存在一个 a0 ,使得 ha(x)≡ha(y) (发生碰撞),也即自由度为 (1+r)−1=r 。
















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











