









将数据从 mysql import 到 HDFS 中
我们要使用 mysql 的话,意味着要对其进行连接,自然使用 JDBC(Java Data Base Connectivity)。在之前配置 hive 的 mysql 时,我们已将 mysql-connector-java-5.1.10.jar 拷贝到 hive/lib 目录下,
[root@hadoop0 ~]# cp $HIVE_HOME/lib/mysql-connector-java-5.1.10.jar $SQOOP_HOME/lib/我们以导入 hive 数据库的TBLS表到 HDFS(默认路径为/usr/<username>) 为例,进行演示
[root@hadoop0 ~]# sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password 824756 --table TBLS --fields-terminated-by '\t'导入到 HDFS 时,HDFS 会将为空的字段显示为null,我们可在之前的命令中增加一个参数--null-string '**'(将null替换为**字符形式)。注意,'--'不可用,'--'是作为专有字符使用的。
默认sqoop在执行任务时,会自动四个map 任务并行地执行导入任务,以加快执行的速度,所以我们会在hdfs文件系统中看到四个文件,如下图所示:
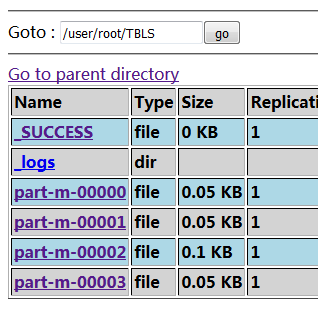
这在导入小数据时是快不了的,如何指定一个 map 任务来执行呢,增加一个参数:--m 1(强制性指定 map 任务数)。
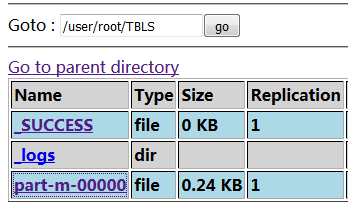
--null-string '**':将空字段指定为**显示,--不可用-m 1:指定导入数据时所启用的 map 任务数,默认为4;--append:允许多次写入:--hive-import:导入到hive中--P而不是--password时,我们不必在指令中给出密码的明文形式,而以命令行的方式输入密码;--check-column 'TBL_ID --incremental append --last-value 6':以行为基准的增量导入
将数据从 HDFS export 到 mysql 中
sqoop export 必须按照目录导出,而不能按照文件导出(看下面的命令形式);
[root@hadoop0 ~]# sqoop export --connect jdbc:mysql://hadoop0:3306/hive --username root -P --table users --fields-terminated-by '\t' --export-dir '/ids'
# ids 是hdfs中的一个文件夹,sqoop的导出操作是将/ids下的文件导出到users表中
# 所以要求hive数据库的users表必须存在
# hdfs中的/ids文件下必须有文件,- 不需
--append,可以不断的导出
问题及解决
我们使用 sqoop 执行数据的导入操作时,可能会发生如下的错误提示:
ERROR manager.SqlManager: Error reading from database: java.sql.SQLException: Streaming result set com.mysql.jdbc.RowDataDynamic@33573e93 is still active. No statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.
java.sql.SQLException: Streaming result set com.mysql.jdbc.RowDataDynamic@33573e93 is still active. No statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.解决方案是:在导入命令中增加--driver com.mysql.jdbc.Driver。
也即将之前的:
[root@hadoop0 ~]# sqoop import --connect ...修改为:
[root@hadoop0 ~]# sqoop import --driver com.mysql.jdbc.Driver --connect ...















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











