







LLMs之DeepSeek-V3之PP:DualPipe(用于V3/R1训练中计算通信重叠的双向流水线并行算法)的简介、安装和使用方法、案例应用之详细攻略
目录
3、profile-data:该项目旨在分析V3/R1版本中的计算-通信重叠情况
DualPipe的简介
2025年2月27日,DualPipe是DeepSeek-V3技术报告中提出的一种创新的双向流水线并行算法。它实现了前向和后向计算-通信阶段的完全重叠,并减少了流水线气泡。DualPipe旨在通过计算和通信的完全重叠来提高DeepSeek-V3/R1模型的训练效率。 它通过减少流水线气泡来优化训练过程,但该项目主要提供算法框架和示例,需要用户进行进一步的集成和适配才能应用于实际的训练任务。
GitHub地址:https://github.com/deepseek-ai/DualPipe
1、特点
>> 双向流水线并行:DualPipe采用双向流水线并行算法,允许前向和后向计算同时进行,最大限度地重叠计算和通信。
>> 计算通信重叠:通过双向流水线并行,实现前向和后向计算与通信的完全重叠,显著提高训练效率。
>> 减少流水线气泡:该算法有效减少了流水线气泡,进一步提高了效率。
>> 可扩展性:DualPipe算法适用于多节点训练场景,能够提升大规模模型训练的效率。
2、DualPipe调度示例

项目中给出了一个DualPipe调度示例,展示了在8个并行进程和20个微批次的情况下,双向流水线并行的调度方式。 此外,还提供了不同方法(1F1B、ZB1P和DualPipe)在流水线气泡和内存使用方面的比较。 该比较结果表明,DualPipe算法在减少流水线气泡和内存使用方面具有优势。
3、profile-data:该项目旨在分析V3/R1版本中的计算-通信重叠情况
GitHub地址:https://github.com/deepseek-ai/profile-data
项目目的是帮助社区更好地理解通信-计算重叠策略和底层实现细节。
DeepSeek基础设施中的性能数据
公开分享训练和推理框架的性能数据。
使用PyTorch Profiler捕获性能数据,可通过Chrome或Edge浏览器查看,项目采用了绝对平衡的MoE路由策略进行性能分析。
训练:展示DualPipe中单个前向和反向块的重叠策略

每个块包含4个MoE层,并行配置符合DeepSeek-V3预训练设置(EP64, TP1,4K序列长度),为简化分析,PP通信未包含在性能分析中。
推理
预填充:描述预填充阶段的性能数据
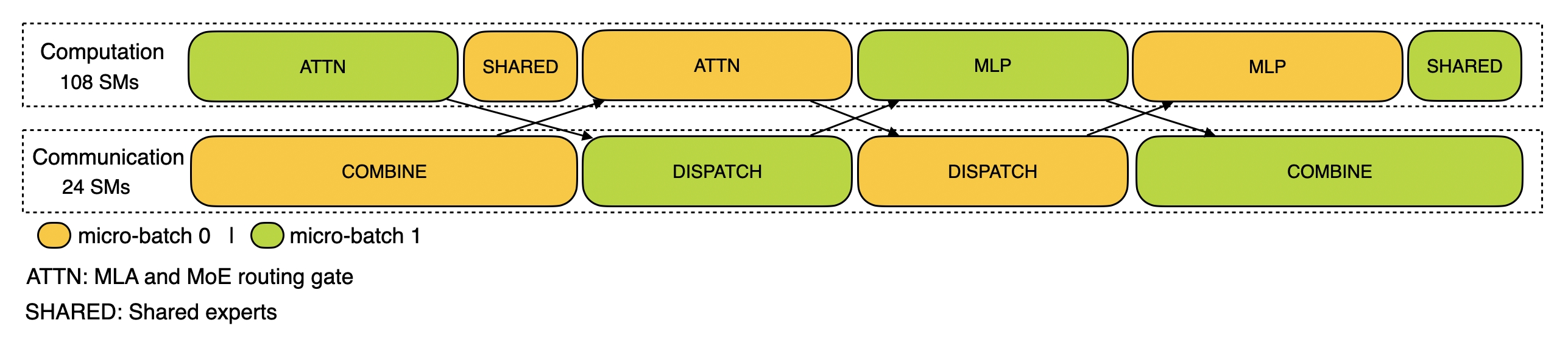
采用EP32和TP1配置(与DeepSeek V3/R1实际在线部署一致),提示长度为4K,每个GPU的批处理大小为16K个令牌。预填充阶段使用两个微批次来重叠计算和全对全通信,同时确保两个微批次之间的注意力计算负载平衡。
解码:描述解码阶段的性能数据(尚未发布)
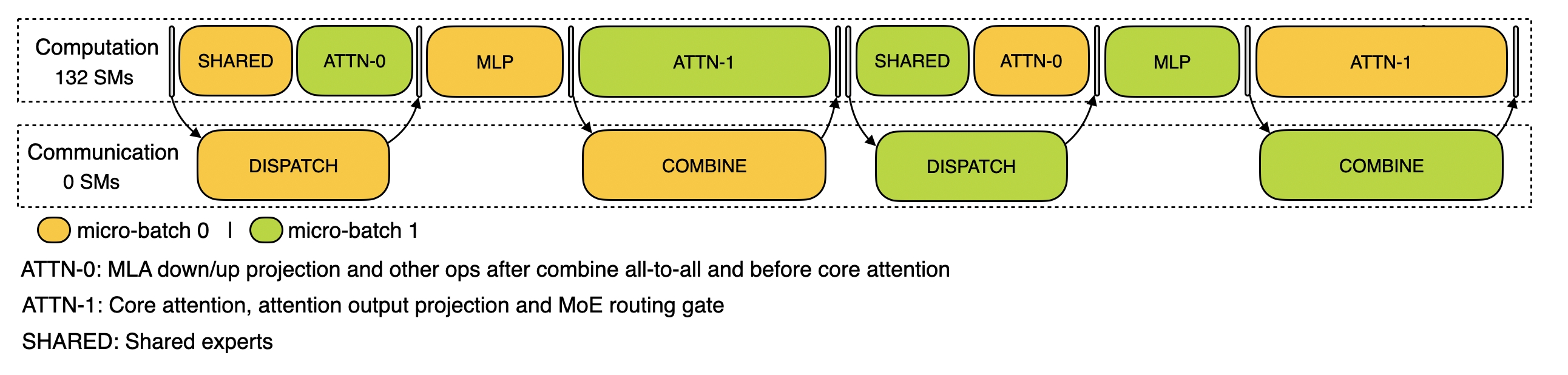
采用EP128, TP1配置,提示长度为4K(与实际在线部署配置相近),每个GPU的批处理大小为128个请求。解码阶段同样利用两个微批次来重叠计算和全对全通信。与预填充不同的是,解码阶段的全对全通信不会占用GPU SMs,系统在计算完成后等待全对全通信完成。关于全对全通信的实现,可参考DeepEP。
DualPipe的安装和使用方法
1、安装
前提条件
PyTorch 2.0及以上版本
安装
项目没有提供详细的安装步骤,只提供了运行示例的命令:
python example.py即该项目可能更侧重于算法的演示,而非一个独立可安装的库。
2、使用方法
运行示例代码example.py可以查看DualPipe算法的简单示例。 但是,该示例代码仅供演示,实际应用中需要根据具体的模块实现自定义的overlapped_forward_backward方法。需要用户根据自己的模型和训练框架进行集成。
DualPipe的案例应用
持续更新中……



















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











