






论文题目:
SNI-SLAM: Semantic Neural Implicit SLAM
论文作者:
Siting Zhu, Guangming Wang, Hermann Blum, Jiuming Liu, Liang Song,Marc Pollefey, Hesheng Wang
导读: 本文是发布在CVPR 2024的论文,提出了SNI-SLAM:一个利用神经隐式表示的语义SLAM系统,它能够同时执行准确的语义建图、高质量的表面重建和稳健的相机跟踪。©️【深蓝AI】编译
1. 摘要
本文提出了SNI-SLAM,一个利用神经隐式表示的语义SLAM系统,它能够同时执行准确的语义建图、高质量的表面重建和稳健的相机跟踪。在这个系统中,本文引入了层次化语义表示,以支持对场景的自上而下结构化语义建图的多级语义理解。此外,为了充分利用环境中多个属性之间的相关性,本文通过交叉注意力将外观、几何和语义特征整合起来以实现特征协作。这种策略使算法能够更全面地理解环境,从而使SNI-SLAM即使在单个属性有缺陷时也能保持稳健。接着,本文设计了一个基于内部融合的解码器,以便从多级特征中获取语义、RGB和截断符号距离场(TSDF)值,继而实现准确解码。此外,本文提出了一个特征损失来更新特征级别的场景表示。与RGB损失和深度损失等低级损失相比,本文的特征损失能够在更高层次上指导网络优化。本文的SNI-SLAM方法在Replica和ScanNet数据集上的建图和跟踪精度方面优于所有最近的基于NeRF(神经辐射场)的SLAM方法,同时还展示了在准确语义分割和实时语义建图方面的出色能力。
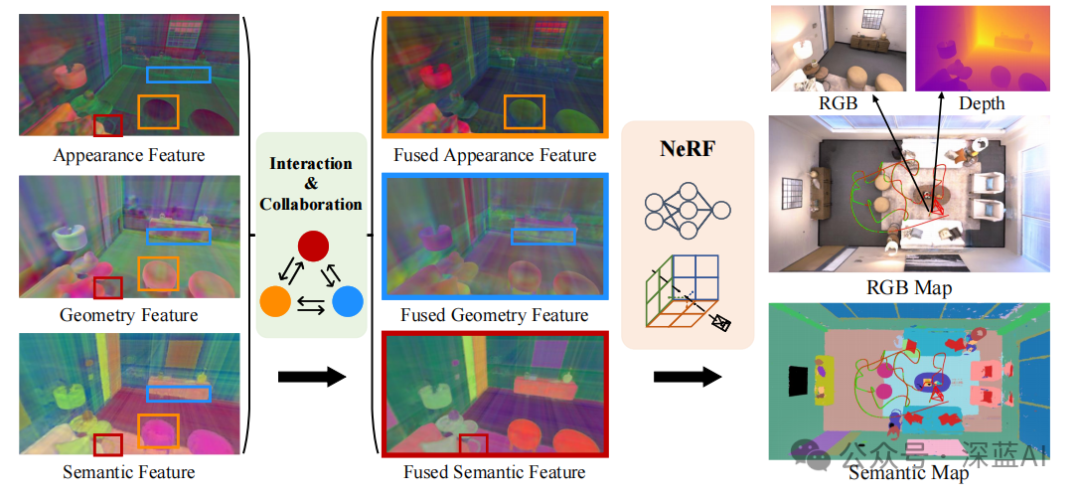
图1|SNI-SLAM系统利用环境中多模态特征之间的相关性,基于NeRF进行语义SLAM。这种建模策略不仅与现有的基于NeRF的SLAM相比实现了更高的精度,而且能够实现实时语义建图。本文提出了一种外观、几何和语义之间的特征协作方法,显著增强了特征的表示能力。融合外观(橙色框):消除了椅子因光线造成的阴影。融合几何(蓝色框):改善了柜子底部边缘的不一致性。融合语义(红色框):增强了桌子腿和地板之间的区分度。©️【深蓝AI】编译
2. 介绍
语义SLAM在机器人和自动驾驶中可以构建包含环境语义信息的高精度地图。传统语义SLAM方法在处理未知区域预测和存储需求上存在局限,而NeRF作为场景表示的新方式显示出解决这些问题的潜力。
基于NeRF的SLAM研究虽已取得进展,但现有大多系统仅能生成RGB图像而非直接支持下游任务所需的语义信息。有研究展示了NeRF同时学习几何与语义表征的能力,然而离线训练耗时较长,不适用于实时语义SLAM应用。
因此,本研究提出了一种新的基于NeRF的语义SLAM框架——SNI-SLAM,它利用跨注意力机制融合多模态特征,并采用层次化的粗到细语义建图策略,以增强对复杂场景的建模能力。通过设计融合解码器从不同分辨率层级提取语义、颜色和深度信息,SNI-SLAM能够实现更加准确且丰富的语义理解,并实现实时高效的相机定位和语义地图构建。
3. 方法
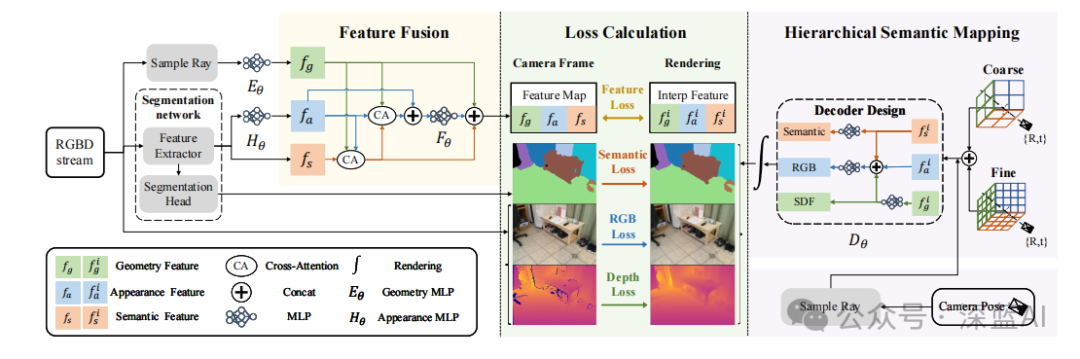
图2|SNI-SLAM系统概述。RGB图像被送入语义特征提取器以获得语义特征。这些特征随后通过外观多层感知机(MLP)Hθ转换为外观特征。几何特征通过射线采样得到,然后经过几何MLP Eθ处理。接下来,使用基于交叉注意力的特征融合方法将这三种特征融合,生成特征图。这个特征图、输入的RGB-D以及从分割网络获得的分割结果作为监督信号。通过插值得到场景表示生成的特征,这些特征用于构建特征损失,并通过解码和渲染过程获得生成的RGB、深度和语义信息。监督信息和生成的信息用于构建损失以更新场景表示和MLP网络。采用分层语义表示进行语义建图。对于相机跟踪,利用损失函数来优化相机姿态。©️【深蓝AI】编译
3.1 基于交叉注意力的特征融合
首先,几何特征(fg)、语义特征(fs)和外观特征(fa)是相互关联且互补的。例如,语义特征对于识别和理解物体具有稳定性,不受光照或视角变化的影响;而外观特征可以补充语义信息,通过观察颜色、亮度和纹理等属性来推测物体类别。同时,几何特征在机器人应用中对定位和量化物体的位置和形状至关重要,这种信息与语义信息相结合,可进一步推断物体可能的性质或身份。为了充分利用这些特征间的相关性,研究提出了使用交叉注意力来融合上述三种特征:输入RGB图像首先经过预训练的语义分割网络提取语义特征,然后利用实时更新的环境特定外观MLP网络Hθ将语义特征转换为外观特征。此外,还可通过基于NeRF频率编码获取三维点的几何特征向量,如下:
γ ( p ) = ( s i n 2 0 π p , c o s 2 0 π p , . . . , s i n 2 L − 1 π p , c o s 2 L − 1 π p ) γ(p)=(sin2^0πp,cos2^0πp,...,sin2^L-1πp,cos2^L-1πp) γ(p)=(sin20πp,cos20πp,...,sin2L−1πp,cos2L−1πp)
其中, L L L定义了所使用的频率总数。对于3D坐标,使用 L = 6 L=6 L=6。 γ ( p ) γ(p) γ(p)通过几何多层感知机 E θ ( γ ( p ) ) Eθ(γ(p)) Eθ(γ(p))进行处理,以获取几何特征 f g f_g fg,该特征存储了环境的几何信息。
接下来,利用几何特征的结构特性来引导注意力。具体来说,将几何特征 f g f_g fg作为查询( Q Q Q),外观特征 f a f_a fa作为键( K K K),语义特征 f s f_s fs作为值( V V V),进行交叉注意力计算,从而得到融合后的语义特征 T s T_s Ts:
T s = s o f t m a x ( f g f a T ∣ ∣ f a ∣ ∣ 2 2 ) f s T_s=softmax({f_gf_a^T \over \sqrt{||f_a||_2^2}})f_s Ts=softmax(∣∣fa∣∣22fgfaT)fs
通过这种融合,基于几何和外观特征的匹配,动态地调整语义信息的加权组合,从而突出匹配并削弱不匹配,进而最小化错误语义预测的影响。此外,本文还将外观特征 f a f_a fa、几何特征 f g f_g fg和融合后的语义特征 T s T_s Ts分别作为值( V V V)、查询( Q Q Q)和键( K K K),以获取融合后的外观特征 T a T_a Ta:
T a = s o f t m a x ( f g T s T ∣ ∣ T s ∣ ∣ 2 2 ) f a T_a=softmax({f_gT_s^T \over \sqrt{||T_s||_2^2}})f_a Ta=softmax(∣∣Ts∣∣22fgTsT)fa
通过交叉注意力机制,融合后的外观特征Ta得到了增强,但它可能会丢失原始外观特征fa中的一些细粒度细节。因此,将fa和Ta进行拼接,然后将拼接后的特征通过融合多层感知机Fθ进行处理。这种融合方式既保留了来自Ta的增强信息,又集成了来自fa的更精细的细节,从而实现了更丰富的外观表示。接着,将结果与fg和Ts进行拼接,得到特征图FM = {fg, T’a, Ts}。这种基于交叉注意力的多模态特征融合方法促进了不同模态特征之间的交互和相互学习,从而得到了更准确的特征表示。
3.2 层次化语义建图

图3|粗粒度特征与细粒度特征的可视化。粗粒度特征捕获了组件的一般结构和布局。细粒度特征提供了更精细的细节。©️【深蓝AI】编译
针对现有基于NeRF方法在处理复杂场景时性能受限的问题,本研究采用了一种从粗到细的分层语义建模策略来增强环境的语义表示能力。
具体实现上,使用特征平面存储空间效率较高的特征,并进行多级语义建图。每一特征平面上设置了两种不同空间分辨率层级的特征:粗略级别特征(F coarse s-xy, F coarse s-xz, F coarse s-yz)和精细级别特征(F fine s-xy, F fine s-xz, F fine s-yz),它们分别对应着场景的不同细节层次。对于给定坐标点,将对应的粗粒度和细粒度特征进行拼接以获得更丰富全面的特征信息。
同时,在解码器设计方面,SNI-SLAM摒弃了传统独立优化各特征的方法,而是采取融合方式。解码器将几何、外观以及经过跨注意力机制融合后的特征进行连接并输入至MLP网络,从而得到颜色、Signed Distance Field (SDF)值等输出信息。这种结构确保了特征之间的协同工作,使得模型能够根据融合特征生成精确的颜色、深度图像及语义分割结果,进而提升整个SLAM系统的性能表现。
3.3 损失函数
本文从输入图像中采样M个像素,定义自由空间损失:
L f s = 1 ∣ M ∣ ∑ m ∈ M 1 ∣ P m f s ∣ ∑ p ∈ P m f s ( d ( p ) − 1 ) 2 L_{fs} = {1 \over |M|}\sum_{m \in M}{1\over|P_m^{fs}| }\sum_{p \in P_m^{fs}}(d(p)-1)^2 Lfs=∣M∣1m∈M∑∣Pmfs∣1p∈Pmfs∑(d(p)−1)2
对于位于截断区域内且靠近表面的点,损失函数如下:
L t r = 1 ∣ M ∣ ∑ m ∈ M 1 ∣ P m t r ∣ ∑ p ∈ P m f s ( z ( p ) + T ⋅ d ( p ) − D ( m ) ) 2 L_{tr} = {1 \over |M|}\sum_{m \in M}{1\over|P_m^{tr}| }\sum_{p \in P_m^{fs}}(z(p)+T \cdot d(p) -D(m))^2 Ltr=∣M∣1m∈M∑∣Pmtr∣1p∈Pmfs∑(z(p)+T⋅d(p)−D(m))2
语义损失: 对于语义信息的监督,本文采用交叉熵损失。值得注意的是,在渲染语义信息的过程中,本文断开了梯度,以防止语义损失干扰几何和外观特征的优化:
L s = − ∑ m ∈ M ∑ l = 1 L p l ( m ) ⋅ l o g p l ( m ) L_s=-\sum_{m \in M} \sum_{l=1}^L p_l(m)\cdot logp_l(m) Ls=−m∈M∑l=1∑Lpl(m)⋅logpl(m)
特征损失: 当仅使用颜色、深度和语义值作为监督信号时,MLP网络会过于关注不太重要的细节,而忽略一些更显著的特征。为了解决这个问题,本文构建了特征损失,并利用它来为更新特征平面和MLP网络提供额外的指导。
L f = ∣ ∣ f e x t r a c t − f i n t e r p ∣ ∣ 1 L_f=||f_{extract} - f_{interp}||_1 Lf=∣∣fextract−finterp∣∣1
颜色和深度损失: 输入是包含真实RGB和深度值的RGB-D帧。本文通过将渲染的RGB和深度值与真实值进行比较,构建颜色和深度损失。然后,这些损失函数用于更新网络:
L
c
=
1
∣
M
∣
∑
i
=
0
M
∣
∣
C
i
−
C
i
g
t
∣
∣
L_{c} = {1 \over |M|}\sum_{i=0}^M||C_i-C_i^{gt}||
Lc=∣M∣1i=0∑M∣∣Ci−Cigt∣∣
L
d
=
1
∣
M
∣
∑
i
=
0
M
∣
∣
D
i
−
D
i
g
t
∣
∣
L_{d} = {1 \over |M|}\sum_{i=0}^M||D_i-D_i^{gt}||
Ld=∣M∣1i=0∑M∣∣Di−Digt∣∣
完整的损失函数 L L L是上述损失的加权和:
L = λ f s L f s + λ t r L t r + λ S L S + λ f L f + λ D C L C + λ D L D L=\lambda_{fs}L_{fs} + \lambda_{tr}L_{tr}+\lambda_{S}L_{S}+\lambda_{f}L_{f}+\lambda_{DC}L_{C}+\lambda_{D}L_{D} L=λfsLfs+λtrLtr+λSLS+λfLf+λDCLC+λDLD
其中的 λ λ λ就是权重。
4. 实验
4.1 数据集
本文在两个带有语义真实标注的数据集上评估SNI-SLAM的性能,包括模拟数据集Replica上的8个合成场景和真实世界数据集ScanNet上的4个场景。
评估指标:为了评估SLAM系统,本文使用了NICE-SLAM中的指标。对于网格重建指标,本文使用了深度L1(厘米)、精度(厘米)、完成度(厘米)和完成度比率(%),阈值为5厘米。本文移除了任何相机半径外的未观察区域,以及按照Co-SLAM进行的额外网格修剪以去除噪声点。此外,本文还使用ATE来评估跟踪精度。语义分割的评估是基于mIoU和每像素精度。
4.2 基线方法
本文将语义分割准确性的指标与NIDS-SLAM进行了比较NIDS-SLAM是唯一一种基于NeRF的语义SLAM方法。对于SLAM的精度,本文与最先进的基于NeRF的密集视觉SLAM方法进行了比较。
4.3 实现细节
本文使用16通道的特征向量来表示语义、几何和外观特征。解码器MLP有两层,隐藏层的维度为32,在NVIDIA RTX 4090 GPU上运行SNI-SLAM。
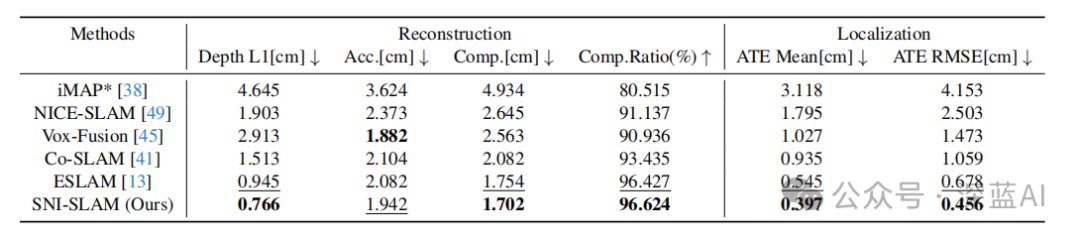
表1|SNI-SLAM与其他基于NeRF的密集SLAM方法在地图重建和定位精度方面的定量比较。结果是在Replica数据集上的8个场景的平均值。为确保结果更具客观性,每个场景都进行了五次独立运行并取平均值。本文的工作超过了以前的工作,表明本算法有出色的SLAM性能。©️【深蓝AI】编译

图4|本文的方法与基线在场景重建方面的定性比较。真实图像和细节是使用ReplicaViewer软件渲染的。本文可视化了Replica数据集中的3个选定场景,并将细节用彩色框突出显示。本文方法实现了更准确的详细几何形状和更高的完成度,尤其是在观察受限的地方。©️【深蓝AI】编译

表2|在Replica数据集的4个场景上,SNI-SLAM与现有的基于NeRF的语义SLAM方法NIDS-SLAM的定量比较,因为NIDS-SLAM的结果仅在这些场景上进行了报告。为了与其进行公平的比较,本文使用真实的语义标签作为监督来获得结果。对于一个场景,算法每50帧计算渲染和真实语义地图之间的mIoU和像素精度,以获得平均mIoU和像素精度。本文的方法优于NIDS-SLAM。©️【深蓝AI】编译
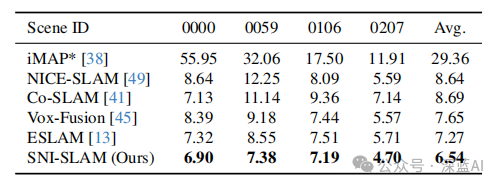
表3|SNI-SLAM与其他现有的基于NeRF的SLAM方法在ScanNet数据集上的跟踪指标RMSE(厘米)进行了比较。结果是五次独立运行的平均值。本文的方法优于基线方法。©️【深蓝AI】编译
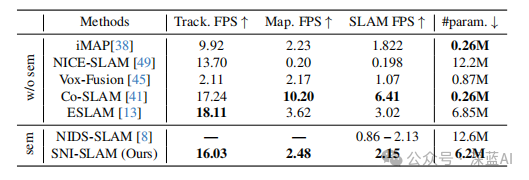
表4|在Replica数据集上的运行时间和内存比较(w/o sem:无语义建图;sem:语义建图)。与现有的基于NeRF的SLAM相比,本文的基于语义NeRF的SLAM在时间消耗略有增加且参数数量几乎相同的情况下,能够实现语义建图。此外,与NIDS-SLAM相比,本文的方法实现了更快的运行时间,且参数数量减半。©️【深蓝AI】编译
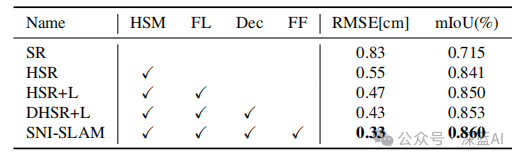
表5|在Replica数据集的office0场景上的消融研究:(HSM) 分层语义建图;(FL) 特征损失;(Dec) 解码器设计;(FF) 基于交叉注意力的特征融合;(SR) 仅使用特征平面作为场景表示的基于语义NeRF的SLAM;(HSR) 添加由粗到细的语义建图;(HSR+L),(DHSR+L) 添加相应的创新。©️【深蓝AI】编译
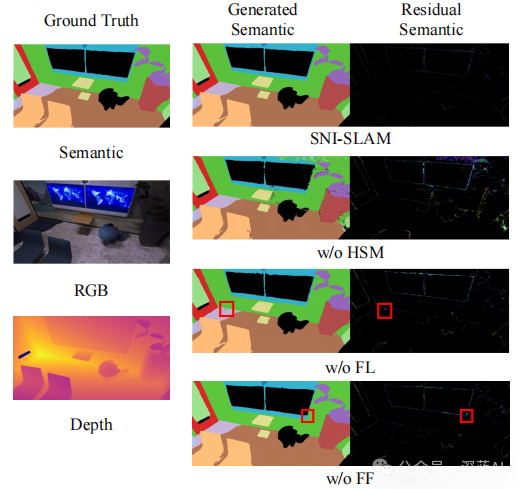
图5|在Replica数据集的office0场景上的语义渲染结果和真实标签的消融研究。可视化不同情况下的渲染结果:(w/o HSM) 无分层语义建图;(w/o FL) 无特征损失;(w/o FF) 无特征融合。从残差中可以看出,整个SNI-SLAM系统实现了最佳的语义准确性。©️【深蓝AI】编译
5. 结论
本文提出了SNI-SLAM,一个基于神经隐式表示的语义SLAM系统,旨在提高密集视觉建图和跟踪精度的同时,提供整个场景的语义地图。本文提出了一种基于交叉注意力的特征融合方法,使外观、几何和语义特征能够相互促进并进行交叉学习。本文还提出了粗到细的语义表示方法,以在多个层次上建模场景中的语义信息。这种表示方法可以在保持整体场景语义信息精度的同时,考虑到复杂的语义细节。此外,本文还提出了一种新的解码器设计,它能够实现特征平面上插值特征的融合,从而得到更准确的解码结果。
编译|蒙牛二锅头
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。

















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









