







TensorFlow2数据统计函数:
- tf.norm(范数)
- tf.reduce_min/max(最大值/最小值)
- tf.argmax/argmin(最大值/最小值的位置)
- tf.equal(两个张量的比较)
- tf.unique(独特值)
一. tf.norm(范数)
1、范数定义(注: 这里只讨论向量的范数,不讨论矩阵的范数)
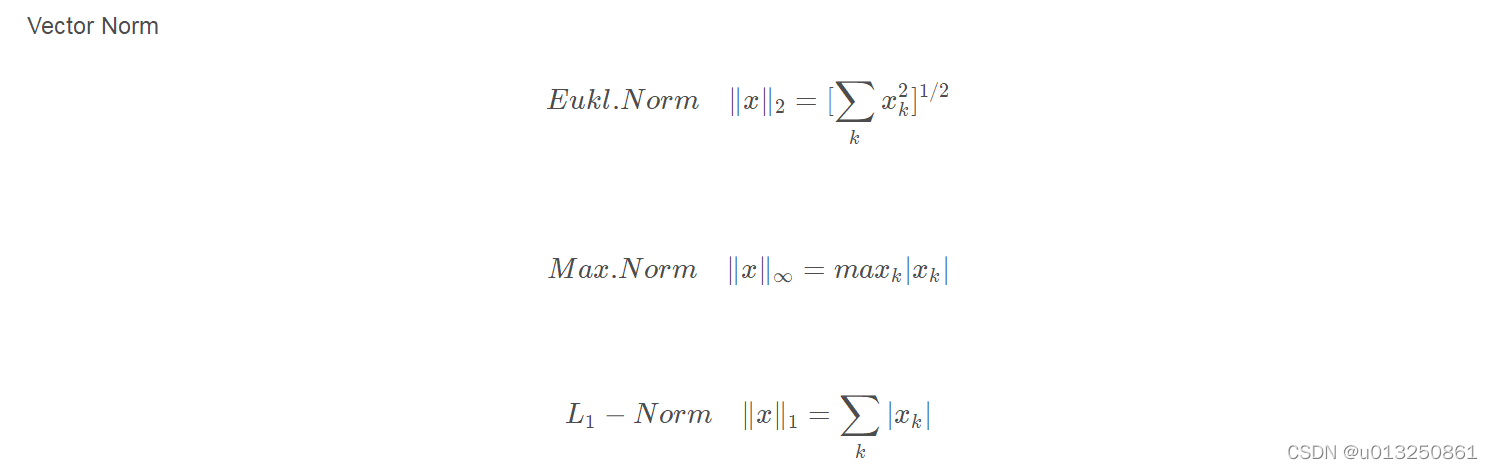
2、tf.norm(二范数)
如果不指定tf.norm()中的参数ord,那么默认为求二范数
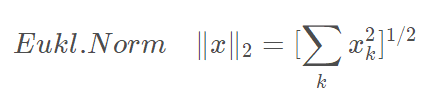
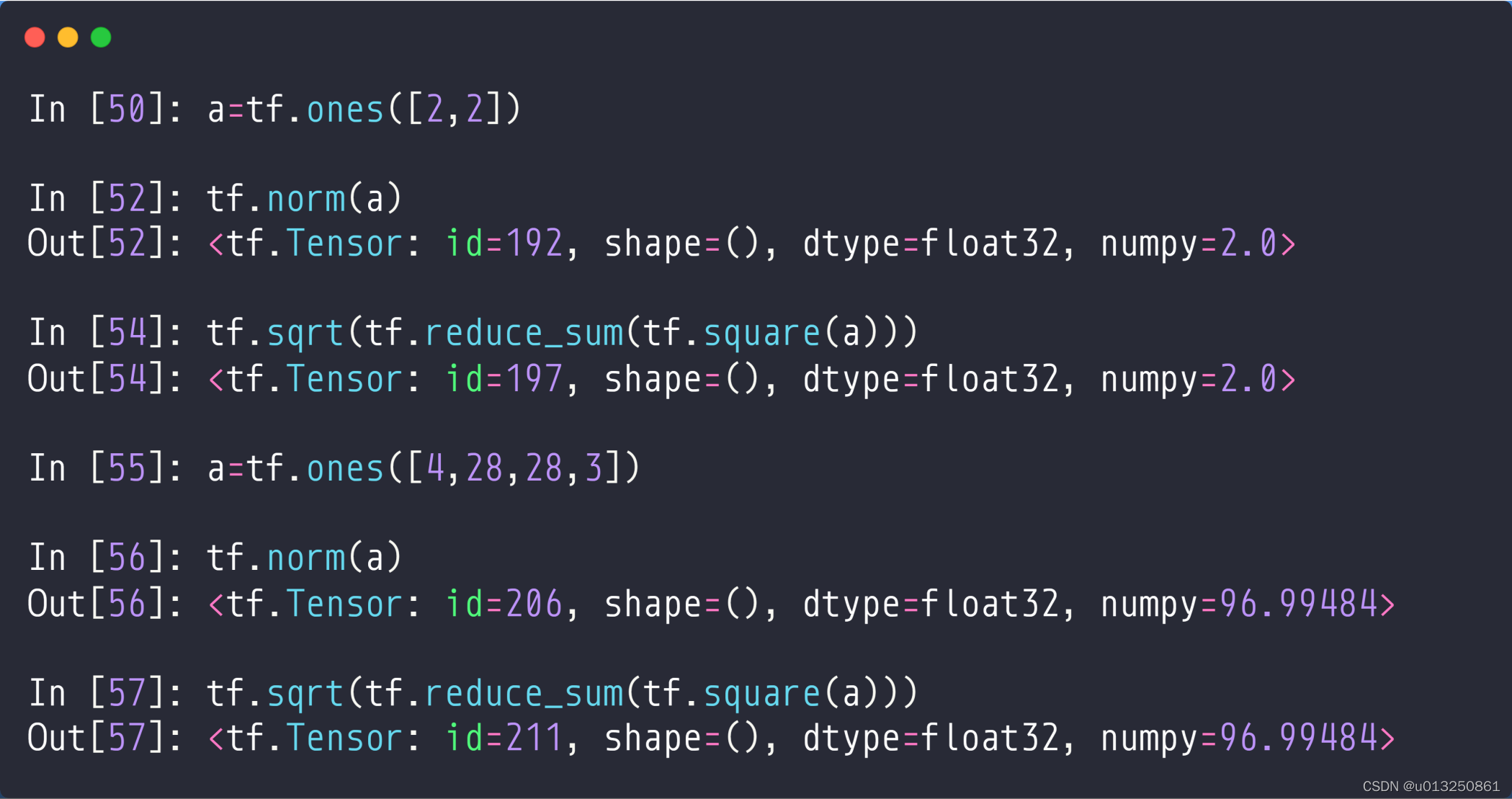
- a = tf.ones([2, 2]): 创建一个2×2元素值都为1的Tensor;
- tf.norm(a) :求解a的二范数,即:
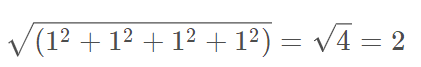
- tf.squrt(tf.reduce_sum(tf.square(a))): 验证tf.norm(a)的正确性,其作用与tf.norm(a)一样;
3、L1 Norm(一范数)
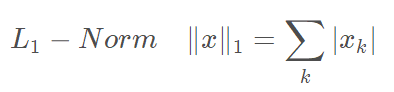
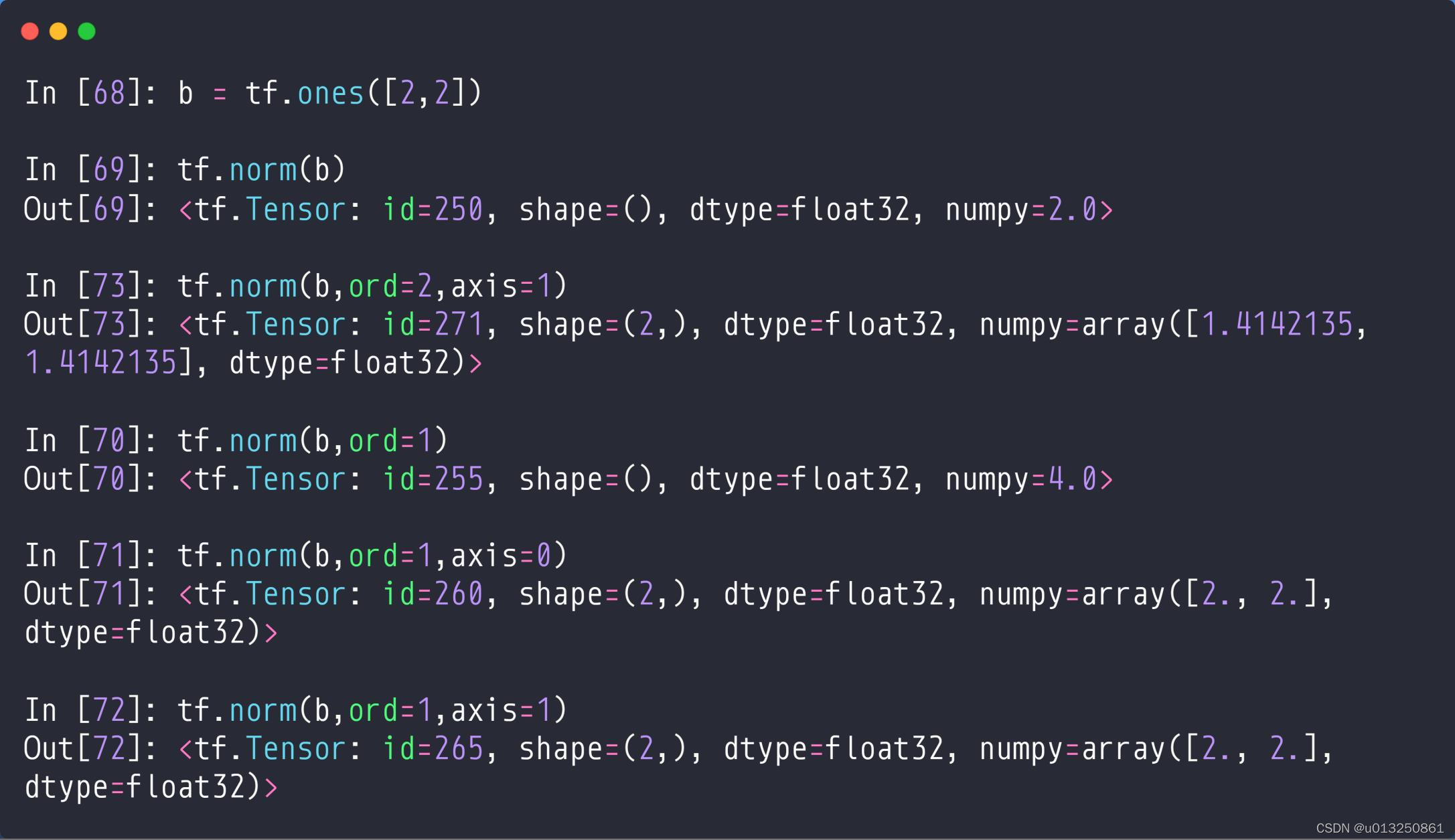
- tf.norm(b): 求b的二范数,即:
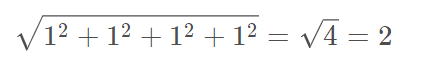
- tf.norm(b, ord=2, axis=1): ord=2表示求b的二范数,axis=1表示求b中第2个维度的二范数,即:
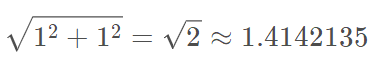
共有2个这样的维度,所以得到一个Tensor(Vector)为: [ 1 , 4142135 , 1.4142135 ] [1,4142135, 1.4142135] [1,4142135,1.4142135]; - tf.norm(b, ord=1): ord=1表示求b的一范数,即:
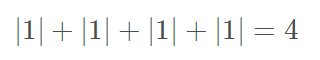
- tf.norm(b, ord=1, axis=0): ord=1表示求b的一范数,axis=0表示求b中第1个维度的二范数,即:

共有2个这样的维度,所以得到一个Tensor(Vector)为: [2., 2.]; - tf.norm(b, ord=1, axis=1): ord=1表示求b的一范数,axis=1表示求b中第2个维度的二范数,即:
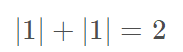
共有2个这样的维度,所以得到一个Tensor(Vector)为: [2., 2.];
二. reduce_min/max/mean
例如:
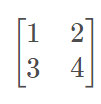
reduce_min()操作就是选取第1行中的最小值1,再选取第2行中的最小值3,就变为:
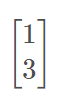
reduce_max()和reduce_mean()操作同理。可以看到reduce操作是一个减维的过程,shape由[2, 2]变为了[2];

- 不指定axis参数,默认求解整个a的reduce_min/max/mean;
- 指定axis参数,则求解该维度下的reduce_min/max/mean;
三. argmax/argmin
例如,有矩阵:
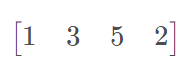
tf.argmax()就是取最大值5所在的位置,也就是2,所以argmax=[2]; tf.argmax().shape=[1];
如果有矩阵:
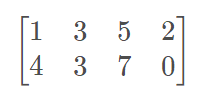
tf.argmax()就是取第一行最大值5所在的位置,也就是2; 再取第一行最大值7所在的位置,也就是2; 所以argmax=[2, 2];
tf.argmax().shape=[2];
tf.argmin()同理。
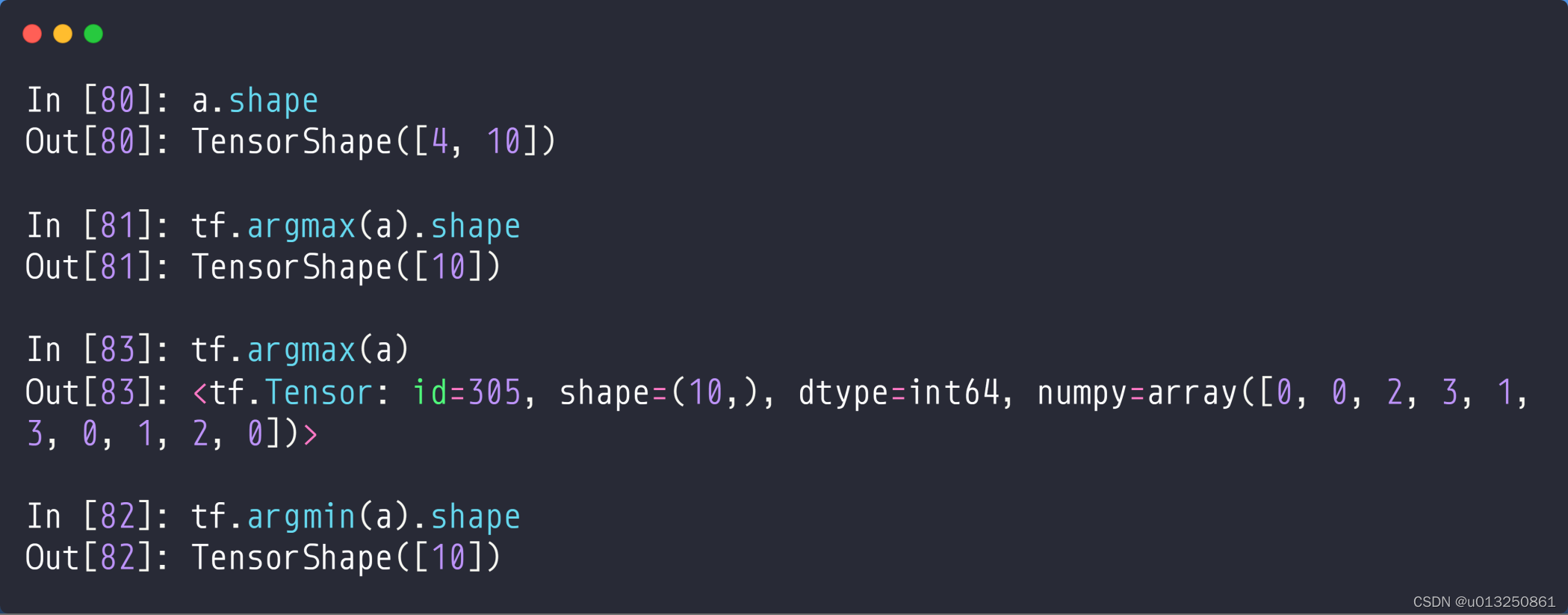
- tf.argmax(a).shape: 如果没有指定axis,那么默认取第1个维度,共有10个4行,也就是说,取这10个4行中每一行的最大值的所在位置,所以其shape=[10];
- tf.argmax(a): 取这10个4行中每一行的最大值的所在位置
- tf.argmin(a): 取这10个4行中每一行的最小值的所在位置,所以其shape=[10];
注: argmax/argmin返回的是一个index,所以其数据类型为int64。
四. tf.equal
1、tf.equal定义及用法

- tf.equal(a, b): 将a和b的元素值作比较,一样就为True,不一样就为False。所以tf.equal(a, b)=[False, False, False, False, False];
- tf.reduce_sum(tf.cast(res, dtype=tf.int32)): cast(res, dtype=tf.int32)表示先将res中的数据类型转换为tf.int32,也就是说,Ture转换为1,False转换为0,即得到一个 [0, 0, 0, 0, 0] 的Tensor; 再利用tf.reduce_sum()函数计算累加和,即 0 + 0 + 0 + 0 + 0 = 0 0 + 0 + 0 + 0 + 0 = 0 0+0+0+0+0=0; 这个值代表了a和b之间相同元素值的个数,通常用于求解正确率,例如pred(预测值)和label(标签值)之间相同元素的个数,再除以总数据量,就为正确率。
2、求解正确率(Accuracy)实例
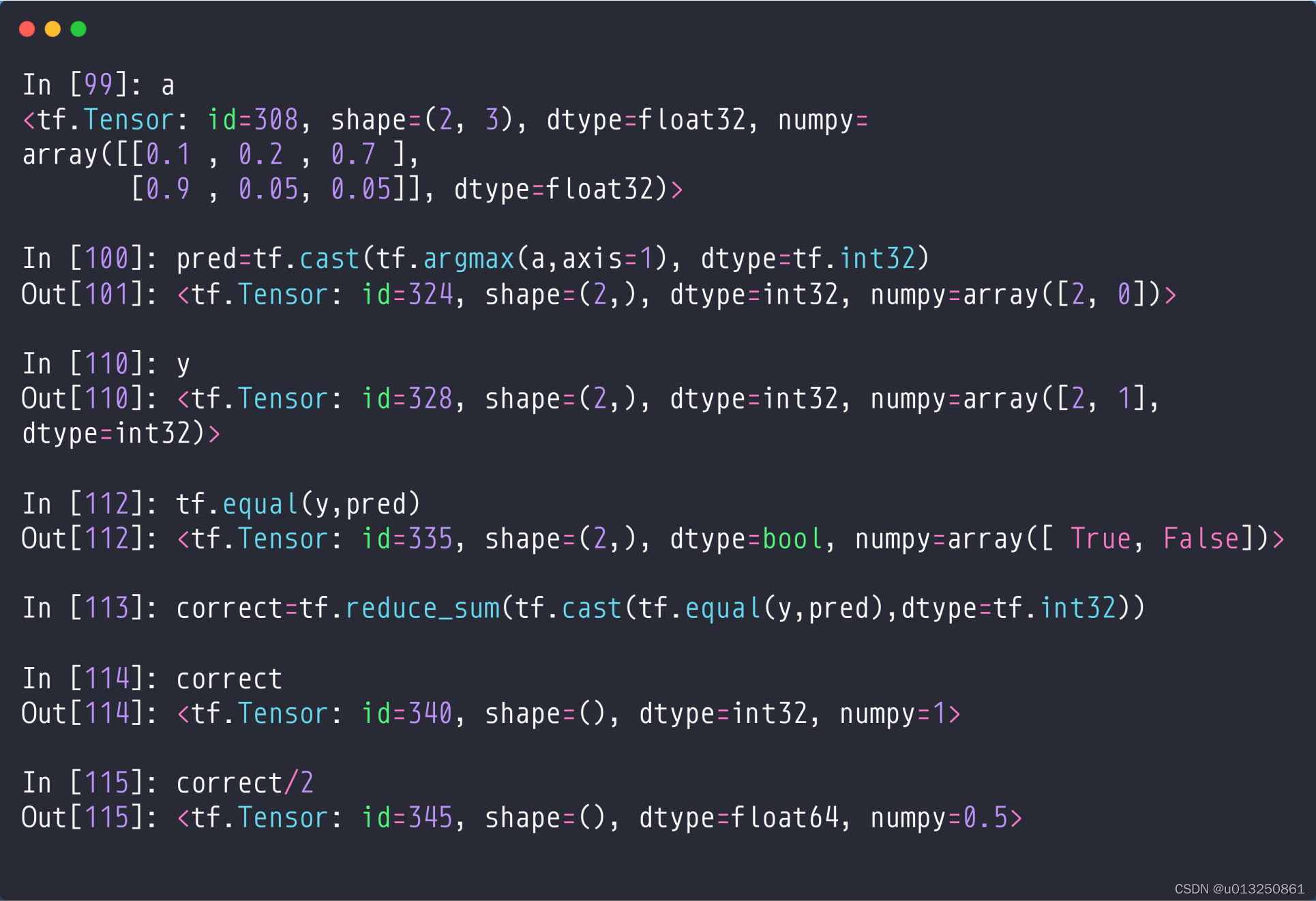
a = [[0.1, 0.2, 0.7], [0.9, 0.05, 0.05]]: 可以理解为第1个数字为“0”的概率为0.1,为“1”的概率为0.2,为“2”的概率为0.7; 第2个数字为“0”的概率为0.9,为“1”的概率为0.05,为“2”的概率为0.05;pred = tf.cast(tf.argmax(a, axis=1), dtype=tf.int32): tf.argmax(a, axis=1)表示求出a中第2个维度,即一共有2个3列,求每个3列的最大值的所在位置,得到一个index,第1个3列最大值0.7的所在位置是2,第2个3列最大值0.9的所在位置是0,所以index=[2, 0],数据类型为in64; 再利用tf.cast()函数将这个index转换为tf.int32的数据类型;- y为每个元素的label值,y=[2, 1]代表第1个数字的标签值为2,第2个数字的标签值为1;
tf.equal(y, pred): 利用equal()函数计算标签值y与预测值pred之间的不同的元素,得到一个Tensor: [True, False];correct = tf.reduce_sum(tf.cast(tf.equal(y, pred), dtype=tf.int32)): tf.cast(tf.equal(y, pred), dtype=tf.int32)表示将[True, False]转换为[1, 0]; 再利用tf.reduce_sum()函数计算pred(预测值)和label(标签值)之间相同元素的个数,correct=1表示只有1个元素是相同的,也就是说pred(预测值)和label(标签值)之间只有1个数字对上号了;correct/2: correct除以数据总量2为计算正确率,correct/2=0.5表示正确率为50%。
五、tf.unique
tf.unique()的作用是去除重复的元素。
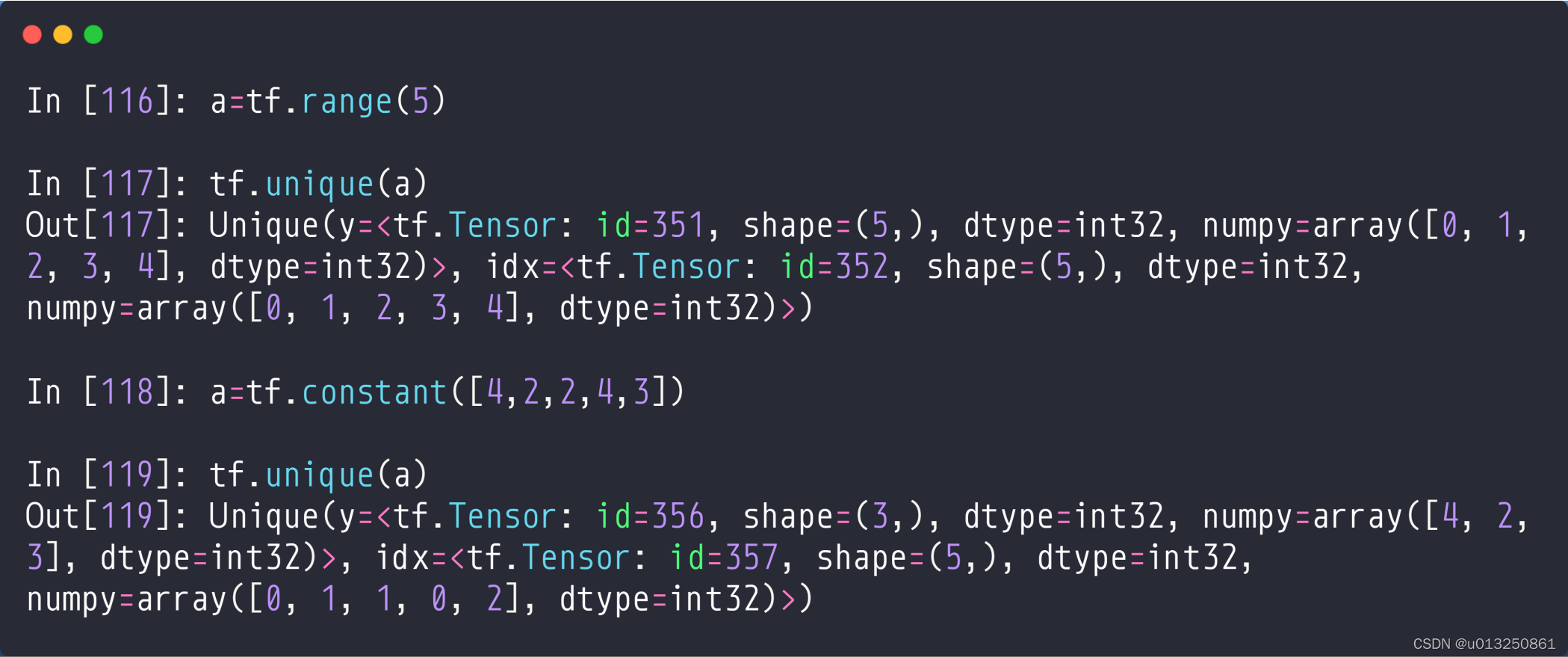
- a = [0, 1, 2, 3, 4]
tf.unique(a): 可以理解为首先建立一张没有重复元素的表单[0, 1, 2, 3, 4],然后建立对应的索引[0, 1, 2, 3, 4],最后将a中的元素按照新建表单(即没有重复元素的表单)的索引排列,即为[0, 1, 2, 3, 4]; - a = [4, 2, 2, 4, 3]
tf.unique(a): 可以理解为首先建立一张没有重复元素的表单[4, 2, 3],然后建立对应的索引[0, 1, 2],最后将a中的元素按照新建表单(即没有重复元素的表单)的索引排列,即为[0, 1, 1, 0, 2];
注: 这个操作是可以还原的,通过tf.gather(unique, idx)来返回原来的Tensor,其中unique为[4, 2, 3],idx为[0, 1, 1, 0, 2],最终得到[4, 2, 2, 4, 3]。
参考资料:
深度学习(13)TensorFlow高阶操作二: 数据统计
TensorFlow进阶(2.数据统计)
Tensorflow数据统计
TensorFlow高阶操作之数据统计
tensorflow数据统计
TensorFlow-数据统计


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









