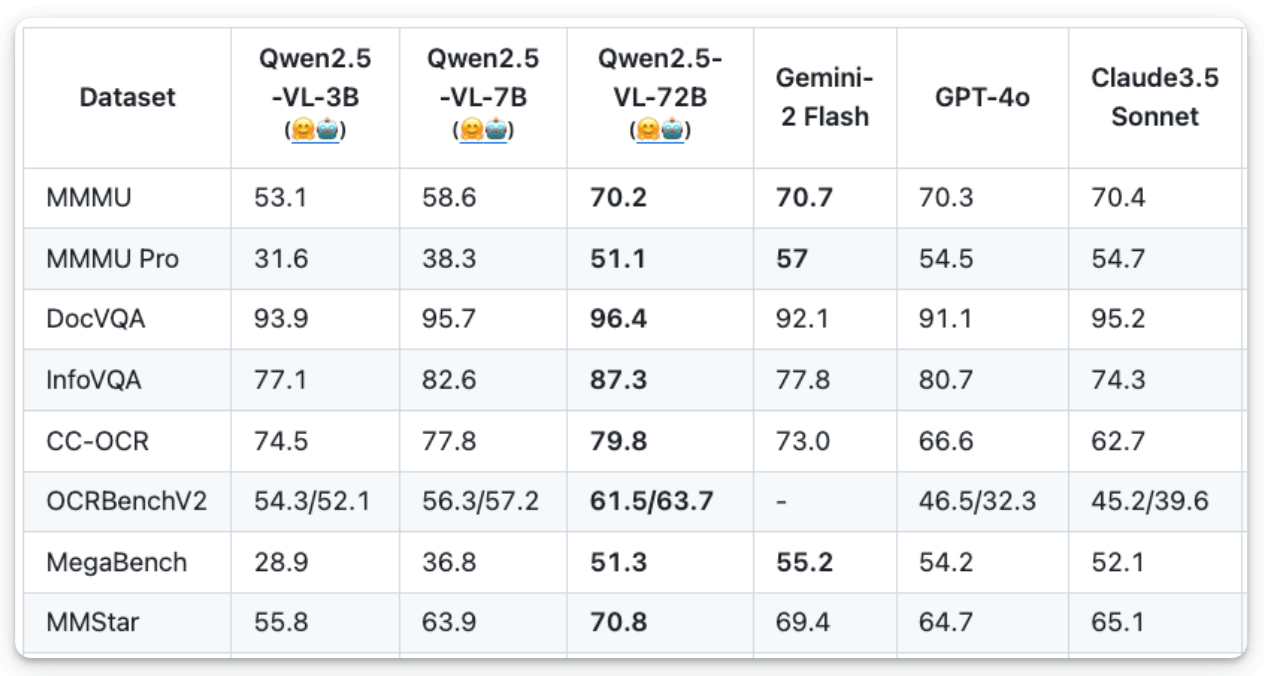
Recently, the Qwen team at Alibaba Cloud released the Qwen2.5-VL series, a multimodal LLM, outperforming most powerful LLMs: 最近,阿里云的 Qwen 团队发布了 Qwen2.5-VL 系列,这是一款多模态 LLM,性能超过了大多数强大的 LLMs:


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1656
1656






{kind=link}