







 本文介绍了Apex库在PyTorch中的应用,用于实现混合精度训练,以减小模型显存占用并加速计算。详细讨论了混合精度训练的目的、Apex的功能以及其在处理梯度溢出和舍入误差方面的策略。通过amp.initialize()和amp.scale_loss()等关键代码,阐述了如何实现和优化混合精度训练。同时,指出了Apex的不支持DataParallel多卡训练等缺点。
本文介绍了Apex库在PyTorch中的应用,用于实现混合精度训练,以减小模型显存占用并加速计算。详细讨论了混合精度训练的目的、Apex的功能以及其在处理梯度溢出和舍入误差方面的策略。通过amp.initialize()和amp.scale_loss()等关键代码,阐述了如何实现和优化混合精度训练。同时,指出了Apex的不支持DataParallel多卡训练等缺点。

apex(A PyTorch Extension: 主要用到:Automatic Mixed Precision)
- 使用
-
- 导入 from apex import amp
-
- 改造模型和优化器
- model, optim = amp.initialize(model, optim, opt_level=‘O1’, verbosity=0)
-
- 改造loss,加入loss裁剪
- with amp.scale_loss(loss, optim) as scaled_loss:
- … scaled_loss.backward()
-
一、概述
1、混合精度训练的目的
训练网络的基本上都是在N卡上面执行的,数据集比较大时,训练网络会耗费大量的时间。由于我们需要使用反向传播来更新具有细微变化的权重,因而我们在训练网络的过程中通常会选用FP32类型的数据和权重。
混合精度训练,即当你使用N卡训练你的网络时,混合精度会在内存中用FP16做储存和乘法从而加速计算,用FP32做累加避免舍入误差。
- 优势就是可以使你的训练时间减少一半左右。
- 缺陷是只能在支持FP16操作的一些特定类型的显卡上面使用,而且会存在溢出误差和舍入误差。
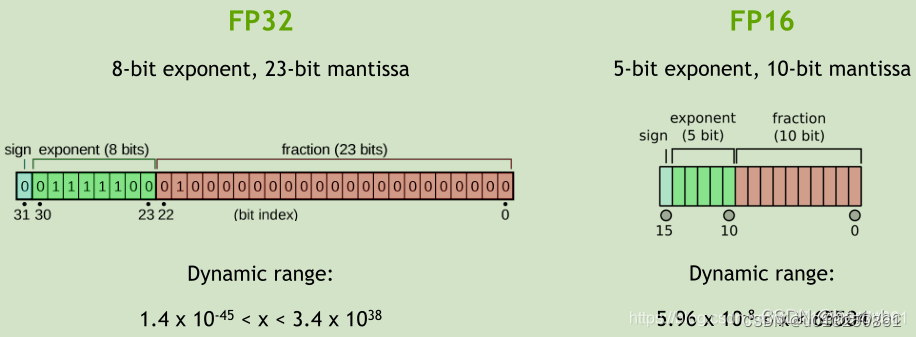
FP32和FP16都是用来表示某一个数值;
FP32和FP16都是由符号位、指数和尾数一起组成;
即FP16最大能够表示的数字是65503;

FP16计算速度更快、更加节约内存
计算同样的操作,FP16可以获得8倍的加速、2倍左右的内存扇出、节省1/2的内存资源;
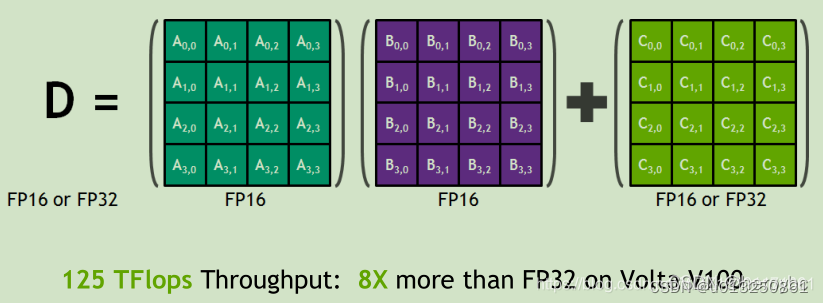
下图展示了执行卷积的过程(乘操作和加操作)
2、F16缺点
2.1 缺点1:FP16会带来梯度溢出错误
比FP32的动态范围小了很多,因而在计算的过程中很容易出现上溢出(超出能够表示的最大数值)和下溢出(超出能够表示的最小数值)问题,溢出之后就会出现NAN的问题。在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。
2.2 缺点2:FP16会带来舍入误差
舍入误差,即当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,具体的细节如下图所示,由于更新的梯度值超出了FP16能够表示的最小值的范围,因此该数值将会被舍弃,这个权重将不进行更新。

二、混合精度训练方案:APEX
1、APEX是什么
APEX是英伟达开源的,完美支持PyTorch框架,用于改变数据格式来减小模型显存占用的工具。其中最有价值的是amp(Automatic Mixed Precision),将模型的大部分操作都用Float16数据类型测试,一些特别操作仍然使用Float32。并且用户仅仅通过三行代码即可完美将自己的训练代码迁移到该模型。实验证明,使用Float16作为大部分操作的数据类型,并没有降低参数,在一些实验中,反而由于可以增大Batch size,带来精度上的提升,以及训练速度上的提升。
2、查看能否正确导入apex
from apex import amp
使用混合精度训练。所谓的混合精度训练,即在内存中用FP16做储存和乘法从而加速计算,用FP32做累加避免舍入误差,这样可以很好的解决舍入误差的问题。
损失放大。有些情况下,即使使用了混合精度训练的方法,由于激活梯度的值太小,会造成下溢出,从而导致模型无法收敛的问题。所谓的损失放大,即反向传播前,将损失变化(dLoss)手动增大2^k,因此反向传播时得到的中间变量(激活函数梯度&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5854
5854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









