







若需观看机器人系列相关博客,请劳驾至:【足式机器人无死角系列之-【强化学习基础-通用】、【仿真及训练环境】、【强化学习】:isaac-gym 与 isaac-lab 从零开始
郑重声明:该系列博客为本人 ( W e n h a i Z h u ) 独家私有 , 禁止转载与抄袭 , 首次举报有谢 , 若有需请私信授权! \color{red}郑重声明:该系列博客为本人(WenhaiZhu)独家私有,禁止转载与抄袭,首次举报有谢,若有需请私信授权! 郑重声明:该系列博客为本人(WenhaiZhu)独家私有,禁止转载与抄袭,首次举报有谢,若有需请私信授权!
| 该篇博客开始,则认为读者环境部分已经都解决了,且能够进行简单的训练与 play 可视化之后的结果,若对环境搭建存在疑问的朋友请阅读前面的博客,进行环境搭建。 注意:如果有提示大家,[大致过一遍即可,不用在意细节] 的地方,就不要钻牛角尖,快速阅读一下即可,后面会回过来百分百的进行详细分析。 |
本系列博客链接为: {\color{blue}本系列博客链接为:} 本系列博客链接为:【05.isaac-lab】最新从零无死角系列-(00) 目录最新无死角源码讲解:https://blog.csdn.net/weixin_43013761/article/details/143084425
本博客编写于: 20241228 ,台式机为 u b u n t u 20.04 , 3090 G e F o r c e R T X 显存 24 G { \color{purple} 本博客编写于:20241228,台式机为 ubuntu 20.04,3090 GeForce RTX 显存24G} 本博客编写于:20241228,台式机为ubuntu20.04,3090GeForceRTX显存24G:与你现在的代码,或者环境等存在一定差异也在情理之中,故切勿认为该系列博客绝对正确,且百密必有一疏,若发现错误处,恳请各位读者直接指出,本人会尽快进行整改,尽量使得后面的读者少踩坑,评论部分我会进行记录与感谢,只有这样,该系列博客才能成为精品,这里先拜谢各位朋友了。
文末正下方中心提供了本人 联系方式, 点击本人照片即可显示 W X → 官方认证,请备注 强化学习 。 {\color{blue}{文末正下方中心}提供了本人 \color{red} 联系方式,\color{blue}点击本人照片即可显示WX→官方认证,请备注\color{red} 强化学习}。 文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证,请备注强化学习。
一、前言
| 通过前面两篇博客,已经完成了环境搭建,下面就是对源码进行分析了,接下来该系列博客应该对 isaac-lab 源码进行讲解,本人不漏过任何细节,进行全面的分析,后续的工程与代码可能就没有这个待遇了。(* ̄︶ ̄) 重点: 这里学到的,不仅仅是代码的理解,而是会告诉你应该如何取分析一套陌生,或者不熟悉的强化学习代码,通用思维与技巧,只要看明白这一系列博客,后面所有强化学习的代码或开源项目应该都是有能力独立阅读的。 思来想去,本人最终于还是决定从主体框架入手进行讲解,只有知道整体流程是如何的,在后续分析细节时才能不迷惘,所以顺着以下思路对代码进行剖析: 1: 了解 Isaac-sim 设计理念与基本结构 --> 该篇博客。 2: 掌握训练过程的总体流程(以任务为导向)。 3: 环境与强化学习库,或者强化学习算法是如何联系到一起的。 4: ......待定 个人感觉,只要知道了这些东西,对于工程的整体把控应该算是不错了,后续就是细节的解刨了:比如如何创建带相机的机器人;如何构建各总各样的地形;如何获取网络的输出的力矩对机器人进行控制等。 |
在正式讲解之前,来看一下 https://docs.robotsfan.com/isaaclab/source/setup/ecosystem.html,其描述了 isaac-lab 与 isaac-sim 以及 NVIDIA Omniverse 之间的关系:
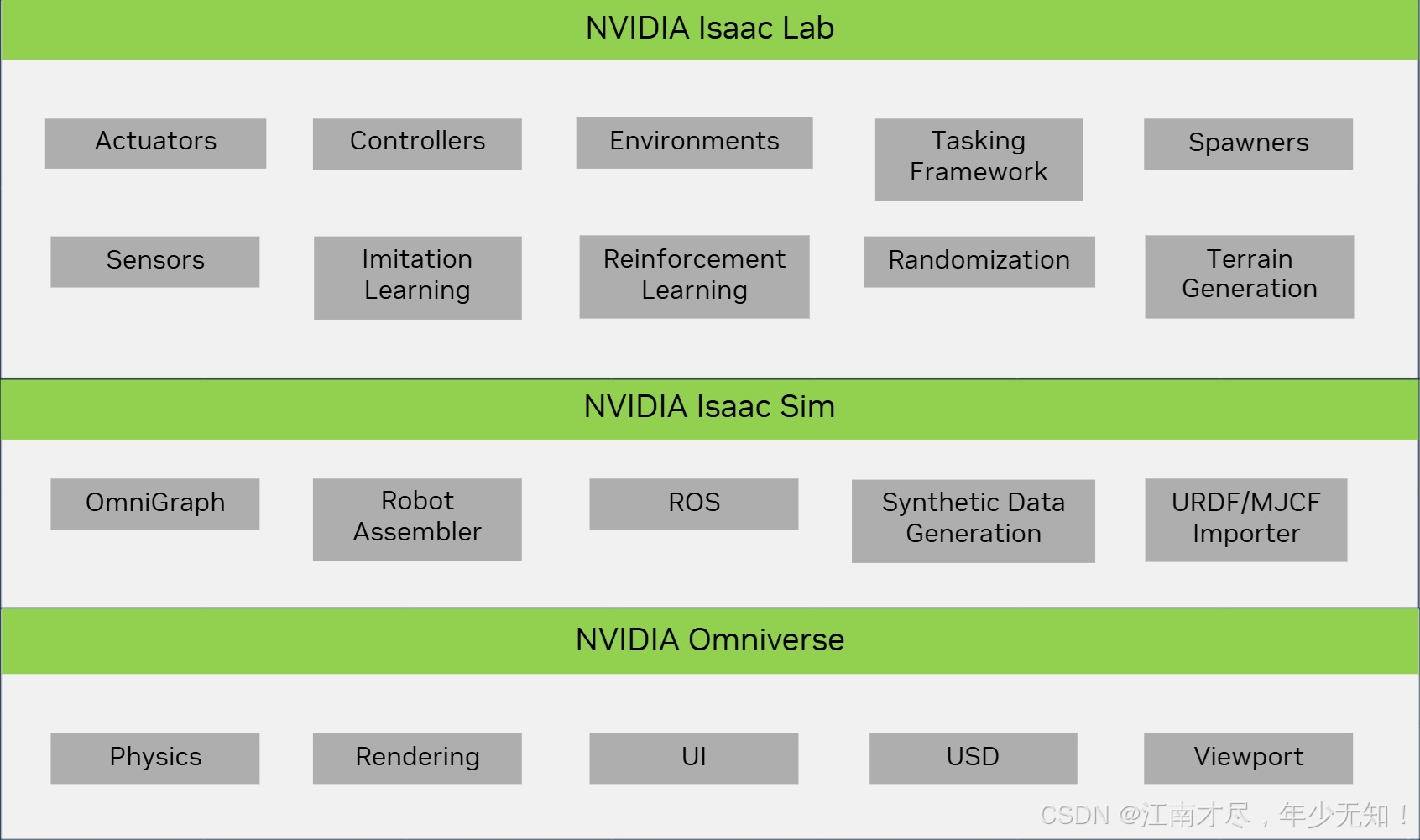
NVIDIA Omniverse: 翻译过来叫宇宙,其实本质上来说就是一个物理引擎,负责最底层的力学逻辑与渲染工作,同时集成了用户界面系统,场景描述主要使用USD格式,其为通用场景描述,用于3D资产管理。
NVIDIA Isaac-sim: 就是对 Omniverse 的包装,利用其最基本的物理引擎构与渲染功能,构建了一套机器人装配器(Robot Assembler),用于构建和配置机器人模型;且开发了图形化编程功能;另外还扩展了 ROS 桥,便于机器人通信;此外还做了机器人格式数据的转换功能,如 URDF/MJCF/USD 之间的相互转换。
NVIDIA Isaac-lab: 是对 Isaac-sim 更上一层的封装,主要是针对于智能体的强化学习。封装的目的是为了把强化学习中的各个模块独立开来如:
执行器(Actuators): 控制机器人运动部件的组件
控制器(Controllers): 实现运动控制算法的模块
环境(Environments): 用于模拟训练的虚拟环境
任务框架(Tasking Framework): 管理和协调机器人任务
生成器(Spawners): 在模拟环境中生成物体和机器人
随机化(Randomization): 增加训练数据的多样性
模仿学习(Imitation Learning): 通过示范学习行为
地形生成(Terrain Generation): 创建各种模拟环境地形
… …
这样独立解耦的目的,是为了在同一框架下,或者同一机制下兼容多个强化学习库,如 SKRL、RSL-RL、RL-Games、Stable-Baselines3。这些强化学习库都是被广泛应用的,且使用 Isaac-lab 很容易引入,扩展其他的强化学习库。
| 直白的说:就是通一套环境,可以跑各种各样的强化学习算法,很容易对算法进行迁移与对比,且部署流程比较相近,避免很多重复性的工作。 |
二、任务设计工作流程
其实官方文档:https://docs.robotsfan.com/isaaclab/source/overview/core-concepts/task_workflows.html 有简单的说明 isaac-lab 整体任务设计流程。主要分为 管理器式环境 {\color{blue}管理器式环境} 管理器式环境 与 直接式环境 {\color{blue}直接式环境} 直接式环境。 后续主要讲解的就是前者 管理器式环境 任务流程相关源码。
1.管理器式环境
上述官方文档可以找到图示如下图示(虽然为官方给出,比较权威,但并没有进行详细介绍,所以初步看起来还是不太好明白的):

本人初次看上图的时候也是比较迷惘的,其实等到后续分析过源码之后再来理解这个图示就是十分简单了,前面提到 Isaac-lab 主要的目的就是把强化学习中各个模块都独立开来。为了实现这个目的,源码中将各个模块设计为独立类管理的各个组件,一达到解耦的目的。
图示中可以看到很多管理器,比如 Action Manager、Command Manager、Observation Manager 等等,其都是专注于自己的相关部分,就拿 Command Manager 来说,其主要包含姿态、速度以及用户自定义的指令等。不同管理器之间的协调由类 envs.ManagerBasedRLEnv 协调。 它接收一个任务配置类实例 ( envs.ManagerBasedRLEnvCfg ),其中包含任务各个组件的配置。 根据配置,设置场景并初始化任务。 然后,通过环境进行步进时,依次调用所有管理器执行必要的操作。
为了他们自己的任务,我们期望用户主要定义任务配置类,并使用现有的 envs.ManagerBasedRLEnv 类进行任务实现。任务配置类应继承自基类 envs.ManagerBasedRLEnvCfg,并包含分配给每个组件的各种配置类的变量(例如 ObservationCfg 和 RewardCfg)。直白的说,每个管理器都会有属于自己的配置类,该配置类应该继承自 envs.ManagerBasedRLEnvCfg。
2.直接式的环境
直接式的环境更符合传统环境实现,其中单个脚本直接实现奖励函数、观测函数、重置和环境的所有其他组件。这种方法不需要管理类。相反,用户可以通过基类 envs.DirectRLEnv 或 envs.DirectMARLEnv 的API自由实现他们的任务。对于从 IsaacGymEnvs 和 OmniIsaacGymEnvs 框架迁移的用户,这种工作流程可能更为熟悉。
 在使用直接式实现定义环境时,我们期望用户定义一个实现整个环境的单个类。任务类应该继承自基类 envs.DirectRLEnv 或 envs.DirectMARLEnv,并且应该有其相应的配置类,该配置类分别继承自 envs.DirectRLEnvCfg 或 envs.DirectMARLEnvCfg 。任务类负责设置场景、处理动作、计算奖励、观测、重置和终止信号。
在使用直接式实现定义环境时,我们期望用户定义一个实现整个环境的单个类。任务类应该继承自基类 envs.DirectRLEnv 或 envs.DirectMARLEnv,并且应该有其相应的配置类,该配置类分别继承自 envs.DirectRLEnvCfg 或 envs.DirectMARLEnvCfg 。任务类负责设置场景、处理动作、计算奖励、观测、重置和终止信号。
三、强化学习库比较
首先要明白一点,isaac-sim 是一个相对底层的物理仿真系统,其并不直接具备强化学习功能。isaac-lab 则是对进行封装,去能与强化学习库进行组合,详细细节可以参考 https://docs.robotsfan.com/isaaclab/source/overview/reinforcement-learning/rl_frameworks.html
有的朋友可能会比较好奇,强化学习的库主流的有好几个,比如说:SKRL、RSL-RL、RL-Games 等,要知道他们的参数配置,数据格式,以及输入标准都是不一样的,isaac-lab 是如何对他们进行统一的呢?这个就要涉及到强化学习包装器 :https://docs.robotsfan.com/isaaclab/source/overview/reinforcement-learning/rl_existing_scripts.html,可以理解为一个适配器,或者数据接口转换器,且支持用户自定义。这里先不做过多讲解,因为后续博客会对其进行十分详细的解刨。
关于支持的强化学习库,官方已经给出了一些介绍,其源码或详细链接分别为:
SKRL:https://skrl.readthedocs.io/en/latest
rsl_rl:https://github.com/leggedrobotics/rsl_rl
rl_games:https://github.com/Denys88/rl_games
Stable-Baselines3:https://stable-baselines3.readthedocs.io/en/master/index.html
每个强化学习库,支持那些强化学习算法,使用的深度学习框架,生态环境等都给出了详细介绍:

且对使用单个RTX 4090 GPU,同一个 Isaac-Humanoid-v0 环境下,使用 --headless 模式进行了每个RL库的训练,并记录了每个RL库在65.5M步的总训练时间。

后续过程中,首先以 rsl_rl 库为主,进行学习与讲解,因为本人方向主要为足式机器人,且对该库比较熟悉。不过后续过程中会进行拓展,对其他强化学习库也进行讲解与剖析。如果需知道每个库当个算法的性能,可以参考:https://docs.robotsfan.com/isaaclab/source/overview/reinforcement-learning/performance_benchmarks.html
四、Hydra 配置系统
其实该部分内容在文档中,已经有相当不错的讲解:https://docs.robotsfan.com/isaaclab/source/features/hydra.html,不过本人这里依旧需要记录一下,主要用于个人回顾。
熟悉 legged_gym 的朋友应该知道,训练过程中包含的参数实在太多,比如说地形、相机、触地、关节、回报、训练、神经网络等相关配置。通常来说都是基于配置文件进行配置。命令行也有一些可以配置的参数,如:“–seed”、“–num_envs”、“–headless”。但是显然,其定然是有限。总的来说呢,启动训练时,无法通过命令行进行任意参数的修改,大部分参数都只能通过命令行进行修改。
但是 isaac-lab 集成了 Hydra 机制,可以在执行指令进行训练时,通过命令行进行任意参数的修改,官方的介绍为:Isaac Lab 支持 Hydra 配置系统,以通过命令行参数修改任务的配置,这对于自动化实验和执行超参数调整非常有用。
环境的任何参数都可以通过在命令行输入中添加一个或多个形式为 env.a.b.param1=value 的元素来修改,其中 a.b.param1 反映了参数的层次结构,例如 env.actions.joint_effort.scale=10.0 。类似地,智能体的参数可以通过使用 agent 前缀来修改,例如 agent.seed=2024 。
这些命令行参数的设置方式遵循配置文件的精确结构。由于不同的 RL 框架使用不同的约定,因此参数设置方式可能会有所不同。例如,使用 rl_games 时,种子将通过 agent.params.seed 设置,而在 rsl_rl 、 skrl 和 sb3 中,则通过 agent.seed 设置。因此,使用 hydra 参数进行训练可以使用以下语法运行:
# rsl_rl
python scripts/reinforcement_learning/rsl_rl/train.py --task=Isaac-Cartpole-v0 --headless env.actions.joint_effort.scale=10.0 agent.seed=2024
# rl_games
python scripts/reinforcement_learning/rl_games/train.py --task=Isaac-Cartpole-v0 --headless env.actions.joint_effort.scale=10.0 agent.params.seed=2024
# skrl
python scripts/reinforcement_learning/skrl/train.py --task=Isaac-Cartpole-v0 --headless env.actions.joint_effort.scale=10.0 agent.seed=2024
# sb3
python scripts/reinforcement_learning/sb3/train.py --task=Isaac-Cartpole-v0 --headless env.actions.joint_effort.scale=10.0 agent.seed=2024
上述命令将以无头模式运行任务 Isaac-Cartpole-v0 的训练脚本,并将 env.actions.joint_effort.scale 参数设置为 10.0,以及将 agent.seed 参数设置为 2024。为了保持向后兼容性,并提供更友好的用户体验,保留了旧的 cli 参数形式 --param,例如 --num_envs、–seed、–max_iterations 。这些参数优先于 hydra 参数,并将覆盖由 hydra 参数设置的值。
1.将参数设置为 None
要将参数设置为 None,请使用 null 关键字,这是 Hydra 中的一个特殊关键字,会自动转换为 None。在上面的示例中,我们还可以通过将 env.observations.policy.joint_pos_rel=null 设置为 None 来禁用 joint_pos_rel 观察。
2.可调用对象
可以通过使用语法 module:attribute_name 修改配置文件中的函数和类。例如,在 Cartpole 环境中:
class ObservationsCfg:
"""Observation specifications for the MDP."""
@configclass
class PolicyCfg(ObsGroup):
"""Observations for policy group."""
# observation terms (order preserved)
joint_pos_rel = ObsTerm(func=mdp.joint_pos_rel)
joint_vel_rel = ObsTerm(func=mdp.joint_vel_rel)
......
# observation groups
policy: PolicyCfg = PolicyCfg()
其中的 joint_pos_rel 是一个 ObsTerm 的实例对象,改类包含了函数属性 func,并不是一个普通的参数。比如说初始配置中 joint_pos_rel 中 func 绑定的是 mdp.joint_pos_rel 函数,可以通过如下指令设置为 mdp.joint_vel_rel 函数,也就是可以修改 joint_pos_rel 以计算绝对位置,而不是相对位置:
# 附加在启动指令后面即可
env.observations.policy.joint_pos_rel.func=omni.isaac.lab.envs.mdp:joint_pos 。
3.注意事项
在使用命令行参数修改参数时应特别小心。一些配置会根据其他参数执行中间计算。这些计算在参数被修改时不会更新。 例如,对于 Cartpole 相机深度环境的配置:
class CartpoleDepthCameraEnvCfg(CartpoleRGBCameraEnvCfg):
# camera
tiled_camera: TiledCameraCfg = TiledCameraCfg(
prim_path="/World/envs/env_.*/Camera",
offset=TiledCameraCfg.OffsetCfg(pos=(-5.0, 0.0, 2.0), rot=(1.0, 0.0, 0.0, 0.0), convention="world"),
data_types=["depth"],
spawn=sim_utils.PinholeCameraCfg(
focal_length=24.0, focus_distance=400.0, horizontal_aperture=20.955, clipping_range=(0.1, 20.0)
),
width=80,
height=80,
)
# spaces
observation_space = [tiled_camera.height, tiled_camera.width, 1]
如果用户修改了相机的宽度,即 env.tiled_camera.width=128 ,那么参数 env.observation_space=[80,128,1] 也必须更新并作为输入提供。
类似地,post_init 方法不会随着命令行输入而更新。在 LocomotionVelocityRoughEnvCfg 中,例如,post init 更新如下:
class LocomotionVelocityRoughEnvCfg(ManagerBasedRLEnvCfg):
"""Configuration for the locomotion velocity-tracking environment."""
# Scene settings
scene: MySceneCfg = MySceneCfg(num_envs=4096, env_spacing=2.5)
# Basic settings
observations: ObservationsCfg = ObservationsCfg()
actions: ActionsCfg = ActionsCfg()
commands: CommandsCfg = CommandsCfg()
# MDP settings
rewards: RewardsCfg = RewardsCfg()
terminations: TerminationsCfg = TerminationsCfg()
events: EventCfg = EventCfg()
curriculum: CurriculumCfg = CurriculumCfg()
def __post_init__(self):
"""Post initialization."""
# general settings
self.decimation = 4
self.episode_length_s = 20.0
# simulation settings
self.sim.dt = 0.005
self.sim.render_interval = self.decimation
self.sim.disable_contact_processing = True
self.sim.physics_material = self.scene.terrain.physics_material
# update sensor update periods
# we tick all the sensors based on the smallest update period (physics update period)
if self.scene.height_scanner is not None:
self.scene.height_scanner.update_period = self.decimation * self.sim.dt
if self.scene.contact_forces is not None:
self.scene.contact_forces.update_period = self.sim.dt
# check if terrain levels curriculum is enabled - if so, enable curriculum for terrain generator
# this generates terrains with increasing difficulty and is useful for training
if getattr(self.curriculum, "terrain_levels", None) is not None:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = True
else:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = False
在这里,当修改 env.decimation 或 env.sim.dt 时,用户还需要输入更新后的 env.sim.render_interval 、env.scene.height_scanner.update_period 和 env.scene.contact_forces.update_period 。
五、结语
其中 [四、Hydra 配置系统] 介绍的第三点 [3.注意事项] 个人觉得是十分重要的,所以从官方文档摘录下来,起到警惕的作用。通过该篇博客,对于 isaac-lab 的设计理念应该有了一定了解。下篇博客就是正式开始对源码进行分析了,该篇博客以及完成了如下部分的讲解:
| √ 1: 了解 Isaac-sim 设计理念与基本结构。 |



















 4663
4663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











