







输入Nvidia-smi
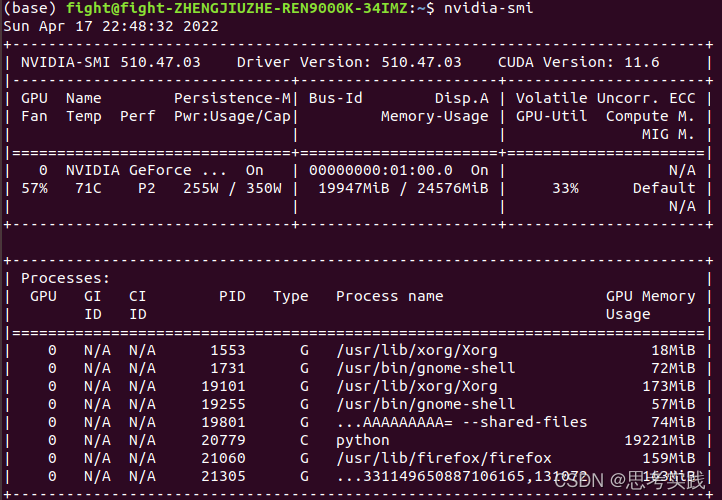
![]()
比如这里面PID:20779占了很大的内存,但程序又没有被停掉,我允许其他程序的时候,就会爆内存(out of memory)。
然后 kill - 9 PID 就可以了,很好用。
参考资料:
输入Nvidia-smi
![]()
比如这里面PID:20779占了很大的内存,但程序又没有被停掉,我允许其他程序的时候,就会爆内存(out of memory)。
然后 kill - 9 PID 就可以了,很好用。
参考资料:
 909
1870
909
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























