







原文链接:https://arxiv.org/abs/2308.09421
1. 引言
目前依靠显式深度估计获取的图像3D表达有局限。首先是提升特征的不均匀分布,即近处密集,远处稀疏。二是检测性能极大依赖于深度估计精度。
NeRF能从已知相机姿态的图像重建密集而细节的3D场景几何与占用信息。受NeRF启发,本文使用类似NeRF的3D表达。首先结合图像特征与归一化的视锥3D坐标,得到3D位置感知的视锥特征。然后用其生成有符号的距离场和辐射场(RGB色彩),距离场将每个位置到其最近表面的距离编码为标量。然后,使用体素渲染技术,通过原始RGB图像和激光雷达点云进行监督,生成RGB图像和深度图。过去的方法是基于预测深度图生成3D表达,而本文是基于3D表达生成深度图。本文的方法能在无需显式的逐网格标注的情况下生成密集的3D占用(体积网格密度)。
3. 准备知识
3.1 有符号距离函数(SDF)
有符号距离函数是空间坐标的连续函数,输出点到最近表面的距离,其符号表示点位于表面的内侧(负)或外侧(正)。
设
Ω
∈
R
3
\Omega\in\mathbb{R}^3
Ω∈R3是占用空间,
M
=
∂
Ω
\mathcal{M}=\partial\Omega
M=∂Ω为边界表面,
Ω
\Omega
Ω的指示函数
1
Ω
(
x
)
=
{
1
,
若
x
∈
Ω
0
,
若
x
∉
Ω
\mathbf{1}_\Omega(x)=\left \{\begin{matrix}1,若x\in\Omega\\0,若x\notin\Omega\end{matrix}\right.
1Ω(x)={1,若x∈Ω0,若x∈/Ω则有距离符号函数为
d
Ω
=
(
−
1
)
1
Ω
(
x
)
min
y
∈
M
∥
x
−
y
∥
d_\Omega=(-1)^{\mathbf{1}_\Omega(x)}\min_{y\in\mathcal{M}}\|x-y\|
dΩ=(−1)1Ω(x)y∈Mmin∥x−y∥其中
∥
⋅
∥
\|\cdot\|
∥⋅∥为标准欧式2范数。表面
M
\mathcal{M}
M可用满足
d
Ω
(
⋅
)
=
0
d_\Omega(\cdot)=0
dΩ(⋅)=0的集合表示。
3.2 将SDF转换为密度
体积网格密度 σ : R 3 → R + \sigma:\mathbb{R}^3\rightarrow\mathbb{R}_+ σ:R3→R+是标量函数,其中 σ ( x ) \sigma(x) σ(x)可解释为光在 x x x处被遮挡的概率。使用可学习的SDF变换建模密度 σ \sigma σ: σ ( x ) = α Ψ β ( − d Ω ( x ) ) \sigma(x)=\alpha\Psi_\beta(-d_\Omega(x)) σ(x)=αΨβ(−dΩ(x))其中 α , β > 0 \alpha,\beta>0 α,β>0为可学习参数, Φ β \Phi_\beta Φβ为均值为0、尺度为 β \beta β的拉普拉斯分布的累积分布函数: Φ β ( s ) = { 1 2 exp ( s β ) , 若 s ≤ 0 1 − 1 2 exp ( − s β ) , 若 s > 0 \Phi_\beta(s)=\left \{\begin{matrix}\frac{1}{2}\exp(\frac{s}{\beta})\ \ \ \ \ \ \ \ \ \ ,若s\leq0\\1-\frac{1}{2}\exp(-\frac{s}{\beta}),若s>0\end{matrix}\right. Φβ(s)={21exp(βs) ,若s≤01−21exp(−βs),若s>0随着 β \beta β趋于0,密度 σ \sigma σ收敛到 Ω \Omega Ω的指示函数,即对于所有 x ∉ Ω \ M x\notin\Omega\backslash\mathcal{M} x∈/Ω\M,有 σ → α 1 Ω \sigma\rightarrow\alpha\mathbf{1}_\Omega σ→α1Ω。本文设置 α = β − 1 \alpha=\beta^{-1} α=β−1。
3.3 体积网格渲染
体积网格强度(RGB色彩) c : R 3 → R 3 c:\mathbb{R}^3\rightarrow\mathbb{R}^3 c:R3→R3是空间坐标的向量函数,其中 c ( x ) c(x) c(x)表示位置 x x x处的强度或颜色。给定颜色 c c c和密度 σ \sigma σ,以近端 t n t_n tn和远端 t f t_f tf为界的射线 r ( t ) = o + t d r(t)=o+td r(t)=o+td(其中 o o o为射线起点, d d d为射线方向)的期望颜色 C ( r ) C(r) C(r)为: C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) ) d t ,其中 T ( t ) = exp ( − ∫ t n t f σ ( r ( s ) ) d s ) C(r)=\int_{t_n}^{t_f}T(t)\sigma(r(t))c(r(t))dt,其中T(t)=\exp\left(-\int_{t_n}^{t_f}\sigma(r(s))ds\right) C(r)=∫tntfT(t)σ(r(t))c(r(t))dt,其中T(t)=exp(−∫tntfσ(r(s))ds)函数 T ( t ) T(t) T(t)表示沿射线从 t n t_n tn到 t t t的积累透射率,即光从 t n t_n tn到 t t t不被遮挡的概率。
4. 方法
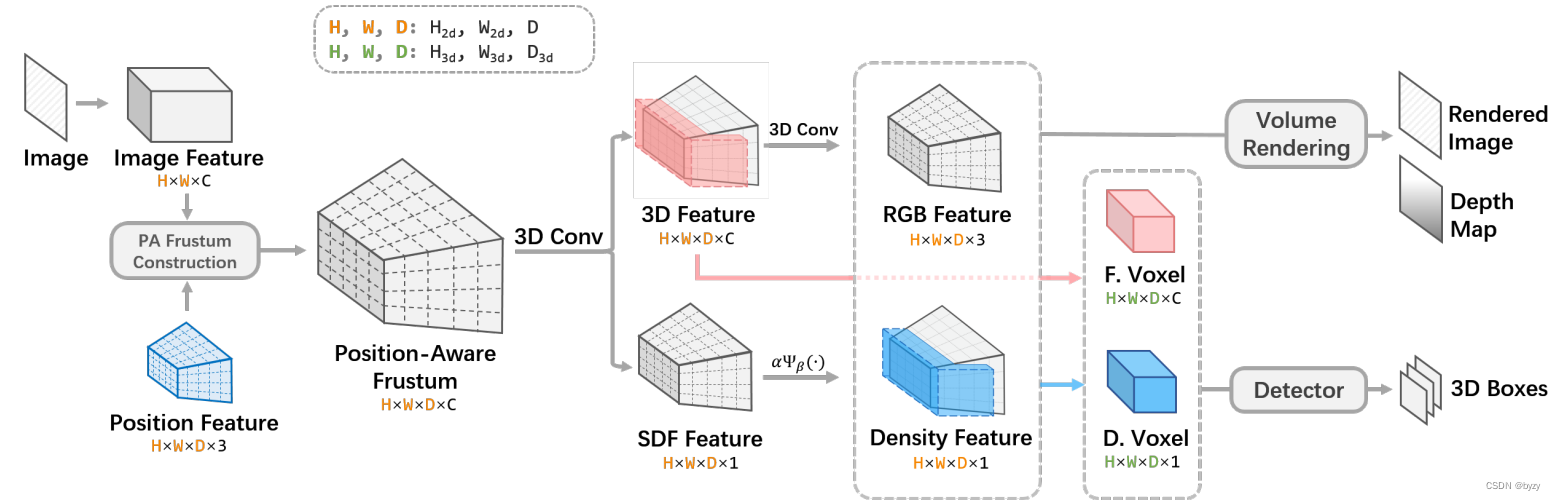
概述:整体框架如上图所示。本文依照LIGA-Stereo(去掉立体视觉部分),将3D特征表达替换为本文的类似NeRF的表达,其余部分(主干网络和检测头)保持不变。
给定图像,首先图像主干提取特征,然后生成类似NeRF的3D表达。具体来说,首先由3D视锥特征和SDF函数特征转换建立位置感知的视锥,并通过体积网格渲染获得RGB和密度信息以渲染RGB图像和深度图(由RGB损失和深度损失监督)。然后,使用网格采样从3D视锥特征建立规则的3D体素和相应的密度,形成3D体素特征,输入检测头。
4.1 类似NeRF的表达
本文使用的类似NeRF表达与NeRF的区别是,NeRF使用MLP编码,需要逐场景训练;而本文的表达从单一RGB图像中预测连续的3D几何信息。
4.1.1 位置感知的视锥建立
在没有深度的情况下将2D图像特征提升到3D空间,最直接的方法就是在不同深度平面复制图像特征。但是这样会导致模糊的空间特征。
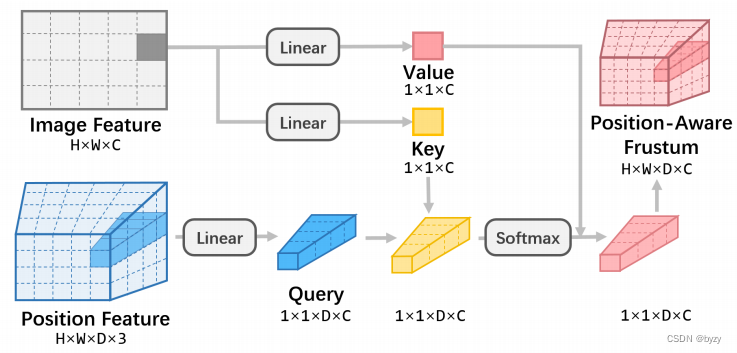
本文使用基于查询的方式,将2D图像特征
F
i
m
a
g
e
∈
R
H
×
W
×
C
F_{image}\in\mathbb{R}^{H\times W\times C}
Fimage∈RH×W×C映射到归一化的3D视锥空间。具体来说,给定最小深度
z
n
z_n
zn和最大深度
z
f
z_f
zf,在深度区间内带随机扰动地等间距采样
D
D
D个平面。每个像素
(
u
,
v
)
(u,v)
(u,v)在每个平面上,都有对应的3D坐标
(
u
,
v
,
z
)
(u,v,z)
(u,v,z)。该坐标会被归一化。这样,得到
F
p
o
s
∈
R
H
×
W
×
D
×
3
F_{pos}\in\mathbb{R}^{H\times W\times D\times3}
Fpos∈RH×W×D×3的3D位置视锥特征。使用线性层将
F
p
o
s
F_{pos}
Fpos映射为
Q
∈
R
H
×
W
×
D
×
C
Q\in\mathbb{R}^{H\times W\times D\times C}
Q∈RH×W×D×C,另外两个线性层将
F
i
m
a
g
e
F_{image}
Fimage映射为
K
,
V
∈
R
H
×
W
×
C
K,V\in\mathbb{R}^{H\times W\times C}
K,V∈RH×W×C,并按下式得到位置感知的视锥特征:
F
P
=
Softmax
(
Q
K
)
V
F_P=\text{Softmax}(QK)V
FP=Softmax(QK)V其中Softmax沿深度维度进行。
4.1.2 视锥内的体积网格渲染
首先进一步使用3D卷积块(softplus激活函数)处理 F P F_P FP,得到 F ′ ∈ R H × W × D × ( 1 + C ) F'\in\mathbb{R}^{H\times W\times D\times (1+C)} F′∈RH×W×D×(1+C)。
i) SDF和密度特征
F ′ F' F′的第一个通道特征被视为SDF特征 F s d f ∈ R H × W × D × 1 F_{sdf}\in\mathbb{R}^{H\times W\times D\times 1} Fsdf∈RH×W×D×1,表达输入图像的场景几何。对任意的3D点,可通过对 F s d f F_{sdf} Fsdf三线性采样得到其有符号距离 s ( x , y , z ) s(x,y,z) s(x,y,z)。然后,场景体积网格密度 σ \sigma σ(或者密度视锥 F d e n s i t y ∈ R H × W × D × 1 F_{density}\in\mathbb{R}^{H\times W\times D\times 1} Fdensity∈RH×W×D×1)可由下式获取: σ ( x , y , z ) = α Ψ β ( s ( x , y , z ) ) F d e n s i t y = α Ψ β ( F s d f ) \sigma(x,y,z)=\alpha\Psi_\beta(s(x,y,z))\\F_{density}=\alpha\Psi_\beta(F_{sdf}) σ(x,y,z)=αΨβ(s(x,y,z))Fdensity=αΨβ(Fsdf)密度将被用于渲染深度图,加权体素特征。
ii) RGB特征
F
′
F'
F′剩下的
C
C
C个通道的特征
F
′
′
∈
R
H
×
W
×
D
×
C
F''\in\mathbb{R}^{H\times W\times D\times C}
F′′∈RH×W×D×C会通过另一个3D卷积块(softmax激活函数),得到近似场景辐射场的
F
r
g
b
∈
R
H
×
W
×
D
×
3
F_{rgb}\in\mathbb{R}^{H\times W\times D\times 3}
Frgb∈RH×W×D×3。同样可使用三线性插值从
F
r
g
b
F_{rgb}
Frgb得到任一一点的色彩强度
c
(
x
,
y
,
z
)
c(x,y,z)
c(x,y,z)。
从原始视图渲染:为节省GPU空间,本文渲染下采样的RGB图像
I
^
l
o
w
\hat{I}_{low}
I^low和深度图
Z
^
l
o
w
\hat{Z}_{low}
Z^low。给定相机参数和一组深度值,
I
^
l
o
w
\hat{I}_{low}
I^low中的一个像素可被投影为若干3D点。相邻两个3D点的距离记为
δ
x
i
,
y
i
,
z
i
\delta_{x_i,y_i,z_i}
δxi,yi,zi。设深度
z
i
z_i
zi处的距离图为
δ
z
i
∈
R
H
×
W
×
1
\delta_{z_i}\in\mathbb{R}^{H\times W\times 1}
δzi∈RH×W×1,并从
F
d
e
n
s
i
t
y
F_{density}
Fdensity和
F
r
g
b
F_{rgb}
Frgb得到密度图
σ
z
i
∈
R
H
×
W
×
1
\sigma_{z_i}\in\mathbb{R}^{H\times W\times 1}
σzi∈RH×W×1和色彩图
c
z
i
∈
R
H
×
W
×
3
c_{z_i}\in\mathbb{R}^{H\times W\times 3}
czi∈RH×W×3。可按下式渲染
I
^
\hat{I}
I^:
I
^
l
o
w
=
∑
i
=
1
D
T
i
(
1
−
exp
(
−
σ
z
i
δ
z
i
)
)
c
z
i
\hat{I}_{low}=\sum_{i=1}^DT_i(1-\exp(-\sigma_{z_i}\delta_{z_i}))c_{z_i}
I^low=i=1∑DTi(1−exp(−σziδzi))czi其中
T
i
=
exp
(
−
∑
j
=
1
i
−
1
σ
z
j
δ
z
j
)
T_i=\exp(-\sum_{j=1}^{i-1}\sigma_{z_j}\delta_{z_j})
Ti=exp(−∑j=1i−1σzjδzj)为从深度平面1到深度平面
i
i
i的积累透射率图。类似地,深度图可按下式渲染:
Z
^
l
o
w
=
∑
i
=
1
D
T
i
(
1
−
exp
(
−
σ
z
i
δ
z
i
)
)
z
i
\hat{Z}_{low}=\sum_{i=1}^DT_i(1-\exp(-\sigma_{z_i}\delta_{z_i}))z_i
Z^low=i=1∑DTi(1−exp(−σziδzi))zi 本文直接将
I
^
l
o
w
\hat{I}_{low}
I^low与
Z
^
l
o
w
\hat{Z}_{low}
Z^low上采样到原始尺寸,得到
I
^
\hat{I}
I^和
Z
^
\hat{Z}
Z^。使用RGB损失和深度损失对上述渲染进行监督。
从其余视图渲染:只要其余视图的视锥与原始视锥重叠且校准矩阵已知,就可从该视图进行渲染。渲染方法与前文相同。这样可以利用其余视图的额外监督。例如,如下图所示,可以从双目相机图像作为体积网格渲染目标,此时甚至可不用深度监督。

4.1.3 体素特征生成
类似CaDDN,使用相机参数和可微采样将视锥体素特征转换为规则体素特征。首先定义体素
V
∈
R
H
′
×
W
′
×
D
′
×
3
V\in\mathbb{R}^{H'\times W'\times D'\times 3}
V∈RH′×W′×D′×3,将各体素中心变换到视锥坐标系,使用三线性采样视锥特征
(
F
′
′
,
F
d
e
n
s
i
t
y
)
(F'',F_{density})
(F′′,Fdensity)得到体素特征
(
V
′
′
,
V
d
e
n
s
i
t
y
)
(V'',V_{density})
(V′′,Vdensity)。
由于密度表示3D占用,本文使用其加强3D体素特征
V
′
′
V''
V′′。最终的3D体素特征为
V
3
d
=
V
′
′
⋅
tanh
(
V
d
e
n
s
i
t
y
)
V_{3d}=V''\cdot\tanh(V_{density})
V3d=V′′⋅tanh(Vdensity)其中
tanh
(
⋅
)
\tanh(\cdot)
tanh(⋅)将
V
d
e
n
s
i
t
y
V_{density}
Vdensity归一化,而
V
3
d
V_{3d}
V3d为类似NeRF的表达,因其和NeRF是以相同的优化方式学习场景几何和占用的。
4.2 损失函数
损失函数包括4项:RGB损失,深度损失,SDF损失和LIGA原始的损失。
RGB损失:包含两项,SmoothL1损失和SSIM损失,这两项经常用于图像重建。
深度损失:使用激光雷达点云投影到图像上获取深度标签。深度损失为稀疏深度图与预测深度图之间的L1损失。
L
d
e
p
t
h
=
1
N
d
e
p
t
h
∑
u
,
v
∥
Z
^
−
Z
∥
1
L_{depth}=\frac{1}{N_{depth}}\sum_{u,v}\|\hat{Z}-Z\|_1
Ldepth=Ndepth1u,v∑∥Z^−Z∥1其中
N
d
e
p
t
h
N_{depth}
Ndepth为有深度标签的像素数。
SDF损失:鼓励
F
s
d
f
F_{sdf}
Fsdf在几何表面
M
\mathcal{M}
M处消失。
L
s
d
f
=
1
N
g
t
∑
x
,
y
,
z
∥
F
s
d
f
(
x
,
y
,
z
)
∥
2
L_{sdf}=\frac{1}{N_{gt}}\sum_{x,y,z}\|F_{sdf}(x,y,z)\|_2
Lsdf=Ngt1x,y,z∑∥Fsdf(x,y,z)∥2其中
N
g
t
N_{gt}
Ngt为当前相机视图内的激光雷达点数。
LIGA损失:保留检测损失、模仿损失和辅助2D监督损失,移除立体深度估计损失。
5. 实验
5.3 主要结果
KITTI:MonoNeRD能在无需额外数据的情况下达到与其余方法可比的性能。
Waymo:MonoNeRD能在无需数据增广和使用轻量级主干的情况下达到与其余方法可比的性能。
5.4 消融研究
结构组件:实验表明,只使用RGB图像监督、不使用深度监督,会损害检测性能;仅使用深度监督、不使用图像监督,对性能有大幅提升。进一步加上SDF损失和RGB损失能达到最好的性能。
位置感知的模块:将基于查询的位置感知模块替换为位置特征与图像特征的拼接;实验表明性能会有下降。
5.5 可视化
可视化表明,与之前的基于深度的变换得到的3D表达相比,本文的方法能生成密集而连续的几何信息(特别是在远处)。
补充材料
A. 解释与讨论
A.1 基于深度的变换v.s.类NeRF
使用CaDDN中基于深度的变换方法替换MonoNeRD中的类NeRF表达作为基准方案。实验表明MonoNeRD能超过基准方案的性能,证明了类NeRF表达的优越性。
A.2 关于泛化性
跨不同场景的泛化性:NeRF将场景编码到MLP中,需要对每个场景单独优化。本文的MonoNeRD方法通过卷积引入如平移等价性的归纳偏好,从而使网络学到训练数据共有的底层特征和表达。
训练和推断的泛化差异:使用更多的训练数据训练时,MonoNeRD比其余基于深度变换的方法性能提升更显著。
跨数据集的泛化性:本文的方法严重依赖相机内参,因此不能实现不同数据集的泛化性。
A.3 局限性
由于单目图像的视锥是无限范围的,因此从界外区域(如天空)整合图像特征会损害最终的检测性能。此外,SDF不能表示非水密流形和有界流形(如零厚度的表面)。MonoNeRD无法重建360度的场景,因其只有单目输入。最后,本文的方法不能处理有光泽的表面。
B. 额外定量结果
B.1 KITTI测试结果
在行人类别上本文方法能达到SotA性能,在自行车类别上能达到有竞争力的性能(性能差异的原因是该类的训练样本较少)。
B.2 2D和3D监督的消融
使用两种深度监督方式:(1)提供显式深度监督的激光雷达深度标签;(2)使模型通过图像的重建损失隐式地学习深度的立体RGB图像监督。实验表明两种监督均能为训练提供3D信息,但同时使用两者并不能进一步提升模型性能。这可能是两种监督通过体素渲染提供了不同类型的深度监督(显式和隐式),会给模型带来较大的学习负担。引入SDF损失后,性能能进一步提升,因其为模型提供了3D约束,这一约束甚至能促进模型从不同的深度监督类型进行学习。
B.3 深度平面采样的消融
实验表明增大深度平面数 D D D,性能先增加后保持稳定。这可能是因为沿深度轴的过度采样会导致相邻的视锥平面特征相似。
C. 额外定量结果
C.1 如果没有目标检测会怎样?
本文发现,被遮挡区域的信息主要来自目标检测损失。可视化表明去掉目标检测损失会使被遮挡区域的重建不可控。但引入新视图监督后,该现象会被减轻。
C.3 渲染结果
可视化表明同时使用激光雷达深度监督和立体RGB监督的深度图渲染结果比只使用激光雷达深度监督的更好,特别是对于不可获取激光雷达深度标签的区域(如天空)。
















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











