







原文链接:https://arxiv.org/abs/2402.13243
1. 引言
最近,端到端自动驾驶成为重要而受欢迎的领域,但非确定性的规划导致难以从驾驶演示中提取知识。从统计角度看,在同一场景下可做出的行为(包括时机和速度)是随机的,而其潜在的很多影响因素是不能建模的。
现有的基于学习的规划方法以确定性的方式直接回归行为。回归目标 a ^ \hat a a^为未来轨迹或控制信号(加速度和转向)。但人类驾驶的差异会导致回归目标的模糊性(尤其对于非凸解空间而言,两个解之间的值可能不是解),且这类方法倾向于输出数据集中出现最多的轨迹(直行或停止),从而导致不高的性能。
本文使用概率规划处理规划的不确定性,提出VADv2,第一个在连续的规划解空间上使用概率建模的方法。规划策略被建模为以环境为条件的非静止随机过程 p ( a ∣ o ) p(a|o) p(a∣o),其中 o o o为历史和当前对驾驶环境的观测, a a a为候选规划行为。
规划行为空间是高维连续时空空间。本文使用概率场函数建模行为空间到概率分布的映射。本文将规划行为空间离散化为大量规划“词汇”,并使用大量的驾驶演示学习规划行为的概率分布。对于离散化,本文收集驾驶演示中所有的轨迹,并使用最远轨迹采样选择 N N N条有代表性的轨迹作为规划词汇。
该概率建模的方法灵感来自于大型语言模型对文本不确定性的处理。即使用以上下文为条件的、下一单词在大型语料库中的概率分布,并从该分布中采样一个单词作为预测的下一单词。
概率规划还有两个优点:(1)可建模行为和环境的关系,可为所有驾驶词汇而非仅正样本提供监督,有更丰富的监督信息;(2)在推断阶段更加灵活,因其输出多模态规划轨迹,容易与基于规则的或基于优化的方法结合,且可灵活添加规划词汇并评估。
VADv2以环视图像流为输入,将传感器数据转化为token嵌入,输出行为的概率分布并采样以控制车辆。VADv2能稳定地端到端运行。
3. 方法
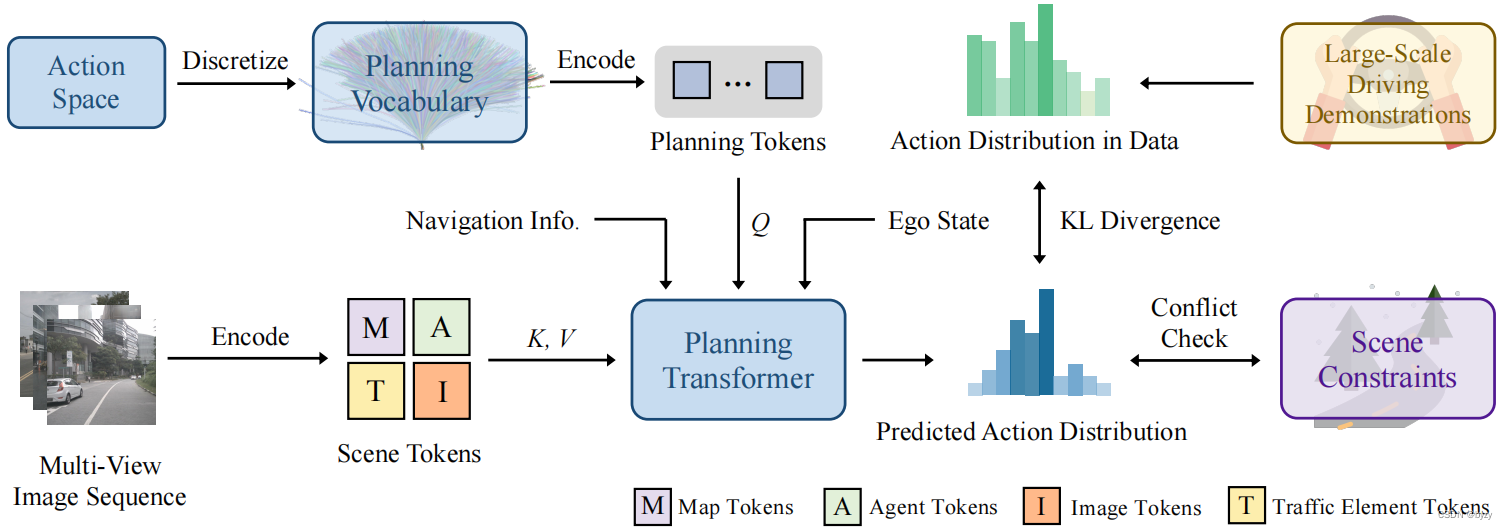
如图所示,VADv2以多视图图像序列为流式输入,编码为环境token嵌入,并输出行为的概率分布,最后采样行为控制车辆。大规模驾驶演示和场景约束被用于监督预测的分布。
3.1 场景编码器
图像中的信息是稀疏而低级的。本文使用编码器将数据转化为实例级的token嵌入 E e n v E_{env} Eenv,以显式地提取高级信息。 E e n v E_{env} Eenv包含地图token、智能体token、交通元素token和图像token。地图token被用于预测地图的矢量表达(包括中线、分隔带、道路边界和行人交叉路);智能体token用于预测其余交通参与者的运动信息(包括位置、朝向、大小、速度和多模态未来轨迹);交通元素token用于预测交通元素(交通灯和停止信号)的状态。这三类token均由相应的真值监督,以确保其显式编码相应的高级信息。图像token包含丰富的信息,与实例级的token互补。此外,导航信息和自车状态也被MLP编码为嵌入 { E n a v i , E s t a t e } \{E_{navi},E_{state}\} {Enavi,Estate}。
3.2 概率规划
规划空间为高维连续时空空间 A = { a ∣ a ∈ R 2 T } \mathbb A=\{a|a\in\mathbb R^{2T}\} A={a∣a∈R2T}。本文将其离散化为大型规划词汇表 V = { a i } N \mathbb V=\{a^i\}^N V={ai}N。具体来说,收集驾驶演示中所有规划行为并使用最远轨迹采样选择 N N N个行为,作为规划词汇。注意规划词汇来自驾驶演示,因此其遵循运动学(即相应的控制信号不会超过范围)。
每个规划词汇是路径点的序列
a
=
(
x
1
,
y
1
,
x
2
,
y
2
,
⋯
,
x
T
,
y
T
)
a=(x_1,y_1,x_2,y_2,\cdots,x_T,y_T)
a=(x1,y1,x2,y2,⋯,xT,yT)。每个路径点对应一个未来时刻。概率
p
(
a
)
p(a)
p(a)为
a
a
a的连续函数,且对
a
a
a的微小变化不敏感,即
lim
Δ
a
→
0
[
p
(
a
)
−
p
(
a
+
Δ
a
)
]
=
0
\lim_{\Delta a\rightarrow 0}[p(a)-p(a+\Delta a)]=0
limΔa→0[p(a)−p(a+Δa)]=0。本文使用概率场建模行为空间
A
\mathbb A
A到概率分布
{
p
(
a
)
∣
a
∈
A
}
\{p(a)|a\in\mathbb A\}
{p(a)∣a∈A}的连续映射,将每个行为(轨迹)编码为高维规划token嵌入
E
(
a
)
E(a)
E(a),并使用级联Transformer解码器与环境信息
E
e
n
v
E_{env}
Eenv交互,与导航信息
E
n
a
v
i
E_{navi}
Enavi和自车状态
E
s
t
a
t
e
E_{state}
Estate结合输出概率:
p
(
a
)
=
MLP
(
Transformer
(
E
(
a
)
,
E
e
n
v
)
+
E
n
a
v
i
+
E
s
t
a
t
e
)
,
q
=
E
(
a
)
,
k
=
v
=
E
e
n
v
,
a
=
(
x
1
,
y
1
,
x
2
,
y
2
,
⋯
,
x
T
,
y
T
)
,
E
(
a
)
=
Cat
[
Γ
(
x
1
)
,
Γ
(
y
1
)
,
⋯
,
Γ
(
x
T
)
,
Γ
(
y
T
)
]
,
Γ
(
p
o
s
)
=
Cat
[
γ
(
p
o
s
,
0
)
,
γ
(
p
o
s
,
1
)
,
⋯
,
γ
(
p
o
s
,
L
−
1
)
]
,
γ
(
p
o
s
,
j
)
=
Cat
[
cos
(
p
o
s
/
1000
0
2
π
j
/
L
)
,
sin
(
p
o
s
/
1000
0
2
π
j
/
L
)
]
p(a)=\text{MLP}(\text{Transformer}(E(a),E_{env})+E_{navi}+E_{state}),\\ q=E(a),k=v=E_{env},\\ a=(x_1,y_1,x_2,y_2,\cdots,x_T,y_T),\\ E(a)=\text{Cat}[\Gamma(x_1),\Gamma(y_1),\cdots,\Gamma(x_T),\Gamma(y_T)],\\ \Gamma(pos)=\text{Cat}[\gamma(pos,0),\gamma(pos,1),\cdots,\gamma(pos,L-1)],\\ \gamma(pos,j)=\text{Cat}[\cos(pos/10000^{2\pi j/L}),\sin(pos/10000^{2\pi j/L})]
p(a)=MLP(Transformer(E(a),Eenv)+Enavi+Estate),q=E(a),k=v=Eenv,a=(x1,y1,x2,y2,⋯,xT,yT),E(a)=Cat[Γ(x1),Γ(y1),⋯,Γ(xT),Γ(yT)],Γ(pos)=Cat[γ(pos,0),γ(pos,1),⋯,γ(pos,L−1)],γ(pos,j)=Cat[cos(pos/100002πj/L),sin(pos/100002πj/L)]
其中 Γ \Gamma Γ为编码函数,将坐标从 R \mathbb R R映射到高维嵌入空间 R 2 L \mathbb R^{2L} R2L。这样的高维映射可以更好地近似高频场函数。
3.3 训练
VADv2包含三类监督:分布损失、冲突损失和场景token损失。
分布损失:使用KL散度最小化预测分布于数据分布的差异:
L
dist
=
D
K
L
(
p
d
a
t
a
∣
∣
p
p
r
e
d
)
L_\text{dist}=D_{KL}(p_{data}||p_{pred})
Ldist=DKL(pdata∣∣ppred)
训练时,真实轨迹被加入规划词汇表并作为正样本,其余轨迹被视为负样本,并根据轨迹与真实轨迹的距离分配权重(越接近真实样本,惩罚越小)。
冲突损失:使用驾驶场景约束帮助模型学习驾驶的先验知识,并正则化预测分布。若规划词汇表中的一个行为与其余智能体的未来运动或道路边界冲突,该行为被视为负样本,分配很大的损失权重以减小该行为的概率。
场景token损失:即地图token、智能体token或地图元素token对应的损失。
地图token损失使用预测地图点和真实地图点之间的 l 1 l_1 l1回归损失,以及地图分类的focal损失。
智能体token损失包含检测损失和运动预测损失。智能体属性(位置、朝向、大小等)使用 l 1 l_1 l1回归损失,类别使用focal损失。与真实智能体匹配的智能体会被预测 K K K个未来轨迹,并使用最小最终位移误差(minFDE)的轨迹为代表性预测。使用该预测与真实轨迹的 l 1 l_1 l1损失,作为运动回归损失。多模态运动分类损失使用focal损失。
地图元素token分为交通灯token和停止信号token。交通灯token会输入MLP预测交通灯状态(红黄绿)以及交通灯是否影响自车。停止信号token也被送入MLP预测停止信号区域与自车的重叠。focal损失用于监督这些预测。
3.4 推断
本文采样最高概率的行为并使用PID控制器转换为控制信号(油门、刹车、转向)。
实际应用中,可采样最优的 K K K个行为,并使用基于规则的方法过滤、基于优化的方法细化。
4. 实验
4.2 指标
闭环评估使用CARLA的官方指标,路线完整度、违规分数和驾驶分数。本文在基于学习的策略基础上,使用基于规则的包装方法。
开环评估使用L2距离和碰撞率,其计算更快且更加稳定。
4.3 与SotA方法比较
实验表明,VADv2在仅使用图像输入的情况下也能比多模态方法有更高的性能。
4.4 消融研究
实验表明,没有分布损失的情况下,模型性能很差;没有冲突损失时,模型缺少驾驶的先验信息,性能也会受到影响。由于规划token会与场景token交互学习场景信息,任意场景token缺少时,性能也会下降。


















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











