









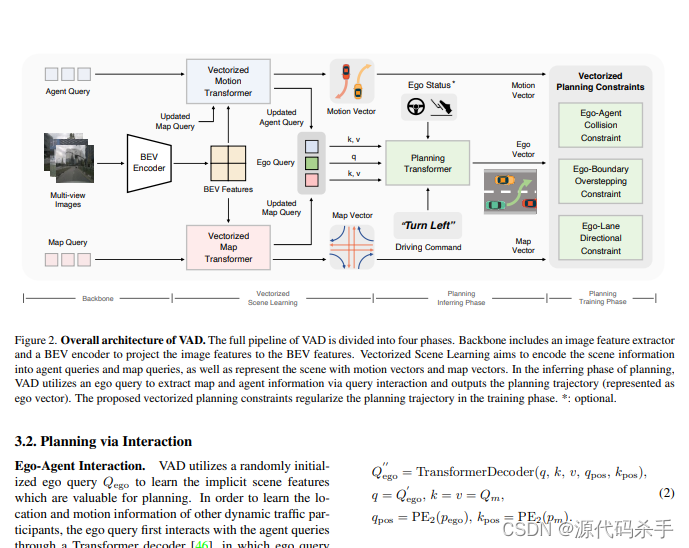
这篇论文提出了一种名为VAD的自动驾驶场景表示向量化方法,旨在提高自动驾驶系统的规划性能和推理速度。以往的方法依赖于密集的栅格化场景表示(例如,代理占用和语义地图)来进行规划,这种方法计算密集且缺少实例级别的结构信息。本文提出了VAD,一种全面向量化的自动驾驶范式,将驾驶场景建模为完全向量化的表示。所提出的向量化范式具有两个显著优点。一方面,VAD利用向量化的代理运动和地图元素作为显式的实例级别规划约束,有效提高了规划安全性。另一方面,VAD比以往的端到端规划方法运行速度更快,通过摆脱计算密集的栅格化表示和手动设计的后处理步骤。VAD在nuScenes数据集上实现了最先进的端到端规划性能,远远超过了以前的最佳方法。VAD-Base模型大大降低了平均碰撞率29.0%,运行速度提高了2.5倍。此外,轻量级变体VAD-Tiny大大提高了推理速度(高达9.3倍),同时实现了可比较的规划性能。VAD的出色性能和高效性对于自动驾驶系统的实际部署至关重要。该论文的代码和模型已经在GitHub上开源,可以供研究人员和开发者使用。
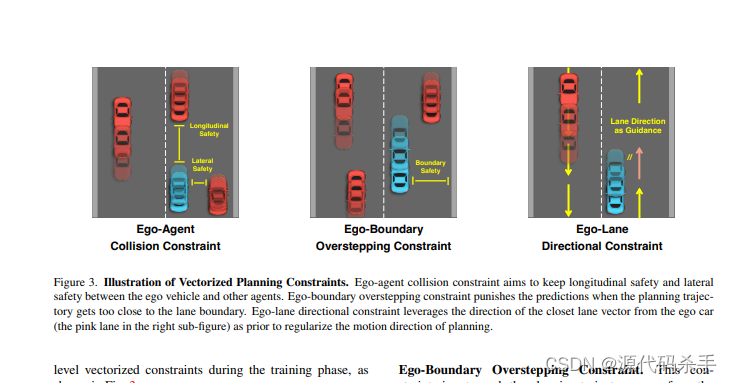
这个项目是一个名为VAD的自动驾驶场景表示向量化方法,旨在提高自动驾驶系统的规划性能和推理速度。该项目基于mmdet3d、detr3d、BEVFormer和MapTR等项目,使用了向量化场景表示和简洁的模型设计,实现了SOTA的端到端规划性能,并大幅度提高了推理速度。
该项目的技术原理和算法实现可以在其GitHub存储库中找到
该存储库包含了VAD的代码和模型,以及使用说明和结果。VAD的模型使用了ResNet50作为骨干网络,通过将点云数据转换为BEV图像,使用Transformer进行特征提取和规划。VAD的代码使用了PyTorch框架,可以在Linux系统上运行。
该项目的实现基于向量化场景表示和Transformer网络,通过将点云数据转换为BEV图像,使用Transformer进行特征提取和规划。VAD的模型使用了ResNet50作为骨干网络,通过将点云数据转换为BEV图像,使用Transformer进行特征提取和规划。VAD的代码使用了PyTorch框架,可以在Linux系统上运行。
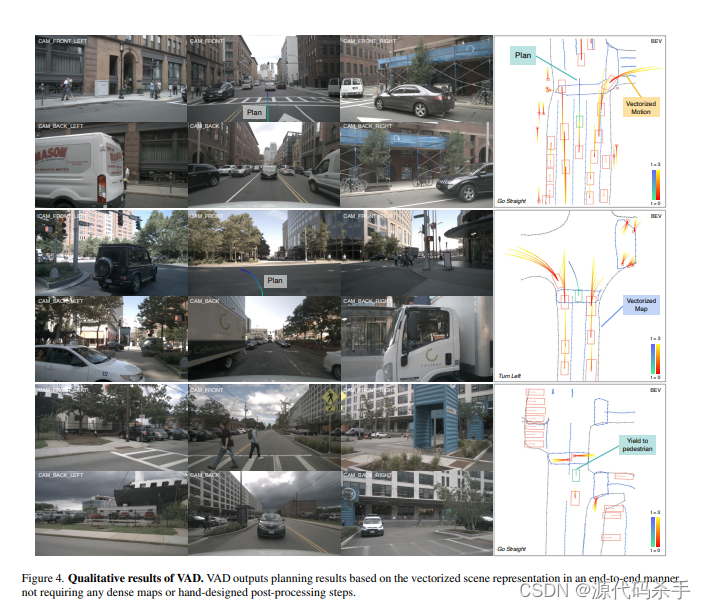
该项目的结果表明,VAD的性能优于以往的方法,并且推理速度得到了显著提高。该项目的代码和模型已经在GitHub上开源,可以供研究人员和开发者使用。如果有任何问题或建议,可以通过存储库中提供的联系方式与项目团队联系。




















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











