







参考:https://blog.csdn.net/silangquan/article/details/17184807
photorealistic rendering attempts to make an image indistinguishable from a photograph. non-photorealistic rendering (NPR), also called stylistic rendering, has a wide range of goals. one objective of some forms of NPR is to create images similar to technical illustrations. only those details relevant to the goal of the particular application are the ones that should be displayed. for example, a photograph of a shiny ferrari engine may be

useful in selling the car to a customer, but to repair the engine, a simplified line drawing with the relevant parts highlighted may be more meaningful (as well as cheaper to print).
11.1 toon shading
just as varying the font gives a different feel to the next, different styles of rendering have their own mood, meaning, and vocabulary. there has been a large amount of attention given to one particular form of NPR, cel or toon rendering. since this style is identified with cartoons, it has strong conotation0 内涵 of fantasy and (in the west, at least) childhood. at is simplest, objects are drawn with solid lines separating areas of different solid colors. one reason this style is popular is what McCloud, in his classic book understanding comics, calls “amplification through simplification”. by simplifying and stripping out clutter 通过简化和去除杂乱, one can amplify the effect of information relevant to the presentation. for cartoon characters, a wider audience will identify with those drawn in a simple style.
the toon rendering style has been used in computer graphics for well over a decade to integrate three-dimensional models with two-dimensional cel (真就是一个cel,不是cell) animation. it lends itself well to automatic generation by computer because it is easily defined, compared to other NPR styles. games such as okami and cel damage have used it to good effect. see figure 11.2.

figure 11.2. an example of real-time NPR rendering from the game okami.
https://baike.baidu.com/item/%E5%A4%A7%E7%A5%9E/3420158?fromtitle=okami&fromid=23280347&fr=aladdin
there are a number of different approaches to toon rendering. for models with textures and no lighting, a solid-fill 纯色填充,单一色彩 cartoon style can be approximated by quantiznig the textures. for shading, the two most common methods are to fill the polygonal areas with solid (unlit) color 纯色 or to use a two-tone approach, representing lit and shadowed areas. solid shading is trivial, and the two-tone approach, sometimes called hard shading, can be performed by remapping traditional lighting equation elements to different color palettes托盘. this approach is related to the lighting model work by gooch et al. for NPR technical illustration. also silhoettes are often rendered in a black color, which amplifies the cartoon look. silhouette finding and rendering is dealt with in the next section.

figure 11.3. on the left, a Gouraud-shaded duck. the rest of the ducks have silhouettes rendered, with solid shading, diffuse two-tone shading, and specular/diffuse three-tone shading. (reprinted by permission of adam lake and carl marshal, intel corporation, copyright intel corporation 2002).
11.2 Silhouette edge rendering
11.2.1 surface angle silhouetting
in a similar fashion to the surface shader in section 11.1, the dot product between the direction to the viewpoint and the surface normal can be used to give a silhouette edge. if this value is near zero, then the surface is nearly edge-on to the eye and so is likely to be near a silhouette edge. the technique is equivalent to shading the surface using a spherical environment map (EM) with a black ring around the edge. see figure 11.5. in practice, a one-dimensional texture can be used in place of the environment map. Marshall performs this silhouetteing method by using a vertex shader. instead of computing the reflection to access the EM, he uses the dot product of the view ray and vertex normal to access the one-dimensional texture. Everitt uses the mipmap pyramid to perform the process, coloring the topmost layers with black. as a surface becomes edge-on, it access these top layers and so is shaded black. since no vertex interpolation is done, the edge is sharper. these methods are extremely fast, since the accelerator does all the work in a single pass, and the texture filtering can help antialias the edges.

figure 11.5. silhouettes rendered by using a spheremap. by widening the circle along the edge of the spheremap, a thicker silhouette edge is displayed. (image courtesy of kenny hoff.)
this type of technique can work for some models, in which the assumption that there is a relationship between the surface normal and the silhouette edge holds true. for a model such as a cube, this method fails, as the sohouette edge will usually not be caught. however, by explicitly drawing the crease edges, such sharp features will be rendered properly, though with a different style than the silhouette edges. a feature or drawback of this method is that silhouette lines are drawn with variable width, depending on the curvature of the surface. large, flat polygons will turn entirely black when nearly edge-on, which is usually not the effect desired. in experiments, Wu found that for the game Cel Damage this technique gave excellent results for one quarter of the models, but failed on the rest.
11.2.2 procedural geometry silhouetteing
one of the first techniques for real-time silhouette rendering was presented by Rossignac and van Emmerick, and later refined by Raskar and Cohen. the basic idea is to render the frontfaces normally, then render the backfaces in a way as to make their silhouette edges visible. there are a number of methods of rendering these backfaces, each with its own strengths and weakness. each method has as its first step that the frontfaces are drawn. then fronface culling is turned on and backface culling turned off. so that only backfaces are displayed.
one method to render the silhouette edges is to draw only the edges (not the faces) of the backfaces. using biasing or other techniques (see section 11.4) ensures that these lines are drawn just in front of the frontfaces. in this way, all lines except the silhouette edges are hidden.

figure 11.6. the z-bias method of sihouetting, done by translating the backface forward. if the frontface is at a different angle, as shown on the right, a different amount of the backface is visible.
one way to make wider lines is to render the backfaces themselves in black. without any bias, these backfaces would remain invisible. so, what is done is to move the backfaces forward in screen Z by biasing them. in this way, only the edges of the backfacing triangles are visible. Raskar and Cohen give a number of biasing methods, such as translating by a fixed amount, or by an amount that compensates for the nonlinear nature of the z-depths, or using a depth-slope bias call such as glPolygonOffset. Lengyel discusses how to provide finear depth control by modifying the perspective matrix. a problem with all these methods is that they do not create lines with a uniform width. 这些线不是统一的宽度 to do so, the amount to move forward depends not only on the backface, 向前移动多少,不仅仅依赖于后表面,还依赖于相邻的前表面 but also on the neighbouring frontface(s). see figure 11.6. the slope of the backface 背面的斜度可以用来作为前面多边形的偏移 can be used to bias the polygon forward, but the thickness of the line will also depend on the angle of the frontface. 但是这个厚度依赖于前表面的角度。
参考网址:https://blog.csdn.net/candycat1992/article/details/45577749
Raskar and Cohen [1046] solve this neighbor dependency problem by instead fattening each backface triangle out along its edges by the amount needed to see a consistently thick line. that is, the slope of the triangle and the distance from the viewer determine how much the triangle is expanded.

figure 11.7. triangle fattening. on the left, a backface triangle is expanded along its plane. each edge moves a different amount in world space to make the resulting edge the same thickness in screen space. for thin triangles, this technique falls apart, as one corner becomes elongated.细长的 on the right, the triangle edges are expanded and joined to form mitered corners 斜角 to avoid this problem.


figure 11.8. Silhouettes rendered with backfacing edge drawing with thick lines, z-bias, and fattened triangle algorithms. the backface edge technique gives poor joins between lines and nonuniform lines due to biasing problems on small features. the z-bias technique gives nonuniform edge width because of the dependence on the angles of the frontfaces. z-bias给出了不同的线的宽度,因为取决于前表面的角度(Images courtesy of Raskar and Cohen [1046].)
one method is to expand the three vertices of each triangle outwards along its plane. a safer method of rendering the triangle is to move each edge of the triangle outwards and connect the edges. doing so avoids having the vertices stick far away from the original triangle. see figure 11.7. note that no biasing is needed with this method, as the backfaces expand beyond the edges of the frontfaces. see figure 11.8 for results from the three methods. an improved way of computing the edge expansion factors is presented in a later paper by Raskar[1047].
in the method just given, the backface triangles are expanded along their original planes. another method is to move the backfaces outwards by shifting their vertices along the shared vertex normals, by an amount

Figure 11.9. The triangle shell technique creates a second surface by shifting the surface along its vertex normals.
沿着法线外扩,只画前表面。
proportional to their z-distance from the eye [506]. this is referred to as the shell or halo method, as the shifted backfaces form a shell around the original object. imagine a sphere. render the the sphere normally, then expand the sphere by a radius that is 5 pixels wide with respect to the sphere’s center. that is, if moving the sphere’s center one pixel is equivalent to moving it in world space by 3 millimeters, then increase the radius of the sphere by 15 millimeteres. render only this exapnded version’s backfaces in black(1). the silhouette edge will be 5 pixels wide. see figure 11.9. this method has some advantages when performed on the gpu. moving vertices outwards along their normals is a perfect task for a vertex shader, so the accelerator can create silhouettes without any help from the cpu. this type of expansion is sometimes called shell mapping. vertex information is shared and so entire meshes an be rendered, instead of individual polygons. the method is simple to implement, efficient, robuts, and gives steady performance. it is the technique used by the game Cel Damage [1382] for example. see figure 11.10.
this shell technique has a number of potential pitfalls. imagine looking head-on at a cube so that only one face is visible. each of the four backfaces forming the silhouette edge will move in the direction of its corresponding cube face, so leaving gaps at the corners. this occurs because while there is a single vertex at each corner, each face has a different vertex normal. the problem is that the expanded cube does not truly form a shell, because each corner vertex is expanding in a different direction. one solution is to force vertices in the same location to share a single, new, average vertex normal. another technique is to create degenerate geometry at the creases that then gets expaned into polygons with area [1382].
shell and fattening techniques waste some fill, since all the backfaces are rendered. fattening techniques can not currently be performed on curved surfaces generated by the accelerator. Shell techniques can work with
curved surfaces, as long as the surface representation can be displaced
outwards along the surface normals. The z-bias technique works with all
curved surfaces, since the only modification is a shift in z-depth. Other
limitations of all of these techniques is that there is little control over
the edge appearance, semitransparent surfaces are difficult to render with
silhouettes, and without some form of antialiasing the edges look fairly
poor [1382].
One worthwhile feature of this entire class of geometric techniques is
that no connectivity information or edge lists are needed. Each polygon is
processed independently from the rest, so such techniques lend themselves
to hardware implementation [1047]. However, as with all the methods
discussed here, each mesh should be preprocessed so that the faces are
consistent (see Section 12.3).
This class of algorithms renders only the silhouette edges. Other edges
(boundary, crease, and material) have to be rendered in some other fashion.
These can be drawn using one of the line drawing techniques in Section 11.4.
For deformable objects, the crease lines can change over time. Raskar [1047]
gives a clever solution for drawing ridge lines without having to create and
access an edge connectivity data structure. The idea is to generate an
additional polygon along each edge of the triangle being rendered. These
edge polygons are bent away from the triangle’s plane by the user-defined
critical dihedral angle that determines when a crease should be visible.
Now if two adjoining triangles are at greater than this crease angle, the
edge polygons will be visible, else they will be hidden by the triangles. For
valley edges, this technique can be performed by using the stencil buffer
and up to three passes.
11.2.3 Silhouetting by Image Processing
The algorithms in the previous section are sometimes classified as imagebased,
as the screen resolution determines how they are performed. Another
type of algorithm is more directly image-based, in that it operates entirely on data stored in buffers and does not modify (or even know about)
the geometry in the scene.
Saito and Takahashi [1097] first introduced this G-buffer, concept, which
is also used for deferred shading (Section 7.9.2). Decaudin [238] extended
the use of G-buffers to perform toon rendering. The basic idea is simple:
NPR can be done by performing image processing techniques on various
buffers of information. By looking for discontinuities in neighboring Zbuffer
values, most silhouette edge locations can be found. Discontinuities
in neighboring surface normal values signal the location of boundary
(and often silhouette) edges. Rendering the scene in ambient colors
can also be used to detect edges that the other two techniques may
miss.
Card and Mitchell [155] perform these image processing operations in
real time by first using vertex shaders to render the world space normals
and z-depths of a scene to a texture. The normals are written as a normal
map to the color channels and the most significant byte of z-depths as the
alpha channel.
Once this image is created, the next step is to find the silhouette, boundary,
and crease edges. The idea is to render a screen-filling quadrilateral
with the normal map and the z-depth map (in the alpha channel) and detect
edge discontinuities [876]. The idea is to sample the same texture six
times in a single pass and implement a Sobel edge detection filter [422].
The texture is sampled six times by sending six pairs of texture coordinates
down with the quadrilateral. This filter is actually applied twice to
the texture, once along each axis, and the two resulting images are composited.
One other feature is that the thickness of the edges generated can
be expanded or eroded by using further image processing techniques [155].
See Figure 11.11 for some results.
This algorithm has a number of advantages. The method handles all
primitives, even curved surfaces, unlike most other techniques. Meshes do
not have to be connected or even consistent, since the method is imagebased.
From a performance standpoint, the CPU is not involved in creating
and traversing edge lists.
There are relatively few flaws with the technique. For nearly edge-on
surfaces, the z-depth comparison filter can falsely detect a silhouette edge
pixel across the surface. Another problem with z-depth comparison is that
if the differences are minimal, then the silhouette edge can be missed. For
example, a sheet of paper on a desk will usually have its edges missed.
Similarly, the normal map filter will miss the edges of this piece of paper,
since the normals are identical. One way to detect this case is to add a
filter on an ambient or object ID color rendering of the scene [238]. This is
still not foolproof; for example, a piece of paper folded onto itself will still
create undetectable edges where the edges overlap [546].


Figure 11.11. The normal map (upper left) and depth map (middle left) have edge
detection applied to their values. The upper right shows edges found by processing the
normal map, the middle right from the z-depth map. The image on the lower left is
a thickened composite. The final rendering in the lower right is made by shading the
image with Gooch shading and compositing in the edges. (Images courtesy of Drew
Card and Jason L. Mitchell, ATI Technologies Inc.)
With the z-depth information being only the most significant byte,
thicker features than a sheet of paper can also be missed, especially in
large scenes where the z-depth range is spread. Higher precision depth
information can be used to avoid this problem.
11.2.4 Silhouette Edge Detection
Most of the techniques described so far have the disadvantage of needing
two passes to render the silhouette. For procedural geometry methods, the
second, backfacing pass typically tests many more pixels than it actually
shades. Also, various problems arise with thicker edges, and there is little
control of the style in which these are rendered. Image methods have
similar problems with creating thick lines. Another approach is to detect
the silhouette edges and render them directly. This form of silhouette edge
rendering allows more fine control of how the lines are rendered. Since
the edges are independent of the model, it is possible to create effects
such as having the silhouette jump in surprise while the mesh is frozen in
shock [1382].
A silhouette edge is one in which one of the two neighboring triangles
faces toward the viewer and the other faces away. The test is
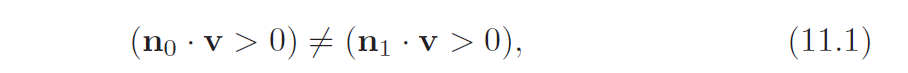
where n0 and n1 are the two triangle normals and v is the view direction
from the eye to the edge (i.e., to either endpoint). For this test to work
correctly, the surface must be consistently oriented (see Section 12.3).
The standard method for finding the silhouette edges in a model is
to loop through the list of edges and perform this test [822]. Lander [726]
notes that a worthwhile technique is to cull out edges that are inside planar
polygons. That is, given a connected triangle mesh, if the two neighboring
triangles for an edge lie in the same plane, do not add this edge to the list
of edges to test for being a silhouette edge. Implementing this test on a
simple clock model dropped the edge count from 444 edges to 256.
There are other ways to improve efficiency of silhouette edge searching.
Buchanan and Sousa [144] avoid the need for doing separate dot product
tests for each edge by reusing the dot product test for each individual
face. Markosian et al. [819] start with a set of silhouette loops and uses a
randomized search algorithm to update this set. For static scenes, Aila and
Miettinen [4] take a different approach, associating a valid distance with
each edge. This distance is how far the viewer can move and still have the
silhouette or interior edge maintain its state. By careful caching, silhouette
recomputation can be minimized.
In any model each silhouette always consists of a single closed curve,
called a silhouette loop. It follows that each silhouette vertex must have
an even number of silhouette edges [12]. Note that there can be more than
one silhouette curve on a surface. Similarly, a silhouette edge can belong
to only one curve. This does not necessarily mean that each vertex on the
silhouette curve has only two incoming silhouette edges. For example, a
curve shaped like a figure eight has a center vertex with four edges. Once
an edge has been found in each silhouette, this edge’s neighbors are tested
to see whether they are silhouette edges as well. This is done repeatedly
until the entire silhouette is traced out.
If the camera view and the objects move little from frame to frame, 如果两帧之间物体移动的少,那么有理由认为前一阵的轮廓线对于本帧还是有效的。it is reasonable to assume that the silhouette edges from previous frames might still be valid silhouette edges. Therefore, a fraction of these can be tested to find starting silhouette edges for the next frame. Silhouette loops are also created and destroyed as the model changes orientation. Hall [493] discusses detection of these, along with copious 丰富的 implementation details.
Compared to the brute-force algorithm, Hall reported as much as a seven times performance increase. The main disadvantage is that new silhouette loops can be missed for a frame or more if the search does not find them.
The algorithm can be biased toward better speed or quality.
Once the silhouettes are found, the lines are drawn. An advantage of
explicitly finding the edges is that they can be rendered with line drawing,
textured impostors (see Section 10.7.1), or any other method desired. Biasing
of some sort is needed to ensure that the lines are properly drawn in
front of the surfaces. If thick edges are drawn, these can also be properly
capped and joined without gaps. This can be done by drawing a screenaligned
circle at each silhouette vertex [424].
One flaw of silhouette edge drawing is that it accentuates the polygonal
nature of the models. That is, it becomes more noticeable that the model’s
silhouette is made of straight lines. Lake et al. [713] give a technique
for drawing curved silhouette edges. The idea is to use different textured
strokes depending on the nature of the silhouette edge. This technique
works only when the objects themselves are given a color identical to the
background; otherwise the strokes may form a mismatch with the filled
areas. A related flaw of silhouette edge detection is that it does not work
for vertex blended, N-patch, or other accelerator-generated surfaces, since
the polygons are not available on the CPU.
Another disadvantage of explicit edge detection is that it is CPU intensive.
A major problem is the potentially nonsequential memory access.
It is difficult, if not impossible, to order faces, edges, and vertices simultaneously
in a manner that is cache friendly [1382]. To avoid CPU processing
each frame, Card and Mitchell [155] use the vertex shader to detect
and render silhouette edges. The idea is to send every edge of the model
down the pipeline as a degenerate quadrilateral, with the two adjoining
triangle normals attached to each vertex. When an edge is found to be
part of the silhouette, the quadrilateral’s points are moved so that it is no
longer degenerate (i.e., is made visible). This results in a thin quadrilateral
“fin,” representing the edge, being drawn. This technique is based on the
same idea as the vertex shader for shadow volume creation, described on
page 347. Boundary edges, which have only one neighboring triangle, can
also be handled by passing in a second normal that is the negation of this
triangle’s normal. In this way, the boundary edge will always be flagged
as one to be rendered. The main drawbacks to this technique are a large
increase in the number of polygons sent to through the pipeline, and that
it does not perform well if the mesh undergoes nonlinear transforms [1382].
McGuire and Hughes [844] present work to provide higher-quality fin lines
with endcaps.
If the geometry shader is a part of the pipeline, these additional fin polygons do not need to be generated on the CPU and stored in a mesh.
The geometry shader itself can generate the fin quadrilaterals 四边形 as needed. Other silhouette finding methods exist. For example, Gooch et al. [423] use Gauss maps for determining silhouette edges. In the last part of Section
14.2.1, hierarchical methods for quickly categorizing sets of polygons as front or back facing are discussed. See Hertzman’s article [546] or either NPR book [425, 1226] for more on this subject.
11.2.5 Hybrid Silhouetting 混合轮廓技术
Northrup and Markosian [940] use a silhouette rendering approach that has both image and geometric elements. Their method first finds a list of silhouette edges. 首先检测找到轮廓线 They then render all the object’s triangles and silhouette edges, assigning each a different ID number (i.e., giving each a unique color). This ID buffer is read back and the visible silhouette edges are determined from it. These visible segments are then checked for overlaps and linked together to form smooth stroke paths.检查是否重叠,然后辅以笔画方式描绘,形成了笔画风格 Stylized strokes are then rendered along these reconstructed paths. The strokes themselves can be stylized in many different ways, including effects of taper, flare, wiggle, and fading, as well as depth and distance cues. An example is shown in
Figure 11.12. Kalnins et al. [621] use this method in their work, which attacks an important area of research in NPR: temporal coherence. Obtaining a silhouette is, in one respect, just the beginning. As the object and viewer move, the silhouette edge changes. With stroke extraction techniques some coherence is available by tracking the separate silhouette loops. However, when two loops merge, corrective measures need to be taken or a noticeable jump from one frame to the next will be visible. A pixel search and “vote”
algorithm is used to attempt to maintain silhouette coherence from frame to frame.

Figure 11.12. An image produced using Northrup and Markosian’s hybrid 混合技术 technique, whereby silhouette edges are found, built into chains, and rendered as strokes. (Image courtesy of Lee Markosian.) 轮廓被发现,连成链条,以铅笔画的形式渲染。















 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









