



Control
自动驾驶的控制目标
理想的控制器和司机的驾驶经验密切相关。如下表所示。
| 老司机开车 | 理想的控制器 |
|---|---|
| 不压线 | 精确性(Steady State Error) |
| 驾驶稳 | 稳定性(Stability) |
| 反应快 | 快速性(Rise time,Peak time) |
| 不容易受干扰 | 鲁棒性(Robust) |
无人驾驶汽车做到不压线,对应控制器的精确性;坐在车上的人没有感受到颠簸,对应控制器的稳定性;对于路上的行人、车辆能够无人驾驶汽车能够及时反应执行避障,对应控制器的快速性;无人驾驶汽车不受从传输信号的干扰,对应控制器的鲁棒性。
自动驾驶控制器的设计
自动驾驶控制器的设计[7]主要依赖于四个方面,分别是受控对象、环境、目标任务、以及控制调优。
受控对象可以是乘用车、货运卡车、物流小车等,需要根据受控对象的特点设计控制器,比如货运卡车转弯惯性比较大,如果是基于物流小车、乘用车特点设计控制器,无人驾驶转弯的安全性将大大降低。控制器的设计也依赖不同的环境,城市公路上有很多行人、车辆,路大都平坦,需要对控制器做出很多规则上的约束,提高控制的可靠性。
基于城市公路环境设置的控制器并不适用山地野外,山地野外,会经常碰到土堆、凹坑这样凹凸不平的情况,对规则的约束没有城市道路那样严格,控制器的设计也会不同。
控制器的设计还依赖不同的目标任务,不同的目标任务需要设置不同的控制器,常见的目标任务有定速巡航、目标跟随、执行特殊任务等。对于控制器设计的控制调优,需要综合分析,比如PID控制器,它的调优需要依赖经验,一般是先调节比例系数Kp,再调节微分系数Kd。
业界常用的控制算法
自动驾驶常用的控制算法[8]有PID控制、LQR控制、MPC控制。
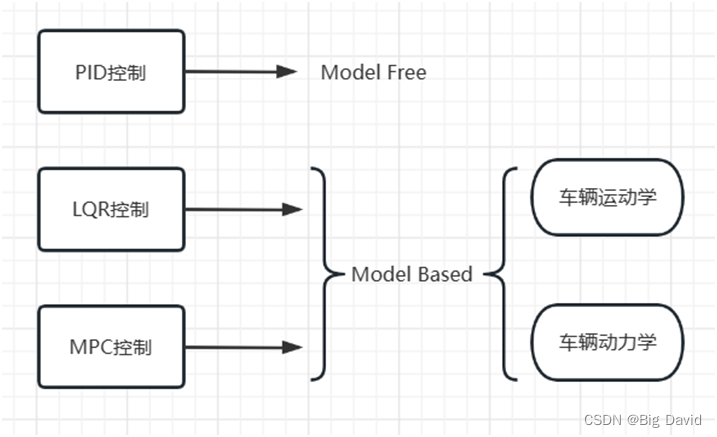
通过该图可以了解到PID控制不需要基于模型,LQR和MPC控制需要基于车辆运动学和车辆动力学。控制油门和刹车可以控制车的纵向速度和位移,而横向控制不仅依赖于车辆转向还依赖于横向速度,纵向控制与横向控制无法完全解耦。
控制器有两个输入:
1)目标轨迹:来自规划模块,每一个路径点,规划模块指定一个位置和一个参考速度,在每个时间步都对轨迹进行更新。
2)车辆状态:车辆位置(position)、从车辆内部传感器获取的数据(如速度、转向、加速度)
计算目标轨迹与实际行进轨迹之间的偏差,控制器的输出就是控制输入(转向、加速、制动)的值。
PID控制算法
PID算法一般用于车辆的横、纵向控制,一般用在纵向控制比较多,下面是对PID算法的原理的阐述。如图所示直行是目标轨迹,偏离的是车的实际运动轨迹。设想一辆车试图遵循目标轨迹,P控制器在车辆开始偏离时立即将其拉回目标轨迹。比例控制意味着车辆偏离越远,控制器就越难将其拉回目标轨迹。

只有P控制器,现实中很容易超出参考轨迹,当车辆接近参考轨迹时,需要控制器更稳定。D控制器致力于使车辆运动处于稳定状态。PD控制器类似于P控制器增加一个阻尼项,可最大限度地减少控制器输出的变化速度。如图所示,直行的是目标轨迹,偏离的是车的实际运动轨迹。
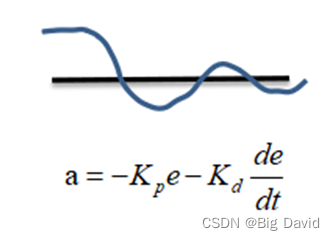
I控制器负责纠正车辆的任何系统性偏差。例如,转向可能失准,可能造成恒定的转向偏移,在这种情况下,需要向一侧转向以保持直行,为了解决整个问题,控制器对系统的累积误差进行惩罚,将P、I、D结合构成PID控制器。如图所示目标轨迹和车辆实际运动轨迹。

PID控制的优点是只需要知道车辆与目标轨迹之前的偏差就能进行调节。缺点一方面PID算法是一个线性算法,对于复杂的系统而言,这是不够的。对于无人驾驶汽车,需要应用不同的PID控制器来控制转向和加速,意味着很难将横向和纵向控制结合起来。另一方面,PID控制器依赖实时误差测量,意味着测量延迟限制可能会失效。
LQR控制算法
LQR,也称线性二次调节器,是基于车辆横向跟踪偏差模型的控制器,一般用在车辆的横向控制上。LQR一般处理线性控制,通过使用车辆的状态来使误差最小化。
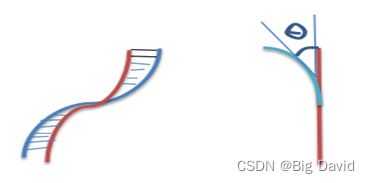
横向控制包含四个组件:横向误差、横向误差的变化率、朝向误差、朝向误差的变化率,横向误差和朝向误差如图所示。

因为使用会有成本,如耗费气体或电力,LQR算法希望尽可能少使用控制输入。为了尽量减少误差,可以保持误差的运行总和、控制输入的运行总和。当汽车往右偏转的特别厉害之际,添加到误差总和中,当控制输入将汽车往左侧转时,从控制输入总和中减去一点。这种方法会导致问题,因为右侧的正误差,只需将左侧的负误差消除即可,对控制输入也是如此。
在此总结LQR涉及的控制目标:
1)车辆跟踪参考轨迹,即车辆跟踪偏差越小越好。
2)控制量越小越好,以小的控制量代价获取好的控制效果。由此引入二次项代价函数。
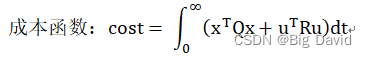
其中,Q、R代表x和u的权重集合。
LQR控制方法被描述为 u = -Kx,代表如何从x计算得出u。找到一个最优的u,就是找到一个最优的K。
MPC模型预测控制
MPC是一种更复杂的控制器,依赖于数学优化。模型预测控制有三步:
(1)建立车辆模型
(2)使用优化引擎计算有限时间范围内的控制输入
(3)执行第一组输入
MPC是一个重复过程,它着眼未来,计算一系列的控制输入,并优化该序列。控制器实际上只实现了序列中的第一组控制输入,然后控制器再次重复该循环。因为采用了近似测量与计算,如果实现了整个控制输入序列,实际产生的车辆状态将与模型有很大差异,所以最好在每个时间步不断重新评估控制输入的最优序列。
预测越深入,控制器就越准确,不过需要的时间也越长,需要在快速和准确度之间做出取舍。获取结果的速度越快,越能快速地将控制输入应用到实际车辆上,下一步是将模型发送到搜索最佳控制输入的优化引擎,优化引擎的工作原理是通过搜索密集数学空间来寻求最佳解决方案,为缩小范围,优化引擎依赖于车辆模型的约束条件,可间接评估控制输入。通过使用这些方法对车辆轨迹进行建模。根据成本函数对轨迹进行评估,成本函数主要基于与目标轨迹的偏差,其次基于加速度、提升乘坐舒适度的措施。
为了让乘客感觉舒适,对控制输入的调整应很小,动作变化幅度过大会让乘客感觉不舒服。根据情况考虑成本并设计成本函数。模型、约束、成本函数合并在一起并作为优化问题加以解决。在不同的优化引擎中选择一种来寻找最佳方案。
MPC算法考虑了车辆模型,所以比PID控制更精确,而且适用于不同的成本函数,可以在不同的情况下优化不同的成本。但是与PID控制相比,模型预测控制相对更复杂、更缓慢、更难以实现。
在工业界,以量产为目的的车辆控制主流还是PID和LQR算法。PID等传统算法有各种优化的方法,可以加各种trick,足够满足目前无人驾驶控制性能的需求。但是无人驾驶汽车控制可扩展性的重要程度通常意味着值得为MPC投入实现成本,所以MPC成为了一个非常重要的无人驾驶车控制器。
汽车纵向运动控制
无人驾驶的纵向控制就是控制汽车的纵向运动,控制输入是油门和刹车,控制的状态量有车速、加速度和跟车距离。汽车纵向控制中最常用的控制应用就是自适应巡航系统(ACC),最常用的纵向控制算法就是PID算法。
自适应巡航系统根据前车的相对距离、相对速度,对距离和速度进行一个控制。输入量有驾驶员设定的速度、车自身的速度、和前车之间的距离、和前车之间的相对速度、时间间隔。输出量即本车的加速度,并通过纵向标定表得出油门控制量和刹车控制量,实现汽车的纵向运动。自适应巡航系统有两种模式,第一种模式是保持速度驾驶,第二种模式是保持两车之间的安全距离。遵循的基本原则如下:
1)如果两车距离很近,控制的目标是保持安全的距离。
2)如果两车距离很远,控制的目标是保持理想的速度。
相信大家一定有疑问,为什么输入量用时间间隔而不用固定距离,因为固定的时间间隔可以使跟车距离和车速保持关系。在车辆跟车模式中,纵向控制器必须满足两个条件:(1)个体车辆稳定性(2)车队稳定性
百度Apollo纵向控制原理如下图所示,该图可以为纵向控制器的设置提供参考。
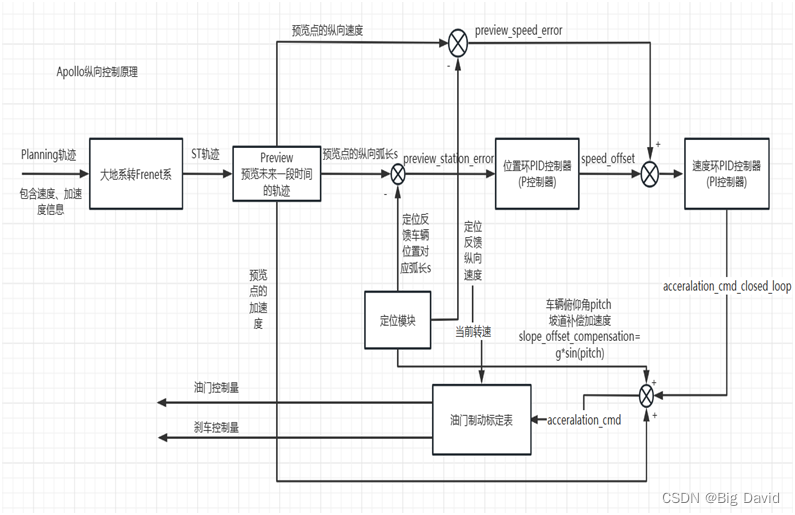
可以看出纵向控制是基于Frenet坐标系的,位置跟踪控制器采用P控制器实现车辆位置闭环控制,速度跟踪控制器实现速度闭环控制,根据车辆的俯仰角得出坡道加速度补偿,以及预览点的加速度实现加速度开环控制。基于加速度和定位反馈纵向速度查找油门制动标定表得到油门和刹车的控制量,从而实现车辆的纵向控制。
汽车横向运动控制
无人驾驶的横向控制就是控制汽车的转向。横向控制根据上层运动规划输出的路径、曲率等信息进行跟踪控制,以减少跟踪误差,同时保证车辆行驶的稳定性和舒适性,如下图所示Apollo横向控制的框架结构。
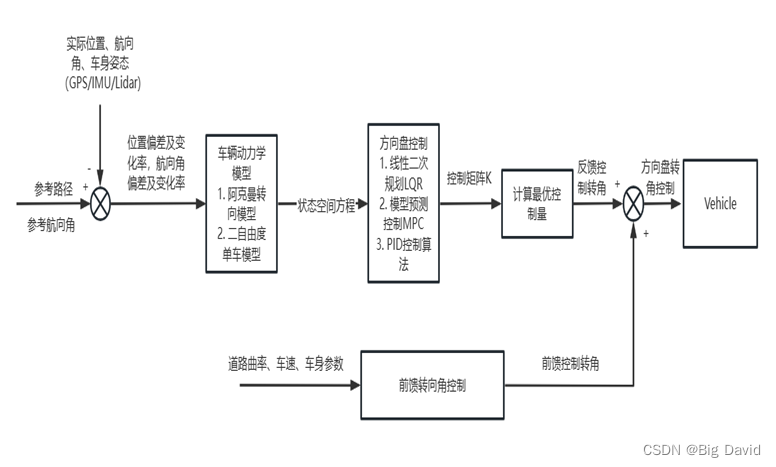
根据横向控制使用车辆模型的不同,可以分为两种类型,一种是无模型的横向控制方法,一种是基于模型的横向控制算法。
无模型的横向控制
无模型的横向控制即传统的PID控制算法,将车辆当前的路径跟踪偏差作为输入量,对路径跟踪偏差进行PID控制得到转向控制量。
因为PID算法不需要参考车辆模型,所以使用起来简单,适用于车辆低速行驶的控制。但PID算法由于没有考虑车辆本身的特性,因此对外界干扰的鲁棒性较差,无法满足车辆在高速行驶过程中的有效控制。
基于模型的横向控制
基于模型的方法分为基于车辆运动学模型的横向控制算法和基于车辆动力学的横向控制算法。
基于运动学模型的横向控制算法中,Pure Pursuit和Stanley前轮反馈算法在中低速场景下,路径跟踪性能较好。相比于 Pure Pursuit算法,Stanley 前轮反馈算法额外考虑了横摆角偏差。因此在大多数场景下,Stanley跟踪性能更佳。然而,由于没有设置前向预瞄,Stanley算法会出现转向过度的情况。与 Pure Pursuit和 Stanley算法相比,后轮反馈控制算法计算更加复杂,对路径的平滑性要求更高。在中等速度下的跟踪性能及鲁棒性与 Stanley方法近似。然而在速度较大时,稳态误差也会变大,从而导致控制效果不佳。
基于二自由度动力学模型的LQR算法与前述的基于运动学模型的横向控制算法相比,LQR参数调节更加复杂。不仅需要获取车辆自身的模型参数,还需要调节LQR成本函数的Q、R矩阵来得到较优的跟踪性能。LQR非常适用于路径平滑的高速公路及城市驾驶场景,具有较好的车辆高速控制性能。所以在业界量产中,LQR横向控制算法应用广泛。但是模型的固有缺陷,LQR与前馈控制的结合无法解决所有的跟踪问题。当无人驾驶汽车运动不满足二自由度动力学模型或者轮胎动力学线性化的假设条件时,LQR算法的跟踪性能会大幅度降低。

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









