







本篇源代码:
https://github.com/holdenQWER/CDC_example
CDC解决方案
EDA厂商提供golden的CDC处理单元,Synopsys的Building Block IP提供如下解决方案:
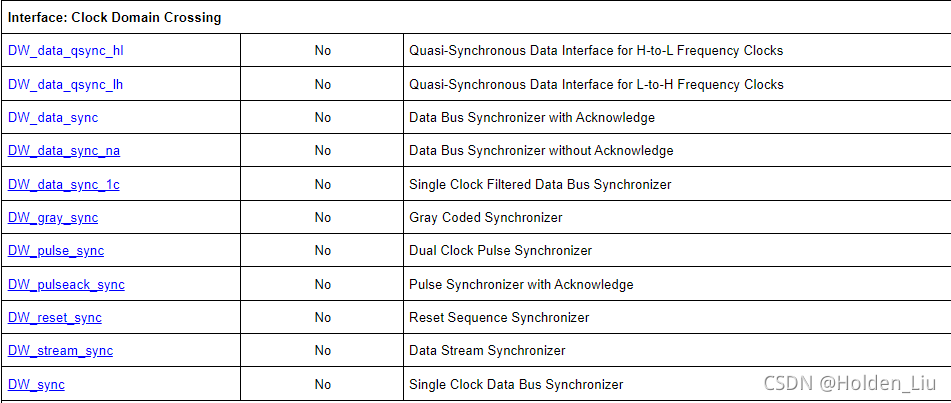
归类如下:

CDC处理中,根据跨时钟域信号宽度,分为Signle-bit和Mulit-bit。VC Spyglass CDC将Single-bit归为control path,Mulit-bit归为data path
Single-bit
Single-bit分为level 类型和event 类型。
Level Signal
level signal跨时钟域时,会保持较长时间不变,从快时钟域到慢时钟域,还是慢时钟域到快时钟域,都不会漏采样,使用2级同步器即可。
Event Signal
event signal常看做一个单周期的pulse signal。无论是快到慢,还是慢到快,都有漏采样的风险。
destination domain要确保成功采样到event single,需要event single至少维持destination domain 采样时钟3个沿(无论是上升沿还是下降沿,连续的3个沿)。

所以从慢时钟域到快时钟域,如果快时钟域的频率大于慢时钟域的1.5倍,就满足了three edge的要求。
Fast to Slow
从快时钟域到慢时钟域,需要对快时钟域的信号做展宽处理,以满足慢时钟域的three edge要求。
可以通过移位寄存器对evnet_signal做打拍处理,然后自身各bit相或,展宽event signal。移位寄存器的位宽和clock_ratio相关。这种展宽的方式只适合clock_ratio固定的CDC处理,相邻pulse的间隔也有要求。
Slow to Fast
从慢时钟域到快时钟域,如果频率相差较大,慢时钟域会过采样。可以使用边沿检测的方式,防止过采样。

event_d_dly1的Q端和D端取反后相与,检测上升边沿。evnet_s需间隔至少一个clk_s的周期,避免信号重叠漏采。
Pulse Synchronizer
上述两种CDC处理方法都有明显的限制,只能从快到慢或者从慢到快。可以将信号展宽和边沿检测相结合,设计一种通用的pulse synchronizer。
module pulse_sync(input clk_s,
input rstn_s,
input event_s,
input clk_d,
output event_d);
reg event_s_dly;
reg event_d_dly;
wire event_s_expand;
wire event_d_clr;
wire event_d_sync;
assign event_s_expand = (event_s | event_s_dly) & (~event_d_clr);
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
event_s_dly <= 1'b0;
else
event_s_dly <= event_s_expand;
rstn_sync u_rstn_sync(.clk(clk_d),
.rstn_in(rstn_s),
.rstn_out(rstn_d));
sync_cell u_sync_to_dst(.clk(clk_d),
.rst_n(rstn_d),
.in(event_s_dly),
.out(event_d_sync));
sync_cell u_sync_to_src(.clk(clk_s),
.rst_n(rstn_s),
.in(event_d_sync),
.out(event_d_clr));
always @(posedge clk_d or negedge rstn_d)
if(~rstn_d) begin
event_d_dly <= 1'b0;
end
else begin
event_d_dly <= event_d_sync;
end
assign event_d = event_d_sync & ~event_d_dly;
endmodule
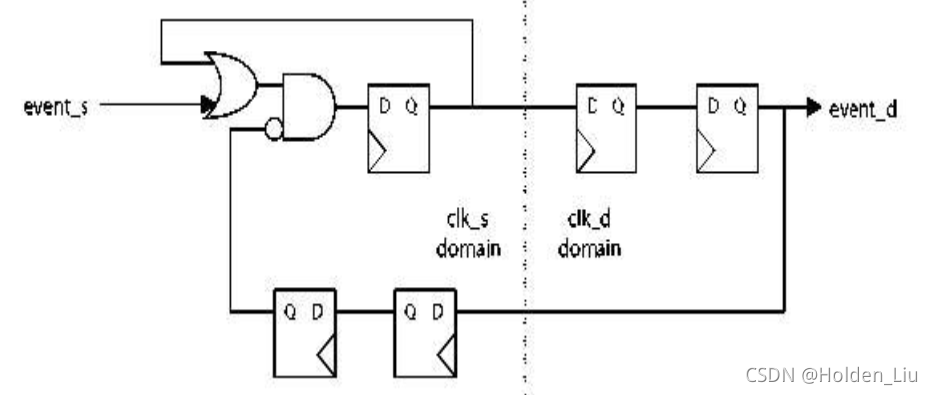
src domain利用或门将边沿信号转化成电平信号;destination domain采样到信号后回复ack清0。ack信号也需要2级同步处理。(上述电路图缺少了destination domain边沿检测的部分。)
上述设计的latency比较大,需要2次2级同步处理。event_s信号要和ack做好handshake。
A Better Design for Pulse Synchronizer
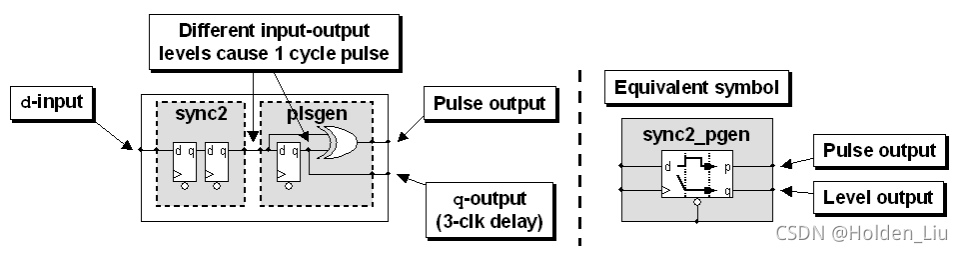
下面介绍一种Design Ware库中的脉冲同步器:DW_pulse_sync
电路逻辑如下:

将source domain的两级同步+电平转脉冲的电路结构用简易的图标表示如下:
CODE:
module pulse_sync(input clk_s,
input rstn_s,
input event_s,
input clk_d,
input rstn_d,
output event_d);
reg event_s_toggle;
reg event_d_dly;
wire event_d_sync;
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
event_s_toggle <= 1'b0;
else
event_s_toggle <= event_s_toggle ^ event_s;
sync_cell u_2dff_sync(.clk(clk_d),
.rst_n(rstn_d),
.in(event_s_toggle),
.out(event_d_sync));
always @(posedge clk_d or negedge rstn_d)
if(~rstn_d)
event_d_dly <= 1'b0;
else
event_d_dly <= event_d_sync;
assign event_d = event_d_dly ^ event_d_sync;
endmodule
source domain通过异或门,实现pulse的边沿转电平的操作。这种结构实现不归零编码Non-Return-to-Zero (NRZ),相当于一个toggle register。
destimation domain通过异或门将level转化成一个周期的pulse。
这种不需要ack的脉冲同步器,相比上一种设计,缩减了latency,结构也更简单。
使用时需注意一下两点:
第一:脉冲的频率小于目的域时钟频率的1/2

上述限制出于两点考虑,
1:event_s_toggle需要满足three edge,才能被目的域时钟有效采样到,频率相差1.5倍即可。
2:event_d_sync的level至少需要持续2拍,否则无法恢复出脉冲,也就是说event_s_toggle至少要被目的域时钟采样两次,频率相差2倍即可。
第二:source domain复位后,destinantion domain也需要复位
在奇数脉冲时,电平被toggle为1,只复位source domain,再次传播脉冲时,第一个脉冲会被漏采。
偶数脉冲时,可以单独复位source domain。
DW库中也提供了带反馈信号的脉冲同步器Dw_pulseack_sync ,结构如下:
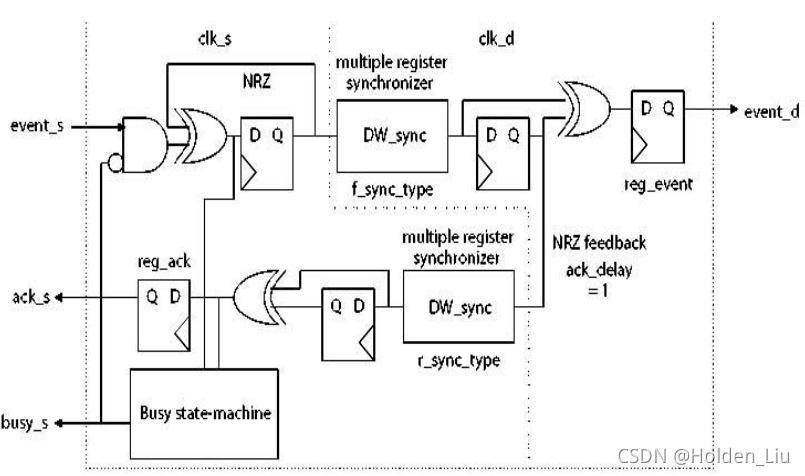
FSM判断ready busy:
module pulse_sync_ack(input clk_s,
input rstn_s,
input event_s,
input clk_d,
input rstn_d,
output event_d,
output ack_s);
reg event_s_toggle;
reg event_d_dly;
wire event_d_sync;
wire event_ack;
reg event_ack_dly;
wire ack_pulse;
reg state_cur;
reg state_nxt;
reg ack_r;
parameter READY = 1'b0;
parameter BUSY = 1'b1;
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
state_cur <= READY;
else
state_cur <= state_nxt;
always @(*) begin
state_nxt = state_cur;
case (state_cur)
READY:begin
ack_r = 1;
if(event_s)
state_nxt = BUSY;
end
BUSY: begin
ack_r = 0;
if(ack_pulse)
state_nxt = READY;
end
default: begin
state_nxt = READY;
end
endcase
end
assign ack_s = ack_r;
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
event_s_toggle <= 1'b0;
else
event_s_toggle <= event_s_toggle ^ (event_s & ack_s);
sync_cell u_2dff_sync_s(.clk(clk_d),
.rst_n(rstn_d),
.in(event_s_toggle),
.out(event_d_sync));
always @(posedge clk_d or negedge rstn_d)
if(~rstn_d)
event_d_dly <= 1'b0;
else
event_d_dly <= event_d_sync;
assign event_d = event_d_dly ^ event_d_sync;
sync_cell u_2dff_sync_d(.clk(clk_s),
.rst_n(rstn_s),
.in(event_d_dly),
.out(event_ack));
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
event_ack_dly <= 1'b0;
else
event_ack_dly <= event_ack;
assign ack_pulse = event_ack_dly ^ event_ack;
endmodule
只有在ack_s为高时,source domain才可以发送event_s脉冲,对异步时钟的频率没有要求,latency较大。

Mulit-bit
对于Mulit-bit的signal,总结如下几类方法:
- 对
Muilt-bit的各bit分别2级同步器处理。这种方式适用于可以通过格雷编码的设计,如Binary counters;下级电路对data coherency不敏感,如被软件处理的interrupt信号;使用更高频率过采样等等。 - 采用
Multi-Cycle Path (MCP )结构的设计。 - 使用异步FIFO。
上述的方法根据实际业务选择最佳方案,而不是相互取代的。
Multi-Cycle Path (MCP)formulation
MCP解释如下:

DW_data_sync_na就是一个MCP结构的设计:
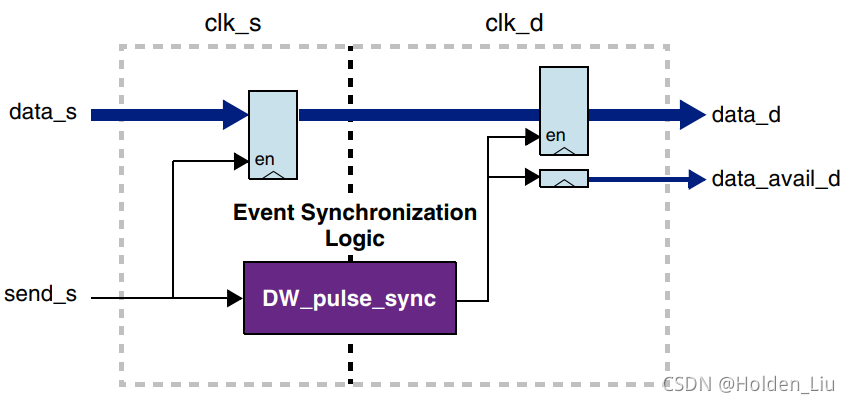
分为control path, data path;
control path需要同步处理,采用的是DW-pulse_sync;
data path不需要同步处理,节约寄存器使用;
源和目的端各一个data MUX,由同步的脉冲control信号控制。control使能时,data需保持不变,维持数个Multi-Cycle目的域时钟,直到被采样,避免了data path上的亚稳态。
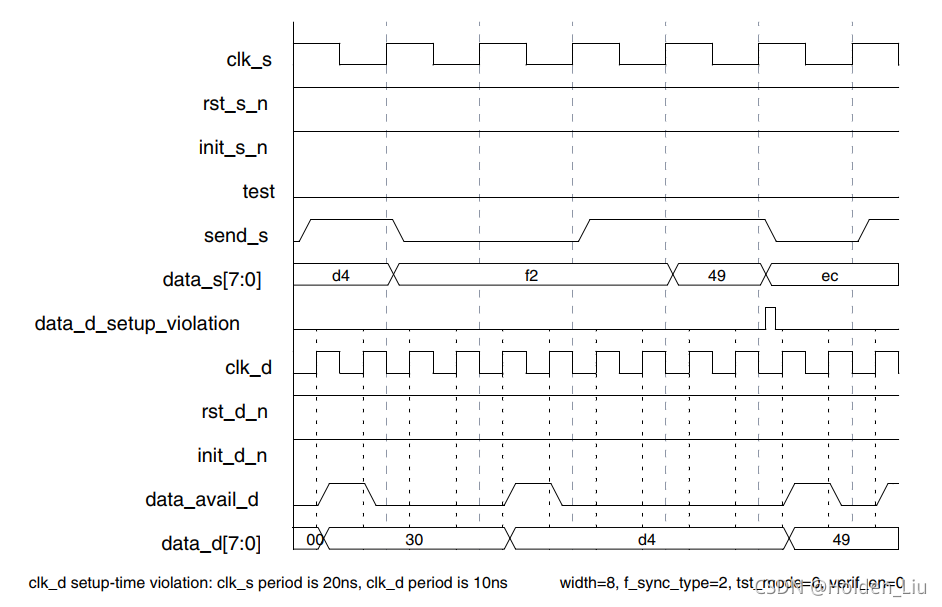
DW_data_sync_na不带ack反馈,若要支持back-to-back的传输,需要destination domain 频率比source domain频率快三倍。
如下图,频率2倍关系,dataf2和data49 back -to-back发送,dataf2 miss captured。DW_pulse_sync并不支持back-to-back的同步,需要额外逻辑设计,所以至少要3倍频率。
DW_data_sync则是带ack反馈的data同步器,结构类似如下:
是将上述DW_pulseack_sync的输出脉冲作为data MUX的sel。
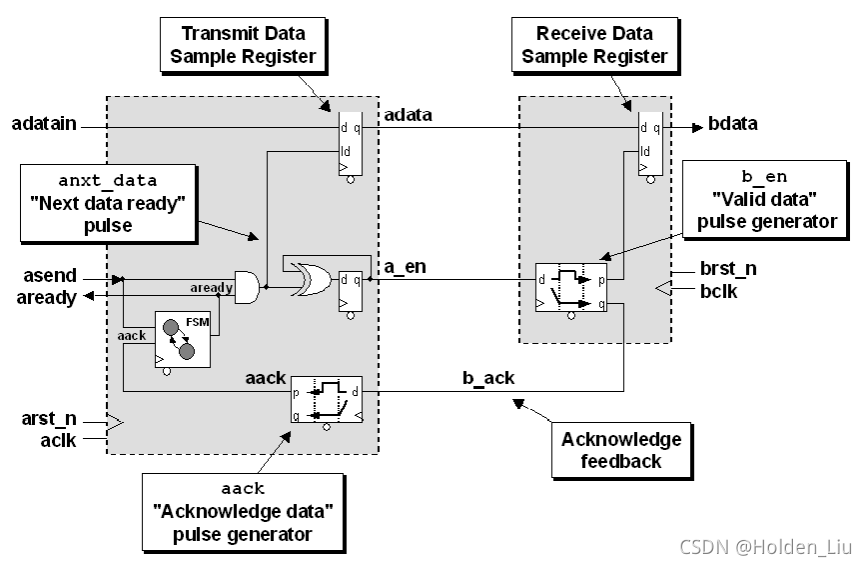
上述电路默认destination domain一直可以接收source domain的数据。
下面介绍一种destination domain可以通过load信号控制是否准备接受source doamin数据的流控结构:
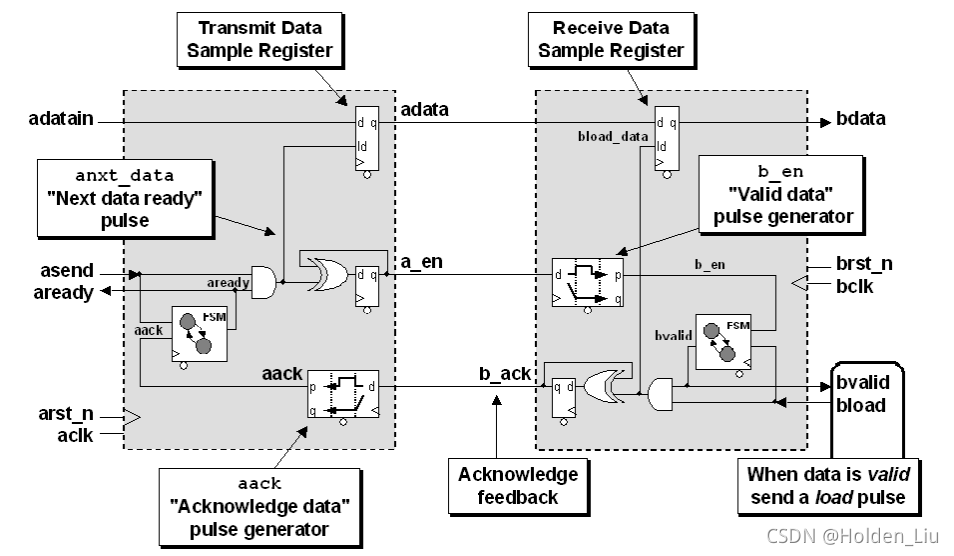
从电路图可以看出,source domain destination domain结构对称,destination domain的FSM划分为 idle wait ready的三个状态。
ack_s拉高时,src端拉高data_vld_s发送有效数据,期间data_s保持不变。随后ack_s拉低。- 数拍后
data_vld_d有效,并持续为高。直到dst端拉高load_d对data_vld_d下的data_d采样。 - 完成采样后,
ack_s拉高,src端可以进行下一次操作。

CODE:
module data_sync(input clk_s,
input rstn_s,
input data_vld_s,
input [7:0] data_s,
input clk_d,
input rstn_d,
input load_d,
output data_vld_d,
output reg [7:0] data_d,
output ack_s);
reg state_curs;
reg state_nxts;
reg [1:0]state_curd;
reg [1:0]state_nxtd;
reg ack_r;
parameter READYS = 1'b0;
parameter BUSYS = 1'b1;
parameter IDLED = 2'b00;
parameter WAITD = 2'b01;
parameter READYD = 2'b10;
reg [7:0] data_r;
reg data_vld;
wire data_sel_s;
wire data_sel_d;
wire ack_sync;
wire data_vld_sync;
// source domain data MUX
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
data_r <= 8'h0;
else if (data_sel_s)
data_r <= data_s;
// destination domain data MUX
always @(posedge clk_d or negedge rstn_d)
if(~rstn_d)
data_d <= 8'h0;
else if (data_sel_d)
data_d <= data_r;
// source domain FSM
always @(posedge clk_s or negedge rstn_s)
if(~rstn_s)
state_curs <= READYS;
else
state_curs <= state_nxts;
always @(*) begin
state_nxts = state_curs;
case (state_curs)
READYS:begin
ack_r = 1;
if(data_vld_s)
state_nxts = BUSYS;
end
BUSYS: begin
ack_r = 0;
if(ack_sync)
state_nxts = READYS;
end
default: begin
state_nxts = READYS;
end
endcase
end
assign ack_s = ack_r;
assign data_sel_s = data_vld_s & ack_s;
// source to destination pulse sync
pulse_sync u_pulse_sync_s(.clk_s(clk_s),
.rstn_s(rstn_s),
.event_s(data_sel_s),
.clk_d(clk_d),
.rstn_d(rstn_d),
.event_d(data_vld_sync));
// destination domain FSM
always @(posedge clk_d or negedge rstn_d)
if(~rstn_d)
state_curd <= IDLED;
else
state_curd <= state_nxtd;
always @(*) begin
state_nxtd = state_curd;
case (state_curd)
IDLED:begin
data_vld = 0;
if(data_vld_sync)
state_nxtd = WAITD;
end
WAITD:begin
data_vld = 1;
if(load_d)
state_nxtd = READYD;
end
READYD:begin
data_vld = 0;
if(!load_d)
state_nxtd = IDLED;
end
default:begin
state_nxtd = IDLED;
data_vld = 0;
end
endcase
end
assign data_sel_d = load_d & data_vld;
assign data_vld_d = data_vld;
// destination to source domain sync
pulse_sync u_pulse_sync_d(.clk_s(clk_d),
.rstn_s(rstn_d),
.event_s(data_sel_d),
.clk_d(clk_s),
.rstn_d(rstn_s),
.event_d(ack_sync));
endmodule
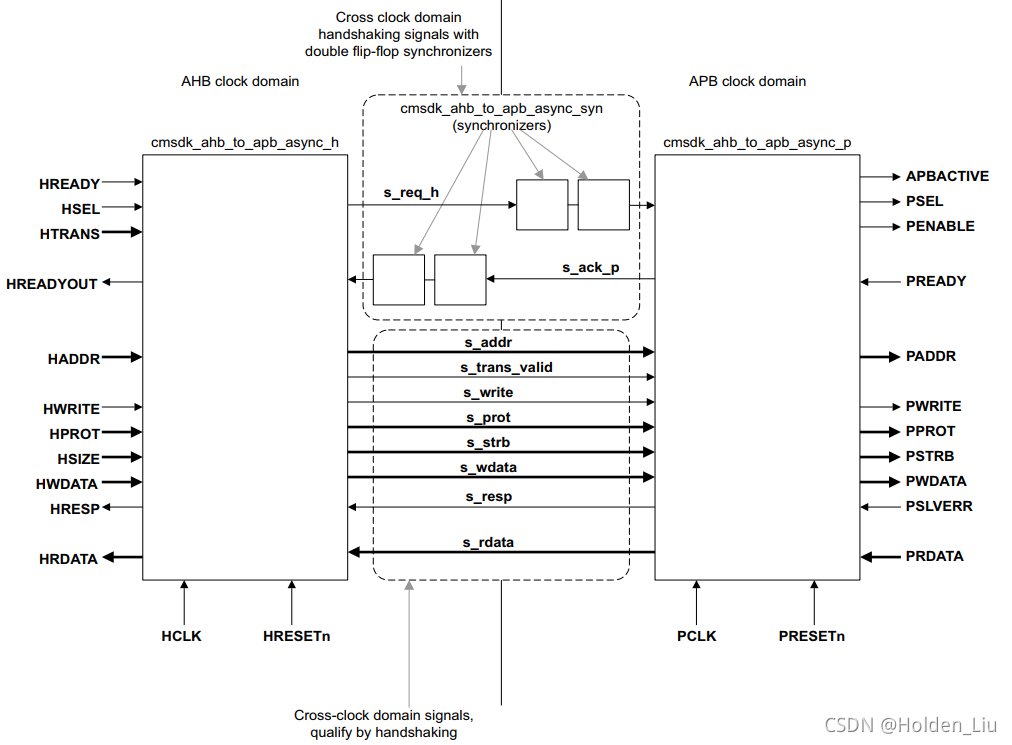
AHB to APB asynchronous bridge设计采用的也是MCP结构,只需要同步req/ack 握手信号。
异步FIFO
异步FIFO适用对缓冲有要求的异步数据流的设计。DW提供了常见的两种fifo,DW_fifo_s2_sf和DW_fifo_2c_df。
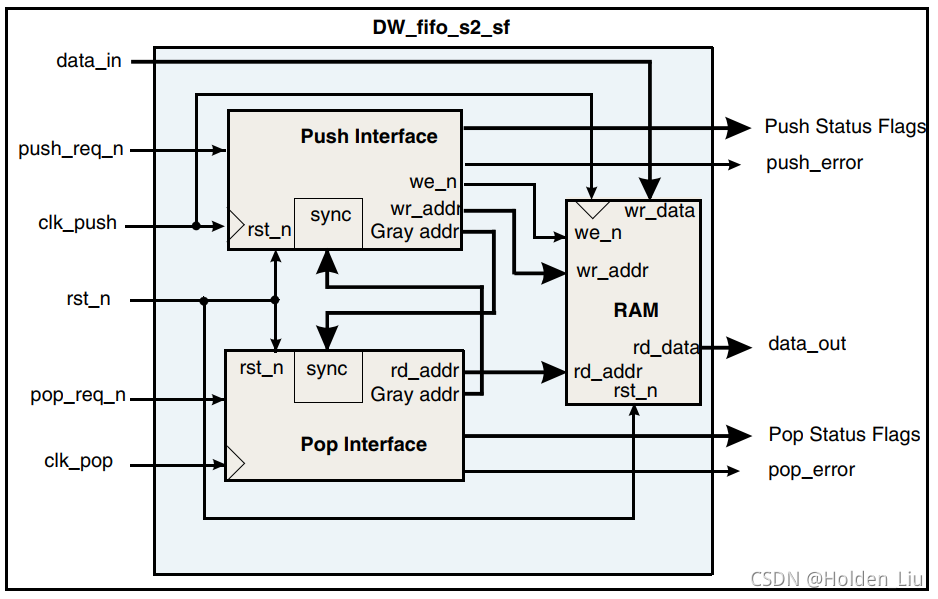
异步FIFO的设计难点主要在于异步读写指针的比较和空满状态的产生。具体参考:🔗 Simulation and Synthesis Techniques for Asynchronous FIFO Design with Asynchronous Pointer Comparisons – Cliff Cummings
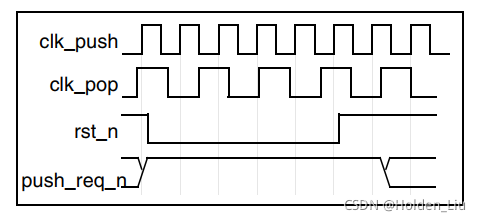
在使用DW_fifo_s2_sf需要注意,clk_push和clk_pop时钟域由一个rst_n控制,VC Spyglass CDC检测时会报error。可以将fifo设置为blackbox或者将rst_n设置为static。
为了避免复位时的亚稳态,需要rst_n拉低至少三个慢时钟的周期,并在一个clk_push周期后才可以push数据。建议rst_n使用clk_push的复位信号。
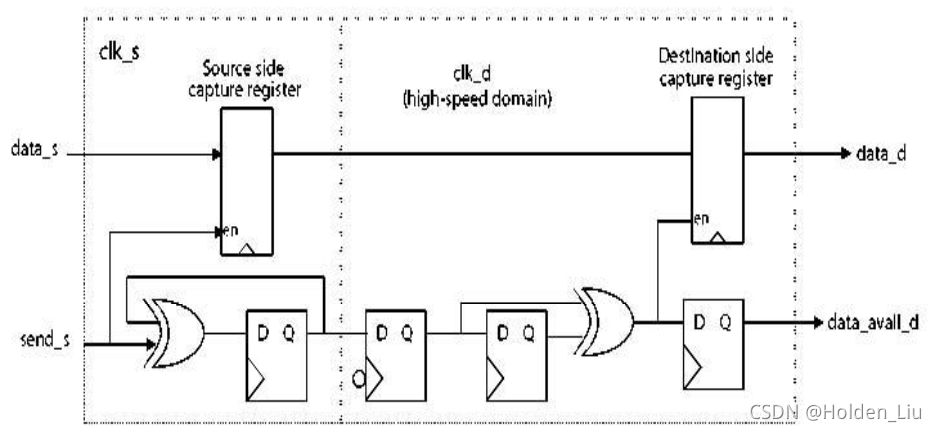
Qasi Synchronous
时钟同源,由同一个分频器产生,频率为整数倍关系,相位差固定,可以看成qasi synchronous准同步电路,可以当作同步电路处理,ctrl path不需要同步处理。
DW_data_qsync_lh 为快时钟域到慢时钟域的传输。
DW_data_qsync_hl 为慢时钟域到快时钟域的传输。
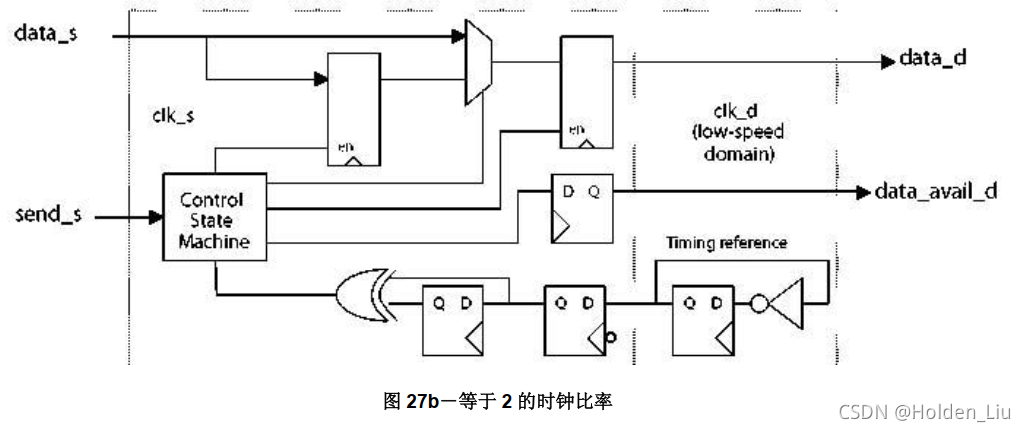
使用时配置clk_ratio参数。当clk_ratio = 2时,负责采样的第一个触发器使用下降沿采样,利于时序管理;其余情况所有触发器都是上升沿采样。
clk_ratio=2时DW_data_qsync_lh结构如下:
clk_ratio=2时DW_data_qsync_hl 结构如下:


















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











