







 本文介绍了2022年由Wang等人提出的基于自然界兔子生存策略的人工兔优化算法(ARO),该算法模仿了兔子的迂回觅食和随机隐藏行为,用于解决工程优化问题。算法通过动态调整能量因子实现搜索机制的灵活切换。
本文介绍了2022年由Wang等人提出的基于自然界兔子生存策略的人工兔优化算法(ARO),该算法模仿了兔子的迂回觅食和随机隐藏行为,用于解决工程优化问题。算法通过动态调整能量因子实现搜索机制的灵活切换。
1.背景
2022年,Wang等人受到自然界中兔子生存策略启发,提出了人工兔优化算法(ArtificialRabbits Optimization, ARO)。
2.算法原理
2.1算法思想
ARO模拟了自然界中兔子的生存策略,包括迂回觅食和随机隐藏。

2.2算法过程
迂回觅食:
在迂回觅食阶段,假设种群中的每只兔子都有自己的区域,有一些草和洞穴,兔子总是随机地访问彼此的位置觅食。事实上,在觅食时,兔子很可能会扰乱食物来源以获取足够的食物。因此,ARO 算法的迂回觅食行为意味着每个搜索个体倾向于使用向群中随机选择的其他搜索个体的位置来更新其位置,并添加扰动。
X
i
(
t
+
1
)
=
X
j
(
t
)
+
R
⋅
(
X
i
(
t
)
−
X
j
(
t
)
)
+
round
(
0.5
∙
(
0.05
+
r
1
)
)
∙
r
2
(1)
\begin{aligned}X_i\left(t+1\right)=&X_j\left(t\right)+R\cdot\left(X_i\left(t\right)-X_j\left(t\right)\right)+\text{round}\left(0.5\bullet\left(0.05+r_1\right)\right)\bullet r_2\end{aligned}\tag{1}
Xi(t+1)=Xj(t)+R⋅(Xi(t)−Xj(t))+round(0.5∙(0.05+r1))∙r2(1)
R 表示移动步长:
R
=
(
e
−
e
(
t
−
1
T
)
2
)
∙
sin
(
2
π
r
3
)
∙
c
(2)
R=(e-e^{(\frac{t-1}{T})^2})\bullet\sin(2\pi r_3)\bullet c\tag{2}
R=(e−e(Tt−1)2)∙sin(2πr3)∙c(2)
随机隐藏:
为了躲避捕食者,兔子通常会在巢穴周围挖一些不同的洞来躲藏。在 ARO 算法的每次迭代中,兔子总是沿着搜索空间的每个维度在其周围产生若干个洞穴,并且总是从所有洞穴中随机选择一个进行隐藏,以降低被捕食的概率。
X
i
(
t
+
1
)
=
X
i
(
t
)
+
R
∙
(
r
4
∙
H
∙
g
∙
X
i
(
t
)
−
X
i
(
t
)
)
(3)
\begin{aligned}X_i\left(t+1\right)=&X_i\left(t\right)+R\bullet\left(r_4\bullet H\bullet g\bullet X_i\left(t\right)-\right.X_i\left(t\right))\end{aligned}\tag{3}
Xi(t+1)=Xi(t)+R∙(r4∙H∙g∙Xi(t)−Xi(t))(3)
H 为隐藏参数:
H
=
T
−
t
+
1
T
∙
r
5
(4)
H=\frac{T-t+1}T\bullet r_5\tag{4}
H=TT−t+1∙r5(4)
在 ARO 算法中,兔子总是倾向于在迭代初始阶段频繁地进行迂回觅食,而在迭代后期阶段频繁地进行随机隐藏,这种搜索机制取决于兔子的能量,它会随着时间的推移而逐渐收缩。能量因子A :
A
(
t
)
=
4
∙
(
1
−
t
T
)
∙
ln
1
r
6
(5)
A(t)=4\bullet(1-\frac tT)\bullet\ln\frac1{r_6}\tag{5}
A(t)=4∙(1−Tt)∙lnr61(5)
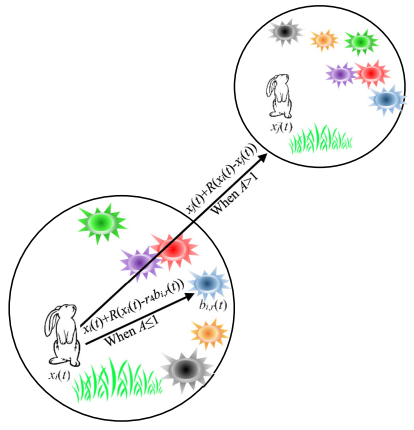
伪代码:

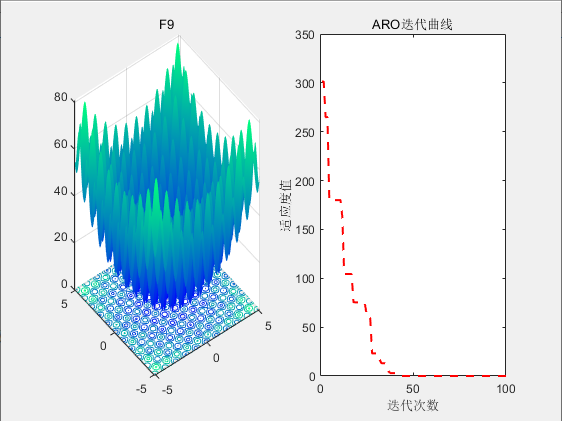
3.结果展示
4.参考文献
[1] Wang L, Cao Q, Zhang Z, et al. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems[J]. Engineering Applications of Artificial Intelligence, 2022, 114: 105082.


















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











