








1.摘要
本文提出了一种创新的优化算法——指数-三角优化算法(ETO),它巧妙地结合了指数函数和三角函数。ETO算法设计上着重于探索与开发两个阶段的平衡,这是众多优化算法共同面临的挑战。通过整合多个随机和自适应变量,ETO算法在性能上相比现有算法实现了显著的提升。
2.算法原理
指数-三角优化算法通过运用指数和三角函数来调整搜索个体的位置,有效实现了探索与开发的平衡。此外,ETO的设计考虑到了处理复杂技术问题的需要,基于NFL理论强调了不同问题需求不同优化策略的重要性。ETO的结构简单,易于实施和调整参数,使其不仅在性能上优越,还在适应不同问题类型上具有极高的灵活性和适应性。
受限探索方法
受限搜索策略通过有限探索方法来优化搜索过程,减少计算资源和时间消耗,同时确保捕捉到最优解:
C
E
i
+
1
=
f
l
o
o
r
[
2
−
2
×
t
×
(
M
a
x
_
I
t
e
r
−
C
E
i
×
a
)
]
+
C
E
i
C
E
i
=
f
l
o
o
r
(
1
+
M
a
x
_
I
t
e
r
b
)
\begin{aligned}&CE_{i+1}=floor[2-2\times t\times(Max\_Iter-CE_i\times a)]+CE_i\\\\&CE_i=floor\left(1+\frac{Max\_Iter}b\right)\end{aligned}
CEi+1=floor[2−2×t×(Max_Iter−CEi×a)]+CEiCEi=floor(1+bMax_Iter)
受限探索策略确定当前迭代的探索限制,随后更新搜索空间的上限和下限:
U
p
i
=
r
1
×
(
1
−
t
M
a
x
_
I
t
e
r
)
×
∣
r
2
×
X
j
b
e
s
t
−
X
j
s
∣
+
X
j
b
e
s
t
L
o
w
i
=
−
r
1
×
(
1
−
t
M
a
x
_
I
t
e
r
)
×
∣
r
2
×
X
j
b
e
s
t
−
X
j
s
∣
+
X
j
b
e
s
t
\begin{gathered} Up_{i}=r_{1}\times\left(1-{\frac{t}{Max\_Iter}}\right)\times\left|r_{2}\times X_{j}^{best}-X_{j}^{s}\right|+X_{j}^{best} \\ Low_{i}=-r_{1}\times\left(1-{\frac{t}{Max\_Iter}}\right)\times\left|r_{2}\times X_{j}^{best}-X_{j}^{s}\right|+X_{j}^{best} \end{gathered}
Upi=r1×(1−Max_Itert)×
r2×Xjbest−Xjs
+XjbestLowi=−r1×(1−Max_Itert)×
r2×Xjbest−Xjs
+Xjbest
探索阶段
优化过程中的探索阶段被细分为两个阶段,持续的迭代对于防止算法收敛至局部最优解至关重要:
X
t
+
1
i
,
j
=
{
X
j
b
e
s
t
+
r
a
n
d
(
)
×
α
1
×
∣
X
j
b
e
s
t
−
X
t
i
j
∣
i
f
q
1
≤
0.5
X
j
b
e
s
t
−
r
a
n
d
(
)
×
α
1
×
∣
X
j
b
e
s
t
−
X
t
i
j
∣
i
f
q
1
>
0.5
X_{t+1}^{i,j}=\begin{cases}X_j^{best}+rand()\times\alpha_1\times\left|X_j^{best}-X_t^{ij}\right|\mathrm{if}q_1\leq0.5\\\\X_j^{best}-rand()\times\alpha_1\times\left|X_j^{best}-X_t^{ij}\right|\mathrm{if}q_1>0.5\end{cases}
Xt+1i,j=⎩
⎨
⎧Xjbest+rand()×α1×
Xjbest−Xtij
ifq1≤0.5Xjbest−rand()×α1×
Xjbest−Xtij
ifq1>0.5
其中,参数
a
1
a_1
a1表述为:
α
1
=
3
×
r
a
n
d
(
)
×
(
t
Max
_
I
t
e
r
−
0.85
)
×
exp
(
d
1
d
2
−
1
)
\alpha_1=3\times rand()\times\left(\frac{t}{\text{Max}\_Iter}-0.85\right)\times\exp\left(\frac{d_1}{d_2}-1\right)
α1=3×rand()×(Max_Itert−0.85)×exp(d2d1−1)
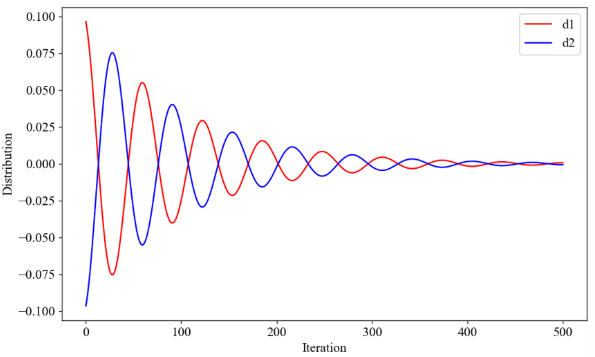
d
1
=
0.1
×
exp
(
−
0.01
×
t
)
×
cos
[
0.5
×
M
a
x
I
t
e
r
×
(
1
−
t
M
a
x
I
t
e
r
)
]
d
2
=
−
0.1
×
exp
(
−
0.01
×
t
)
×
cos
[
0.5
×
M
a
x
I
t
e
r
×
(
1
−
t
M
a
x
I
t
e
r
)
]
d_{1}=0.1\times\exp(-0.01\times t)\times\cos\biggl[0.5\times Max_Iter\times\biggl(1-\frac{t}{Max_Iter}\biggr)\biggr]\\d_{2}=-0.1\times\exp(-0.01\times t)\times\cos\biggl[0.5\times Max_Iter\times\biggl(1-\frac{t}{Max_Iter}\biggr)\biggr]
d1=0.1×exp(−0.01×t)×cos[0.5×MaxIter×(1−MaxItert)]d2=−0.1×exp(−0.01×t)×cos[0.5×MaxIter×(1−MaxItert)]
在探索程序的后续阶段,个体行为相对独立,不受之前确定的最佳解的影响。这种独立性使得它们可以无方向性偏见地进入搜索空间的新区域,其移动仅由当前位置直接决定。个体位置更新:
X
t
+
1
i
j
=
{
X
t
i
j
+
3
×
∣
r
a
n
d
(
)
×
α
2
×
X
j
b
e
s
t
−
X
t
i
j
∣
if
q
2
≤
0.5
X
t
i
j
−
3
×
∣
r
a
n
d
(
)
×
α
2
×
X
j
b
e
s
t
−
X
t
i
j
∣
if
q
2
>
0.5
X_{t+1}^{ij}=\begin{cases}X_t^{ij}+3\times\left|rand()\times\alpha_2\times X_j^{best}-X_t^{ij}\right|\text{if}q_2\leq0.5\\X_t^{ij}-3\times\left|rand()\times\alpha_2\times X_j^{best}-X_t^{ij}\right|\text{if}q_2>0.5\end{cases}
Xt+1ij=⎩
⎨
⎧Xtij+3×
rand()×α2×Xjbest−Xtij
ifq2≤0.5Xtij−3×
rand()×α2×Xjbest−Xtij
ifq2>0.5
其中,参数
a
2
a_2
a2表述为:
α
2
=
r
a
n
d
(
)
×
exp
{
tanh
[
1.5
×
(
−
t
M
a
x
_
I
t
e
r
−
0.75
)
−
r
a
n
d
(
)
]
}
\alpha_2=rand()\times\exp\left\{\tanh\left[1.5\times\left(-\frac{t}{Max\_Iter}-0.75\right)-rand()\right]\right\}
α2=rand()×exp{tanh[1.5×(−Max_Itert−0.75)−rand()]}
开发阶段
为确保全面探索搜索空间,开发过程被明确分为两个阶段,这两个阶段贯穿整个迭代过程。在第一阶段,算法主要集中于探索当前点邻域:
X
t
+
1
i
j
=
{
X
j
b
e
s
t
+
q
4
×
α
3
×
∣
m
n
d
(
)
×
X
j
b
e
s
t
−
X
t
i
,
j
∣
i
f
q
3
≤
0.5
X
j
b
e
s
t
−
q
4
×
α
3
×
∣
m
n
d
(
)
×
X
j
b
e
s
t
−
X
t
i
,
j
∣
i
f
q
3
>
0.5
X_{t+1}^{ij}=\begin{cases}X_j^{best}+q_4\times\alpha_3\times\left|\boldsymbol{m}\boldsymbol{n}\boldsymbol{d}()\times X_j^{best}-X_t^{i,j}\right|\mathrm{if}q_3\leq0.5\\X_j^{best}-q_4\times\alpha_3\times\left|\boldsymbol{m}\boldsymbol{n}\boldsymbol{d}()\times X_j^{best}-X_t^{i,j}\right|\mathrm{if}q_3>0.5\end{cases}
Xt+1ij=⎩
⎨
⎧Xjbest+q4×α3×
mnd()×Xjbest−Xti,j
ifq3≤0.5Xjbest−q4×α3×
mnd()×Xjbest−Xti,j
ifq3>0.5
其中,参数
a
3
a_3
a3表述为:
α
3
=
3
×
r
a
n
d
(
)
×
(
t
Max
_
I
t
e
r
−
0.85
)
×
exp
(
∣
d
1
d
2
∣
−
1.3
)
\alpha_3=3\times rand()\times\left(\frac{t}{\text{Max}\_Iter}-0.85\right)\times\exp\left(\left|\frac{d_1}{d_2}\right|-1.3\right)
α3=3×rand()×(Max_Itert−0.85)×exp(
d2d1
−1.3)
在开发的后期阶段,候选解中心围绕已识别的最佳解进行更集中的探索:
X
t
+
1
i
j
=
X
t
i
,
j
+
c
×
∣
r
a
n
d
(
)
×
α
2
×
X
j
b
e
s
t
−
X
t
i
,
j
∣
X_{t+1}^{ij}=X_{t}^{i,j}+c\times\left|rand()\times\alpha_{2}\times X_{j}^{best}-X_{t}^{i,j}\right|
Xt+1ij=Xti,j+c×
rand()×α2×Xjbest−Xti,j
其中,参数
c
c
c表述为:
c
=
exp
[
tan
(
∣
d
1
d
2
∣
)
]
c=\exp\biggl[\tan\biggl(\biggl|\frac{d_1}{d_2}\biggr|\biggr)\biggr]
c=exp[tan(
d2d1
)]
伪代码


3.结果展示
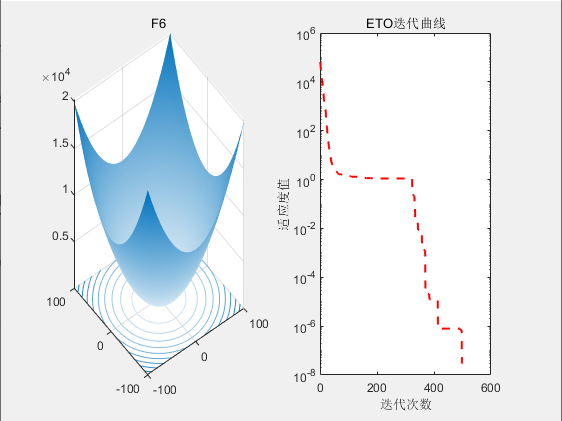
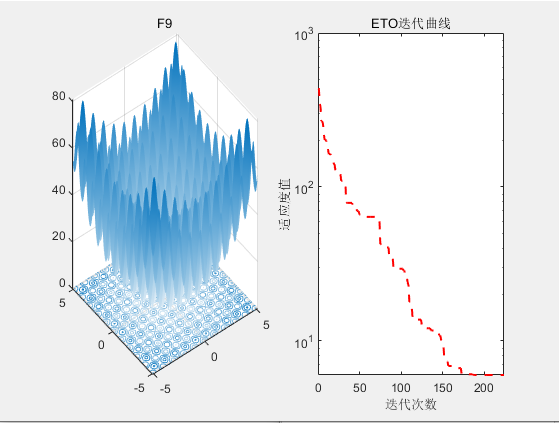
4.参考文献
[1] Luan T M, Khatir S, Tran M T, et al. Exponential-trigonometric optimization algorithm for solving complicated engineering problems[J]. Computer Methods in Applied Mechanics and Engineering, 2024, 432: 117411.


















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











