








 本文介绍了一种新型深度网络PointPillars,可在LiDAR点云上进行端到端训练,实现3D对象检测。在KITTI挑战中,PointPillars在速度和准确性方面超越了现有方法,特别是在鸟瞰图(BEV)和3D指标上的平均精度(mAP)。通过使用垂直柱状结构和2D卷积层,该方法不仅提高了检测性能,还显著提升了运算速度。
本文介绍了一种新型深度网络PointPillars,可在LiDAR点云上进行端到端训练,实现3D对象检测。在KITTI挑战中,PointPillars在速度和准确性方面超越了现有方法,特别是在鸟瞰图(BEV)和3D指标上的平均精度(mAP)。通过使用垂直柱状结构和2D卷积层,该方法不仅提高了检测性能,还显著提升了运算速度。
https://arxiv.org/abs/1812.05784
PointPillars:用于从点云进行对象检测的快速编码器
文章目录
概述
In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline.
本文考虑将点云编码为适合下游检测管道的格式的问题。
两种编码器
最近的文献表明,编码器有两种类型:
- 固定编码器( fixed encoders ),往往速度快,但牺牲了准确性,
- 从数据中学习的编码器更准确,但速度较慢
我们提出了
PointPillars 编码器:利用PointNets学习垂直柱(柱)中组织的点云的representation特征
a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars).
PointPillars在速度和精度方面都大大优于以前的编码器
进一步提出:精简的下游网络
a lean downstream network
虽然编码后的特征可用于任何标准的 2D 卷积检测架构,但我们进一步提出了一个精简的下游网络。
性能
此检测性能是在 62 Hz 运行时实现的:2 - 4 倍的运行时间改进。
我们方法的更快版本: 105 Hz
1. Introduction
激光雷达使用激光扫描仪测量到环境的距离,从而生成稀疏点云表示。
传统上,激光雷达处理 的pipeline 的目标检测是: 通过涉及背景扣除的自下而上的管道,然后进行时空聚类和分类。
a bottom-up pipeline involving background subtraction, followed byspatiotemporal clustering and classification.
效果背书
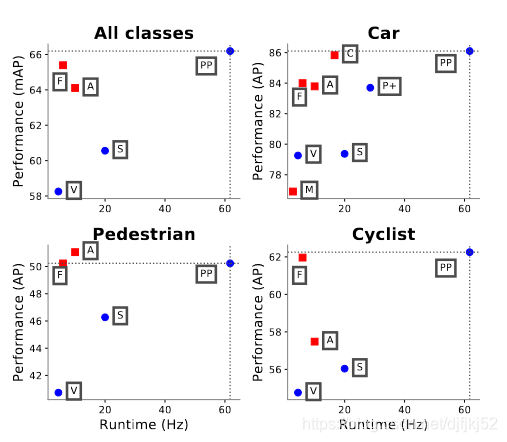
图1.在KITTI [5]测试装置上,我们提出的PointPillars,PointPillars方法的鸟瞰图性能与速度之间的关系。
仅限激光雷达的方法绘制为蓝色圆圈;
激光雷达和视觉方法绘制的红色方块。
还从KITTI排行榜上绘制了一些顶级方法:M:MV3D [2],AAVOD [11],C:ContFuse [15],V:VoxelNet [31],F:Frustum PointNet [21],S:SECOND [ 28],P + PIXOR ++ [29]。
在速度和准确性方面,PointPillars均优于其他所有仅使用激光雷达的方法,并且除行人之外还优于所有基于融合的方法。在3D度量标准上实现了类似的性能(表2)。
计算机视觉与lidar之间的主要差异:
虽然图像处理的方式之间有很多相似之处,但是有两个主要区别:
1)点云是一个稀疏表示,而图像是密集的,
2)点云是3D的,而图像是2D的,因此从点云进行对象检测不会轻易地适用于标准的图像卷积流水线。
早期的研究
一些早期的工作着重于使用3D卷积[3]或将点云投影到图像中[14]。
Some early works focus on either using 3D convolu-tions [3] or a projection of the point cloud into the image[14].
最近热点
从鸟瞰图观察激光雷达点云[2,11,31,30]。
Recent methods tend to view the lidar point cloudfrom a bird’s eye view [2, 11, 31, 30].
从上面透视的几个好处:
- 没有尺度歧义性
- 几乎没有遮挡
鸟瞰图的缺点
鸟瞰图往往非常稀疏,这使得直接应用卷积神经网络不切实际且效率低下。
解决此问题的常用方法
解决此问题的常用方法是将地平面划分为规则网格(例如10 x 10厘米),然后在每个网格单元中的点上执行手工制作的特征编码方法[2、11、26、30]。
不是最优的
由于hard-coded 特征提取方法可能不能推广到新的不同配置/厂家的激光雷达传感器,在没有大量工程努力的情况下,因此这些方法可能不是最优的。
首批良好通用的方法 VoxelNet
为了解决这些问题,并建立在Qi等人开发的PointNet设计上。 [22],VoxelNet [31]是在此领域真正进行端到端学习的首批方法之一。
1、VoxelNet将空间划分为多个体素(spaceinto voxels),将PointNet应用于每个体素;
2、然后是3D卷积中间层以合并垂直轴;
3、然后应用2D卷积检测体系结构。
尽管VoxelNet性能很强,但4.4Hz的推理时间太慢,无法实时部署。最近SECOND [28]改进了VoxelNet的推理速度,但3D卷积仍然是瓶颈。
PointPillars 仅使用2D卷积层就可以进行端到端学习
PointPillars使用一种新颖的编码器,该编码器学习点云的支柱(垂直列)上的特征,以预测面向对象的3D方向的盒子。
这种方法有几个优点。
1、首先,通过学习功能而不是依靠固定的编码器,PointPillarscan利用了点云所表示的全部信息。
2、此外,通过在支柱上而不是体素上进行操作,无需手动调整垂直方向的分箱。
3、最后,支柱是高效的,因为所有键操作都可以表述为2D卷积,在GPU上进行计算非常高效。
4、 学习功能的另一个好处是PointPillars无需手动调整即可使用不同的点云配置。例如,它可以轻松地合并多个激光雷达/雷达点云。
代码
我们还重新发布了可以重现我们结果的代码(https://github.com/nutonomy/second.pytorch)。
卷积神经网络进展
我们首先回顾一下将卷积神经网络应用于对象检测的最新工作,然后重点研究特定于来自点云的对象检测的方法。
1.1.1使用CNN进行目标检测
从Girshick等人的开创性工作开始 [6]建立了卷积神经网络(CNN)结构是图像检测的最新技术。
一系列论文提出了针对该问题的两阶段方法,其中在第一阶段中,区域提案网络(RPN)提出了候选提案。然后,对这些提案的裁剪和调整大小版本进行第二阶段分类网络。
在Liu等人最初提出的单阶段架构,在单阶段体系结构中,大量的锚定框被回归,并在单个阶段中被分类为一组预测,从而提供了一种快速,简单的体系结构。在准确性和运行时间方面,单阶段方法优于两阶段方法。在这项工作中,我们使用单阶段方法
在这项工作中,我们使用单阶段方法
1.1.2 激光雷达点云中的目标检测
部署3D卷积
1、点云中的对象检测本质上是三个维度的问题。因此,部署3D卷积网络进行检测是很自然的,这是几项早期工作的范例[3,13]。虽然提供了直接的体系结构,但是这些方法很慢。例如恩格尔基特等人。 [3]在单点云上推理需要0.5s。
2、大多数最新方法通过将3D点云投影到地平面[11,2]或图像平面[14]上来改善运行时间。
2.1、在最常见的范例中,点云以体素组织,每个垂直列中的体素集被编码为固定长度,手工制作的特征编码,以形成可以由标准图像检测体系结构处理的伪图像。
2.2、这里值得注意的作品包括MV3D [2],AVOD [11],PIXOR [30]和Complex YOLO [26],它们使用相同固定编码 作为其架构的第一步。
2.3、前两种方法还将激光雷达特征与图像特征融合在一起,以创建多模式检测器。
2.4、MV3D和AVOD中使用的融合步骤迫使它们使用two-satge
2.5、PIXOR和Complex YOLO使用single stage
简单的体系结构:PointNet
在他们的开创性工作中,齐等人。 [22,23]提出了一个简单的体系结构PointNet,用于从无序的点集中学习,这为全面的端到端学习提供了一条途径。
Vox-elNet [31]是在激光雷达点云中部署PointNets进行物体检测的首批方法之一。在他们的方法中,将PointNets应用于体素,然后由一组3D卷积层,一个2D骨架和一个检测头对其进行处理。这样可以进行端到端学习,但是像早期依赖3D卷积的工作一样,Voxel-Net速度很慢,单个点云需要225ms的推理时间(4.4Hz)。
另一种最近的方法,Frustum Point-Net [21],使用PointNets对视锥中的点云进行分割和分类,该视锥是将对图像的检测投影到3D中生成的。与其他融合方法相比,Frustum PointNet拥有较高的基准性能,但其多阶段设计使端到端学习变得不切实际。
最近,SECOND [28]对VoxelNet进行了一系列改进,从而提高了性能并大大提高了20Hz的速度。但是,它们无法删除十分占用资源的的3D卷积层。
1.2. Contributions
我们提出了一种新颖的点云编码器和网络PointPillars,
它在点云上运行以实现对3D对象检测网络的端到端训练, 比其他方法快2-4倍。
我们在KITTI数据集上进行了实验,并在BEV和3D基准上展示了汽车,行人和骑自行车者的最新技术水平。
我们进行了一些消融研究以检查 实现强大检测性能的关键因素。
PointPillars Network
PointPillars接受点云作为输入,并估算面向汽车,行人和骑自行车的人的3D框。
它包括三个主要阶段(图2):
(1)一种特征编码器网络,可将点云转换为稀疏伪图像;
(2)2D卷积主干,用于将伪图像处理为高级表示;
(3)检测头,该检测头可检测并退回3D bbox
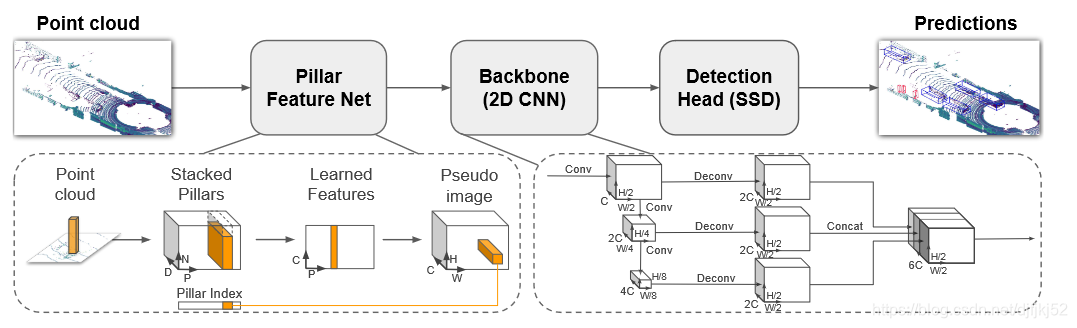
网络的主要组件是:
-
a Pillar Feature Network,
-
Backbone,
-
and SSD Detection Head.
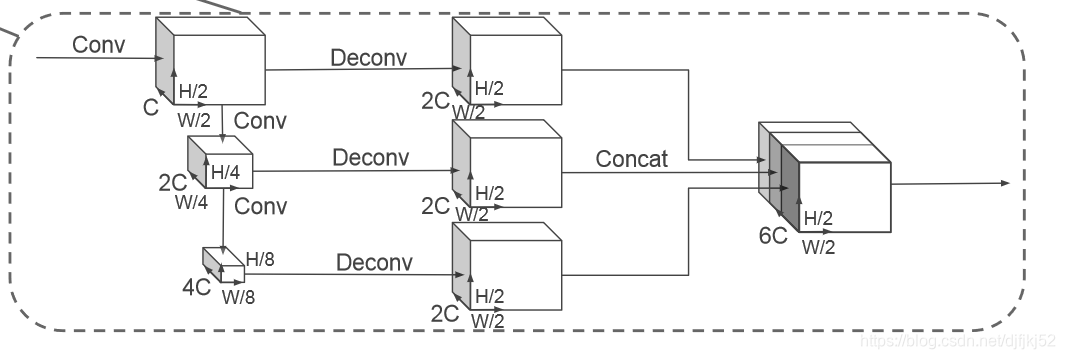
原始点云将转换为堆叠的柱张量和柱索引张量。 编码器使用堆叠的支柱来学习一组特征,这些特征可以分散回2D伪图像以进行卷积神经网络。 检测头使用来自骨干的特征来预测对象的3D边界框。 注意:此处显示了汽车网络的骨干尺寸
2.1。 Pointcloud到伪图像 Pseudo-Image
要应用2D卷积架构,我们首先将点云转换为伪图像
1、我们用 l 表示点云中具有坐标x,y,z和反射强度
2、第一步,将点云离散到x-y平面中的均匀间隔的网格中,从而创建一组支柱P ,具有| P | = B。(注意,不需要超级参数来控制z维度中的合并。)
3、将每个支柱中的点增加xc,yc,zc,xp和yp
4、其中c下标表示到支柱中所有点的算术平均值的距离,p下标表示从支柱x,y中心的偏移量。
5、现在,增强的激光雷达点l为D = 9维。
由于点云的稀疏性,该组支柱将大部分为空,而非空支柱通常将在其中拥有很少的点。
例如,来自HDL-64E Velodyne激光雷达的点云在0.162平方米处具有6k-9k非空柱,在KITTI中通常使用的范围为约97%的稀疏度。
通过对每个样本的非空支柱数(P)和每个支柱的点数(N)施加限制,来创建大小为(D,P,N)的张量张量,从而利用这种稀疏性。
如果样本或支柱容纳的数据太多,无法容纳该张量,则将数据随机采样。 相反,如果样本或支柱的数据太少而无法填充张量,则将使用零填充
接下来,我们使用PointNet的简化版本,其中,对于每个点,都应用线性层,然后是Batch-Norm [10]和ReLU [19],以生成一个(C,P,N)大小的张量。 接下来是对通道的最大操作,以创建大小为(C,P)的输出张量。 请注意,可以将线性层公式化为张量上的1x1卷积,从而实现非常有效的计算
编码后,特征散布回原始支柱位置,以创建大小为(C,H,W)的伪图像,其中H和W表示画布的高度和宽度。
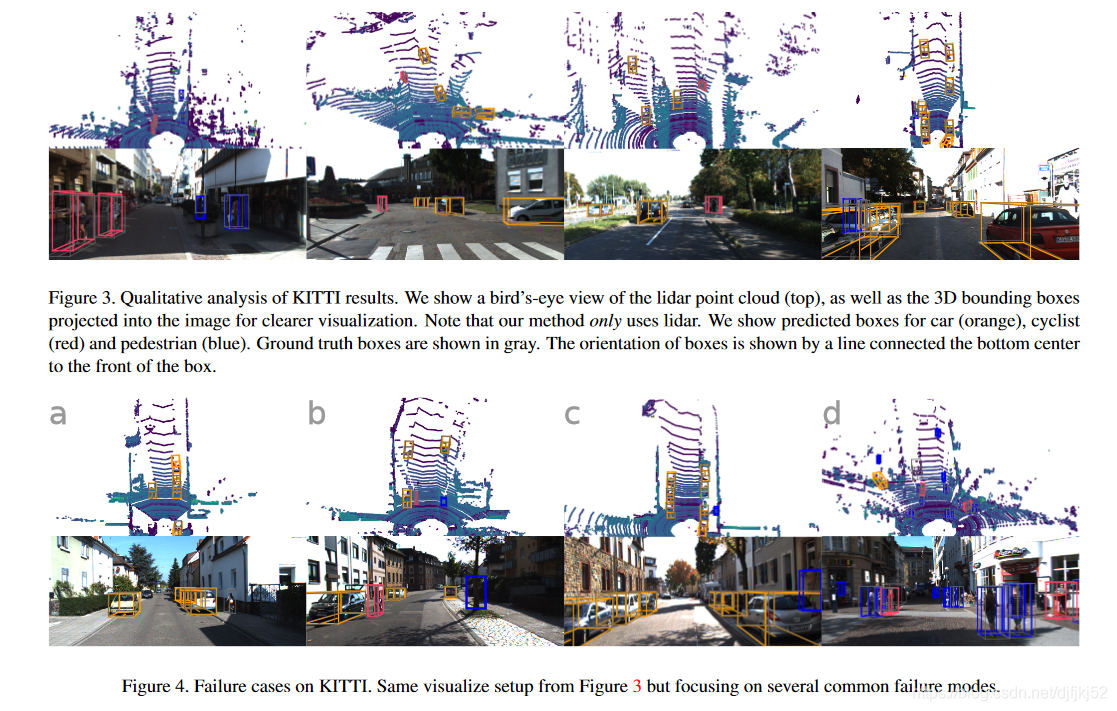
图4. KITTI上的故障案例。 从图3中可以看到相同的设置,但重点是几种常见的故障模式。
2.2. Backbone
我们使用与[31]类似的主干,其结构如图2所示。主干具有两个子网:一个自上而下的网络以越来越小的空间分辨率产生特征,另一个网状网络执行上采样和采样。 自上而下的功能的串联。 自上而下的主干网可以由一系列块Block(S,L,F)来表征。 每个块的步幅为S(相对于原始输入伪图像进行测量)。一个块具有L3x3 2D转换层,具有F个输出通道,每个通道后跟BatchNorm和ReLU。
该层内部的第一个卷积具有步幅S / Sin,以确保该块在收到步幅S_in的输入Blob后在步幅S上运行。
块中的所有后续卷积都步长为1
每个自上而下块的最终特征通过如下的上采样和级联进行组合:首先,将特征从初始步幅Sin上采样到Up(Sin,Sout,F)到最终步幅Sout(都再次测量为wrut。) 图片)使用具有最终特征的转置二维卷积。 接下来,将BatchNorm和ReLU应用于上采样功能。 最终的输出功能是源自不同步幅的所有功能的串联。
2.3. Detection Head
在本文中,我们使用单发检测器(SSD)[18]设置执行3D对象检测。 与SSD相似,我们使用2D联合截面(IoU)将先验盒与地面真实情况进行匹配[4]。 边界框的高度和高度未用于匹配; 取而代之的是2Dmatch,高度和高程将成为附加的回归目标
3. Implementation Details
在本节中,我们描述了我们的网络参数和优化后的损耗函数。
3.1 Network
1、代替预先训练我们的网络,所有权重均使用[8]中的均匀分布随机初始化。
2、编码器网络具有C = 64维度的输出特征。 除了第一个block 的步幅(汽车为S = 2,行人/骑自行车的人为S = 1)以外,汽车和行人/自行车的主干是相同的步幅。
这两个网络都由三个区块组成,
Block1(S,4,C),
Block2(2S,6,2C),
和Block3(4S,6,4C)。
通过上采样步骤对每个块进行上采样:
Up1(S,S,2C),
Up2(2S,S,2C)
和Up3(4S,S,2C)。
然后,将Up1,Up2和Up3的功能连接在一起,为检测头创建6C维度的特征。
3.2. Loss
我们使用与SEC-OND [28]中介绍的相同的损失函数。 地面真值框和锚点由(x,y,z,w,l,h,θ)定义。 地面真值和锚点之间的本地化回归残差定义为:

学习航向
由于角度定位损失无法区分翻转框,因此我们在离散方向上使用softmax分类损失[28],Ldir,这使网络能够学习航向角。
对象分类
For the object classification loss, we use the focalloss [16]

The total l o s s loss loss is therefore:
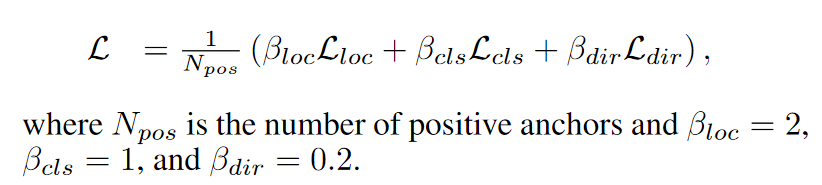
为了优化损失函数,我们使用Adam优化器,其初始学习率为2 * 10−4,每15个epoch衰减学习速率0.8倍,并训练160个epoch。 我们使用2个批次的验证集和4个测试提交量
Dataset
KITTI
这些样本最初分为7481个训练样本和7518个测试样本
对于实验研究experimental studies,我们分为3712个traing 样本和3769个validation 样本[1]
而对于我们的test submission测试提交,我们从验证集中创建了784个样本的最小集合,并对其余的6733个样本进行了训练。
Settings
除非在实验研究中有明确的变化,否则我们将使用xy分辨率:0.16 m,最大柱数(P):12000,每个柱子的最大点数(N):100
我们使用与[31]相同的锚点和匹配策略。每个类锚点都由宽度,长度,高度和z中心描述,并在两个方向上应用:0度和90度。 使用2DIoU按照以下规则将锚点与地面真相进行匹配。 正匹配是带有地面真理框的最高匹配,或者高于正匹配阈值,而负匹配则低于负阈值。 所有其他锚点在损失中都将被忽略。
在推断时,我们应用了轴对齐的非最大抑制(NMS),其重叠阈值为0.5IoU,与rotational NMS相比可提供类似的性能,但速度要快得多
Car.x,y,z范围分别为[(0,70.4),(-40,40),(-3,1)]米。 汽车锚的宽度,长度和高度为(1.6、3.9、1.5)m,z中心为-1 m。 Matching使用正阈值和负阈值0.6和0.45。
行人和骑自行车者。x,y,z范围分别为[(0,48),(-20,20),(-2.5、0.5)]米。 行人锚点的宽度,长度和高度为(0.6、0.8、1.73)米,z中心为-0.6米,而骑自行车的锚点的宽度,长度和高度为(0.6、1.76、1.73)米,z中心为- 0.6米 匹配使用正阈值和负阈值0.5和0.35。
4.3. Data Augmentation数据增强
数据扩充对于在KITTI基准上获得良好性能至关重要[28,30,2]。
首先,按照SECOND [28],我们为所有类别的地面真实3D框以及这些3D框内的关联点云创建一个查找表。 然后,对于每个样本,我们分别为汽车,行人和骑自行车的人随机选择15、0、8个地面真实样本,并将其放入当前点云中。 我们发现这些设置比建议的设置执行得更好[28]。
接下来,对所有地面真值框分别进行增强。每个框都旋转(从[-π/ 20,π/ 20]均匀绘制)并平移(从N(0,0.25)分别绘制的x,y和z)以进一步丰富 训练集。
最后,我们执行了两组全局增强,它们共同应用于点云和所有框。首先,我们沿x轴应用随机镜像翻转[30],然后进行全局旋转和缩放[31,28]。 最后,我们使用从N(0,0.2)得出的x,y,z进行全局平移,以模拟定位噪声
6. Realtime Inference
所有运行时间均在具有Intel i7 CPU和1080ti GPU的台式机上进行测量。
The main inference steps are as follows.
First, the pointcloud is loaded and filtered based on range and visibility inthe images (1.4ms).
Then, the points are organized in pil-lars and decorated (2.7ms).
Next, the PointPillar tensor isuploaded to the GPU (2.9ms), encoded (1.3ms), scatteredto the pseudo-image (0.1ms),
and processed by the back-bone and detection heads (7.7ms).
Finally NMS is appliedon the CPU (0.1ms)
a total runtime of 16.2ms.
关键设计是PointPilar编码。
例如,在1.3ms时,它比VoxelNet编码器(190ms)快2个数量级[31]。最近,SECOND提出了一种更快的稀疏版本的VoxelNet编码器,网络总运行时间为50ms。它们没有提供运行时分析,但是 由于其余部分的架构与我们的架构相似,因此表明编码器的运行速度仍然显着降低; 在其开放源代码实现中,编码器需要48毫秒
瘦身设计 single PointNet
与[31]建议的2个连续PointNet相比,我们在编码器中选择了单个PointNet。 这使我们的运行时在PyTorch runtime中减少了2.5ms。 第一个块的尺寸数量也减少了64位,以匹配编码器输出大小,从而将运行时间减少了4.5毫秒。 最后,通过将上采样特征图层的输出尺寸减少一半至128,我们又节省了3.9ms。 这些变化均不会影响检测性能。
TensorRT
虽然我们所有的实验都是在PyTorch [20]中进行的,但最终的用于编码,主干和检测头的GPU内核是使用NVIDIA TensorRT构建的,后者是用于优化GPU推理的库。 切换到TensorRT可以使PyTorch管道以42.4Hz的运行速度提高45.5%。
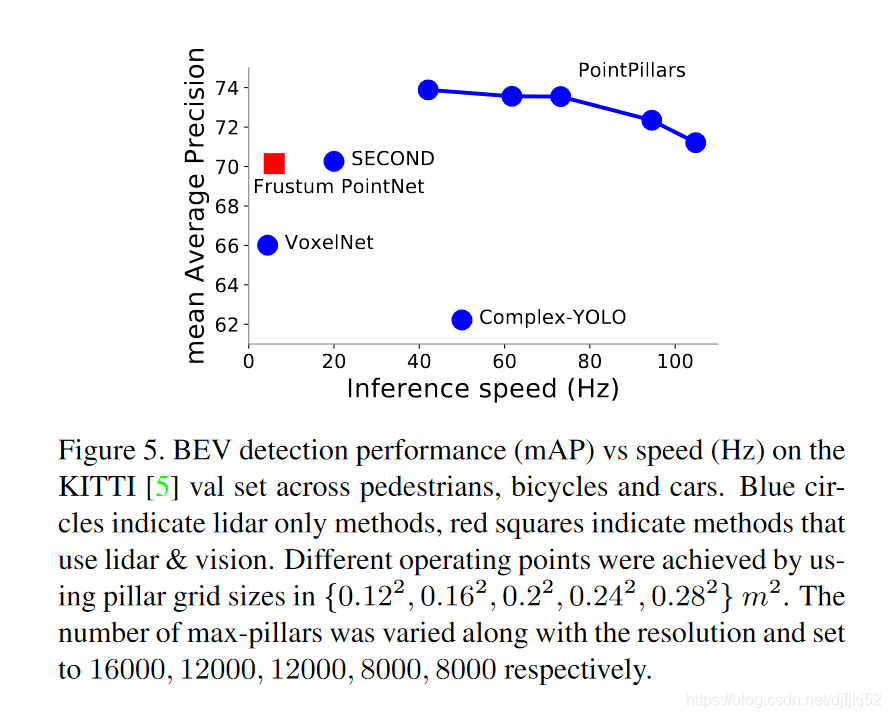
对速度的需求如图5所示,PointPillarscan可以达到105Hz,但精度损失有限。 尽管可以说这种运行时间是多余的,因为激光成像仪通常以20Hz的频率运行,但需要牢记两个关键事项。
首先,由于KITTI地面实况注释的人工制品,
仅使用投影到正面图像中的激光雷达点,该激光雷达点仅占整个点云的10%。
但是,可操作的AV需要查看整个环境并处理完整的点云,从而显着增加了运行时的所有方面。
其次,文献中的时序测量通常在高功率台式机GPU上完成。 但是,可操作的AV可能会使用不具有相同吞吐量的嵌入式GPU或嵌入式计算。
8 消融研究
在本节中,我们提供消融研究,并与最近的文献进行比较来讨论我们的设计选择。
8.1 空间分辨率
可以通过更改空间合并的大小来在速度和准确性之间进行权衡。 较小的支柱可实现更精细的定位,并带来更多功能,而较大的支柱则由于非空支柱较少(加快编码器速度)和较小的伪图像(加快CNN主干线)而速度更快。 为了量化这种影响,我们对网格大小进行了扫描。 从图5可以明显看出,较大的存储箱尺寸可以导致更快的网络。 在0.282时,我们可以达到105Hz,性能与以前的方法相似。 性能的下降主要归因于步行者和骑自行车的人,而汽车的性能在各个中均保持稳定
8.2 Per Box数据增强
VoxelNet [31]和SECOND [28]都建议对每个框进行扩展。 但是,在我们的实验中,最小限度的盒子增强效果更好。 尤其是,行人的检测性能随着更多盒子的增加而显着下降。 我们的假设是,地面实况采样的引入减轻了对每盒扩展的广泛需求
8.3 Point Decorations 增加特征维度
在激光雷达点装饰步骤中,我们执行VoxelNet [31]装饰以及两个附加装饰:xp和yp,它们是从支柱x,y中心偏移的x和y。 这些额外的装饰使最终检测性能提高了0.5 mAP,并提供了更多可重复的实验
8.4 Encoding
为了单独评估提议的PointPillar编码的影响,我们在SECOND的官方代码库中实现了几种编码器[28]。 有关每种编码的详细信息,请参阅原始论文。
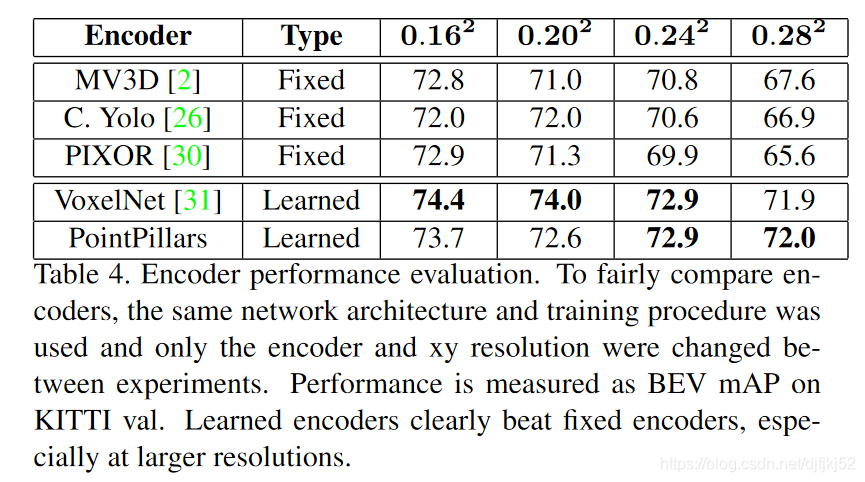
如表4所示,在所有分辨率上,学习特征编码都严格优于固定编码器。 可以预期,因为大多数成功的深度学习架构都经过端到端的培训。 此外,随着每一个柱中较大的点云,固定编码器缺乏表达能力的情况变得更大,箱尺寸越大,差异就越大。 在学习过的编码器中,Voxel-Net比PointPillars略强。 但是,这不是一个公平的比较,因为VoxelNet编码器的速度慢了一个数量级,而参数却增加了几个数量级。 在相似的时间进行比较时,很明显PointPillars提供了更好的工作点(图5)。
表4有一些令人好奇的方面。
首先,尽管在原始论文中指出他们的编码器只能工作在汽车上,
1、但我们发现MV3D [2]和PIXOR [30]编码器可以很好地学习行人和骑自行车的人。
2、其次,我们的实现大大超过了各自发布的结果(1-10mAP)。
尽管由于我们仅使用各自的编码器而不是完整的网络架构,所以这不是比较的合适选择,但性能差异是值得注意的。我们看到了一些潜在的原因。
怀疑VoxelNet和SECOND 提升性能来自:
对于VoxelNet和SECOND,我们怀疑提升性能来自
1、第7.2节中讨论的改进的数据增强超参数。
在固定编码器中,大约有一半的性能提升可以通过引入地面实况数据库采样来解释[28],我们发现该采样率将mAP提高了约3%mAP。
2、剩余的差异可能是由于多个超参数的组合,包括网络设计(层数,层类型,是否使用功能金字塔);锚盒设计(或缺乏锚盒设计[30]);相对于3D和角度的本地化损失;分类损失;优化器选择(SGD与Adam,批处理大小);和更多。
但是,需要进行更仔细的研究以找出每个因果关系。
结论
结束语在本文中,我们介绍了PointPillars,这是一种新颖的深度网络和编码器,可以在li-dar点云上进行端到端训练。 我们证明,在KITTI挑战中,PointPillars通过以更快的速度提供更高的检测性能(在BEV和3D上都为mAP)主导了所有现有方法。 我们的结果表明,PointPillars提供了迄今为止用于激光雷达3D对象检测的最佳架构。

















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









