







官网
https://maartengr.github.io/BERTopic/index.html
技术
BERTopic 支持各种主题建模技术:
文章目录
1 引导式主题建模
引导式主题建模或种子主题建模是一组技术,通过设置模型将收敛到的几个种子主题来引导主题建模方法。这些技术允许用户设置文档中必定包含的预定义数量的主题表示。例如,一家 IT 企业拥有客户使用的软件的票务系统。这些票务通常可能包含有关 IT 企业知道的登录问题的特定错误的信息。
为了对该错误进行建模,我们可以创建一个包含单词 bug、login、password 和 username 的种子主题表示。通过定义这些词,引导式主题建模方法将尝试将至少一个主题收敛到这些词。
引导式 BERTopic 有两个主要步骤:
首先,我们通过连接每个种子主题并将它们传递给文档嵌入器来创建嵌入。这些嵌入将通过余弦相似度与现有文档嵌入进行比较并分配标签。如果文档与种子主题最相似,那么它将获得该主题的标签。如果它与平均文档嵌入最相似,它将获得 -1 标签。然后这些标签通过 UMAP 传递以创建半监督方法,该方法应推动主题创建到种子主题。
其次,我们获取 seed_topic_list 中的所有单词,并为它们分配大于 1 的乘数。这些乘数将用于增加单词在所有主题中的 IDF 值,从而增加种子主题单词出现在主题中的可能性。然而,这也增加了不相关主题具有不相关单词的可能性。在实践中,这不应该成为问题,因为无论乘数如何,IDF 值都可能保持较低水平。乘数现在是一个固定值,但可能会更改为更优雅的值,例如在定义乘数时考虑 IDF 值的分布及其位置。
Example¶
To demonstrate Guided BERTopic, we use the 20 Newsgroups dataset as our example. We have frequently used this dataset in BERTopic examples and we sometimes see a topic generated about health with words such as drug and cancer being important. However, due to the stochastic nature of UMAP, this topic is not always found.
In order to guide BERTopic to that topic, we create a seed topic list that we pass through our model. However, there may be several other topics that we know should be in the documents. Let’s also initialize those:
from bertopic import BERTopic
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))["data"]
seed_topic_list = [["drug", "cancer", "drugs", "doctor"],
["windows", "drive", "dos", "file"],
["space", "launch", "orbit", "lunar"]]
topic_model = BERTopic(seed_topic_list=seed_topic_list)
topics, probs = topic_model.fit_transform(docs)
As you can see above, the seed_topic_list contains a list of topic representations. By defining the above topics BERTopic is more likely to model the defined seeded topics. However, BERTopic is merely nudged towards creating those topics. In practice, if the seeded topics do not exist or might be divided into smaller topics, then they will not be modeled. Thus, seed topics need to be accurate to accurately converge towards them.
2 监督主题建模
虽然主题建模通常是通过以无监督的方式发现主题来完成的,但有时您可能已经拥有一堆要从中建模主题的集群或类。例如,常用的 20 NewsGroups 数据集已经分为 20 个类。同样,您可能已经通过 human-learn、bulk、thisnotthat 或完全不同的包自己创建了一些标签。
我们现在将手动将它们传递给 BERTopic 并尝试了解这些主题与输入文档之间的关系,而不是使用 BERTopic 来发现以前未知的主题。
换句话说,我们将改为执行分类!
我们可以将其视为一种监督主题建模方法。我们将使用分类算法,而不是使用聚类算法。
通常,我们有以下流程:
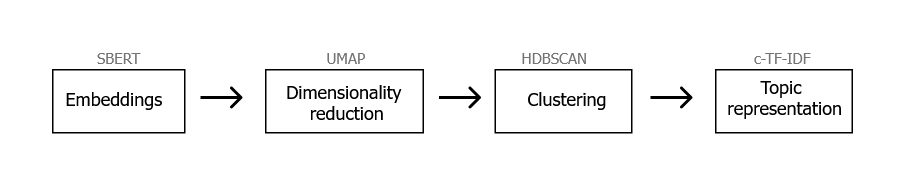
相反,我们现在将跳过降维步骤,用分类模型代替聚类步骤:
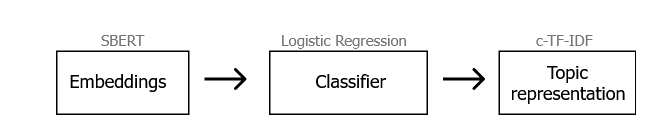
换句话说,我们可以将标签传递给 BERTopic,它不仅会学习如何预测新实例的标签,还会通过在每个标签内的文档集上运行 c-TF-IDF 表示将这些标签转换为主题。这个过程使我们能够对主题本身进行建模,同样也让我们可以选择使用 BERTopic 提供的所有功能。
代码解析 :2.1 加载数据
from sklearn.datasets import fetch_20newsgroups
# 获取带标签的数据
data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
docs = data['data'] # 文档内容
y = data['target'] # 标签
- 使用
fetch_20newsgroups加载 20 NewsGroups 数据集。 remove=('headers', 'footers', 'quotes')用于去除文档中的元信息(如标题、页脚、引用),只保留正文内容。docs是文档列表,y是对应的标签(0 到 19,代表 20 个类别)。
2.2 跳过降维和聚类,使用分类算法
from bertopic import BERTopic
from bertopic.vectorizers import ClassTfidfTransformer
from bertopic.dimensionality import BaseDimensionalityReduction
from sklearn.linear_model import LogisticRegression
# 跳过降维,用分类器替代聚类模型
empty_dimensionality_model = BaseDimensionalityReduction() # 空降维模型
clf = LogisticRegression() # 分类器
ctfidf_model = ClassTfidfTransformer(reduce_frequent_words=True) # c-TF-IDF 模型
# 创建监督学习的 BERTopic 实例
topic_model = BERTopic(
umap_model=empty_dimensionality_model, # 跳过降维
hdbscan_model=clf, # 用分类器替代聚类
ctfidf_model=ctfidf_model # 使用 c-TF-IDF
)
topics, probs = topic_model.fit_transform(docs, y=y) # 训练模型
- 跳过降维:通过传入一个空的降维模型
BaseDimensionalityReduction(),跳过了降维步骤。 - 替代聚类:用逻辑回归分类器
LogisticRegression()替代了原本的聚类算法(如 HDBSCAN)。 - c-TF-IDF:使用
ClassTfidfTransformer从标签中提取主题表示。 - 监督学习:通过传入标签
y,模型直接学习文档与标签之间的关系。
2.3 查看生成的主题
topic_model.get_topic_info()
- 输出每个主题的关键词及其频率。
- 例如:
这些关键词直接反映了输入标签的语义。Topic 0: ['game', 'hockey', 'team', '25'] Topic 1: ['god', 'church', 'jesus', 'christ']
2.4 将主题映射到原始类别
# 将输入标签 `y` 映射到主题
mappings = topic_model.topic_mapper_.get_mappings()
mappings = {value: data["target_names"][key] for key, value in mappings.items()}
# 将原始类别分配给主题
df = topic_model.get_topic_info()
df["Class"] = df.Topic.map(mappings)
df
mappings将生成的主题编号映射到原始类别名称(如rec.sport.hockey)。- 最终输出一个 DataFrame,显示每个主题对应的原始类别。
2.5 预测新文档的主题
topic, _ = topic_model.transform("this is a document about cars")
topic_model.get_topic(topic)
- 使用训练好的模型预测新文档的主题。
- 例如,输入文档
"this is a document about cars",模型会返回与汽车相关的主题及其关键词。
- 关键点总结
- 监督学习:通过传入标签数据,BERTopic 可以直接学习文档与标签之间的关系,而无需无监督的降维和聚类。
- 灵活性:尽管跳过了降维和聚类,BERTopic 仍然保留了其核心功能(如 c-TF-IDF 主题表示、动态主题建模等)。
- 分类器替代聚类:用分类器(如逻辑回归)替代聚类算法,使得模型可以直接预测文档的类别。
- 主题映射:生成的主题可以直接映射到原始类别,便于解释和分析。
这种方法适用于以下场景:
- 已有标注数据,且希望直接利用标签信息进行主题建模。
- 需要对新文档进行分类,同时保留主题建模的可解释性。
- 希望结合监督学习和主题建模的优势,例如在分类任务中提取主题关键词。
通过这种方式,BERTopic 不仅可以用于无监督学习,还可以在监督学习场景中发挥重要作用。
3 半监督
通过已知标签引导主题生成,同时对未知标签的文档进行无监督聚类。
半监督主题建模(部分标签)
在某些情况下,我们可能只有部分文档的标签。这时可以使用半监督主题建模,通过部分标签引导主题生成。
# 定义我们感兴趣的类别(仅计算机相关类别)
labels_to_add = ['comp.graphics', 'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware',
'comp.windows.x']
# 获取这些类别的索引
indices = [category_names.index(label) for label in labels_to_add]
# 构建标签列表:已知类别的文档保留标签,未知类别的文档标记为 -1
y = [label if label in indices else -1 for label in categories]
# 使用部分标签进行半监督主题建模
topic_model = BERTopic(verbose=True).fit(docs, y=y)
-
labels_to_add 是我们感兴趣的类别列表(仅计算机相关类别)。
-
indices 是这些类别在 category_names 中的索引。
-
y 是一个标签列表,已知类别的文档保留其标签,未知类别的文档标记为 -1。
通过传入部分标签 y,BERTopic 会利用已知标签引导主题生成,同时对未知标签的文档进行无监督聚类。
4 手动主题建模(将标签传递给 BERTopic,将这些标签转换为主题)
尽管主题建模通常是通过以无监督的方式发现主题来完成的,但有时您可能已经拥有一堆要从中建模主题的集群或类。例如,常用的 20 NewsGroups 数据集已经分为 20 个类。在这里,我们可能想看看如何将这 20 个类转换为 20 个主题。现在,我们不再使用 BERTopic 来发现以前未知的主题,而是手动将它们传递给 BERTopic,而无需真正学习它们。
我们可以将其视为手动主题建模方法。没有用于检测这些主题的底层算法,因为您之前已经这样做了。这是否仅仅是因为它们已经可用,例如 20 NewsGroups 数据集,或者可能是因为您之前已经使用 human-learn、bulk、thisnotthat 或完全不同的包创建了文档集群。
换句话说,我们可以将标签传递给 BERTopic,它会尝试通过在每个标签内的文档集上运行 c-TF-IDF 表示将这些标签转换为主题。这个过程使我们能够对主题本身进行建模,同样也让我们可以选择使用 BERTopic 提供的一切。
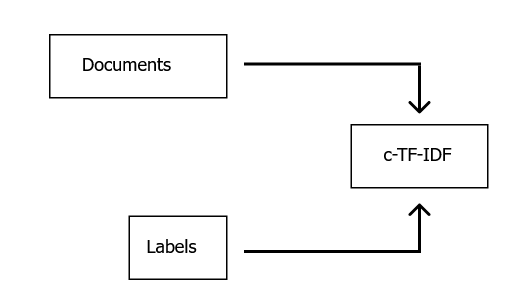
from bertopic import BERTopic
from bertopic.backend import BaseEmbedder
from bertopic.cluster import BaseCluster
from bertopic.vectorizers import ClassTfidfTransformer
from bertopic.dimensionality import BaseDimensionalityReduction
# Prepare our empty sub-models and reduce frequent words while we are at it.
empty_embedding_model = BaseEmbedder()
empty_dimensionality_model = BaseDimensionalityReduction()
empty_cluster_model = BaseCluster()
ctfidf_model = ClassTfidfTransformer(reduce_frequent_words=True)
# Fit BERTopic without actually performing any clustering
topic_model= BERTopic(
embedding_model=empty_embedding_model,
umap_model=empty_dimensionality_model,
hdbscan_model=empty_cluster_model,
ctfidf_model=ctfidf_model
)
topics, probs = topic_model.fit_transform(docs, y=y)
Let’s take a look at a few topics that we get out of training this way by running topic_model.get_topic_info():
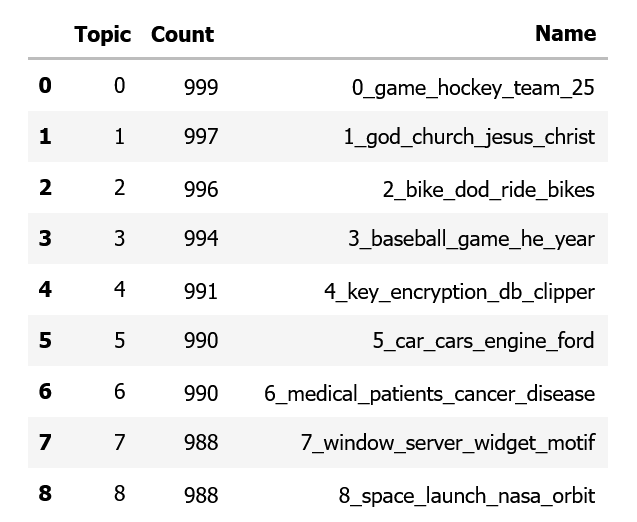
We can see several interesting topics appearing here. They seem to relate to the 20 classes we had as input. Now, let’s map those topics to our original classes to view their relationship:
# Map input `y` to topics
mappings = topic_model.topic_mapper_.get_mappings()
mappings = {value: data["target_names"][key] for key, value in mappings.items()}
# Assign original classes to our topics
df = topic_model.get_topic_info()
df["Class"] = df.Topic.map(mappings)
df
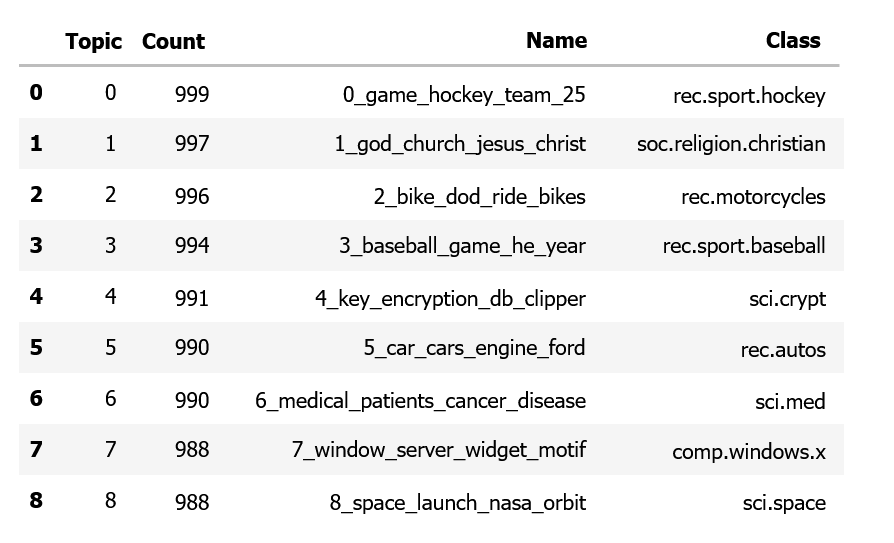
我们可以看到,c-TF-IDF 表示很好地提取了能够很好地表示我们输入类别的单词。这一切都是在没有实际嵌入和聚类数据的情况下完成的。
因此,整个“训练”过程仅需几秒钟。此外,我们仍然可以执行 BERTopic 特定的功能,如动态主题建模、每个类别的主题、分层主题建模、建模主题分布等。
5 主题分布
BERTopic 将主题建模作为集群任务,并尝试对语义相似的文档进行聚类以提取共同主题。使用这种方法的一个缺点是每个文档都被分配到一个集群,因此也是一个主题。实际上,文档可能包含混合主题。这可以通过将文档拆分成句子并将其提供给 BERTopic 来解决。
另一种选择是使用可以执行软聚类的集群模型,如 HDBSCAN。由于 BERTopic 专注于模块化,即使我们使用硬聚类模型(如 k-Means),我们可能仍希望对这种混合主题进行建模,而无需拆分我们的文档。这就是 .approximate_distribution 的作用所在!
Example¶
To calculate our topic distributions, we first need to fit a basic topic model:
from bertopic import BERTopic
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
topic_model = BERTopic().fit(docs)
After doing so, we can approximate the topic distributions for your documents:
topic_distr, _ = topic_model.approximate_distribution(docs)
The resulting topic_distr is a n x m matrix where n are the topics and m the documents. We can then visualize the distribution of topics in a document:
topic_model.visualize_distribution(topic_distr[1])
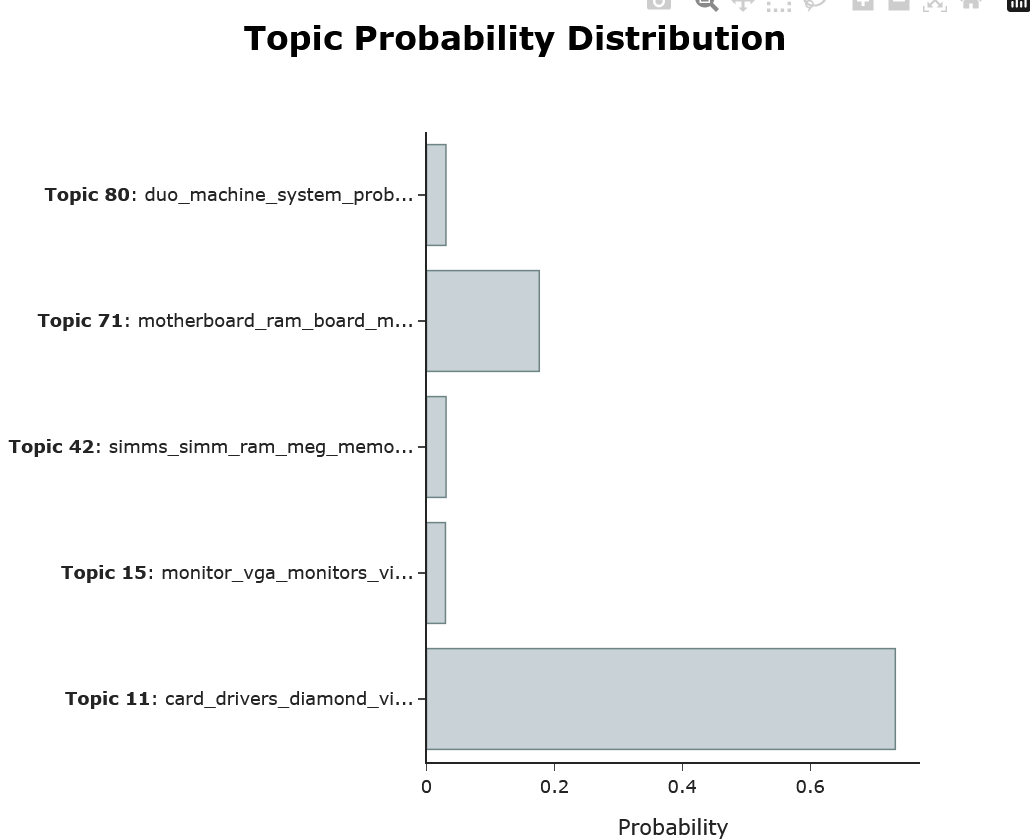
6 分层主题建模
调整主题模型时,生成的主题数量对主题表示的质量有很大影响。某些主题可以合并,了解其影响将有助于您了解哪些主题应该合并,哪些不应该合并。
这就是分层主题建模的用武之地。它尝试对您创建的主题的可能层次性质进行建模,以了解哪些主题彼此相似。此外,您将对数据中可能存在的子主题有更深入的了解。
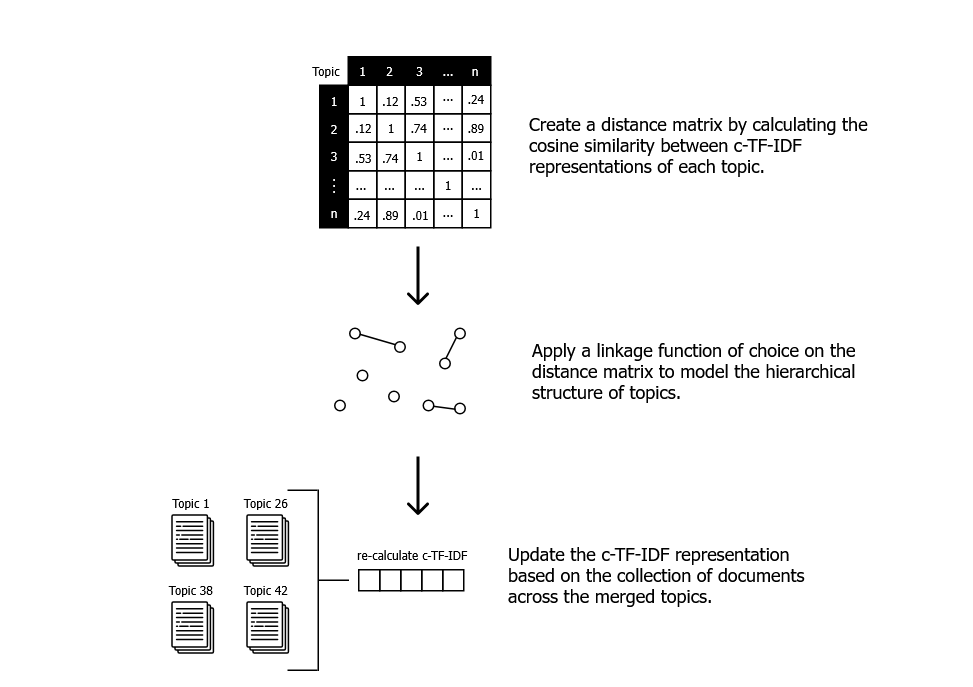
在 BERTopic 中,我们可以利用我们的主题词矩阵(c-TF-IDF 矩阵)来近似这个潜在的层次结构。这个矩阵包含有关每个主题中每个单词的重要性的信息,并且可以很好地以数字形式表示我们的主题。两个 c-TF-IDF 表示之间的距离越小,我们假设它们越相似。实际上,合并主题的过程是通过 scipy 的层次聚类功能完成的(参见此处)。它允许使用多种链接方法,通过这些方法我们可以近似我们的主题层次结构。默认情况下,我们使用 ward,但还有许多其他方法可用。
每当我们合并两个主题时,我们都可以通过将它们的词袋表示相加来计算这两个合并的 c-TF-IDF 表示。我们假设两组主题合并,所有其他主题保持不变,无论它们在层次结构中的位置如何。这有助于我们隔离合并主题集的潜在影响。因此,我们可以看到树中每个级别的主题表示。
Example¶
To demonstrate hierarchical topic modeling with BERTopic, we use the 20 Newsgroups dataset to see how the topics that we uncover are represented in the 20 categories of documents.
First, we train a basic BERTopic model:
from bertopic import BERTopic
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))["data"]
topic_model = BERTopic(verbose=True)
topics, probs = topic_model.fit_transform(docs)
Next, we can use our fitted BERTopic model to extract possible hierarchies from our c-TF-IDF matrix:
hierarchical_topics = topic_model.hierarchical_topics(docs)
生成的 hierarchical_topics 是一个数据框,其中描述了合并的主题。例如,如果您要合并两个主题,那么新主题的主题表示是hierarchical_topics 的数据。
链接函数¶
在创建主题的潜在层次结构时,我们默认使用 Scipy 的 ward 链接函数来生成层次结构。但是,您可能希望针对您的用例使用不同的链接函数,例如单个、完整、平均、质心或中位数。在 BERTopic 中,您可以自己定义链接函数,包括您想要使用的距离函数:
from scipy.cluster import hierarchy as sch
from bertopic import BERTopic
topic_model = BERTopic()
topics, probs = topic_model.fit_transform(docs)
# Hierarchical topics
linkage_function = lambda x: sch.linkage(x, 'single', optimal_ordering=True)
hierarchical_topics = topic_model.hierarchical_topics(docs, linkage_function=linkage_function)
Visualizations¶
To visualize these results, we can start by running a familiar function, namely topic_model.visualize_hierarchy:
topic_model.visualize_hierarchy(hierarchical_topics=hierarchical_topics)
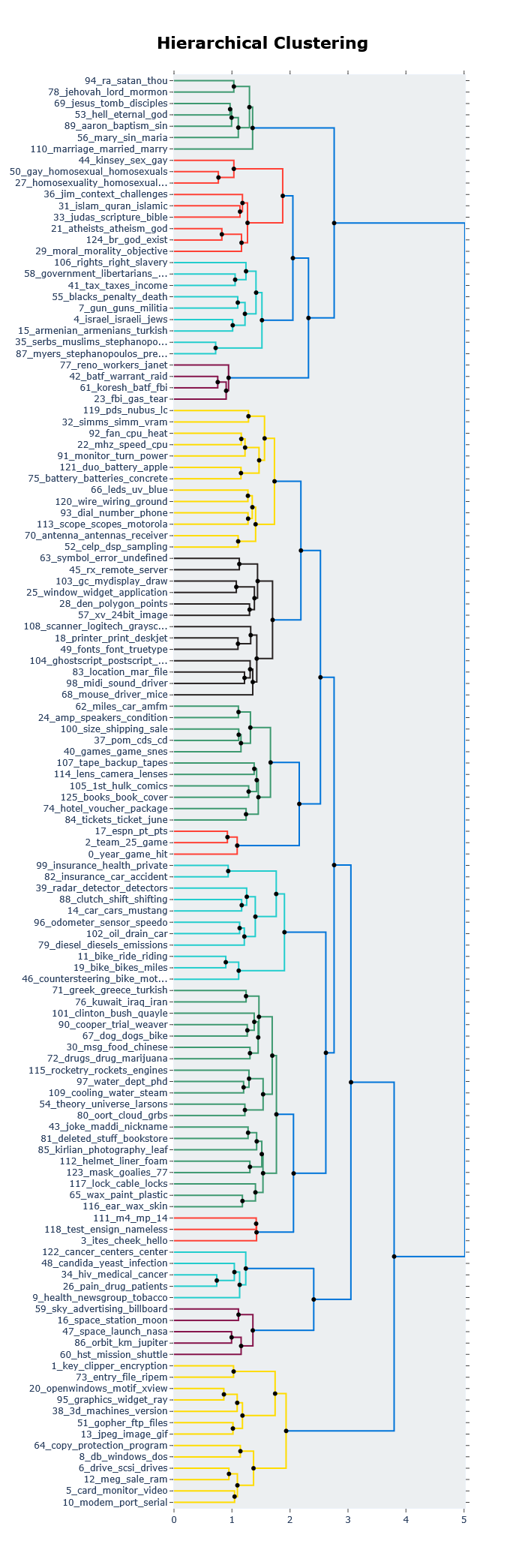
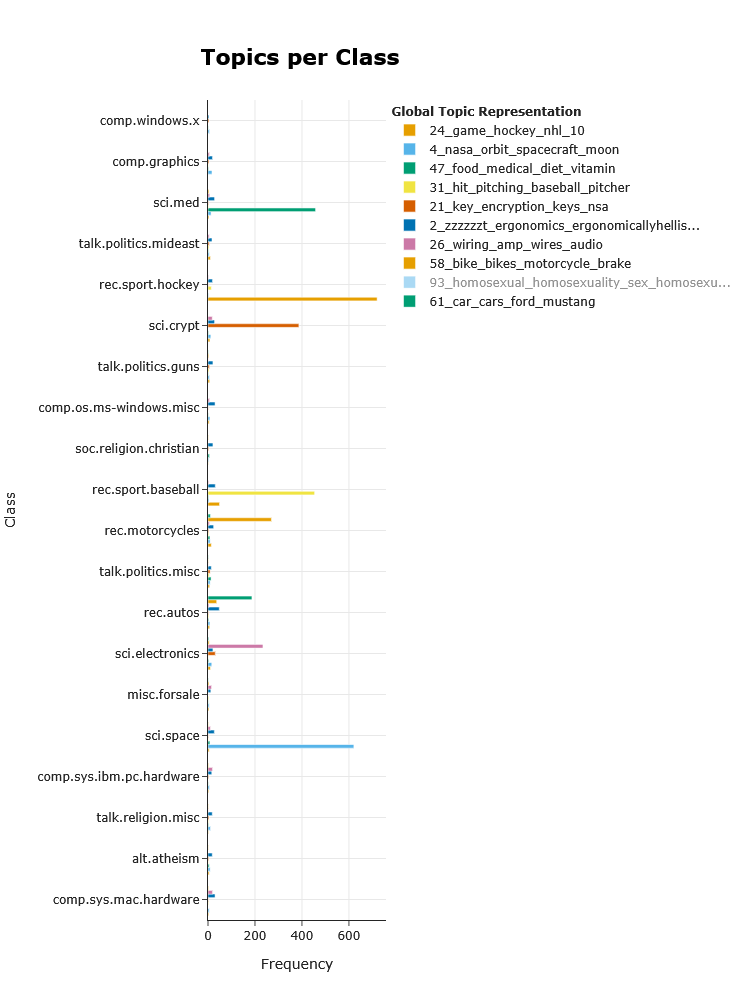
7 每个类别的主题
在某些情况下,您可能对某些主题在某些类别中的表示方式感兴趣。也许您想了解特定用户组如何谈论某些主题。
我们不必按类别运行主题模型,而是只需创建一个主题模型,然后为每个主题提取其按类别的表示。这样您就可以看到某些主题(计算所有文档)在某些子组中的表示方式。
First, let’s prepare the data:
from bertopic import BERTopic
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
docs = data["data"]
targets = data["target"]
target_names = data["target_names"]
classes = [data["target_names"][i] for i in data["target"]]
Next, we want to extract the topics across all documents without taking the categories into account:
topic_model = BERTopic(verbose=True)
topics, probs = topic_model.fit_transform(docs)
Now that we have created our global topic model, let us calculate the topic representations across each category:
topics_per_class = topic_model.topics_per_class(docs, classes=classes)
The classes variable contains the class for each document. Then, we simply visualize these topics per class:
topic_model.visualize_topics_per_class(topics_per_class, top_n_topics=10)
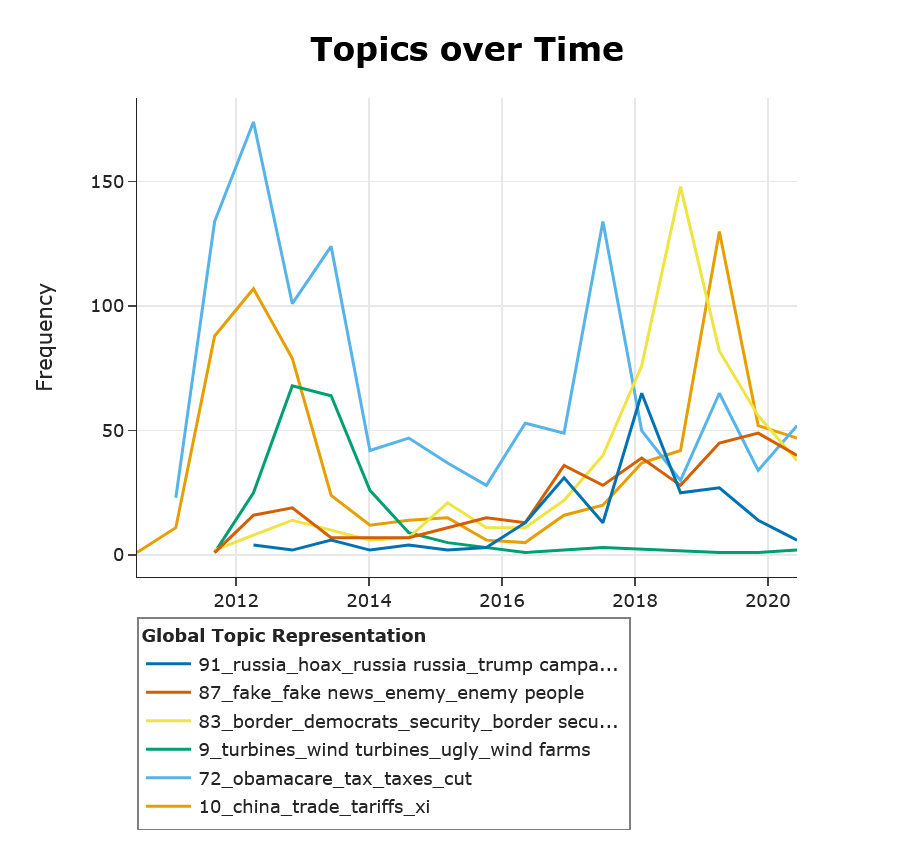
8 动态主题建模 (DTM)
动态主题建模 (DTM) 是一组旨在分析主题随时间演变的技术。这些方法可让您了解主题在不同时期的表示方式。例如,1995 年人们谈论环境意识的方式可能与 2015 年不同。虽然主题本身保持不变,即环境意识,但该主题的确切表示可能有所不同。
BERTopic 通过计算每个时间步长的主题表示来实现 DTM,而无需多次运行整个模型。为此,我们首先需要拟合 BERTopic,就好像数据中没有时间方面一样。因此,将创建一个通用主题模型。我们使用全局表示作为最有可能在不同时间步长中找到的主要主题。对于每个主题和时间步长,我们计算 c-TF-IDF 表示。这将在每个时间步长产生特定的主题表示,而无需从嵌入中创建集群,因为它们已经创建好了。
接下来,进一步微调这些特定主题表示的主要方法有两种,即全局和进化。
可以通过将其 c-TF-IDF 表示与全局表示的 c-TF-IDF 表示平均,对时间步长 t 处的主题表示进行全局微调。这允许每个主题表示略微向全局表示移动,同时仍保留其一些特定词语。
可以通过将其 c-TF-IDF 表示与时间步长 t-1 处的 c-TF-IDF 表示平均,对时间步长 t 处的主题表示进行进化微调。对每个主题表示都执行此操作,允许表示随时间演变。
两种微调方法都默认设置为 True,并允许创建有趣的表示。
从这些主题中,我们将为每个主题生成每个时间戳的主题表示。我们只需调用topics_over_time并传递推文、相应的时间戳和相关主题即可实现此目的:
示例¶
为了在 BERTopic 中演示 DTM,我们首先需要准备数据。DTM 有用的一个很好的例子是 Twitter 数据上的主题建模。我们可以分析某些人在 Twitter 上发布的这些年里是如何谈论某些话题的。由于他的推文具有争议性,我们将使用唐纳德·特朗普的所有推文。
首先,我们需要加载数据并进行一些非常基本的清理。例如,对于这个用例,我对他的转发不感兴趣:
import re
import pandas as pd
# Prepare data
trump = pd.read_csv('https://drive.google.com/uc?export=download&id=1xRKHaP-QwACMydlDnyFPEaFdtskJuBa6')
trump.text = trump.apply(lambda row: re.sub(r"http\S+", "", row.text).lower(), 1)
trump.text = trump.apply(lambda row: " ".join(filter(lambda x:x[0]!="@", row.text.split())), 1)
trump.text = trump.apply(lambda row: " ".join(re.sub("[^a-zA-Z]+", " ", row.text).split()), 1)
trump = trump.loc[(trump.isRetweet == "f") & (trump.text != ""), :]
timestamps = trump.date.to_list()
tweets = trump.text.to_list()
然后,我们需要通过简单地创建和训练 BERTopic 模型来提取全局主题表示:
from bertopic import BERTopic
topic_model = BERTopic(verbose=True)
topics, probs = topic_model.fit_transform(tweets)
从这些主题中,我们将为每个主题生成每个时间戳的主题表示。我们只需调用topics_over_time并传递推文、相应的时间戳和相关主题即可完成此操作:
topics_over_time = topic_model.topics_over_time(tweets, timestamps, nr_bins=20)
就是这样!除了您始终需要的 BERTopic 之外,您现在只需添加时间戳即可快速计算随时间变化的主题。
参数¶
下面将讨论一些值得关注的参数。
Tuning¶
global_tuning 和 evolutionary_tuning 都默认设置为 True,但可以轻松更改。也许您不希望表示受到全局表示的影响,而只是查看它们如何随时间演变:
topics_over_time = topic_model.topics_over_time(tweets, timestamps,
global_tuning=True, evolution_tuning=True, nr_bins=20)
Bin
如果您有超过 100 个唯一时间戳,那么将为每个时间戳创建主题表示,这可能会对主题表示产生负面影响。建议将唯一时间戳的数量保持在 50 以下。为此,您只需设置在计算主题表示时创建的箱体数量即可。时间戳将被取出并放入大小相等的箱体中:
topics_over_time = topic_model.topics_over_time(tweets, timestamps, nr_bins=20)
日期时间格式¶
如果您传递的是字符串(日期)而不是整数,那么 BERTopic 将尝试自动检测字符串具有哪种日期时间格式。不幸的是,如果它们的格式出乎意料,这种方法并不总是有效。我们可以使用 datetime_format 传递时间戳的格式:
topics_over_time = topic_model.topics_over_time(tweets, timestamps, datetime_format="%b%M", nr_bins=20)
可视化¶
对我来说,当你有一个好方法来可视化主题随时间的变化时,DTM 就会变得真正有趣。一个好方法是利用 Plotly 的交互功能。Plotly 允许我们显示主题随时间的变化频率,同时提供将鼠标悬停在点上的选项以显示特定时间的主题表示。只需使用新创建的主题随时间的变化调用 visualize_topics_over_time:
topic_model.visualize_topics_over_time(topics_over_time, top_n_topics=20)
我使用 top_n_topics 仅显示前 20 个最常见的主题。如果我要可视化所有主题(可以通过将 top_n_topics 留空来实现),则有可能数百行会填满整个图。
您还可以使用主题来显示特定主题:
topic_model.visualize_topics_over_time(topics_over_time, topics=[9, 10, 72, 83, 87, 91])
9在线主题建模
在线主题建模(有时称为“增量主题建模”)是一种从小批量实例中增量学习的能力。本质上,它是一种使用之前未训练过的数据更新主题模型的方法。在 Scikit-Learn 中,这种技术通常通过 .partial_fit 函数进行建模,该函数也用于 BERTopic。
在 BERTopic 中,使用此技术有三个主要目标。
减少训练主题模型所需的内存。
随着新数据的出现不断更新主题模型。
随着新数据的出现不断寻找新主题。
在 BERTopic 中,在线主题建模可能有点棘手,因为涉及几个需要提供在线学习的步骤。总结一下,BERTopic 包含以下 6 个步骤:
提取嵌入
降低维度
聚类减少的嵌入
标记主题
提取主题词
(可选)微调主题词
通常,在步骤 1 中,我们使用预先训练的语言模型,这些模型不需要持续更新。这意味着我们可以使用 Sentence-Transformers 之类的嵌入模型来提取嵌入,并且仍然在在线环境中使用它。同样,步骤 5 和 6 不一定需要在线变体,因为它们是在步骤 4(标记化)的基础上构建的。如果标记化本身是增量的,那么步骤 5 和 6 也是如此。
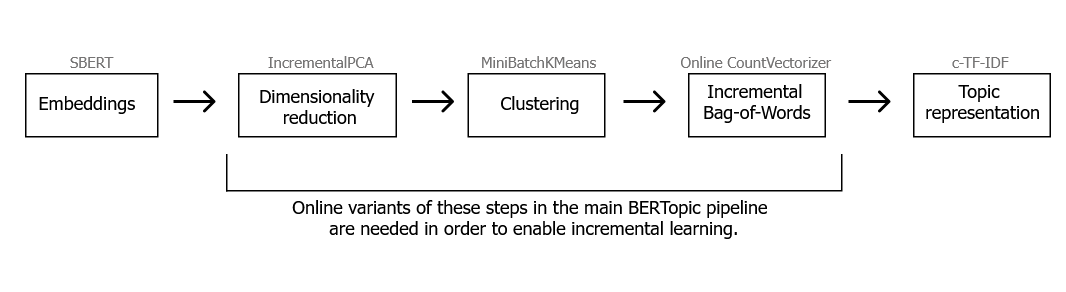
这意味着我们需要步骤 2 到步骤 4 的在线变体。步骤 2 和步骤 3(降维和聚类)可以通过使用 Scikit-Learn 的 .partial_fit 函数进行建模。换句话说,它支持任何可以使用 .partial_fit 进行训练的算法,因为这些算法可以逐步训练。例如,可以使用 Scikit-Learn 的 IncrementalPCA 实现增量降维,使用 MiniBatchKMeans 实现增量聚类。
最后,我们需要为步骤 5(标记化)开发在线变体。在此步骤中,通过 CountVectorizer 创建词袋表示。但是,随着新数据的进入,其词汇表将需要更新。为此,创建了 bertopic.vectorizers.OnlineCountVectorizer,它不仅可以更新词汇表之外的单词,还可以实现衰减和清理功能,以防止稀疏词袋矩阵变得太大。最值得注意的是,衰减参数是一个介于 0 和 1 之间的值,用于衡量前一个词袋矩阵应减少到的频率百分比。例如,值为 .1 将在每次迭代中将词袋矩阵中的频率降低 10%。这将确保最近的数据比之前的迭代具有更大的权重。同样,如果某些词的频率低于设定值,delete_min_df 将从其词汇表中删除它们。这与衰减参数联系在一起,因为如果不使用某些词,它们会随着时间的推移而衰减。有关 OnlineCountVectorizer 的更多信息,请参阅矢量化器文档。
10 多模态主题建模
文档或文本通常伴随着图像,反之亦然。例如,社交媒体图像带有标题,产品带有描述。主题建模传统上侧重于从文本表示创建主题。然而,随着更多多模态表示的创建,对多模态主题的需求也随之增加。
BERTopic 可以在 .fit 和 .fit_transform 阶段以多种方式执行多模态主题建模。
11 6 多种表示
在 BERTopic 的开发过程中,可以创建多种不同类型的表示,从关键字和短语到摘要和自定义标签。有多种技术可供选择来表示主题。因此,有许多有趣且富有创意的方式来总结主题。主题不仅仅是一种表示。
因此,引入了多方面主题建模在 .fit 或 .fit_transform 阶段,您现在可以获得单个主题的多种表示。在实践中,它通过生成和存储各种不同的主题表示来工作(见下图)。
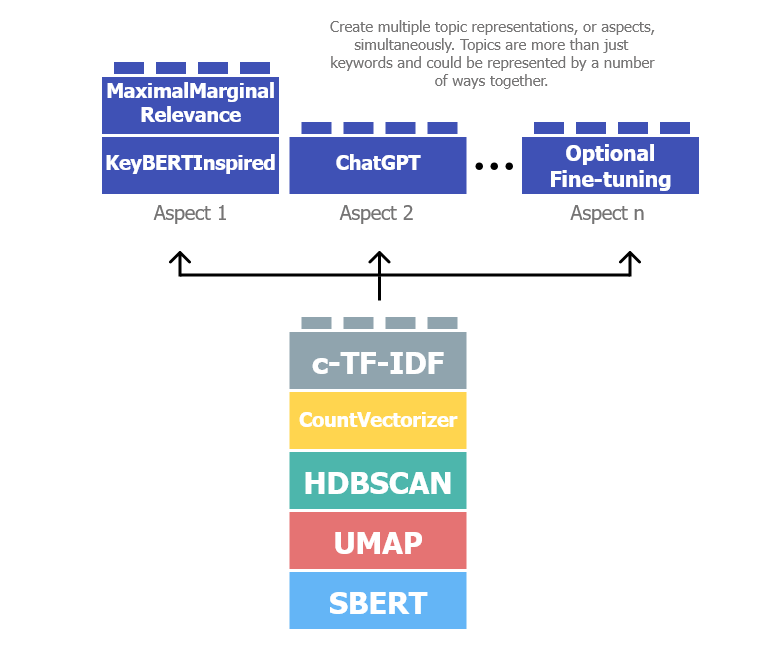
这种方法相当简单。我们可能希望使用 PartOfSpeech 表示模型来表示我们的主题,但我们也可能想尝试 KeyBERTInspired 并比较这些表示模型。我们可以这样做:
from bertopic.representation import KeyBERTInspired
from bertopic.representation import PartOfSpeech
from bertopic.representation import MaximalMarginalRelevance
from sklearn.datasets import fetch_20newsgroups
# Documents to train on
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
# The main representation of a topic
main_representation = KeyBERTInspired()
# Additional ways of representing a topic
aspect_model1 = PartOfSpeech("en_core_web_sm")
aspect_model2 = [KeyBERTInspired(top_n_words=30), MaximalMarginalRelevance(diversity=.5)]
# Add all models together to be run in a single `fit`
representation_model = {
"Main": main_representation,
"Aspect1": aspect_model1,
"Aspect2": aspect_model2
}
topic_model = BERTopic(representation_model=representation_model).fit(docs)
如上所示,要执行多方面主题建模,我们确保representation_model是一个字典,其中定义了每个表示模型管道。大多数可视化选项中使用的主要管道使用“Main”键定义。所有其他方面都可以按照您的需要定义。在上面的例子中,我们感兴趣的另外两个方面定义为“Aspect1”和“Aspect2”。
在我们拟合模型之后,我们可以使用topic_model.get_topic_info()访问所有表示:
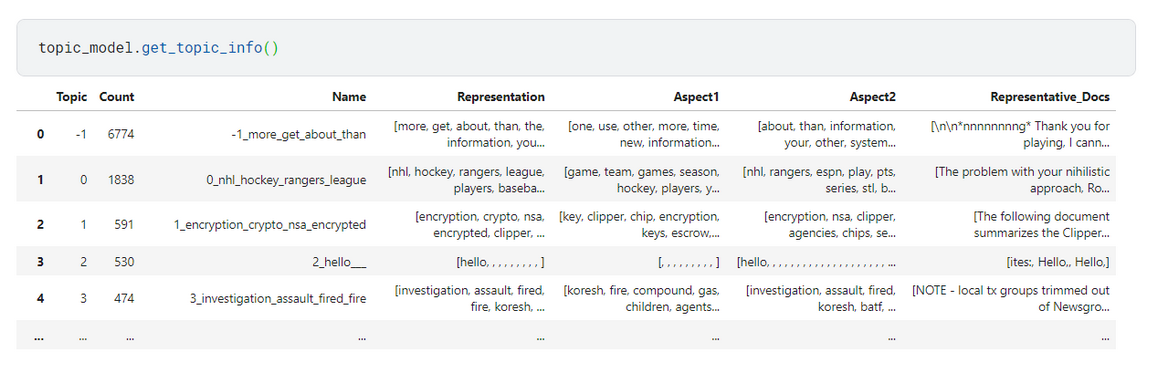
12 LLM 和生成式 AI
正如我们在上一节中看到的,您从 BERTopic 获得的主题可以使用多种方法进行微调。在这里,我们将重点介绍文本生成大型语言模型,例如 ChatGPT、GPT-4 和开源解决方案。
使用这些技术,我们可以进一步微调主题以生成标签、摘要、主题诗歌等。为此,我们首先使用 BERTopic 的 c-TF-IDF 计算生成一组最能描述主题的关键字和文档。然后,将这些候选关键字和文档传递给文本生成模型,并要求生成最适合主题的输出。
这样做的一大好处是,我们可以仅用几个文档来描述一个主题,因此我们不需要将所有文档传递给文本生成模型。这不仅可以显着加快主题标签的生成速度,而且在使用外部 API(例如 Cohere 或 OpenAI)时也不需要大量积分。
13 零样本主题建模
零样本主题建模是一种技术,可让您在大量预定义的文档中查找主题。面对许多文档时,您通常会知道哪些主题肯定会在其中。这是否只是因为您了解数据,还是因为有领域专家参与定义这些主题。
此方法不仅允许您找到那些特定主题,还可以为不符合预定义主题的文档创建新主题。这允许广泛的灵活性,因为有三种场景可供探索:
首先,检测到零样本主题和聚类主题。这意味着一些文档适合预定义主题,而其他文档则不适合。对于后者,发现了新主题。
其次,只检测到零样本主题。在这里,我们不需要寻找其他主题,因为所有原始文档都已分配给预定义主题之一。
第三,未检测到零样本主题。这意味着没有任何文档适合预定义主题,并且将运行常规 BERTopic。
此方法的工作原理如下。首先,我们为预定义主题创建多个标签,并使用任何嵌入模型嵌入它们。然后,我们使用余弦相似度将文档的嵌入与预定义标签进行比较。如果它们通过了用户定义的阈值,则将零样本主题分配给文档。如果没有,那么该文档以及其他文档将遵循常规 BERTopic 管道并尝试查找与零样本主题不匹配的集群。
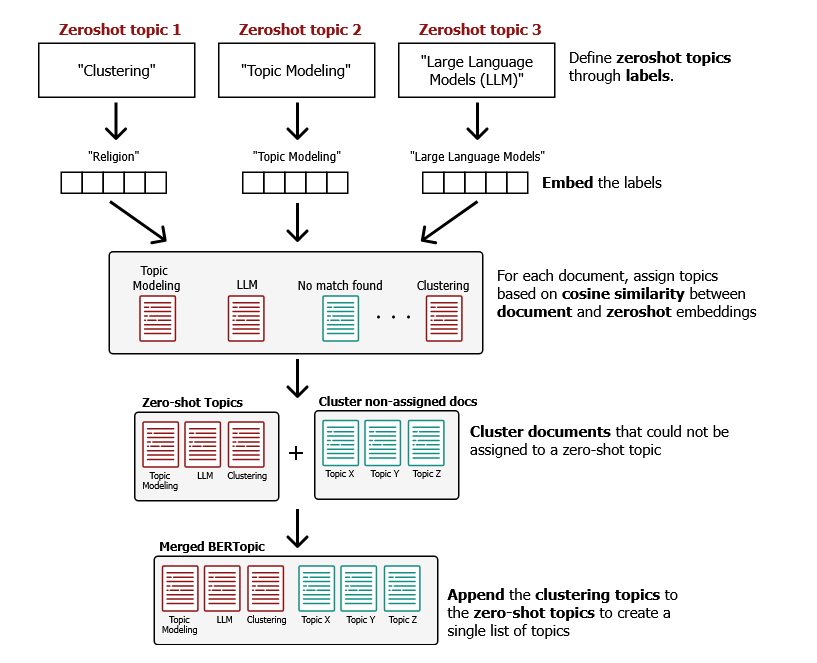
零样本 BERTopic 需要两个参数:* zeroshot_topic_list - 要分配文档的主题名称。确保这尽可能具有描述性有助于改进分配,因为它们基于嵌入之间的余弦相似性。* zeroshot_min_similarity - 将文档与文档匹配所需的最小余弦相似性。它是 0 到 1 之间的值。
from datasets import load_dataset
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
# We select a subsample of 5000 abstracts from ArXiv
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
docs = dataset["abstract"][:5_000]
# We define a number of topics that we know are in the documents
zeroshot_topic_list = ["Clustering", "Topic Modeling", "Large Language Models"]
# We fit our model using the zero-shot topics
# and we define a minimum similarity. For each document,
# if the similarity does not exceed that value, it will be used
# for clustering instead.
topic_model = BERTopic(
embedding_model="thenlper/gte-small",
min_topic_size=15,
zeroshot_topic_list=zeroshot_topic_list,
zeroshot_min_similarity=.85,
representation_model=KeyBERTInspired()
)
topics, _ = topic_model.fit_transform(docs)
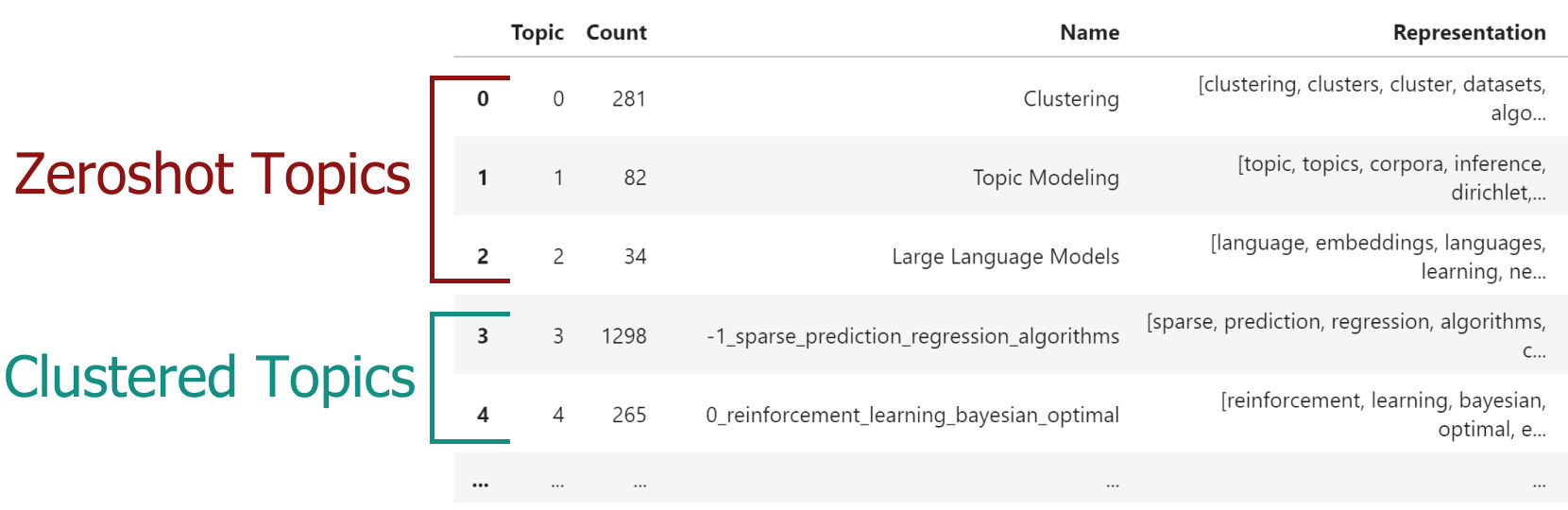
When we run topic_model.get_topic_info() you will see something like this:
14 合并多个拟合模型
在您使用数据训练了新的 BERTopic 模型后,新数据可能仍会传入。虽然您可以使用在线 BERTopic,但您可能更喜欢使用默认的 HDBSCAN 和 UMAP 模型,因为它们不支持开箱即用的增量学习。
相反,您可以在传入数据上训练新的 BERTopic,并将其与您的基础模型合并,以检测新主题是否出现在未见的文档中。这是一种很好的检测新模型是否包含以前未在基础主题模型中找到的信息的方法。
同样,您可能希望使用不同的设置集训练多个 BERTopic 模型,即使它们可能都使用相同的底层嵌入模型。合并这些模型还可以实现一个可以在整个用例中使用的模型。
最后,这种方法还允许一定程度的联合学习,其中每个节点训练一个聚合在中央服务器中的主题模型。
首先,我们在数据的不同部分训练三个独立的模型:
from umap import UMAP
from bertopic import BERTopic
from datasets import load_dataset
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
# Extract abstracts to train on and corresponding titles
abstracts_1 = dataset["abstract"][:5_000]
abstracts_2 = dataset["abstract"][5_000:10_000]
abstracts_3 = dataset["abstract"][10_000:15_000]
# Create topic models
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
topic_model_1 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_1)
topic_model_2 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_2)
topic_model_3 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_3)
然后,我们可以使用.merge_models 将这三个模型合并为一个:
# Combine all models into one
merged_model = BERTopic.merge_models([topic_model_1, topic_model_2, topic_model_3])
When we inspect the first model, we can see it has 52 topics:
>>> len(topic_model_1.get_topic_info())
52
Now, we inspect the merged model, we can see it has 57 topics:
>>> len(merged_model.get_topic_info())
57
It seems that by merging these three models, there were 6 undiscovered topics that we could add to the very first model.
请注意,模型是按顺序合并的。这意味着比较从 topic_model_1 开始,并且来自 topic_model_2 和 topic_model_3 的每个新主题都将添加到 topic_model_1。
15种子词
执行主题建模时,您经常会遇到您在一定程度上熟悉的数据或使用非常特定语言的数据。在这些情况下,主题建模技术可能难以捕捉和表示特定领域缩写、俚语、缩写形式、首字母缩略词等的语义性质。例如,“TNM”分类是一种识别大多数癌症阶段的方法。单词“TNM”是一个缩写,可能无法在通用嵌入模型中正确捕获。
为了确保某些特定领域的单词权重更高,并且在主题表示中更常用,您可以在 bertopic.vectorizer.ClassTfidfTransformer 中设置任意数量的 seed_words。ClassTfidfTransformer 是 BERTopic 的基本表示,本质上将每个主题表示为一个词袋。因此,我们可以选择增加某些词的重要性,例如“TNM”。
为此,让我们看一个例子。我们有一篇论文摘要数据集,想要进行一些主题建模。由于我们可能熟悉这些数据,所以我们知道某些词应该很重要。假设我们对强化学习有深入的了解,并且知道“代理”和“机器人”等词在这样的主题中应该很重要。使用 ClassTfidfTransformer,我们可以定义这些 seed_words,也可以选择它们的值乘以多少。
from umap import UMAP
from datasets import load_dataset
from bertopic import BERTopic
from bertopic.vectorizers import ClassTfidfTransformer
# Let's take a subset of ArXiv abstracts as the training data
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
abstracts = dataset["abstract"][:5_000]
# For illustration purposes, we make sure the output is fixed when running this code multiple times
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
# We can choose any number of seed words for which we want their representation
# to be strengthen. We increase the importance of these words as we want them to be more
# likely to end up in the topic representations.
ctfidf_model = ClassTfidfTransformer(
seed_words=["agent", "robot", "behavior", "policies", "environment"],
seed_multiplier=2
)
# We run the topic model with the seeded words
topic_model = BERTopic(
umap_model=umap_model,
min_topic_size=15,
ctfidf_model=ctfidf_model,
).fit(abstracts)
Then, when we run topic_model.get_topic(0), we get the following output:
[('policy', 0.023413102511982354),
('reinforcement', 0.021796126795834238),
('agent', 0.021131601305431902),
('policies', 0.01888385271486409),
('environment', 0.017819874593917057),
('learning', 0.015321710504308708),
('robot', 0.013881115279230468),
('control', 0.013297705894983875),
('the', 0.013247933839985382),
('to', 0.013058208312484141)]
我们可以看到,输出包含我们分配的一些种子词。但是,如果发现某个词在主题中并不重要,我们仍然可以将其重要性乘以 1,但其重要性将保持相对较低。这是一个很棒的功能,因为它可以让你提高其重要性,同时降低使单词在实际上不应该重要的主题中变得重要的风险。
这种方法的一个好处是,它通常会影响所有其他表示方法,例如 KeyBERTInspired 和 OpenAI。原因是每个表示模型都使用 ClassTfidfTransformer 生成的单词作为候选词来进一步优化。在许多情况下,像“TNM”这样的词可能不会出现在候选词中。通过增加它们的重要性,它们更有可能成为表示模型中的候选词。
使用此方法的另一个好处是它人为地提高了主题的可解释性。当然,有些词可能比其他词更重要,但对领域专家来说可能没有任何意义。对于他们来说,某些词,例如“TNM”,具有很强的描述性,很难用任何方法(嵌入模型、大型语言模型等)捕捉到。
此外,这些种子词可以与领域专家一起定义,因为他们可以决定哪些类型的词通常很重要,可能需要算法开发人员的推动。



















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











