







简洁不意味着简单,同样琐碎也不意味着复杂。比如hadoop完全分布式集群的搭建,并不复杂,只是琐碎。
概念介绍
新近所学皆数学,对基本概念(放在一些特定技术的语言环境里就是术语)、基本原理比较敏感。深以为然一点,在大的原理或者框架之下,所有那些记忆起来特别啰嗦的知识点,都是其中的推论或者特例。熟悉基本概念、基本原理,便打开了永久的记忆之门。
三种安装模式
如果 hadoop 对应的 java进程运行在一个物理机器中,我们将之称为伪分布,如果它运行在多台物理机器中,就称其为分布式。
本地模式
又名非分布式,也是hadoop的默认安装模式,无需进行其他配置即可运行。非分布式是单Java进程(jps命令查看的话,只有一个java进程),便于调试。(jps,Java virtual machine Process Status,查看当前运行的java进程数)伪分布式
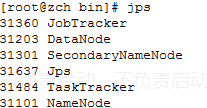
hadoop可以在单节点(单主机)上以伪分布式的方式运行,hadoop进程以分离的java进程来运行,该唯一的节点(主机)既作为namenode也作为datanode。(jps命令查看的话,会有数个java进程,如下图显示)
完全分布式
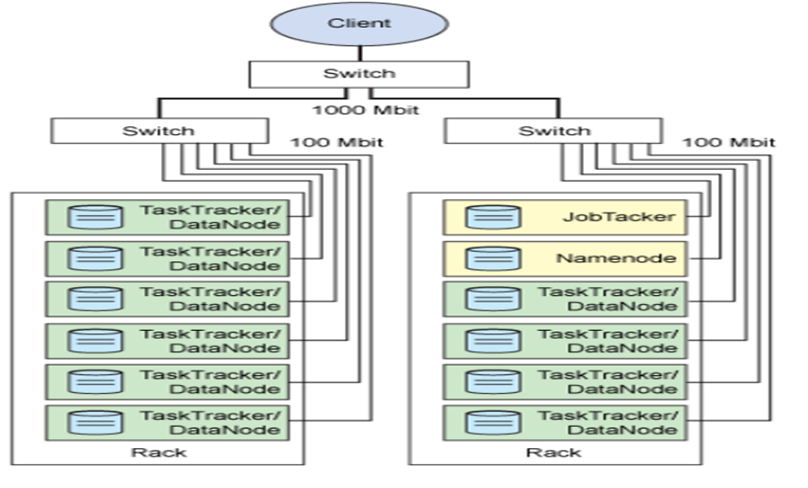
与伪分布式相对,hadoop完全分布式需要部署在多节点(多主机,或者虚拟机)上。不同的节点承担不同的任务,例如,根据hadoop存储安全性原则的要求,需将namenode和secondarynamenode部署在不同的节点上。
部署环境
| item | version |
|---|---|
| VMware | 10.0 |
| 操作系统: | Ubuntu 14.04.1 LTS |
| JDK: | jdk1.8.0_45 |
| hadoop: | hadoop-1.2.1 |
网络拓扑结构及节点配置
| 节点类型 | 节点ip地址 | 节点主机名 | 存放内容 |
|---|---|---|---|
| master节点 | 192.168.16.110 | node1 | namenode |
| slave节点 | 192.168.16.120 | node2 | datanode、secondarynamenode |
| slave节点 | 192.168.16.130 | node3 | datanode |
部署流程及解释
原则:进行任何的Linux相关的操作之后,都要进行必要的验证操作,是否操作成功。好比,进行
rm -rf /的操纵时,先深呼吸,反问自己:路径是否正确,删除操纵是否必要。
网络配置
先用VMware安装三台虚拟机(先安装一台,后clone两台),根据网络拓扑结构及节点配置配置网络。
静态ip配置
三台虚拟机的网络连接方式的配置以及各自静态ip的设置,参见VMware网络连接方式(Host-only、NAT、Bridged)介绍及NAT环境下静态IP配置一文,分别设置三台虚拟机的静态ip。修改主机名
使用下面的命令,分别将三台虚拟机的主机设置为node1,node2,node3,这一操作大概是需要重启主机方可生效。
vim /etc/hostname- 域名解析
域名解析,顾名思义,将ip地址和主机名进行关联。
vim /etc/hosts添加如下entry:
192.168.16.110 node1
192.168.16.120 node2
192.168.16.130 node3建立ssh互信(也即免密码登录)
形式上的免密码登录,也即本质上的建立ssh之间的互信,并非只是为了传输数据的方便,更多的是为了启动以及执行命令的方便。例,如果在主机node1已经实现了对node2、对node3的远程访问,则在node1上可实现全局的开启hadoop,
./start-all.sh,而不必分别启动。这里的ssh和java-web中的ssh之间的联系,好比巴西中场球员奥斯卡和好莱坞的电影艺术学院奖之间的联系,也就是没有联系,仅仅共享一个名字而已。
- 生成秘钥并配置无密码登录主机(在node1主机)
ssh -keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys- 将authorized_keys传送到两台slave(node2、node3)上
scp authorized_keys root@node2:~/.ssh/
scp authorized_keys root@node3:~/.ssh/- 验证是否在node1可以免密码ssh登录node2、node3、
工作原理:ssh登录远程主机时需要进行密钥的检验,
id_dsa是私钥,id_dsa.pub是对应的公钥,一般钥匙对一把锁,将authorized_keys拷贝到远程主机的同名文件,本地和远程的锁和钥匙向匹配,则验证通过。不知道自己的理解对不对。根据开篇中所说,任何一个知识点都可作为一个原理之下的推论的话。这里根据上述的工作原理,可以很容易得出,如何在node2(或者node3)上分别ssh免密码登录node1和node3(node2)。
配置JDK
约定将所有软件都安装在/usr/local/路径下。
解压并重命名
tar -zvxf jdk-8u45-linux-i586.gz
mv jdk1.8.0_45 jdk添加环境变量
在/etc/profile中添加:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH据我考证PATH变量开头的”.”的意义在于,将:$JAVA_HOME/bin这一路径置于整个PATH变量的首部。
也即如果echo $PATH :$JAVA_HOME/bin这一路径会在最开始的位置。
配置Hadoop
解压并重命名
tar -zvxf hadoop-1.2.1.tar.gz
mv hadoop-1.2.1 hadoop设置环境变量
在/etc/profile添加JAVA_HOME的位置:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH配置node1下的hadoop
目前配置的都是主机node1上的文件,进入conf目录;
1. 修改hadoop-env.sh
取消JAVA_HOME的注释并将路径修改为/usr/local/jdk
2. 修改core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
</configuration>这里配置的分别是namenode的RPC路径,以及hdfs文件系统的文件存放位置(根目录或者叫基目录),hdfs文件系统格式化之时,会自动创建/opt/hadoop。
core-site.xml对应有于core-default.xml,hdfs-site.xml对应于hdfs-default.xml,mapred-site.xml对应于mapred-default.xml。这三个defalult文件(可在hadoop的解压文件的docs目录下查看)面都有一些默认配置,现在我们修改这三个site文件,目的就覆盖default里面的一些配置
3. 修改hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>顾名思义,设置副本数,本例为2。
4. 修改slaves
node2
node3配置datanode的ip地址或者主机名(hostname)
5. 修改masters
node2定义secondarynamenode的节点位置,注意这里的masters不是namenode的主机配置,而是secondarynamenode的主机配置。
配置node2、node3下的hadoop
将已经配置好的hadoop文件夹,拷贝到node2、node3下:
scp /usr/local/hadoop/* root@node2:/usr/local/hadoop
scp /usr/local/hadoop/* root@node3:/usr/local/hadoopdone!!!
验证
1. 开启hdfs
在node1端
start-dfs.sh打印输出的日志信息说明了启动该流程:
1. 启动本地的namenode,
2. 启动node3上的datanode
3. 启动node2上的datanode
4. 启动node2上的secondarynamenode
可分别在node1、node2、node3,输入jps命令查看各自的进程数,也即,node1:启动namenode,node2:datanode,secondarynamenode,node3:datanode
如果node1的日志信息,显示四个节点都启动起来了,而在node2、node3端,输入jps,却没有对应的显示,这里是防火墙的问题。此时应当:
service iptables stop
stop-dfs.sh
start-dfs.sh2. 浏览器端验证
访问之前http://node1:50070需要windows操作系统对node1进行解析,在C:\Windows\System32\drivers\etc\hosts文件中添加对应的ip地址和域名的关联信息。
注:50070是hdfs对应于http的端口,而9000是RPC协议端口。
















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











