







HBase 是 NoSQL(非关系型数据库)系列的一种。
HBase 基础知识
HBase:Hadoop database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。
- HBase 利用 Hadoop HDFS 作为其文件存储系统;
- 利用 Hadoop MapReduce 来处理 HBase 中的海量数据;
- 利用 ZooKeeper 作为协调工具。
如何分析一个数据库产品?
- 数据模型(Data Model):我们将数据存储到HBase,那么到底是以一种怎样的方式存储的呢?数据模型是最接近用户的,
- 体系结构(部署模型):
数据模型:
(1)表(table):用来存储管理数据。
(2)行键(row key): 类似于MySQL中的主键,但行健在 HBase 中不是必须的,可有可无。行健是HBase表天然自带的
(3)列族(column family),a collection of columns,列的集合。HBase 中列族是需要在定义表时指定的,而具体的每一列是在插入记录时动态增加的。
HBase 表中的数据,每个列族单独构成一个文件,这称为HBase的物理数据模型。而逻辑数据模型,是一个行健对应一个文件。
(4)时间戳(timestamp),是列(也称作标签、修饰符)的一个属性。任意一列的定义形式为:
族:标签。如何理解这里的时间戳为列的一个属性?时间戳以作为列属性引入到HBase中,是将为维的表(table)增加一维,进入到三维,多了时间维。通俗地说,行和列确定的单元格的值可以为多个,以时间为序。关于数据属性的版本特性,可类比百度搜索引擎为每一个网页提供的
百度快照。
如果不指定时间戳或版本,默认取最新的数据。(5)存储的数据都是字节数组;
- (6)表中的数据按照行健的顺序(行健也是字节)物理存储的(而关系型数据库,比如MySQL是按照插入的先后顺序存储在物理设备上的);
- (7)表中的不同行可以拥有不同数量的成员,即支持动态模式模型。这导致了一个结果即是,表内数据非常稀疏,不同行的相同列可以完全不同。
物理模型:
- (1)HBase 是适合海量数据(PB级)的秒级简单查询的数据库。
(2)海量数据必然存放于外存(内存有限),那么HBase如何实现自己的效率(秒级查询)的呢?HBase表中的记录,按照行健进行拆分,拆分成一个个的region(HBase最大的亮点)。上文HBase数据模型的第六点可知,存放于物理设备上的HBase数据根据其行健已做过排序。regions 存储于region server(单独的物理机器)中的。一个 region 由
[startkey, endkey)表示,每个HRegion分散在不同的region server中,当需要查询每一数据时,是各个region server的查询算法并行查询。
这样,对表的查询转化为对多台region server的并行查询。(3)region大小的设置
region的大小,通过hbase-default.xml 文件的hbase.hregion.max.filesize 属性配置:
<property> <name>hbase.hregion.max.filesize</name> <value>10737418240</value> <description> Maximum HStoreFile size. If any one of a column families' HStoreFiles has grown to exceed this value, the hosting HRegion is split in two. Default: 10G. </description> </property>
HBase 体系结构
(1)HBase 也是主从结构(和Hadoop一样),HMaster(主)、HRegionServer(从)(Hadoop式的主从结构的一个明显缺点是,namenode/JobTracker 的节点宕机,整个集群都会宕机,因为namenode/JobTracker是核心是中枢),HBase对此进行了改进,其允许有多个Master存在,但同一时间,只有一个HMaster在运行,其余则为
备胎。(2)Master 可以启动多个HMaster,通过ZooKeeper的Master Election(3888端口)机制保证总有一个Master运行。
(3)我们再来看ZooKeeper在HBase体系结构中扮演的角色
- (1)保证任何时候,集群中只有一个running master
- (2)存贮所有Region 的寻址入口
- (3)实时监控Region Server 的状态,将Region server 的上线和下线信息,实时通知给Master
- (4)存储Hbase 的schema,包括有哪些table,每个table 有哪些column family(正因为避免Master的宕机,才将这些本该存放在Master上的核心中枢信息,交由ZooKeeper保管,通过其Master Election机制以及统一协调工具实现对随时换一台server做master)
总结
- client 访问hbase 上数据的过程并不需要master 参与,
- 寻址(region的地址)访问zookeeper 和region server,
- 数据读写访问regione server。
- HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HBase的索引结构
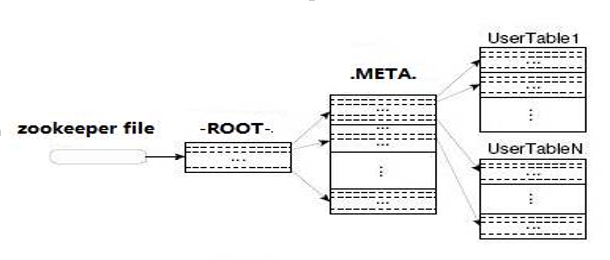
HBase中有两张特殊的Table,-ROOT-和.META.
- .META.:记录了用户表的Region信息,.META.可以有存储多个regoin
- -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region,Zookeeper中记录了-ROOT-表的location
-ROOT-、.META.是系统的内置表
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问
也即如下的二级索引结构(索引的存在是为了加快查询的速度):


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











