







Hive 基础及安装
Hive 操作(一)
hive 操作(二)——使用 mysql 作为 hive 的metastore
hive 操作(三)——hive 的数据模型
hive 操作(四)
大的分类可分为:
(1)受控表(MANAGED_TABLE)
- 内部表
- 分区表
- 桶表
(2)外部表(external table)
和受控表不同,对外部表删除,仅删除引用,而不删除真实存储的数据;
内部表
(1)表定义
表定义,自然包含字段定义,也即列定义;
hive> create table t1(id int); hive> show tables;我们也可进入浏览器端,输入
hadoop0:50070,然后浏览文件系统(Browse File System),进入/hive,会发现一个名为t1的文件夹。至此我们说,现在的hive使用的是mysql作为自己的metastore(映射工具);(2)加载数据
hive> load data local inpath 文件 into table 表名; 如 hive> load data local inpath '/root/id' into table t1; # local:表示从本地的磁盘文件进行加载 # 如果不带local,表示从hdfs进行加载命令中含不含local,表示着两种数据的加载方式。所以如果使用
hadoop fs -put id /hive/t1/id2(也即会从hdfs中加载数据),表t1也会将id2中的数据吸收进来。(3)定义多字段表
hive> create table t2(id int, name string) row format delimited fields terminated by '\t'; # 以制表符区分不同的字段在 hive 中除
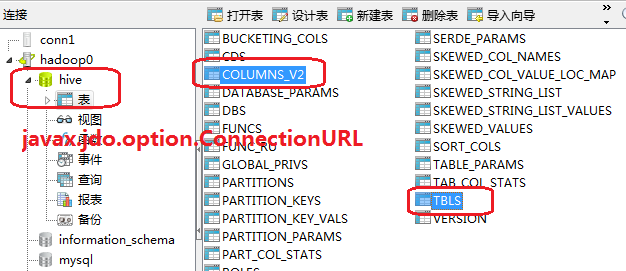
select *以外的操作,均走的是MapReduce的流程,因为select *是全表扫描?是否在新版的 hive 中,对查询语句的支持有所提升,也即并非只有select *很快给出结果,不走MapReduce流程的不只select *一个;在映射工具metastore所在的仓库,也即mysql中,此环境中的hive数据库的TBLS表会对hive所建的表有所显示(显示的是表名),在COLUMNS_V2会显示表的字段信息;
分区表
可以根据字段对数据分区;
(1)创建分区表
hive> create table t3(id int) partitioned by (day int); # 分区信息形式上其实是一个字段 # 这样我们才可在select中利用where进行查询;(2)加载数据到分区表
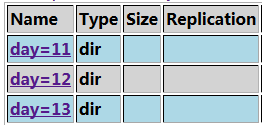
hive> load data local inpath '/root/id' into table t3 partition (day=11);我们可以将同样的数据根据分区信息加载到不同的文件:
hive> load data local inpath '/root/id' into table t3 partition (day=12); hive> load data local inpath '/root/id' into table t3 partition (day=13);
这样,根据某一划分标准(比如按小时、按天),方便我们按照这一标准进行查询(
select ** from table ** where day = 12;);所建的分区表,则就要利用分区信息进行查询,因为高效,如果还是用普通的字段查询的话,效率会很低,丧失建分区表的意义;
分区字段选取的依据在于查询的频率,也即查询频率越高的信息越作为分区字段;
(3)桶表
常用在表链接时;
和分区表一样,也是对数据进行划分,只不过划分的依据有所不同。
桶表是对数据进行哈希取值,然后放到不同文件中存储;
(1)创建桶表
hive> create table t4(id int) clustered by(id) into 4 buckets;(2)加载数据
a. 启动桶机制,也即默认是不使用桶的
set hive.enforce.bucketing = true;b. 加载数据
insert into table t4 select id from t3;
(4)外部表
所谓的外部其实是指hdfs文件系统;
[root@hadoop0 ~]# hadoop -put id /external/idhive> create external table t5(id int) location '/external';对外部表的删除动作,仅删除引用,而不会到外部文件处,真正删除数据。
hive> drop table t5;
















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











