









LLMs:《Large Language Models A Survey综述调查》翻译与解读—概述了早期预训练语言模型发展史→介绍了3个流行的LLM家族及其它代表性模型→构建、增强和使用LLM的方法和技术→数据集和基准→未来方向和挑战
导读:这篇论文系统总结了LLM技术从统计模型到深度学习模型的发展历程,并概括当前三大主流LLM家族的代表模型及其特点,为读者提供了一个 LLMs 领域的全景视角。
背景:
>> 文章回顾了统计语言模型(SLMs)及早期神经网络语言模型(NLMs)。语言模型技术源于20世纪50年代,起初是基于n-gram统计机器学习算法。随后的神经网络语言模型(NLM)采用embedding技术解决了统计语言模型的数据稀疏性问题。
>> 随后提出预训练语言模型(PLMs)及大规模语言模型(LLMs)两个概念。预训练语言模型(PLM)是任务无关的,其学习得到的嵌入空间也是通用的。PLM采用预训练-微调范式进行训练。主流PLM有BERT、GPT系列、T5等。BERT使用双向训练,GPT采用单向自回归训练,T5提出将所有NLP任务统一为生成任务。
近年来LLM技术的成功主要因素:
>> 采用Transformer结构,可以进行高效预训练。
>> 预训练规模不断扩大,如PaLM以540B参数规模进行预训练。
>> 出现强化学习等新技术进行增强训练。
论文总结了三大主流LLM家族技术细节:
● GPT系列模型,以开放AI研发,175B的参数GPT-3首次展示强大语言理解能力。
● LLaMA系列,以元数据研发,13B参数模型性能超越GPT-3,开源可复现。
● PaLM系列,Facebook研发,以8B和62B参数两种规模,在多种任务上领先同级别模型。
核心要点:
>> 详细阐述了构建LLMs的各个环节,包括数据清理、分词方法、模型预训练、微调与指令微调等。
>> 系统介绍了LLMs的常用应用技巧,如提示设计以及外部知识增强等。
>> 文章选取多个重要数据集,对不同模型在这些数据集上的表现进行了对比,以观察模型在自然语言理解、推理、代码生成等多项能力上的优劣。
LLM的主要优势:如上下文学习能力、指令执行能力以及多步推理能力。
LLMs的主要挑战:比如模型效率问题、多模态处理能力、面对安全与伦理问题等。
未来研究方向:如模型效率、多模态、人机交互等。
该论文系统回顾了LLMs的历史发展与分类方法,并探讨了模型构建、应用及评估各个环节,对这一快速发展的研究领域给予了全面而深入的总结,对后续研究具有指导意义。
目录
《Large Language Models A Survey大型语言模型的综述调查》翻译与解读
四波浪潮:SLM(统计语言模型)→NLM(神经语言模型)→PLM(预训练语言模型)→LLM(大语言模型)
LLM:优于PLM的三大特点(规模更大/语言理解和生成能力更强/新兴能力【CoT/IF/MSR】),也可使用外部工具来增强和交互(收集反馈数据然后不断改进自身)
本文结构:第二部分(LLMs的最新技术)→第三部分(如何构建LLMs)→第四部分(LLMs的用途)→第五和第六部分(评估LLMs的流行数据集和基准)→第七部分(面临的挑战和未来方向)
II. LARGE LANGUAGE MODELS大型语言模型
TABLE I: High-level Overview of Popular Language Models
A. Early Pre-trained Neural Language Models早期预训练的神经语言模型
Bengio等人开发第一个NLM→Mikolov等人发布了RNNLM→基于RNN的变体(如LSTM和GRU),被广泛用于许多自然语言应用,包括机器翻译、文本生成和文本分类
诞生Transformer架构:NLM新的里程碑,比RNN更多的并行化+采用GPU+下游微调
基于Transformer的PLMs三大类:仅编码器、仅解码器和编码器-解码器模型
1)、仅编码器PLMs:只包含一个编码器网络、适合语言理解任务(比如文本分类)、使用掩码语言建模和下一句预测等目标进行预训练
BERT:3个模块(嵌入模块+Transformer编码器堆栈+全连接层)、2个任务(MLM和NSP),可添加一个分类器层实现多种语言理解任务,显著提高并成为仅编码器语言模型的基座
Fig. 3: Overall pre-training and fine-tuning procedures for BERT. Courtesy of [24]
ELECTRA(提出RTD替换MLM任务+小型生成器网络+训练一个判别模型)、XLM(两种方法将BERT扩展到跨语言语言模型=仅依赖于单语数据的无监督方法+利用平行数据的监督方法)
Fig. 7: High-level overview of GPT pretraining, and fine-tuning steps. Courtesy of OpenAI.
GPT-1:基于仅解码器的Transformer+生成式预训练【无标签语料库+自监督学习】+微调【下游任务有区别的微调】
GPT-2:基于数百万网页的WebText数据集+遵循GPT-1的模型设计+将层归一化移动到每个子块的输入处+自关注块之后添加额外的层归一化+修改初始化+词汇量扩展到5025+上下文扩展到1024
T5(将所有NLP任务都视为文本到文本生成任务)、mT5(基于T5的多语言变体+101种语言)
MASS(重构剩余部分句子片段+编码器将带有随机屏蔽片段句子作为输入+解码器预测被屏蔽的片段)、BART()
B. Large Language Model Families大型语言模型家族(基于Transformer的PLM+尺寸更大【数百亿到数千亿个参数】+表现更强):比如LLM的三大家族
Fig. 10: The high-level overview of RLHF. Courtesy of [59].
GPT家族(OpenAI开发+后期闭源):开源系列(GPT-1、GPT-2),闭源系列(GPT-3、InstrucGPT、ChatGPT、GPT-4、CODEX、WebGPT,只能API访问)
GPT-3(175B):1750亿参数+被视为史上第一个LLM(因其大规模尺寸+涌现能力)+仅需少量演示直接用于下游任务而无需任何微调+适应各种NLP任务
CODEX(2023年3月,即Copilot的底层技术):通用编程模型,解析自然语言并生成代码作为响应,采用GPT-3+微调GitHub的代码语料库
WebGPT:采用GPT-3+基于文本的网络浏览器回答+三步骤(学习模仿人类浏览行为+利用奖励函数来预测人类的偏好+强化学习和拒绝抽样来优化奖励函数)
InstructGPT:采用GPT-3+对人类反馈进行微调(RLHF对齐用户意图)+改善了真实性和有毒性
ChatGPT(2022年11月30日):一种聊天机器人+采用用户引导对话完成各种任务+基于GPT-3.5+为InstructGPT的兄弟模型
GPT-4(2023年3月):GPT家族中最新最强大的多模态LLM(呈现人类级别的性能)+基于大型文本语料库预训练+采用RLHF进行微调
Fig. 12: Training of LLaMA-2 Chat. Courtesy of [61].
LLaMA2(2023年7月/Meta与微软合作):预训练(公开可用)+监督微调+模型优化(RLHF/拒绝抽样/最近邻策略优化)
Alpaca:利用GPT-3.5生成52K指令数据+微调LLaMA-7B模型,比GPT-3.5相当但成本非常小
Guanaco:采用指令遵循数据+利用QLoRA微调LLaMA模型,单个48GB GPU上仅需24小时可微调65B参数模型,达到了ChatGPT的99.3%性能
Koala:采用指令遵循数据(侧重交互数据)+微调LLaMA模型
Mistral-7B:为了优越的性能和效率而设计,利用分组查询注意力来实现更快的推理,并配合滑动窗口注意力来有效地处理任意长度的序列
其它:Code LLaMA 、Gorilla、Giraffe、Vigogne、Tulu 65B、Long LLaMA、Stable Beluga
Fig. 14: Flan-PaLM finetuning consist of 473 datasets in above task categories. Courtesy of [74].
U-PaLM:使用UL2R(使用UL2的混合去噪目标来持续训练)在PaLM上进行训练+可节省约2倍的计算资源
Flan-PaLM:更多的任务(473个数据集/总共1836个任务)+更大的模型规模+链式思维数据
PaLM-2:计算效率更高+更好的多语言和推理能力+混合目标,快速、更高效的推理能力
Med-PaLM(特定领域的PaLM(医学领域问题回答),基于PaLM的指令提示调优)→Med-PaLM 2(医学领域微调和集成提示改进)
C. Other Representative LLMs其他代表性LLM
Fig. 15: comparison of instruction tuning with pre-train–finetune and prompting. Courtesy of [78].
Fig. 16: Model architecture details of Gopher with different number of parameters. Courtesy of [78].
Fig. 17: High-level model architecture of ERNIE 3.0. Courtesy of [81].
Fig. 20: Different OPT Models’ architecture details. Courtesy of [86].
Fig. 22: An overview of UL2 pretraining paradigm. Courtesy of [92].
Fig. 23: An overview of BLOOM architecture. Courtesy of [93].
BLOOM(基于ROOTS语料库+仅解码器的Transformer,176B)、GLM(双语(中英文)预训练语言模型+对飙100B级别的GPT-3,130B)、Pythia(由16个LLM组成的套件)
Orca(从GPT-4丰富的信号中学习+解释痕迹+多步思维过程,13B)、StarCoder(8K上下文长度,15B参数/1T的toekn)、KOSMOS(多模态大型语言模型+任意交错的模态数据)
Gemini(多模态模型,基于Transformer解码器+支持32k上下文长度,多个版本)
III. HOW LLMS ARE BUILT如何构建LLMs
数据准备(收集、清理、去重等)→分词→模型预训练(以自监督的学习方式)→指令调优→对齐
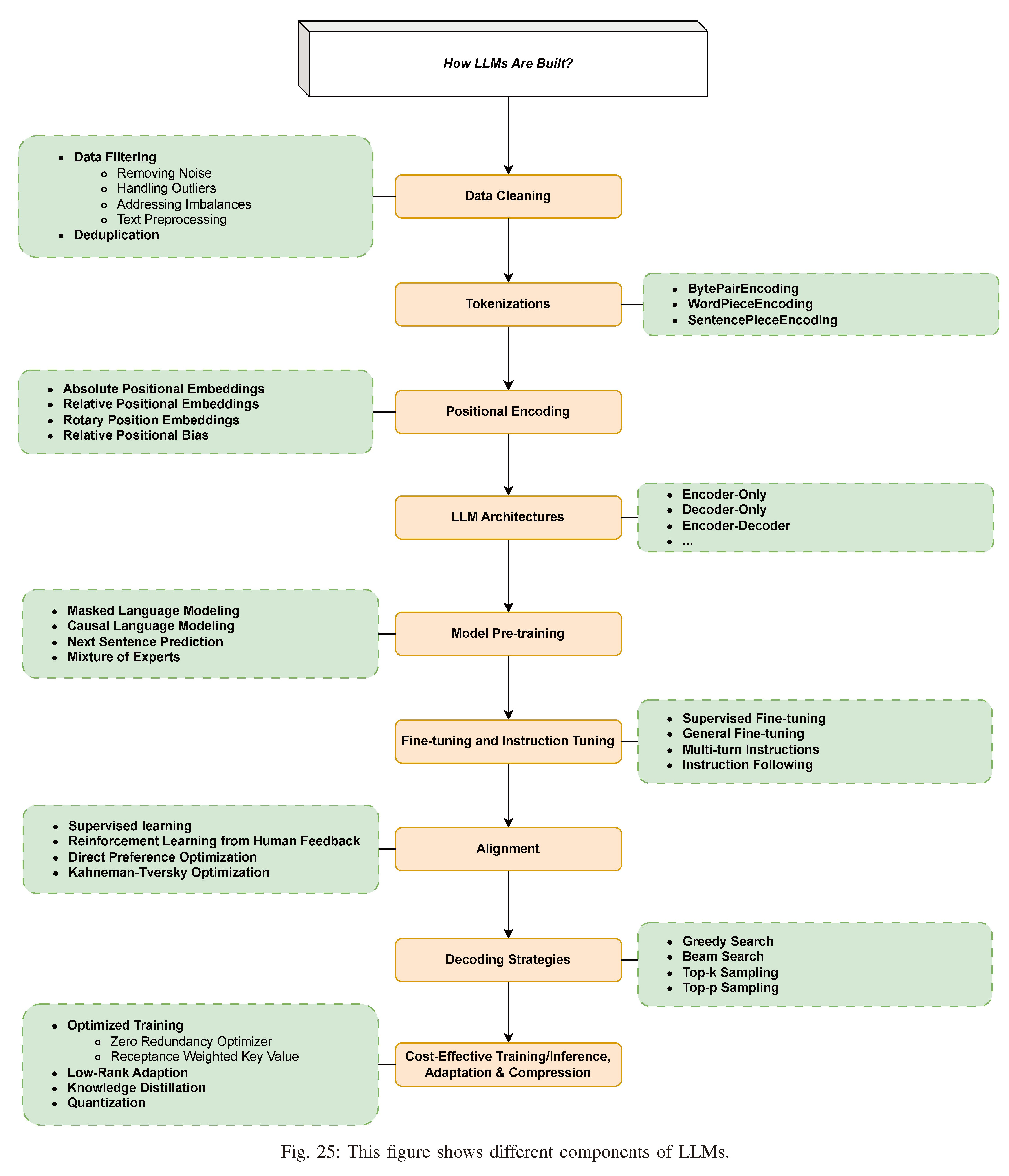
Fig. 25: This figure shows different components of LLMs.
A. Dominant LLM Architectures主流LLM架构(即基于Transformer)
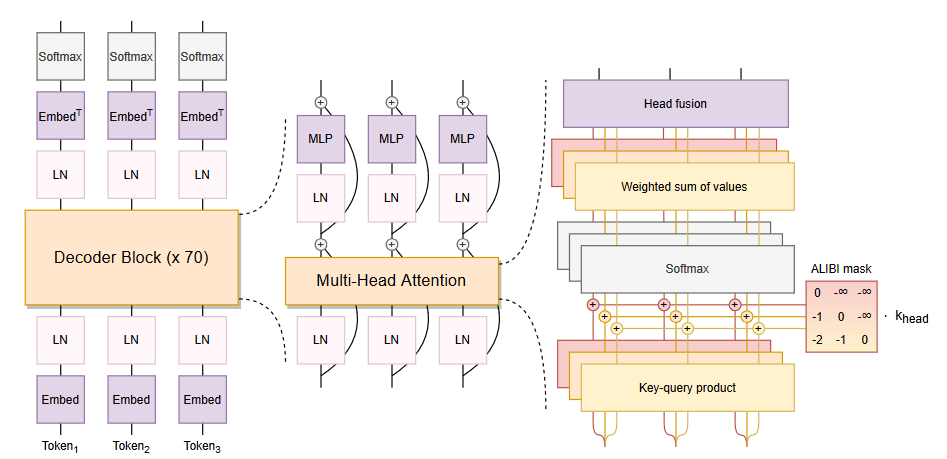
最初是为使用GPU进行有效的并行计算而设计,核心是(自)注意机制,比递归和卷积机制更有效地捕获长期上下文
Fig. 26: High-level overview of transformer work. Courtesy of [44].
2) Encoder-Only:注意层都可以访问初始句子中的所有单词,适合需要理解整个序列的任务,例如句子分类、命名实体识别和抽取式问答,比如BERT
3) Decoder-Only(也被称为自回归模型):注意层只能访问句子中位于其前面的单词,最适合涉及文本生成的任务,比如GPT
4) Encoder-Decoder(也被称为序列到序列模型): 最适合基于给定输入生成新句子的任务,比如摘要、翻译或生成式问答
Falcon40B已证明仅对web数据进行适当过滤和去重就可以产生强大的模型,从CommonCrawl获得了5T的token+从REFINEDWEB数据集中提取了600B个token
数据过滤:目的(数据的高质量+模型的有效性),去除噪声、处理异常值、解决不平衡、文本预处理、处理歧义
去重:可提高泛化能力,NLP任务需要多样化和代表性的训练数据,主要依赖于高级特征之间的重叠比率来检测重复样本
C. Tokenizations分词:分词器依赖于词典、常用的是基于子词但存在OOV问题,三种流行的分词器
Tokenization是将文本序列分割成较小单元(token)的过程,对自然语言处理任务至关重要
BytePairEncoding:最初是一种数据压缩算法,主要是保持频繁词的原始形式,对不常用的词进行分解。通过识别字节级别的频繁模式来压缩数据,有效管理词汇表大小,同时很好地表示常见单词和形态形式
WordPieceEncoding:比如BERT和Electra等,确保训练数据中的所有字符都包含在词汇表中,以防止未知token,并根据频率进行标记化
SentencePieceEncoding:解决了具有嘈杂元素或非传统词边界的语言中的分词问题,不依赖于空格分隔
Fig. 28: Various positional encodings are employed in LLMs.
绝对位置编码 (APE):在Transformer模型中被用来保留序列顺序信息,通过在编码器和解码器堆栈底部将词的位置信息添加到输入嵌入中
相对位置编码(RPE):扩展了自注意力机制,考虑了输入元素之间的成对链接,以及作为密钥的附加组件和值矩阵的子组件。RPE将输入视为具有标签和有向边的完全连接图,并通过限制相对位置来进行预测
旋转位置编码(RoPE)通过使用旋转矩阵对词的绝对位置进行编码,并在自注意力中同时包含显式的相对位置细节,提供了灵活性、降低了词之间的依赖性,并能够改进线性自注意力
相对位置偏差(RPA,如ALiBi):旨在在推理时为解决训练中遇到的更长的序列进行外推。ALiBi在注意力分数中引入了一个偏差,对查询-键对的距离施加罚项,以促进在训练中未遇到的序列长度的外推
E. Model Pre-training预训练:LLM中的第一步,自监督训练,获得基本的语言理解能力
T1、自回归语言建模:模型尝试以自回归方式预测给定序列中的下一个标记,通常使用预测标记的对数似然作为损失函数
T2、掩码语言建模(或去噪自编码):通过遮蔽一些词,并根据周围的上下文预测被遮蔽的词
T3、混合专家:允许用较少的计算资源进行预训练,通过稀疏MoE层和门控网络或路由器来实现,路由器确定将哪些标记发送到哪个专家,并且可以将一个标记发送给多个专家
F. Fine-tuning and Instruction Tuning微调和指令调优
有监督微调SFT:早期语言模型(如BERT)经过自监督训练后,需要通过有标签数据进行特定任务的微调,以提高性能
微调的意义:微调不仅可以针对单一任务进行,还可以采用多任务微调的方法,这有助于提高结果并减少提示工程的复杂性
指令微调:对LLMs进行微调的重要原因之一是将其响应与人类通过提示提供的期望进行对齐,比如InstructGPT和Alpaca
RLHF(利用奖励模型从人类反馈中学习对齐)和RLAIF(从AI反馈中学习对齐)
贪婪搜索:它在每一步中选择最有可能的标记作为序列的下一个标记,简单快速,但可能失去一些时间连贯性和一致性
束搜索:它考虑N个最有可能的标记,直到达到预定义的最大序列长度或出现终止标记,选择具有最高总分数的标记序列作为输出
Top-k 采样:Top-k抽样从k个最可能的选项中随机选择一个标记,以概率分布的形式确定标记的优先级,并引入一定的随机性
Top-p抽样:Top-p抽样选择总概率超过阈值p的标记形成的“核心”,这种方法更适合于顶部k标记概率质量不大的情况,通常产生更多样化和创造性的输出
I. Cost-Effective Training/Inference/Adaptation/Compression高效的训练/推理/适应/压缩
优化训练—降存提速:ZeRO(优化内存)和RWKV(模型架构)是优化训练的两个主要框架,能够大幅提高训练速度和效率
Fig. 32: RWKV architecture. Courtesy of [141].
低秩自适应(LoRA)—减参提速:LoRA通过低秩矩阵近似差异化权重,显著减少了可训练参数数量,加快了训练速度,提高了模型效率,同时产生的模型体积更小,易于存储和共享
知识蒸馏—轻量级部署提速:知识蒸馏是从更大的模型中学习的过程,通过蒸馏多个模型的知识,创建更小的模型,从而在边缘设备上实现部署,有助于减小模型的体积和复杂度
Fig. 35: A generic knowledge distillation framework with student and teacher (Courtesy of [144]).
量化—降低精度提速:量化是指减小模型权重的精度,从而减小模型大小并加快推理速度,包括后训练量化和量化感知训练两种方法
IV. HOW LLMS ARE USED AND AUGMENTED如何使用和扩展LLMs
Fig. 36: How LLMs Are Used and Augmented.
限制:缺乏记忆、随机概率性的、缺乏实时信息、昂贵的GPU、存在幻觉问题
幻觉的分类:内在幻觉(与源材料直接冲突,引入事实错误或逻辑不一致)、外在幻觉(虽然不矛盾,但无法与源进行验证,包括推测性或不可验证的元素)
幻觉的衡量:需要结合统计和基于模型的度量方法,以及人工判断,例如使用ROUGE、BLEU等指标、基于信息提取模型的度量和基于自然语言推理数据集的度量
FactScore:最近的一个度量标准的例子,它既可以用于人类评估,也可以用于基于模型的评估
缓解LLM幻觉的挑战:包括产品设计和用户交互策略、数据管理与持续改进、提示工程和元提示设计,以及模型选择和配置
B. Using LLMs: Prompt Design and Engineering提示设计和工程
提示工程是塑造LLM及其他生成式人工智能模型交互和输出的迅速发展学科,需要结合领域知识、对模型的理解以及为不同情境量身定制提示的方法论
Prompt工程是一门不断发展的学科,通过设计最佳Prompt来实现特定目标
主要的Prompt工程方法包括:CoT、ToT、自我一致性、反思、专家提示、链条和轨道
8)自动提示工程:旨在自动化生成LLM的提示,利用LLM本身的能力生成和评估提示,进而创建更高质量的提示,更有可能引发期望的响应或结果
C. Augmenting LLMs through external knowledge - RAG通过外部知识扩充
Fig. 37: An example of synthesizing RAG with LLMs for question answering application [166].
Fig. 38: This is one example of synthesizing the KG as a retriever with LLMs [167].
FLARE:通过迭代地结合预测和信息检索,提高了大型语言模型的能力
使用外部工具是增强LLM功能的一种方式,不仅包括从外部知识源中检索信息,还包括访问各种外部服务或API
工具是LLM可以利用的外部功能或服务,扩展了LLM的任务范围,从基本的信息检索到与外部数据库或API的复杂交互,比如Toolformer
ART是一种将自动化的链式思维提示与外部工具使用相结合的提示工程技术,增强了LLM处理复杂任务的能力,尤其适用于需要内部推理和外部数据处理或检索的任务。
LLM代理是基于特定实例化的(增强的)LLM的系统,能够自主执行特定任务,通过与用户和环境的交互来做出决策,通常超出简单响应生成的范围
Prompt工程技术针对LLM代理的需要进行了专门的开发,例如ReWOO、ReAct、DERA等。这些技术旨在增强LLM代理的推理、行动和对话能力,使其能够处理各种复杂的决策和问题解决任务
ReWOO:目标是将推理过程与直接观察分离,让LLM先制定完整的推理框架与方案,然后在获取必要数据后执行
ReAct:会引导LLM同时产生推理解释与可执行行动,从而提升其动态解决问题的能力
DERA:利用多个专业化代理交互解决问题和做决定,每个代理有不同角色与职能,这种方式更高效地进行复杂决策
Fig. 39: HuggingGPT: An agent-based approach to use tools and planning [image courtesy of [171]]
Fig. 40: A LLM-based agent for conversational information seeking. Courtesy of [36].
V. POPULAR DATASETS FOR LLMS常用的数据集
Fig. 41: Dataset applications.
Fig. 42: Datasets licensed under different licenses.
TABLE II: LLM Datasets Overview.
基本任务数据集:用于评估LLM基本能力的基准和数据集,如自然问题、数学问题、代码生成等任务的数据集,包括Natural Questions、MMLU、MBPP等。
阅读理解数据集:用于阅读理解任务的数据集,如RACE、SQuAD、BoolQ等。
阅读推理数据集:包括MultiRC等,适用于需要跨句子推理的阅读理解任务的数据集
新兴任务数据集:评估LLM新兴能力的基准和数据集,包括GSM8K、MATH等,用于多步数学推理、解决数学问题等任务
常识推理数据集:如HellaSwag、AI2 Reasoning Challenge (ARC)等,用于评估LLM的常识推理能力,包括常识问题、科学推理等任务
自然常识问题数据集:例如PIQA、SIQA等,旨在评估LLM对社交情境和物理常识的推理能力
开放式问题回答数据集:包括OpenBookQA (OBQA)、TruthfulQA等,用于评估LLM在处理开放性问题时的能力。
指令元学习数据集:OPT-IML Bench,用于评估LLM在指令元学习方面的表现
VI. PROMINENT LLMS’ PERFORMANCE ON BENCHMARKS杰出LLM的基准表现
TABLE III: LLM categories and respective definitions.
TABLE IV: Different LLM categorization.
TABLE V: Commonsense reasoning comparison.
TABLE VI: Symbolic reasoning comparison.
TABLE VII: World knowledge comparison.
TABLE VIII: Coding capability comparison.
TABLE IX: Arithmetic reasoning comparison.
TABLE X: Hallucination evaluation
A. Popular Metrics for Evaluating LLMs评估LLM的流行指标
代码生成需要使用不同的指标,如Pass@k和Exact Match (EM)
评估机器翻译等生成任务时,通常使用Rouge和BLEU等度量标准
LLM的分类和标签:将LLMs根据参数规模划分为小型、中型、大型和超大型4类;按预训练目的划分为基础模型、指令模型和聊天模型3类。此外,还区分原始模型和调优模型,以及公共模型和私有模型
B. LLMs’ Performance on Different Tasks在不同任务上的表现
LLMs在常识推理、世界知识、编码能力、算术推理和幻觉检测等方面表现出不同的性能
GPT-4在HellaSwag常识数据集上表现最好;Davinci-003在OBQA问答数据集上表现最佳
VII. CHALLENGES AND FUTURE DIRECTIONS挑战与未来方向
A. Smaller and more efficient Language Models更小、更高效的语言模型:如Phi系列小语言模型
针对大型语言模型的高成本和低效率,出现了对小型语言模型(SLMs)的研究趋势,如Phi-1、Phi-1.5和Phi-2
未来预计将继续研究如何训练更小、更高效的模型,使用参数有效的微调(PEFT)、师生学习和其他形式的蒸馏等技术
B. New Post-attention Architectural Paradigms新的后注意力机制的架构范式:探索注意力机制之外的新架构,如状态空间模型和MoE混合专家模型
传统的Transformer模块在当前LLM框架中起着关键作用,但越来越多的研究开始探索替代方案,被称为后注意力模型
结构状态空间模型(SSM)是一类重要的后注意力模型,如Mamba、Hyena和Striped Hyena
后注意力模型解决了传统基于注意力的架构在支持更大上下文窗口方面的挑战,为处理更长上下文提供了更有效的方法
MoE机制已经存在多年,但近年来在Transformer模型和LLMs中越来越受欢迎,被应用于最先进和最具性能的模型中
MoEs允许训练极大的模型,而在推理过程中只部分实例化,其中一些专家被关闭。 MoEs已成为最先进LLMs的重要组成部分,例如GPT-4、Mixtral、GLaM
C. Multi-modal Models多模态模型:研发多模态语言模型,融合文本、图片、视频等多种数据类型
未来的LLMs预计将是多模态的,能够统一处理文本、图像、视频、音频等多种数据类型,如LLAVA、GPT-4等
D. Improved LLM Usage and Augmentation techniques改进LLM的使用和增强技术
通过高级提示工程(提升问答引导)、工具使用或其他增强技术,可以解决LLMs的一些缺陷和限制,如幻觉等
预计将在LLMs的应用和使用方面进行持续和加速的研究,如个性化推荐、多代理系统等
E. Security and Ethical/Responsible AI安全和道德/负责任的人工智能:保障LLM模型安全性,减少对抗攻击,并注重LLM的公平性和负责任
需要研究确保LLMs对抗攻击和其他漏洞的稳健性和安全性,以防止它们被用于操纵人们或传播错误信息
正在努力解决LLMs的道德关切和偏见问题,以确保它们公平、无偏见,并能够负责任地处理敏感信息
Open Source Toolkits For LLM Development and Deployment用于LLM开发和部署的开源工具包
A. LLM Training/Inference Frameworks训练/推理框架
DeepSpeed、Transformers、Megatron-LM、BMTrain
FastChat、Skypilot、vLLM、text-generation-inference、LangChain、Are context-aware
OpenLLM、Embedchain、Autogen、BabyAGI
Guidance、PromptTools、PromptBench、Promptfoo
Faiss、Milvus、Qdrant、Weaviate、LlamaIndex、Pinecone
《Large Language Models A Survey大型语言模型的综述调查》翻译与解读
| 地址 | |
| 时间 | 2024年2月9日 |
| 作者 | Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, Jianfeng Gao |
| 总结 |
Abstract摘要
| Abstract—Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs’ ability of general-purpose language understanding and generation is acquired by training billions of model’s parameters on massive amounts of text data, as predicted by scaling laws [1], [2]. The research area of LLMs, while very recent, is evolving rapidly in many different ways. In this paper, we review some of the most prominent LLMs, including three popular LLM families (GPT, LLaMA, PaLM), and discuss their characteristics, contributions and limitations. We also give an overview of techniques developed to build, and augment LLMs. We then survey popular datasets prepared for LLM training, fine-tuning, and evaluation, review widely used LLM evaluation metrics, and compare the performance of several popular LLMs on a set of representative benchmarks. Finally, we conclude the paper by discussing open challenges and future research directions. | 自2022年11月ChatGPT发布以来,大型语言模型(LLM)因其在广泛的自然语言任务上的出色表现而引起了广泛的关注。LLM的通用语言理解和生成能力是通过在大量文本数据上训练数十亿个模型的参数来获得的,正如缩放定律所预测的那样[1],[2]。LLMs的研究领域虽然很新,但在许多不同方面迅速发展。在本文中,我们回顾了一些最著名的LLM,包括三个流行的LLM家族(GPT, LLaMA, PaLM),并讨论了它们的特点、贡献和局限性。我们还概述了用于构建和增强LLMs的技术。然后,我们调查了为LLMs训练、微调和评估而准备的流行数据集,回顾了广泛使用的LLMs评估指标,并比较了几种流行LLMs在一组代表性基准上的性能。最后,对本文的研究方向和面临的挑战进行了展望。 |
I. INTRODUCTION引言
| Language modeling is a long-standing research topic, dating back to the 1950s with Shannon’s application of information theory to human language, where he measured how well simple n-gram language models predict or compress natural language text [3]. Since then, statistical language modeling became fundamental to many natural language understanding and generation tasks, ranging from speech recognition, machine translation, to information retrieval [4], [5], [6]. | 语言建模是一个长期存在的研究课题,可以追溯到20世纪50年代,香农将信息论应用于人类语言的时候,他测量了简单n-gram语言模型预测或压缩自然语言文本的效果[3]。自那时以来,统计语言建模成为许多自然语言理解和生成任务的基础,范围从语音识别、机器翻译到信息检索[4]、[5]、[6]。 |
| The recent advances on transformer-based large language models (LLMs), pretrained on Web-scale text corpora, significantly extended the capabilities of language models (LLMs). For example, OpenAI’s ChatGPT and GPT-4 can be used not only for natural language processing, but also as general task solvers to power Microsoft’s Co-Pilot systems, for instance, can follow human instructions of complex new tasks performing multi-step reasoning when needed. LLMs are thus becoming the basic building block for the development of general-purpose AI agents or artificial general intelligence (AGI). | 最近基于Transformer的大型语言模型(LLMs)在Web规模文本语料库上预训练的进展,显着扩展了语言模型的能力。例如,OpenAI的ChatGPT和GPT-4不仅可以用于自然语言处理,还可以作为通用任务解决器,为微软的Co-Pilot系统提供动力,例如,可以在需要时遵循人类对复杂新任务的指令执行多步推理。。因此,LLM正在成为开发通用人工智能代理或通用人工智能(AGI)的基本构建块。 |
| As the field of LLMs is moving fast, with new findings, models and techniques being published in a matter of months or weeks [7], [8], [9], [10], [11], AI researchers and practitioners often find it challenging to figure out the best recipes to build LLM-powered AI systems for their tasks. This paper gives a timely survey of the recent advances on LLMs. We hope this survey will prove a valuable and accessible resource for students, researchers and developers. | 由于LLMs领域发展迅速,新的发现、模型和技术以几个月甚至几周的速度发布,因此人工智能研究人员和从业者常常发现很难找出为其任务构建LLM驱动的人工智能系统的最佳方法。本文及时调查了LLMs的最新进展。我们希望这项调查能成为学生、研究人员和开发人员宝贵且易于获取的资源。 |
Fig. 1: LLM Capabilities.
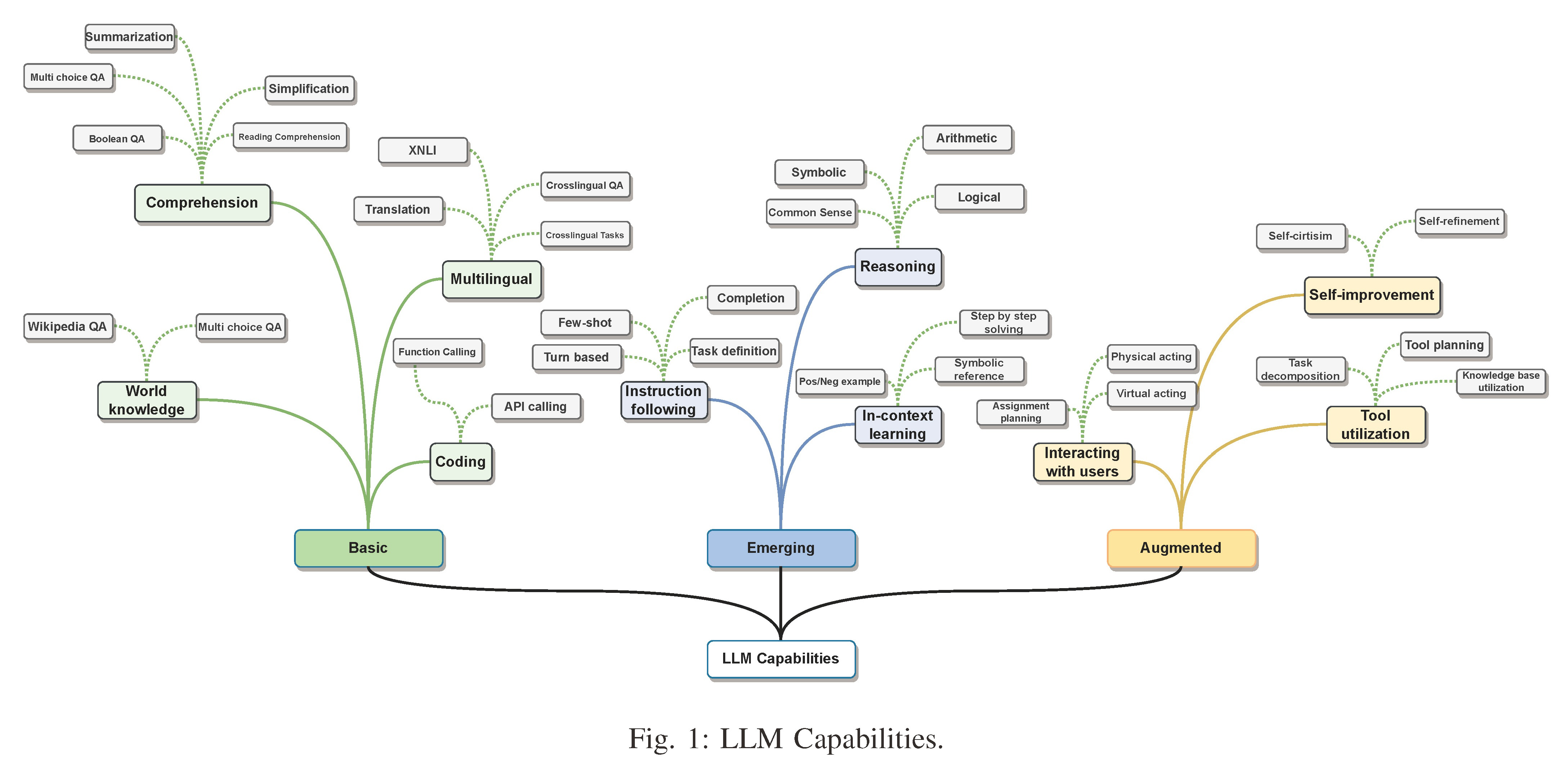
四波浪潮:SLM(统计语言模型)→NLM(神经语言模型)→PLM(预训练语言模型)→LLM(大语言模型)
| LLMs are large-scale, pre-trained, statistical language models based on neural networks. The recent success of LLMs is an accumulation of decades of research and development of language models, which can be categorized into four waves that have different starting points and velocity: statistical language models, neural language models, pre-trained language models and LLMs. | LLM是基于神经网络的大规模、预训练的统计语言模型。LLMs的最近成功是对语言模型研究和开发数十年积累的成果,可以分为四波浪潮:统计语言模型、神经语言模型、预训练语言模型和LLM,它们有不同的起点和速度。 |
SLM
| Statistical language models (SLMs) view text as a sequence of words, and estimate the probability of text as the product of their word probabilities. The dominating form of SLMs are Markov chain models known as the n-gram models, which compute the probability of a word conditioned on its immediate proceeding n − 1 words. Since word probabilities are estimated using word and n-gram counts collected from text corpora, the model needs to deal with data sparsity (i.e., assigning zero probabilities to unseen words or n-grams) by using smoothing, where some probability mass of the model is reserved for unseen n-grams [12]. N-gram models are widely used in many NLP systems. However, these models are incomplete in that they cannot fully capture the diversity and variability of natural language due to data sparsity. | >> 统计语言模型(SLM)将文本视为一系列单词,并估计文本的概率为它们单词概率的乘积。将文本视为单词序列。SLM的主要形式是被称为n-gram模型的马尔可夫链模型,它计算一个单词在其直接前n-1个单词的条件下出现的概率。由于单词概率是使用从文本语料库中收集的单词和n-gram计数来估计的,因此模型需要通过使用平滑来处理数据稀疏性(即为未见过的单词或n-gram分配零概率),其中模型的一些概率质量为未见过的n-gram保留[12]。N-gram模型广泛应用于许多自然语言处理系统。然而,这些模型是不完整的,因为由于数据稀疏性,它们无法充分捕捉自然语言的多样性和可变性。 |
NLM
| Early neural language models (NLMs) [13], [14], [15], [16] deal with data sparsity by mapping words to low-dimensional continuous vectors (embedding vectors) and predict the next word based on the aggregation of the embedding vectors of its proceeding words using neural networks. The embedding vectors learned by NLMs define a hidden space where the semantic similarity between vectors can be readily computed as their distance. This opens the door to computing semantic similarity of any two inputs regardless their forms (e.g., queries vs. documents in Web search [17], [18], sentences in different languages in machine translation [19], [20]) or modalities (e.g., image and text in image captioning [21], [22]). Early NLMs are task-specific models, in that they are trained on task-specific data and their learned hidden space is task-specific. | >> 早期的神经语言模型(NLMs)[13],[14],[15],[16]通过将单词映射到低维连续向量(嵌入向量)来处理数据稀疏性,并使用神经网络基于其前一个单词的嵌入向量的聚合来预测下一个单词。NLM学习的嵌入向量定义了一个隐藏空间,在这个空间中,向量之间的语义相似度可以很容易地计算为它们之间的距离。这为计算任意两个输入的语义相似度打开了大门,而不管它们的形式(例如,网络搜索中的查询与文档,语言翻译中不同语言中的句子)还是模态(例如,图像和文本在图像字幕中)。早期的NLM是特定于任务的模型,因为它们是在特定于任务的数据上训练的,它们学习到的隐藏空间是特定于任务的。 |
PLM
| Pre-trained language models (PLMs), unlike early NLMs, are task-agnostic. This generality also extends to the learned hidden embedding space. The training and inference of PLMs follows the pre-training and fine-tuning paradigm, where language models with recurrent neural networks [23] or transformers [24], [25], [26] are pre-trained on Web-scale unlabeled text corpora for general tasks such as word prediction, and then finetuned to specific tasks using small amounts of (labeled) task-specific data. Recent surveys on PLMs include [8], [27], [28]. | >> 预训练语言模型(PLMs),与早期的NLMs不同,是任务无关的。这种通用性也延伸到了学习的隐藏嵌入空间。PLM的训练和推理遵循预训练和微调范式,其中使用RNN[23]或Transformer[24],[25],[26]的语言模型在web规模的未标记文本语料库上进行预训练,用于单词预测等一般任务,然后使用少量(标记的)特定任务数据对特定任务进行微调。最近关于PLM的调查包括[8],[27],[28]。 |
LLM:优于PLM的三大特点(规模更大/语言理解和生成能力更强/新兴能力【CoT/IF/MSR】),也可使用外部工具来增强和交互(收集反馈数据然后不断改进自身)
| Large language models (LLMs) mainly refer to transformer-based neural language models 1 that contain tens to hundreds of billions of parameters, which are pretrained on massive text data, such as PaLM [31], LLaMA [32], and GPT-4 [33], as summarized in Table III. Compared to PLMs, LLMs are not only much larger in model size, but also exhibit stronger language understanding and generation abilities, and more importantly, emergent abilities that are not present in smaller-scale language models. As illustrated in Fig. 1, these emergent abilities include (1) in-context learning, where LLMs learn a new task from a small set of examples presented in the prompt at inference time, (2) instruction following, where LLMs, after instruction tuning, can follow the instructions for new types of tasks without using explicit examples, and (3) multi-step reasoning, where LLMs can solve a complex task by breaking down that task into intermediate reasoning steps as demonstrated in the chain-of-thought prompt [34]. LLMs can also be augmented by using external knowledge and tools [35], [36] so that they can effectively interact with users and environment [37], and continually improve itself using feedback data collected through interactions (e.g. via reinforcement learning with human feedback (RLHF)). | >> 大型语言模型(Large language models, LLM)主要是指基于Transformer的神经语言模型,包含数百亿到数千亿个参数,这些模型在大规模文本数据上进行了预训练,例如PaLM [31],LLaMA [32]和GPT-4 [33],如表3所总结。与PLMs相比,LLMs不仅在模型规模上更大,而且在语言理解和生成能力上更强,更重要的是,在规模较小的语言模型中不存在的新兴能力。如图1所示,这些突现能力包括 (1)上下文学习,LLMs在推断时通过提示中呈现的少量示例学习新任务, (2)遵循指令,经过指令调整后,LLMs可以按照新类型任务的指令执行任务,而无需使用明确的示例,以及 (3)多步推理。LLMs可以通过将任务分解为中间推理步骤来解决复杂任务,如链式思维提示中所示[34]。 LLM也可以通过使用外部知识和工具来增强[35],[36],这样它们就可以有效地与用户和环境进行交互[37],并使用通过交互收集的反馈数据(例如通过人类反馈的强化学习(RLHF))不断改进自身。 |
基于LLM的AI代理
| Through advanced usage and augmentation techniques, LLMs can be deployed as so-called AI agents: artificial entities that sense their environment, make decisions, and take actions. Previous research has focused on developing agents for specific tasks and domains. The emergent abilities demonstrated by LLMs make it possible to build general-purpose AI agents based on LLMs. While LLMs are trained to produce responses in static settings, AI agents need to take actions to interact with dynamic environment. Therefore, LLM-based agents often need to augment LLMs to e.g., obtain updated information from external knowledge bases, verify whether a system action produces the expected result, and cope with when things do not go as expected, etc. We will discuss in detail LLM-based agents in Section IV. | 通过先进的使用和增强技术,LLM可以被部署为所谓的AI代理:感知环境、做出决策并采取行动的人工实体。以前的研究主要集中在开发特定任务和领域的代理。LLM所展示的涌现能力使得基于LLM构建通用人工智能代理成为可能。虽然LLMs经过训练以在静态设置中产生响应,但AI代理需要采取行动以与动态环境交互。因此,基于LLMs的代理通常需要增强LLMs,以获取来自外部知识库的更新信息,验证系统行动是否产生预期结果,并处理事情不如预期时的情况等。我们将在第四部分详细讨论基于LLMs的代理。 |
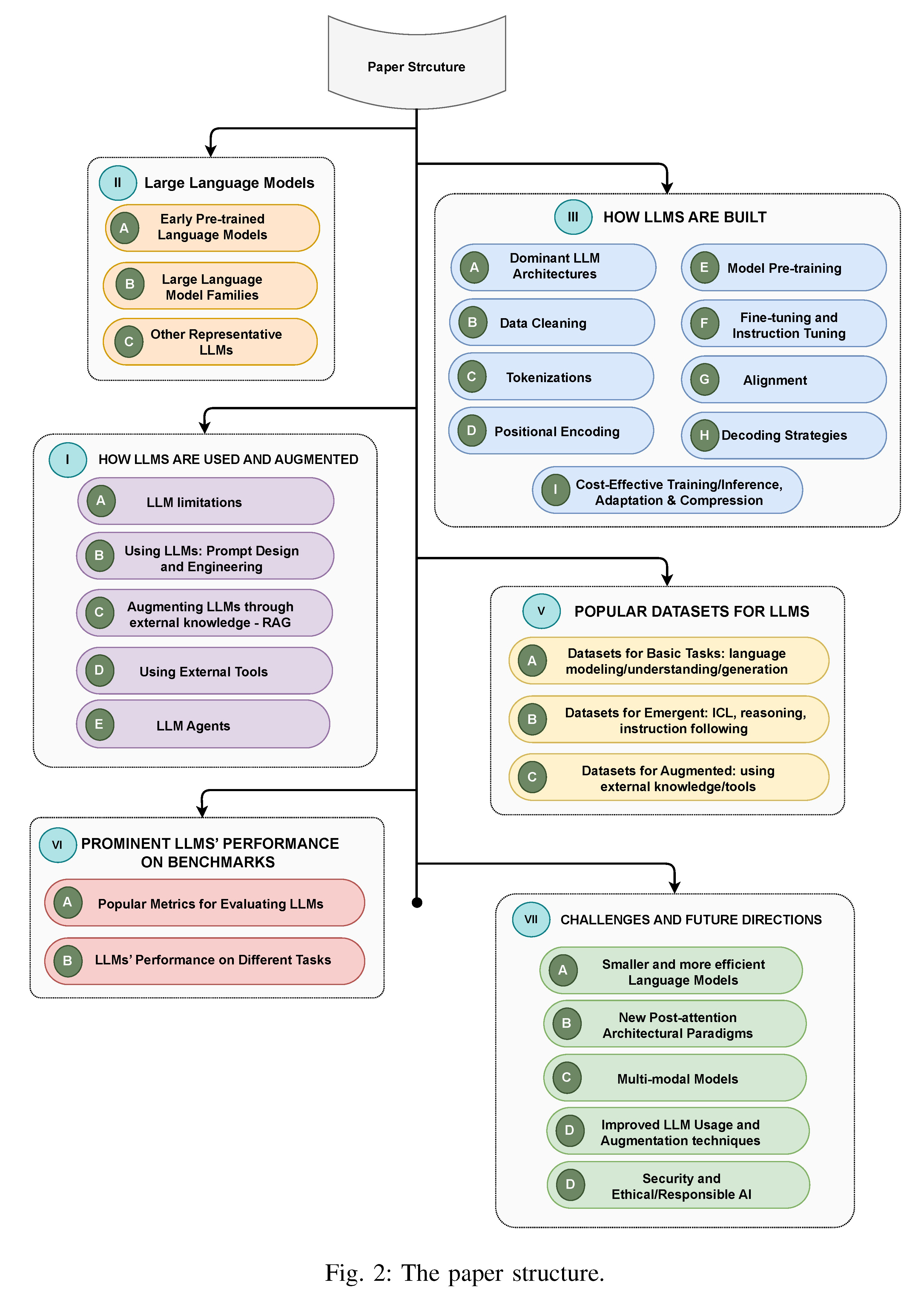
本文结构:第二部分(LLMs的最新技术)→第三部分(如何构建LLMs)→第四部分(LLMs的用途)→第五和第六部分(评估LLMs的流行数据集和基准)→第七部分(面临的挑战和未来方向)
| In the rest of this paper, Section II presents an overview of state of the art of LLMs, focusing on three LLM families (GPT, LLaMA and PaLM) and other representative models. Section III discusses how LLMs are built. Section IV discusses how LLMs are used, and augmented for real-world applications Sections V and VI review popular datasets and benchmarks for evaluating LLMs, and summarize the reported LLM evaluation results. Finally, Section VII concludes the paper by summarizing the challenges and future research directions. | 在本文的其余部分中,第二部分概述了LLMs的最新技术,重点介绍了三个LLMs系列(GPT、LLaMA和PaLM)和其他代表性模型。第三部分讨论了LLMs是如何构建的。第四部分讨论了LLMs的用途,并增强了用于现实世界应用的LLMs。第五和第六部分回顾了用于评估LLMs的流行数据集和基准,并总结了报告的LLMs评估结果。最后,第七部分总结了本文面临的挑战和未来的研究方向。 |
Fig. 2: The paper structure.
II. LARGE LANGUAGE MODELS大型语言模型
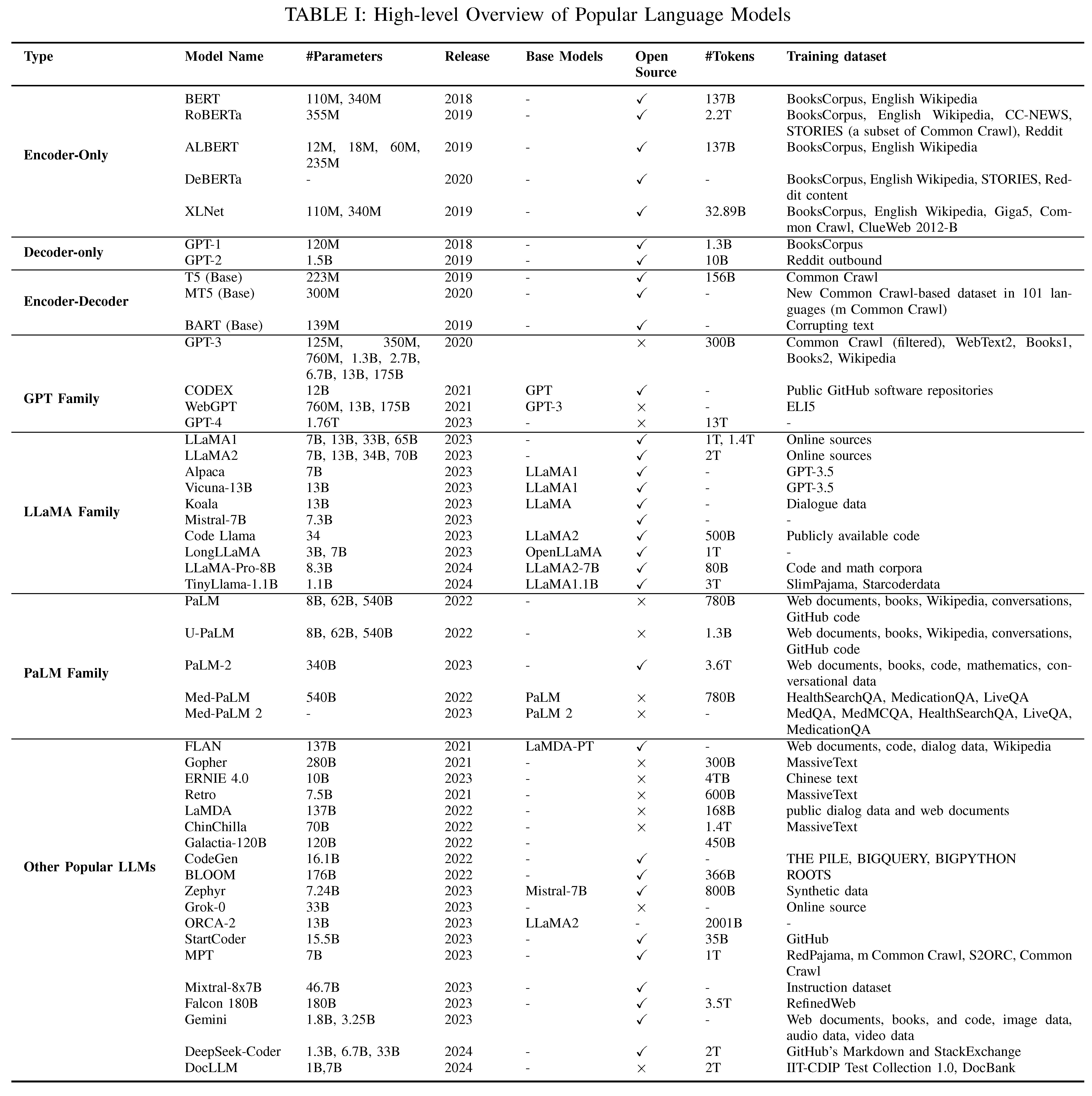
| In this section we start with a review of early pre-trained neural language models as they are the base of LLMs, and then focus our discussion on three families of LLMs: GPT, LlaMA, and PaLM. Table I provides an overview of some of these models and their characteristics. | 在本节中,我们首先回顾早期预训练的神经语言模型,因为它们是LLM的基础,然后重点讨论三个LLM家族:GPT, LlaMA和PaLM。表1提供了其中一些模型及其特征的概述。 |
TABLE I: High-level Overview of Popular Language Models
A. Early Pre-trained Neural Language Models早期预训练的神经语言模型
Bengio等人开发第一个NLM→Mikolov等人发布了RNNLM→基于RNN的变体(如LSTM和GRU),被广泛用于许多自然语言应用,包括机器翻译、文本生成和文本分类
| Language modeling using neural networks was pioneered by [38], [39], [40]. Bengio et al. [13] developed one of the first neural language models (NLMs) that are comparable to n-gram models. Then, [14] successfully applied NLMs to machine translation. The release of RNNLM (an open source NLM toolkit) by Mikolov [41], [42] helped significantly popularize NLMs. Afterwards, NLMs based on recurrent neural networks (RNNs) and their variants, such as long short-term memory (LSTM) [19] and gated recurrent unit (GRU) [20], were widely used for many natural language applications including machine translation, text generation and text classification [43]. | 使用神经网络进行语言建模是由[38],[39],[40]开创的。 >> Bengio等人[13]开发了第一个可与n-gram模型相媲美的神经语言模型(NLM)。然后,[14]成功地将NLM应用于机器翻译。 >> Mikolov[41],[42]发布的RNNLM(一个开源的NLM工具包)极大地促进了NLM的普及。 >> 之后,基于循环神经网络(RNN)及其变体的NLM,如长短期记忆(LSTM)和门控循环单元(GRU),被广泛用于许多自然语言应用,包括机器翻译、文本生成和文本分类。 |
诞生Transformer架构:NLM新的里程碑,比RNN更多的并行化+采用GPU+下游微调
| Then, the invention of the Transformer architecture [44] marks another milestone in the development of NLMs. By applying self-attention to compute in parallel for every word in a sentence or document an “attention score” to model the influence each word has on another, Transformers allow for much more parallelization than RNNs, which makes it possible to efficiently pre-train very big language models on large amounts of data on GPUs. These pre-trained language models (PLMs) can be fine-tuned for many downstream tasks. | 然后,Transformer架构的发明[44]标志着NLM发展的另一个里程碑。通过应用自注意力机制来并行计算句子中的每个单词,或者记录一个“注意力分数”来模拟每个单词对另一个单词的影响,Transformers允许比RNN更多的并行化,这使得可以在GPU上有效地对大量数据进行预训练非常大的语言模型。这些预训练语言模型(PLMs)可以针对许多下游任务进行微调。 |
基于Transformer的PLMs三大类:仅编码器、仅解码器和编码器-解码器模型
| We group early popular Transformer-based PLMs, based on their neural architectures, into three main categories: encoderonly, decoder-only, and encoder-decoder models. Comprehensive surveys of early PLMs are provided in [43], [28]. | 根据它们的神经结构,我们将早期流行的基于Transformer的PLMs分为三大类:仅编码器、仅解码器和编码器-解码器模型。文献[43]、[28]对早期PLM进行了全面调查。 |
1)、仅编码器PLMs:只包含一个编码器网络、适合语言理解任务(比如文本分类)、使用掩码语言建模和下一句预测等目标进行预训练
| 1) Encoder-only PLMs: As the name suggests, the encoderonly models only consist of an encoder network. These models are originally developed for language understanding tasks, such as text classification, where the models need to predict a class label for an input text. Representative encoder-only models include BERT and its variants, e.g., RoBERTa, ALBERT, DeBERTa, XLM, XLNet, UNILM, as to be described below. | 1)仅编码器PLMs:正如名称所示,仅编码器模型只包含一个编码器网络。这些模型最初是为语言理解任务开发的,例如文本分类,在这些任务中,模型需要预测输入文本的类别标签。代表性的仅编码器模型包括BERT及其变体,例如RoBERTa、ALBERT、DeBERTa、XLM、XLNet、UNILM等。如下所述。 |
BERT:3个模块(嵌入模块+Transformer编码器堆栈+全连接层)、2个任务(MLM和NSP),可添加一个分类器层实现多种语言理解任务,显著提高并成为仅编码器语言模型的基座
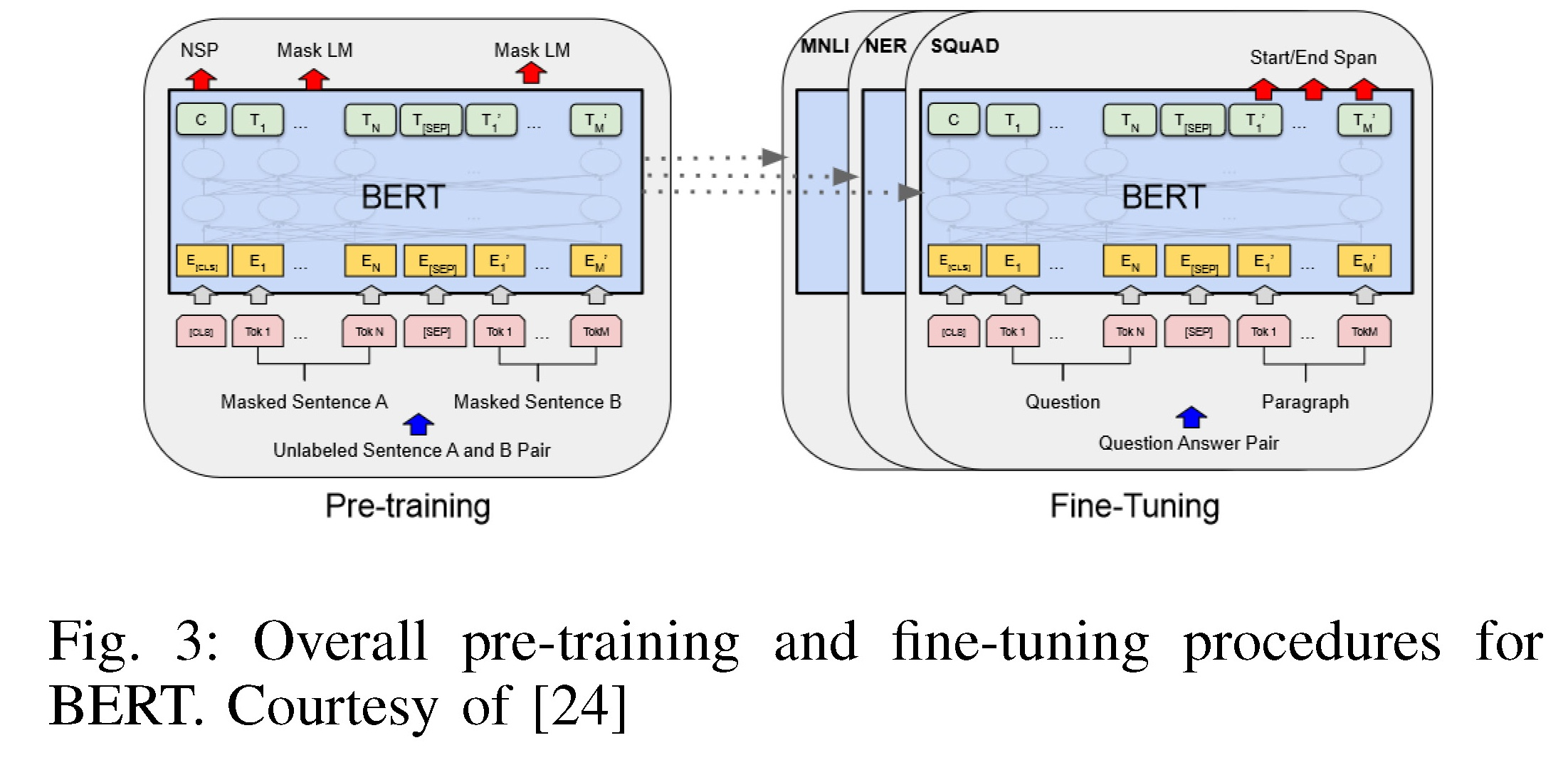
| BERT (Birectional Encoder Representations from Transformers) [24] is one of the most widely used encoder-only language models. BERT consists of three modules: (1) an embedding module that converts input text into a sequence of embedding vectors, (2) a stack of Transformer encoders that converts embedding vectors into contextual representation vectors, and (3) a fully connected layer that converts the representation vectors (at the final layer) to one-hot vectors. BERT is pre-trained uses two objectives: masked language modeling (MLM) and next sentence prediction. The pre-trained BERT model can be fine-tuned by adding a classifier layer for many language understanding tasks, ranging from text classification, question answering to language inference. A high-level overview of BERT framework is shown in Fig 3. As BERT significantly improved state of the art on a wide range of language understanding tasks when it was published, the AI community was inspired to develop many similar encoder-only language models based on BERT. | BERT (Birectional Encoder Representations from Transformers)[24]是最广泛使用的仅编码器语言模型之一。BERT由三个模块组成: (1)将输入文本转换为嵌入向量序列的嵌入模块, (2)一堆Transformer编码器,将嵌入向量转换为上下文表示向量,以及 (3)一个完全连接的层,将表示向量(在最终层)转换为one-hot向量。 BERT的预训练使用两个目标:掩模语言建模(MLM)和下一句预测(NSP)。 预训练的BERT模型可以通过添加一个分类器层进行许多语言理解任务(从文本分类、问答到语言推理)的微调。 BERT框架的高级概述如图3所示。由于BERT在发布时显著提高了广泛的语言理解任务的技术水平,人工智能社区受到启发,基于BERT开发了许多类似的仅编码器语言模型 |
Fig. 3: Overall pre-training and fine-tuning procedures for BERT. Courtesy of [24]
RoBERTa(提高鲁棒性=修改关键超参数+删除NSP+更大的微批量和学习率)、ALBERT(降耗提速=嵌入矩阵拆分+使用组间分割的重复层)、DeBERTa(两种技术【解缠注意力机制+增强的掩码解码器】+新颖的虚拟对抗训练方法来微调)
| RoBERTa [25] significantly improves the robustness of BERT using a set of model design choices and training strategies, such as modifying a few key hyperparameters, removing the next-sentence pre-training objective and training with much larger mini-batches and learning rates. ALBERT [45] uses two parameter-reduction techniques to lower memory consumption and increase the training speed of BERT: (1) splitting the embedding matrix into two smaller matrices, and (2) using repeating layers split among groups. DeBERTa (Decodingenhanced BERT with disentangled attention) [26] improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position, respectively, and the attention weights among words are computed using disentangled matrices on their contents and relative positions, respectively. Second, an enhanced mask decoder is used to incorporate absolute positions in the decoding layer to predict the masked tokens in model pre-training. In addition, a novel virtual adversarial training method is used for fine-tuning to improve models’ generalization. | >> RoBERTa[25]使用一组模型设计选择和训练策略显著提高了BERT的鲁棒性,例如修改几个关键的超参数,删除下一个句子的预训练目标以及使用更大的微批量和学习率进行训练。 >> ALBERT[45]使用两种参数约简技术来降低内存消耗并提高BERT的训练速度:(1)将嵌入矩阵拆分为两个较小的矩阵,(2)使用在各组之间分割的重复层。 >> DeBERTa (增强的解码BERT与解缠注意力)[26]利用两种新技术改进了BERT和RoBERTa模型。第一个是解缠注意力机制,其中每个单词使用两个向量来编码其内容和位置,而单词之间的注意力权重使用关于它们的内容和相对位置的解缠矩阵进行计算。其次,在解码层中使用了增强的掩码解码器来预测模型预训练中的掩码token。此外,还使用了一种新颖的虚拟对抗训练方法来进行微调,以提高模型的泛化能力。 |
ELECTRA(提出RTD替换MLM任务+小型生成器网络+训练一个判别模型)、XLM(两种方法将BERT扩展到跨语言语言模型=仅依赖于单语数据的无监督方法+利用平行数据的监督方法)
| ELECTRA [46] uses a new pre-training task, known as replaced token detection (RTD), which is empirically proven to be more sample-efficient than MLM. Instead of masking the input, RTD corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead of training a model that predicts the original identities of the corrupted tokens, a discriminative model is trained to predict whether a token in the corrupted input was replaced by a generated sample or not. RTD is more sample-efficient than MLM because the former is defined over all input tokens rather than just the small subset being masked out, as illustrated in Fig 4. XLMs [47] extended BERT to cross-lingual language models using two methods: (1) a unsupervised method that only relies on monolingual data, and (2) a supervised method that leverages parallel data with a new cross-lingual language model objective, as illustrated in Fig 5. XLMs had obtained state-of-the-art results on cross-lingual classification, unsupervised and supervised machine translation, at the time they were proposed. | >> ELECTRA[46]使用了一种新的预训练任务,称为替换标记检测(RTD),经验上证明比MLM更具样本效率。RTD不是对输入进行屏蔽,而是用从小型生成器网络中采样的合理替代方案替换一些标记,从而破坏输入。然后,与其训练一个模型来预测受损标记的原始标识相反,训练了一个判别模型来预测损坏输入中的令牌是否被生成的样本取代。RTD比MLM更具样本效率,因为前者是基于所有输入标记而不仅仅是被屏蔽的小子集来定义的,如图4所示。 >> XLM[47]使用两种方法将BERT扩展到跨语言语言模型: (1)一种仅依赖于单语数据的无监督方法, (2)一种利用新的跨语言语言模型目标并利用平行数据的监督方法,如图5所示。在提出XLM时,它们已经在跨语言分类、无监督和有监督机器翻译方面获得了最先进的结果。 |
Fig. 4: A comparison between replaced token detection and masked language modeling. Courtesy of [46].
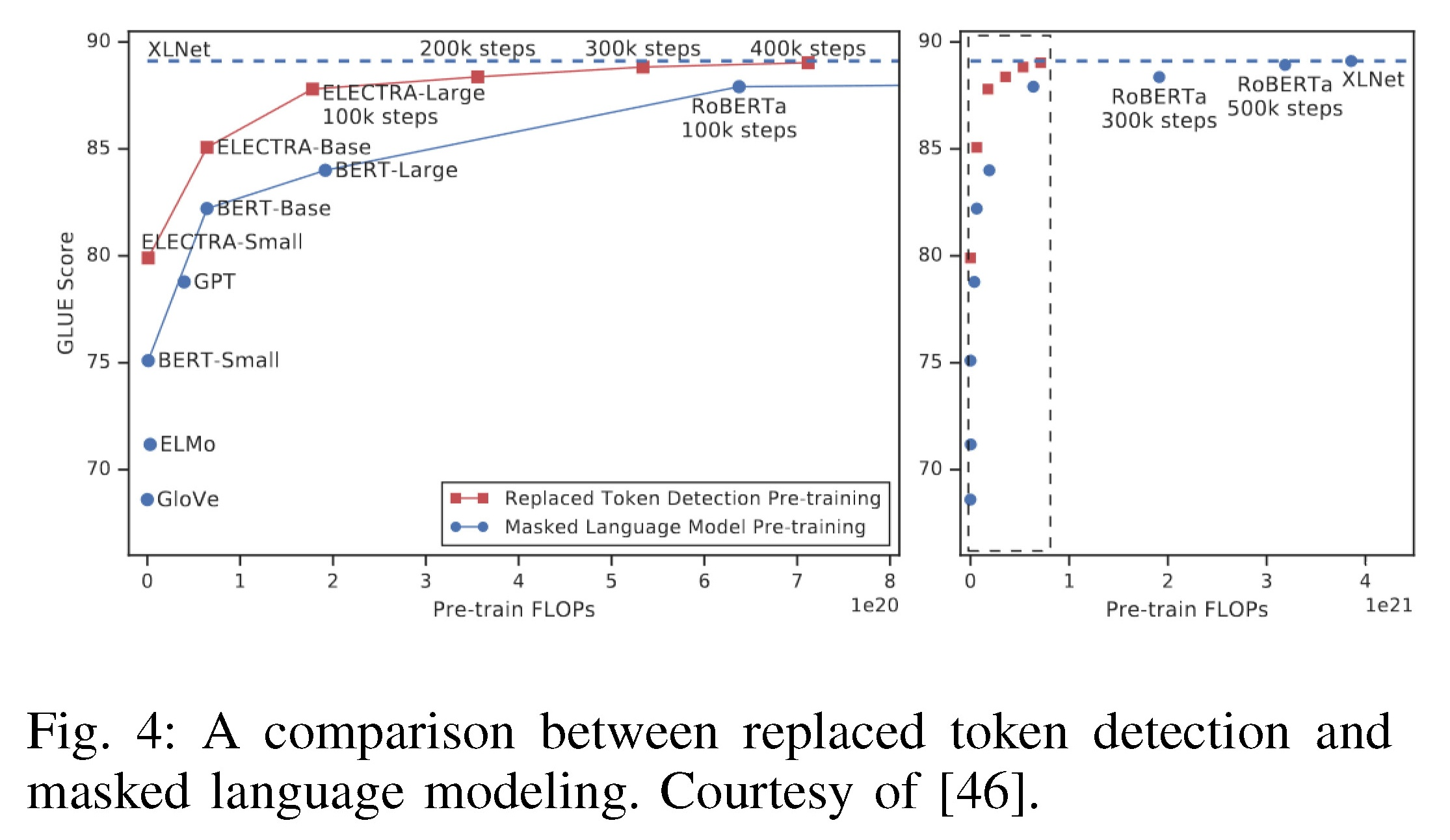
Fig. 5: Cross-lingual language model pretraining. The MLM objective is similar to BERT, but with continuous streams of text as opposed to sentence pairs. The TLM objective extends MLM to pairs of parallel sentences. To predict a masked English word, the model can attend to both the English sentence and its French translation, and is encouraged to align English and French representations. Courtesy of [47].

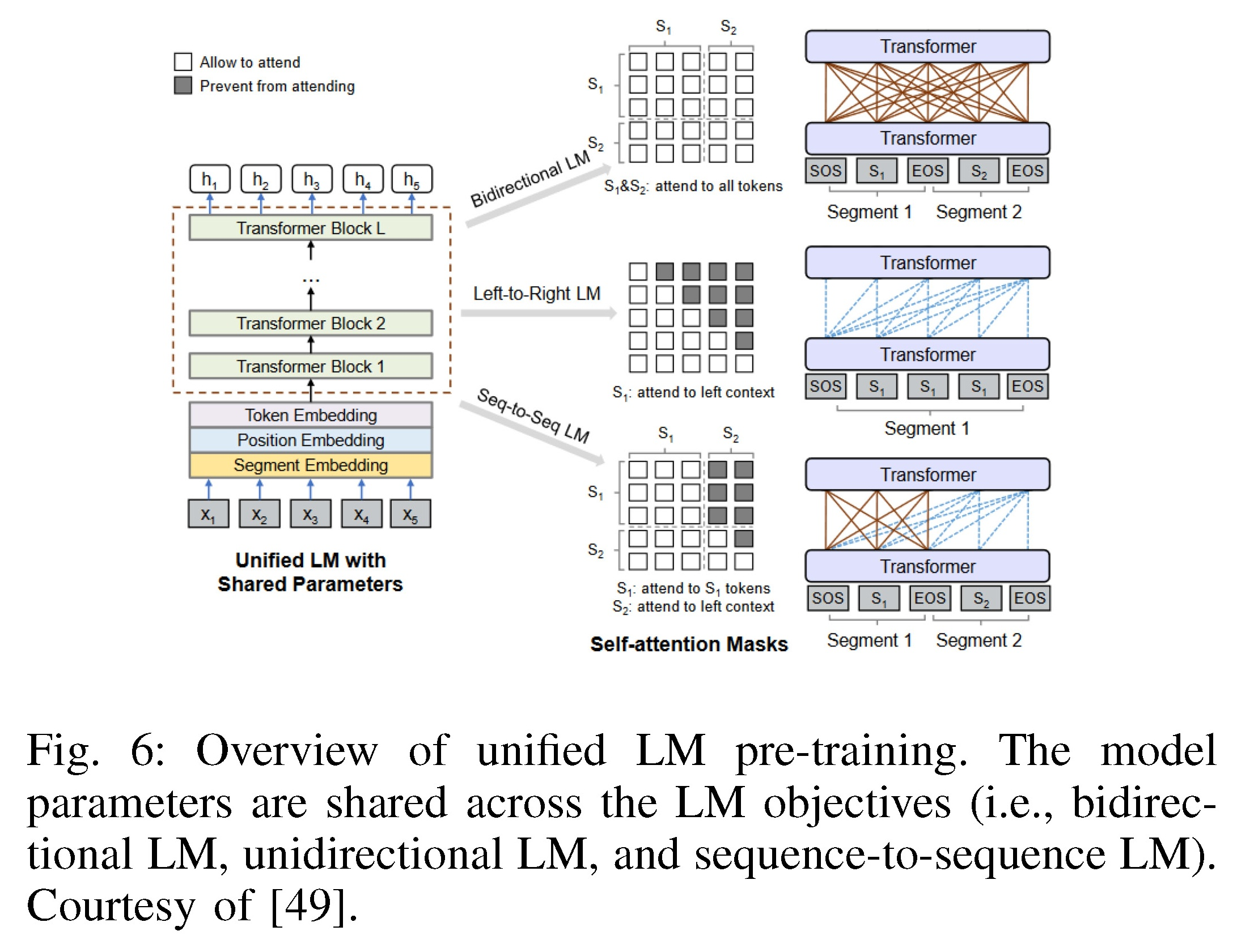
利用自回归(解码器)模型的优点的一些仅编码器:XLNet(基于Transformer-XL+预训练采用广义自回归+MLM中采用连续的文本流而非句子对+TLM将MLM扩展到平行句对)、UNILM(统一三种类型的语言建模任务=单向/双向/序列到序列预测)
| There are also encoder-only language models that leverage the advantages of auto-regressive (decoder) models for model training and inference. Two examples are XLNet and UNILM. XLNet [48] is based on Transformer-XL, pre-trained using a generalized autoregressive method that enables learning bidirectional contexts by maximizing the expected likelihood over Fig. 5: Cross-lingual language model pretraining. The MLM objective is similar to BERT, but with continuous streams of text as opposed to sentence pairs. The TLM objective extends MLM to pairs of parallel sentences. To predict a masked English word, the model can attend to both the English sentence and its French translation, and is encouraged to align English and French representations. Courtesy of [47]. all permutations of the factorization order. UNILM (UNIfied pre-trained Language Model) [49] is pre-trained using three types of language modeling tasks: unidirectional, bidirectional, and sequence-to-sequence prediction. This is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction is conditioned on, as illustrated in Fig 6. The pre-trained model can be fine-tuned for both natural language understanding and generation tasks. Fig. 6: Overview of unified LM pre-training. The model parameters are shared across the LM objectives (i.e., bidirectional LM, unidirectional LM, and sequence-to-sequence LM). Courtesy of [49]. | 还有一些仅编码器的语言模型,利用自回归(解码器)模型的优点进行模型训练和推理。其中两个例子是XLNet和UNILM。 >> XLNet[48]基于Transformer-XL,使用广义自回归方法进行预训练,可以通过最大化图5:跨语言模型预训练的期望似然来学习双向上下文。MLM的目标类似于BERT,但是使用连续的文本流,而不是句子对。TLM的目标是将MLM扩展到平行句对。为了预测一个被屏蔽的英文单词,模型可以同时关注英文句子及其法语翻译,并被鼓励对齐英语和法语表示。由[47]提供。分解顺序的所有排列。 >> UNILM (UNIfied pre-trained Language Model,统一预训练语言模型)[49]使用三种类型的语言建模任务进行预训练:单向、双向和序列到序列预测。这是通过使用共享的Transformer网络和利用特定的自注意力掩码来控制预测所依赖的上下文实现的,如图6所示。预训练的模型可以对自然语言理解和生成任务进行微调。图6:统一LM预训练概述。模型参数在LM目标之间共享(即双向LM、单向LM和序列到序列LM)。由[49]提供。 |
Fig. 6: Overview of unified LM pre-training. The model parameters are shared across the LM objectives (i.e., bidirec-tional LM, unidirectional LM, and sequence-to-sequence LM). Courtesy of [49].
2)、仅解码器PLMs:
| 2) Decoder-only PLMs: Two of the most widely used decoder-only PLMs are GPT-1 and GPT-2, developed by OpenAI. These models lay the foundation to more powerful LLMs subsequently, i.e., GPT-3 and GPT-4. | 2)仅解码器PLMs:两个最广泛使用的纯解码器PLM是由OpenAI开发的GPT-1和GPT-2。这些模型为后来更强大的LLM,即GPT-3和GPT-4奠定了基础。 |
Fig. 7: High-level overview of GPT pretraining, and fine-tuning steps. Courtesy of OpenAI.
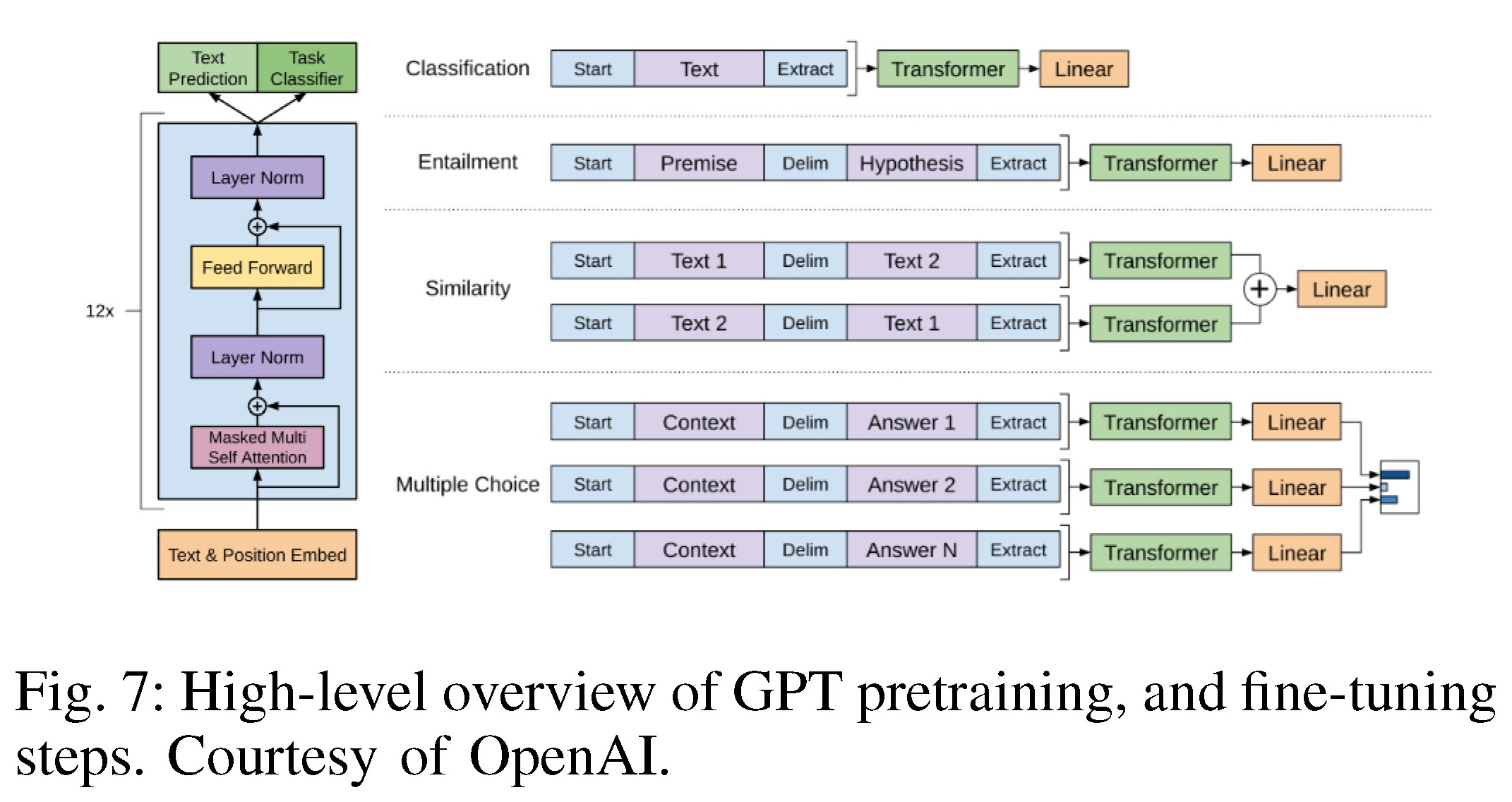
GPT-1:基于仅解码器的Transformer+生成式预训练【无标签语料库+自监督学习】+微调【下游任务有区别的微调】
| GPT-1 [50] demonstrates for the first time that good performance over a wide range of natural language tasks can be obtained by Generative Pre-Training (GPT) of a decoder-only Transformer model on a diverse corpus of unlabeled text in a self-supervised learning fashion (i.e., next word/token predic-tion), followed by discriminative fine-tuning on each specific downstream task (with much fewer samples), as illustrated in Fig 7. GPT-1 paves the way for subsequent GPT models, with each version improving upon the architecture and achieving better performance on various language tasks. | GPT-1[50]首次证明,在各种未标记文本语料库上,通过自监督学习方式(即下一个单词/token预测)对仅解码器的Transformer模型进行生成式预训练(GPT),可以在广泛的自然语言任务上获得良好的性能,然然后在每个具体的下游任务上进行有区别的微调(样本数量少的多),如图7所示。GPT-1为后续的GPT模型铺平了道路,每个版本都对架构进行了改进,并在各种语言任务上实现了更好的性能。 |
GPT-2:基于数百万网页的WebText数据集+遵循GPT-1的模型设计+将层归一化移动到每个子块的输入处+自关注块之后添加额外的层归一化+修改初始化+词汇量扩展到5025+上下文扩展到1024
| GPT-2 [51] shows that language models are able to learn to perform specific natural language tasks without any explicit supervision when trained on a large WebText dataset consisting of millions of webpages. The GPT-2 model follows the model designs of GPT-1 with a few modifications: Layer normalization is moved to the input of each sub-block, additional layer normalization is added after the final self-attention block, initialization is modified to account for the accumulation on the residual path and scaling the weights of residual layers, vocabulary size is expanded to 50,25, and context size is increased from 512 to 1024 tokens. | GPT-2[51]表明,在由数百万个网页组成的大型WebText数据集上训练时,语言模型能够在没有任何明确监督的情况下学习执行特定的自然语言任务。GPT-2模型遵循GPT-1的模型设计,但做了一些修改:将层归一化移动到每个子块的输入处,在最终的自关注块之后添加额外的层归一化,修改初始化以考虑残差路径上的积累和残差层的权重缩放,词汇量扩展到5025,上下文大小从512增加到1024。 |
3)、编码器-解码器PLMs:
| 3) Encoder-Decoder PLMs: In [52], Raffle et al. shows that almost all NLP tasks can be cast as a sequence-to-sequence generation task. Thus, an encoder-decoder language model, by design, is a unified model in that it can perform all natural language understanding and generation tasks. Representative encoder-decoder PLMs we will review below are T5, mT5, MASS, and BART. | 3)编码器-解码器PLMs:在[52]中,Raffle等人表明,几乎所有的NLP任务都可以转换为序列到序列的生成任务。因此,编码器-解码器语言模型在设计上是一个统一的模型,因为它可以执行所有自然语言理解和生成任务。我们将在下面回顾的编码器-解码器PLMs包括T5, mT5, MASS和BART。 |
T5(将所有NLP任务都视为文本到文本生成任务)、mT5(基于T5的多语言变体+101种语言)
| T5 [52] is a Text-to-Text Transfer Transformer (T5) model, where transfer learning is effectively exploited for NLP via an introduction of a unified framework in which all NLP tasks are cast as a text-to-text generation task. mT5 [53] is a multilingual variant of T5, which is pre-trained on a new Common Crawlbased dataset consisting of texts in 101 languages. | T5[52]是一个文本到文本Transformer(T5)模型,将所有NLP任务都视为文本到文本生成任务,有效地利用了迁移学习。 mT5[53]是T5的多语言变体,,它在一个包含101种语言文本的新型Common Crawl数据集上进行了预训练。 |
MASS(重构剩余部分句子片段+编码器将带有随机屏蔽片段句子作为输入+解码器预测被屏蔽的片段)、BART()
| MASS (MAsked Sequence to Sequence pre-training) [54] adopts the encoder-decoder framework to reconstruct a sentence fragment given the remaining part of the sentence. The encoder takes a sentence with randomly masked fragment (several consecutive tokens) as input, and the decoder predicts the masked fragment. In this way, MASS jointly trains the encoder and decoder for language embedding and generation, respectively. | MASS (mask Sequence to Sequence pre-training)[54]采用编码器-解码器框架对给定句子剩余部分的句子片段进行重构。编码器将带有随机屏蔽片段(几个连续的标记)的句子作为输入,解码器预测被屏蔽的片段。这样,MASS同时训练编码器和解码器,分别用于语言嵌入和语言生成。 |
| BART [55] uses a standard sequence-to-sequence translation model architecture. It is pre-trained by corrupting text with an arbitrary noising function, and then learning to reconstruct the original text. | BART[55]使用标准的序列到序列翻译模型架构。它通过使用任意的加噪函数对文本进行破坏性处理进行预训练,然后学习重建原始文本。 |
B. Large Language Model Families大型语言模型家族(基于Transformer的PLM+尺寸更大【数百亿到数千亿个参数】+表现更强):比如LLM的三大家族
| Large language models (LLMs) mainly refer to transformer-based PLMs that contain tens to hundreds of billions of parameters. Compared to PLMs reviewed above, LLMs are not only much larger in model size, but also exhibit stronger language understanding and generation and emergent abilities that are not present in smaller-scale models. In what follows, we review three LLM families: GPT, LLaMA, and PaLM, as illustrated in Fig 8. | 大型语言模型(LLM)主要是指基于Transformer的PLM,包含数百亿到数千亿个参数。与上面提到的PLM相比,LLM不仅模型尺寸更大,而且在语言理解和生成方面表现更强,并且具有在规模较小的模型中不存在的新兴能力。接下来,我们将回顾三个LLM家族:GPT、LLaMA和PaLM,如图8所示。 |
Fig. 8: Popular LLM Families.
Fig. 9: GPT-3 shows that larger models make increasingly efficient use of in-context information. It shows in-context learning performance on a simple task requiring the model to remove random symbols from a word, both with and without a natural language task description. Courtesy of [56].图9:GPT-3显示,更大的模型对上下文信息的利用越来越有效。它显示了在一个简单任务上的上下文学习性能,该任务要求模型从单词中删除随机符号,包括有和没有自然语言任务描述。由[56]提供。
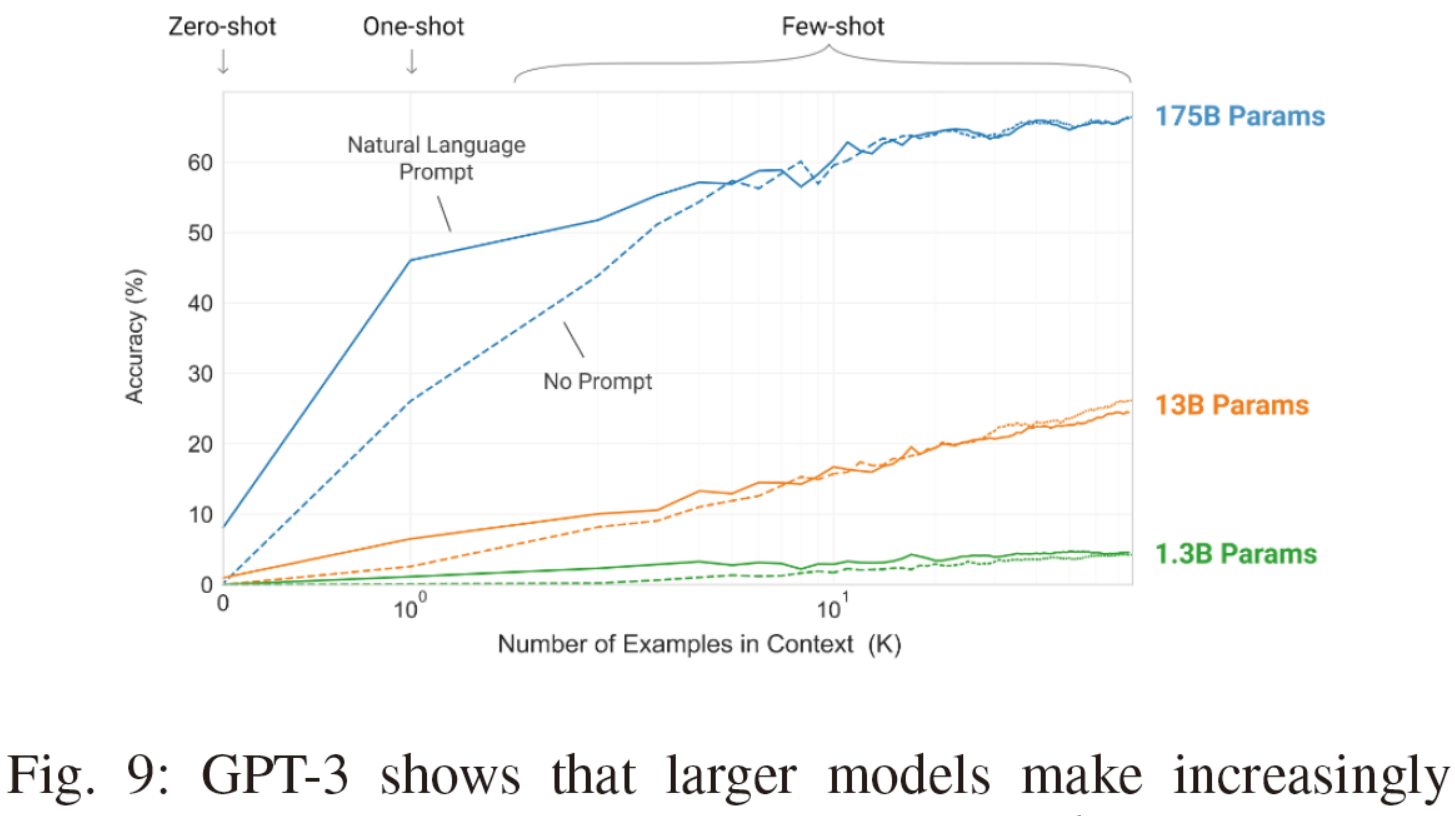
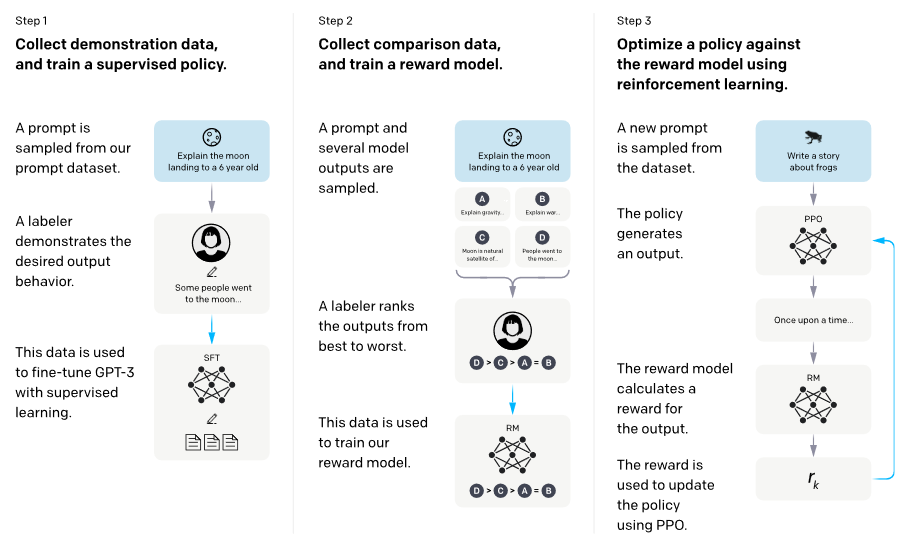
Fig. 10: The high-level overview of RLHF. Courtesy of [59].
GPT家族(OpenAI开发+后期闭源):开源系列(GPT-1、GPT-2),闭源系列(GPT-3、InstrucGPT、ChatGPT、GPT-4、CODEX、WebGPT,只能API访问)
| 1) The GPT Family: Generative Pre-trained Transformers (GPT) are a family of decoder-only Transformer-based language models, developed by OpenAI. This family consists of GPT-1, GPT-2, GPT-3, InstrucGPT, ChatGPT, GPT-4, CODEX, and WebGPT. Although early GPT models, such as GPT-1 and GPT-2, are open-source, recent models, such as GPT-3 and GPT-4, are close-source and can only be accessed via APIs. GPT-1 and GPT-2 models have been discussed in the early PLM subsection. We start with GPT-3 below. | 1) GPT家族:生成预训练Transformer(GPT)是一个由OpenAI开发的仅基于解码器的Transformer语言模型家族。该家族包括GPT-1、GPT-2、GPT-3、InstrucGPT、ChatGPT、GPT-4、CODEX和WebGPT。虽然早期的GPT模型,如GPT-1和GPT-2,是开源的,但最近的模型,如GPT-3和GPT-4,是闭源的,只能通过API访问。GPT-1和GPT-2模型已经在早期的PLM小节中讨论过。我们从下面的GPT-3开始。 |
GPT-3(175B):1750亿参数+被视为史上第一个LLM(因其大规模尺寸+涌现能力)+仅需少量演示直接用于下游任务而无需任何微调+适应各种NLP任务
| GPT-3 [56] is a pre-trained autoregressive language model with 175 billion parameters. GPT-3 is widely considered as the first LLM in that it not only is much larger than previous PLMs, but also for the first time demonstrates emergent abilities that are not observed in previous smaller PLMs. GPT3 shows the emergent ability of in-context learning, which means GPT-3 can be applied to any downstream tasks without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieved strong performance on many NLP tasks, including translation, question-answering, and the cloze tasks, as well as several ones that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, 3-digit arithmetic. Fig 9 plots the performance of GPT-3 as a function of the number of examples in in-context prompts | GPT-3 [56] 是一个具有1750亿个参数的预训练自回归语言模型。GPT-3被广泛认为是第一个LLM,因为它不仅比以前的PLM大得多,而且第一次展示了在以前较小的PLM中没有观察到的涌现能力。GPT3显示了上下文学习的涌现能力,这意味着GPT-3可以应用于任何下游任务,而无需任何梯度更新或微调,任务和少量演示完全通过与模型的文本交互指定。GPT-3在许多NLP任务上取得了很好的表现,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,如拼凑单词、在句子中使用新单词、3位数算术。图9以上下文提示中示例数量作为函数绘制了GPT-3的性能。 |
CODEX(2023年3月,即Copilot的底层技术):通用编程模型,解析自然语言并生成代码作为响应,采用GPT-3+微调GitHub的代码语料库
| CODEX [57], released by OpenAI in March 2023, is a general-purpose programming model that can parse natural language and generate code in response. CODEX is a descendant of GPT-3, fine-tuned for programming applications on code corpora collected from GitHub. CODEX powers Microsoft’s GitHub Copilot. | CODEX[57]是OpenAI于2023年3月发布的通用编程模型,可以解析自然语言并生成代码作为响应。CODEX是GPT-3的后代,对从GitHub收集的代码语料库进行了微调,用于编程应用程序。CODEX为微软的GitHub Copilot提供支持。 |
WebGPT:采用GPT-3+基于文本的网络浏览器回答+三步骤(学习模仿人类浏览行为+利用奖励函数来预测人类的偏好+强化学习和拒绝抽样来优化奖励函数)
| WebGPT [58] is another descendant of GPT-3, fine-tuned to answer open-ended questions using a text-based web browser, facilitating users to search and navigate the web. Specifically, WebGPT is trained in three steps. The first is for WebGPT to learn to mimic human browsing behaviors using human demonstration data. Then, a reward function is learned to predict human preferences. Finally, WebGPT is refined to optimize the reward function via reinforcement learning and rejection sampling. | WebGPT[58]是GPT-3的另一个后代,经过微调后,可以使用基于文本的网络浏览器回答开放性问题,帮助用户搜索和浏览网络。具体来说,WebGPT的训练分为三个步骤。首先是WebGPT学习模仿人类浏览行为,使用人类演示数据。然后,学习奖励函数来预测人类的偏好。最后,通过强化学习和拒绝抽样来优化奖励函数,对WebGPT进行了改进。 |
InstructGPT:采用GPT-3+对人类反馈进行微调(RLHF对齐用户意图)+改善了真实性和有毒性
| To enable LLMs to follow expected human instructions, InstructGPT [59] is proposed to align language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, a dataset of labeler demonstrations of the desired model behavior is collected. Then GPT-3 is fine-tuned on this dataset. Then, a dataset of human-ranked model outputs is collected to further fine-tune the model using reinforcement learning. The method is known Reinforcement Learning from Human Feedback (RLHF), as shown in 10. The resultant InstructGPT models have shown improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. | InstructGPT:为了使LLM能够遵循预期的人类指令,提出了InstructGPT[59],通过对人类反馈进行微调,使语言模型在广泛的任务上与用户意图保持一致。从一组分词器编写的提示和通过OpenAI API提交的提示开始,收集所需模型行为的分词器演示数据集。然后GPT-3在这个数据集上进行微调。接下来,收集了一个包含人类排名模型输出的数据集,以进一步使用强化学习对模型进行微调。这种方法被称为基于人类反馈的强化学习(RLHF),如图10所示。所得到的InstructGPT模型在真实性方面有所改善,并且在减少有毒输出生成方面表现良好,同时在公共NLP数据集上具有最小的性能回归。 |
ChatGPT(2022年11月30日):一种聊天机器人+采用用户引导对话完成各种任务+基于GPT-3.5+为InstructGPT的兄弟模型
| The most important milestone of LLM development is the launch of ChatGPT (Chat Generative Pre-trained Transformer) [60] on November 30, 2022. ChatGPT is chatbot that enables users to steer a conversation to complete a wide range of tasks such as question answering, information seeking, text summarization, and more. ChatGPT is powered by GPT-3.5 (and later by GPT-4), a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response. | ChatGPT:LLM发展最重要的里程碑是在2022年11月30日推出ChatGPT(聊天生成预训练Transformer)[60]。ChatGPT是一种聊天机器人,它使用户能够引导对话完成各种任务,如问题回答、信息搜索、文本摘要等。ChatGPT是由GPT-3.5(后来又由GPT-4)提供支持的,它是InstructGPT的兄弟模型,经过训练可以在提示中遵循指令并提供详细的响应。 |
GPT-4(2023年3月):GPT家族中最新最强大的多模态LLM(呈现人类级别的性能)+基于大型文本语料库预训练+采用RLHF进行微调
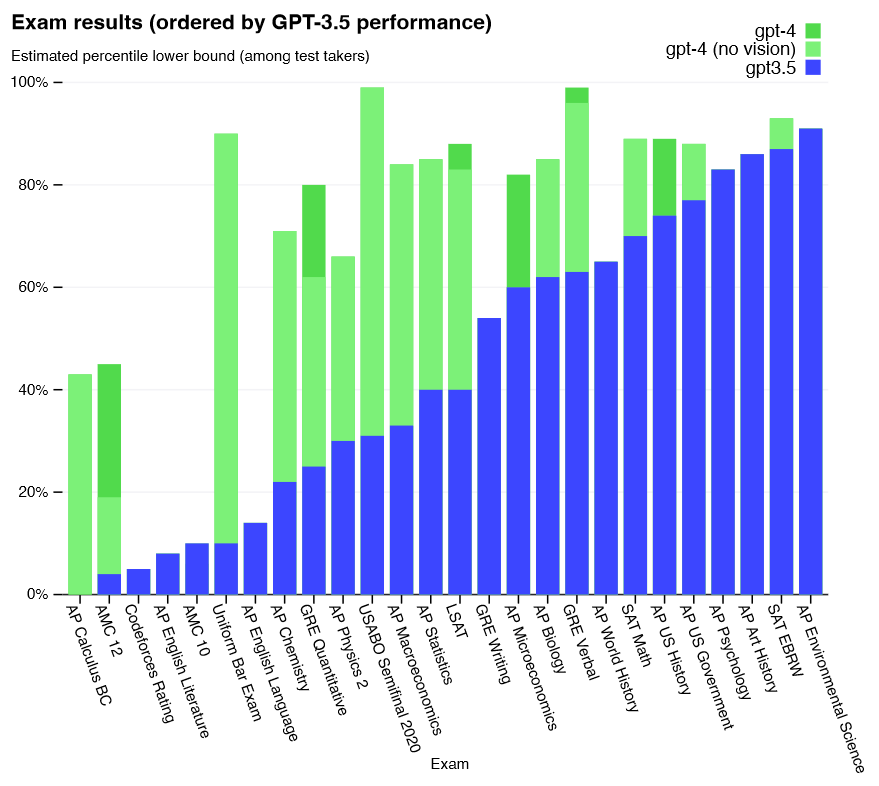
| GPT-4 [33] is the latest and most powerful LLM in the GPT family. Launched in March, 2023, GPT-4 is a multimodal LLM in that it can take image and text as inputs and produce text outputs. While still less capable than humans in some of the most challenging real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers, as shown in Fig 11. Like early GPT models, GPT-4 was first pre-trained to predict next tokens on large text corpora, and then fine-tuned with RLHF to align model behaviors with human-desired ones. | GPT-4[33]是GPT家族中最新最强大的LLM。GPT-4于2023年3月推出,是一种多模态LLM,可以接受图像和文本作为输入,并产生文本输出。虽然在一些最具挑战性的现实场景中仍然不如人类,但GPT-4在各种专业和学术基准测试中表现出人类级别的性能,包括在模拟的司法考试中获得了约前10%考生的成绩,如图11所示。与早期的GPT模型一样,GPT-4首先被预训练以预测大型文本语料库上的下一个标记,然后使用RLHF进行微调,使模型行为与人类期望的行为保持一致。 |
Fig. 11: GPT-4 performance on academic and professional exams, compared with GPT 3.5. Courtesy of [33].
LLaMA家族(主要由Meta开发+开源)
| 2) The LLaMA Family: LLaMA is a collection of foundation language models, released by Meta. Unlike GPT models, LLaMA models are open-source, i.e., model weights are released to the research community under a noncommercial license. Thus, the LLaMA family grows rapidly as these models are widely used by many research groups to develop better open-source LLMs to compete the closed-source ones or to develop task-specific LLMs for mission-critical applications. | 2) LLaMA家族: LLaMA是Meta发布的一系列基础语言模型。与GPT模型不同,LLaMA模型是开源的,也就是说,模型权重是在非商业许可下发布给研究社区的。因此,随着这些模型被许多研究小组广泛用于开发更好的开源LLM以与闭源LLM竞争,或者为关键任务应用程序开发特定于任务的LLM,LLaMA家族发展迅速。 |
Fig. 12: Training of LLaMA-2 Chat. Courtesy of [61].
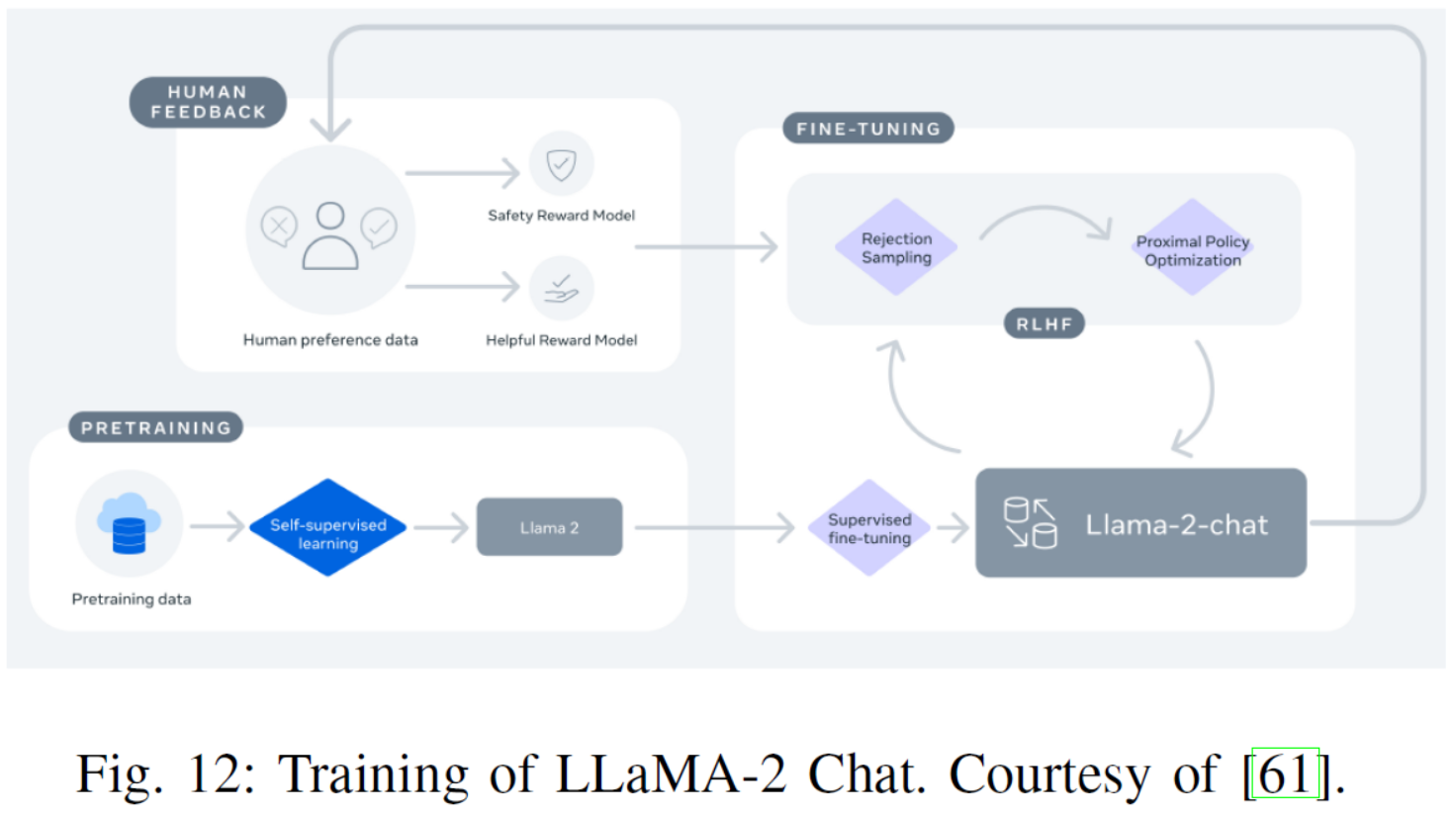
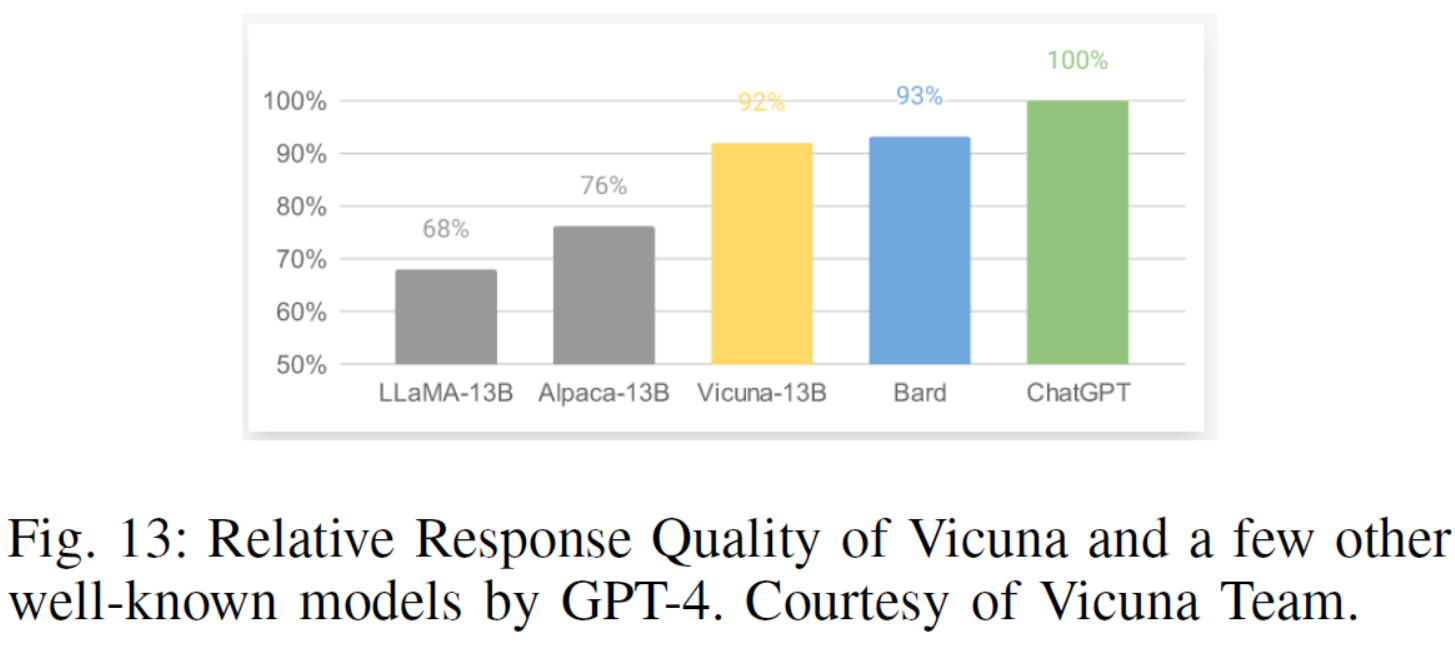
Fig. 13: Relative Response Quality of Vicuna and a few other well-known models by GPT-4. Courtesy of Vicuna Team.
LLaMA1(2023年2月):预训练语料(公开可用+万亿级token)+参照GPT-3的Transformer架构+部分修改(SwiGLU替代ReLU/旋转位置嵌入替代绝对位置嵌入/均方根层归一化替代标准层归一化),良好基准
| The first set of LLaMA models [32] was released in February 2023, ranging from 7B to 65B parameters. These models are pre-trained on trillions of tokens, collected from publicly available datasets. LLaMA uses the transformer architecture of GPT-3, with a few minor architectural modifications, including (1) using a SwiGLU activation function instead of ReLU, (2) using rotary positional embeddings instead of absolute positional embedding, and (3) using root-mean-squared layernormalization instead of standard layer-normalization. The open-source LLaMA-13B model outperforms the proprietary GPT-3 (175B) model on most benchmarks, making it a good baseline for LLM research. | 第一套LLaMA模型[32]于2023年2月发布,参数从7B到65B不等。这些模型是在数万亿个令牌上进行预训练的,这些令牌是从公开可用的数据集中收集的。LLaMA使用了GPT-3的Transformer架构,并进行了一些小的架构修改,包括(1)使用SwiGLU激活函数而不是ReLU,(2)使用旋转位置嵌入而不是绝对位置嵌入,以及(3)使用均方根层归一化而不是标准层归一化。开源的LLaMA-13B模型在大多数基准测试中优于专有的GPT-3 (175B)模型,使其成为LLM研究的良好基准。 |
LLaMA2(2023年7月/Meta与微软合作):预训练(公开可用)+监督微调+模型优化(RLHF/拒绝抽样/最近邻策略优化)
| In July 2023, Meta, in partnership with Microsoft, released the LLaMA-2 collection [61], which include both foundation language models and Chat models finetuned for dialog, known as LLaMA-2 Chat. The LLaMA-2 Chat models were reported to outperform other open-source models on many public benchmarks. Fig 12 shows the training process of LLaMA-2 Chat. The process begins with pre-training LLaMA-2 using publicly available online data. Then, an initial version of LLaMA-2 Chat is built via supervised fine-tuning. Subsequently, the model is iteratively refined using RLHF, rejection sampling and proximal policy optimization. In the RLHF stage, the accumulation of human feedback for revising the reward model is crucial to prevent the reward model from being changed too much, which could hurt the stability of LLaMA model training. | 在2023年7月,Meta与微软合作发布了LLaMA-2系列[61],其中包括基础语言模型和针对对话进行微调的聊天模型,称为LLaMA-2 Chat。据报道,LLaMA-2 Chat模型在许多公共基准测试中优于其他开源模型。图12为LLaMA-2 Chat的训练过程。这个过程从使用公开的在线数据对LLaMA-2进行预训练开始。然后,通过监督微调构建LLaMA-2 Chat的初始版本。然后,使用RLHF、拒绝抽样和最近邻策略优化对模型进行迭代改进。在RLHF阶段,人为反馈对奖励模型修正的积累至关重要,以防止奖励模型变化过大,影响LLaMA模型训练的稳定性。 |
Alpaca:利用GPT-3.5生成52K指令数据+微调LLaMA-7B模型,比GPT-3.5相当但成本非常小
| Alpaca [62] is fine-tuned from the LLaMA-7B model using 52K instruction-following demonstrations generated in the style of self-instruct using GPT-3.5 (text-davinci-003). Alpaca is very cost-effective for training, especially for academic research. On the self-instruct evaluation set, Alpaca performs similarly to GPT-3.5, despite that Alpaca is much smaller. | Alpaca [62]是通过使用GPT-3.5 (text- davincii -003)以自我指导的方式生成的52K指令跟随演示,对LLaMA-7B模型进行微调的。Alpaca是非常划算的训练,尤其是学术研究。在自我指导评估集上,Alpaca的表现与GPT-3.5相似,尽管Alpaca要小得多。 |
Vicuna:从ShareGPT收集用户对话数据+微调利用LLaMA+采用GPT4评估,达到ChatGPT和Bard的90%性能但仅为300美元
| The Vicuna team has developed a 13B chat model, Vicuna13B, by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluation using GPT4 as a evaluator shows that Vicuna-13B achieves more than 90% quality of OpenAI’s ChatGPT, and Google’s Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90% of cases. 13 shows the relative response quality of Vicuna and a few other well-known models by GPT-4. Another advantage of Vicuna-13B is its relative limited computational demand for model training. The training cost of Vicuna-13B is merely $300. | Vicuna团队开发了一个13B聊天模型,Vicuna13B,通过对LLaMA对从ShareGPT收集的用户共享对话进行微调。使用GPT4作为评估器进行的初步评估表明,Vicuna-13B的质量达到了OpenAI的ChatGPT和Google的Bard的90%以上,而在90%以上的情况下优于LLaMA和Stanford Alpaca等其他模型。图13为GPT-4对Vicuna和其他几个知名模型的相对响应质量。Vicuna-13B的另一个优点是它对模型训练的计算需求相对有限。Vicuna-13B的训练费用仅为300美元。 |
Guanaco:采用指令遵循数据+利用QLoRA微调LLaMA模型,单个48GB GPU上仅需24小时可微调65B参数模型,达到了ChatGPT的99.3%性能
| Like Alpaca and Vicuna, the Guanaco models [63] are also finetuned LLaMA models using instruction-following data. But the finetuning is done very efficiently using QLoRA such that finetuning a 65B parameter model can be done on a single 48GB GPU. QLoRA back-propagates gradients through a frozen, 4-bit quantized pre-trained language model into Low Rank Adapters (LoRA). The best Guanaco model outperforms all previously released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of fine-tuning on a single GPU. | 与Alpaca和Vicuna一样,Guanaco模型[63]也是使用指令遵循数据进行微调的LLaMA模型。但是,使用QLoRA进行微调非常有效,因此可以在单个48GB GPU上完成65B参数模型的微调。QLoRA通过冻结的4位量化预训练语言模型将梯度反向传播到低秩适配器(Low Rank Adapters, LoRA)。在Vicuna基准测试中,最好的Guanaco型号的性能超过了之前发布的所有型号,达到了ChatGPT性能水平的99.3%,而只需要在单个GPU上进行24小时的微调。 |
Koala:采用指令遵循数据(侧重交互数据)+微调LLaMA模型
| Koala [64] is yet another instruction-following language model built on LLaMA, but with a specific focus on interaction data that include user inputs and responses generated by highly capable closed-source chat models such as ChatGPT. The Koala-13B model performs competitively with state-of-the-art chat models according to human evaluation based on realworld user prompts. | Koala[64]是另一个基于LLaMA的指令遵循语言模型,但它特别关注交互数据,包括用户输入和由功能强大的闭源聊天模型(如ChatGPT)生成的响应。根据基于真实用户提示的人类评估,Koala-13B模型在与最先进的聊天模型竞争时表现出色。 |
Mistral-7B:为了优越的性能和效率而设计,利用分组查询注意力来实现更快的推理,并配合滑动窗口注意力来有效地处理任意长度的序列
| Mistral-7B [65] is a 7B-parameter language model engineered for superior performance and efficiency. Mistral-7B outperforms the best open-source 13B model (LLaMA-2-13B) across all evaluated benchmarks, and the best open-source 34B model (LLaMA-34B) in reasoning, mathematics, and code generation. This model leverages grouped-query attention for faster inference, coupled with sliding window attention to effectively handle sequences of arbitrary length with a reduced inference cost. | Mistral-7B[65]是一种7b参数语言模型,设计用于优越的性能和效率。Mistral-7B在所有评估基准上优于最佳开源13B模型(LLaMA-2-13B),在推理、数学和代码生成方面优于最佳开源34B模型(LLaMA-34B)。该模型利用分组查询注意力来实现更快的推理,并配合滑动窗口注意力来有效地处理任意长度的序列,同时降低推理成本。 |
其它:Code LLaMA 、Gorilla、Giraffe、Vigogne、Tulu 65B、Long LLaMA、Stable Beluga
| The LLaMA family is growing rapidly, as more instructionfollowing models have been built on LLaMA or LLaMA2, including Code LLaMA [66], Gorilla [67], Giraffe [68], Vigogne [69], Tulu 65B [70], Long LLaMA [71], and Stable Beluga2 [72], just to name a few. | LLaMA家族正在迅速壮大,因为更多的指令跟随模型已经建立在LLaMA或LLaMA2上,包括Code LLaMA [66]、Gorilla [67]、Giraffe [68]、Vigogne [69]、Tulu 65B [70]、Long LLaMA [71]和Stable Beluga2 [72]等等。 |
PaLM家族(Google开发):
PaLM(2022年4月,2023年3月才对外公开):540B参数+基于Transformer+语料库(7800亿个令牌)+高效训练(采用Pathways系统在6144个TPU v4芯片)+与人类表现相当
| 3) The PaLM Family: The PaLM (Pathways Language Model) family are developed by Google. The first PaLM model [31] was announced in April 2022 and remained private until March 2023. It is a 540B parameter transformer-based LLM. The model is pre-trained on a high-quality text corpus consisting of 780 billion tokens that comprise a wide range of natural language tasks and use cases. PaLM is pre-trained on 6144 TPU v4 chips using the Pathways system, which enables highly efficient training across multiple TPU Pods. PaLM demonstrates continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. PaLM540B outperforms not only state-of-the-art fine-tuned models on a suite of multi-step reasoning tasks, but also on par with humans on the recently released BIG-bench benchmark | 3) PaLM家族:PaLM (Pathways Language Model)家族是由Google开发的。第一款PaLM型号[31]于2022年4月公布,直到2023年3月才对外公开。它是一个基于Transformer的LLM,具有540B个参数。该模型是在一个高质量的文本语料库上进行预训练的,该语料库由7800亿个令牌组成,涵盖了广泛的自然语言任务和用例。PaLM使用Pathways系统在6144个 TPU v4芯片上进行预训练,从而实现跨多个TPU pod的高效训练。PaLM通过在数百种语言理解和生成基准上实现最先进的少量学习结果,展示了继续扩展的好处。PaLM540B不仅在一系列多步骤推理任务上优于最先进的微调模型,,而且在最近发布的BIG-bench基准测试中与人类表现相当。 |
Fig. 14: Flan-PaLM finetuning consist of 473 datasets in above task categories. Courtesy of [74].

U-PaLM:使用UL2R(使用UL2的混合去噪目标来持续训练)在PaLM上进行训练+可节省约2倍的计算资源
| The U-PaLM models of 8B, 62B, and 540B scales are continually trained on PaLM with UL2R, a method of continue training LLMs on a few steps with UL2’s mixture-of-denoiser objective [73]. An approximately 2x computational savings rate is reported. | 8B、62B和540B规模的U-PaLM模型正在不断地使用UL2R在PaLM上进行训练,UL2R是一种使用UL2的混合去噪目标来持续训练LLM的方法。据报道,这可以节省约2倍的计算资源。 |
Flan-PaLM:更多的任务(473个数据集/总共1836个任务)+更大的模型规模+链式思维数据
| U-PaLM is later instruction-finetuned as Flan-PaLM [74]. Compared to other instruction finetuning work mentioned above, Flan-PaLM’s finetuning is performed using a much larger number of tasks, larger model sizes, and chain-ofthought data. As a result, Flan-PaLM substantially outperforms previous instruction-following models. For instance, FlanPaLM-540B, which is instruction-finetuned on 1.8K tasks, outperforms PaLM-540B by a large margin (+9.4% on average). The finetuning data comprises 473 datasets, 146 task categories, and 1,836 total tasks, as illustrated in Fig 14. | U-PaLM后来被调整为Flan-PaLM[74]。与上面提到的其他指令调优工作相比,Flan-PaLM的微调使用了更多的任务、更大的模型规模和链式思维数据。因此,Flan-PaLM大大优于以前的指令遵循模型。例如,在1.8K任务上进行指令微调的FlanPaLM-540B的性能大大优于PaLM-540B(平均+9.4%)。调优数据包括473个数据集,146个任务类别,总共1836个任务,如图14所示。 |
PaLM-2:计算效率更高+更好的多语言和推理能力+混合目标,快速、更高效的推理能力
| PaLM-2 [75] is a more compute-efficient LLM with better multilingual and reasoning capabilities, compared to its predecessor PaLM. PaLM-2 is trained using a mixture of objectives. Through extensive evaluations on English, multilingual, and reasoning tasks, PaLM-2 significantly improves the model performance on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference than PaLM. | 与其前身PaLM相比,PaLM-2[75]是一种计算效率更高的LLM,具有更好的多语言和推理能力。PaLM-2是使用混合目标进行训练的。通过对英语、多语言和推理任务的广泛评估,PaLM-2显著提高了不同模型规模下的下游任务性能,同时表现出比PaLM更快速、更高效的推理能力。 |
Med-PaLM(特定领域的PaLM(医学领域问题回答),基于PaLM的指令提示调优)→Med-PaLM 2(医学领域微调和集成提示改进)
| Med-PaLM [76] is a domain-specific PaLM, and is designed to provide high-quality answers to medical questions. Med-PaLM is finetuned on PaLM using instruction prompt tuning, a parameter-efficient method for aligning LLMs to new domains using a few exemplars. Med-PaLM obtains very encouraging results on many healthcare tasks, although it is still inferior to human clinicians. Med-PaLM 2 improves MedPaLM via med-domain finetuning and ensemble prompting [77]. Med-PaLM 2 scored up to 86.5% on the MedQA dataset (i.e., a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries), improving upon Med-PaLM by over 19% and setting a new state-of-the-art. | Med-PaLM[76]是一个特定领域的PaLM,旨在为医学问题提供高质量的答案。Med-PaLM使用指令提示调优在PaLM上进行调优,这是一种参数高效的方法,可以使用少量示例将LLM与新领域对齐。Med-PaLM在许多医疗保健任务中获得了非常令人鼓舞的结果,尽管它仍然不如人类临床医生。Med-PaLM 2通过医学领域微调和集成提示改进了Med-PaLM [77]。Med-PaLM 2在MedQA数据集上得分高达86.5%(即一个结合了六个现有开放问题回答数据集的基准测试,涵盖专业医学考试,研究和消费者查询),比Med-PaLM提高了超过19%,并设定了新的先进技术。 |
C. Other Representative LLMs其他代表性LLM
| In addition to the models discussed in the previous subsections, there are other popular LLMs which do not belong to those three model families, yet they have achieved great performance and have pushed the LLMs field forward. We briefly describe these LLMs in this subsection. | 除了前几节讨论的模型之外,还有其他流行的LLM,它们不属于这三个模型家族,但它们取得了很大的成绩,并推动了LLM领域的发展。我们在本小节中简要介绍这些LLM。 |
Fig. 15: comparison of instruction tuning with pre-train–finetune and prompting. Courtesy of [78].
Fig. 16: Model architecture details of Gopher with different number of parameters. Courtesy of [78].
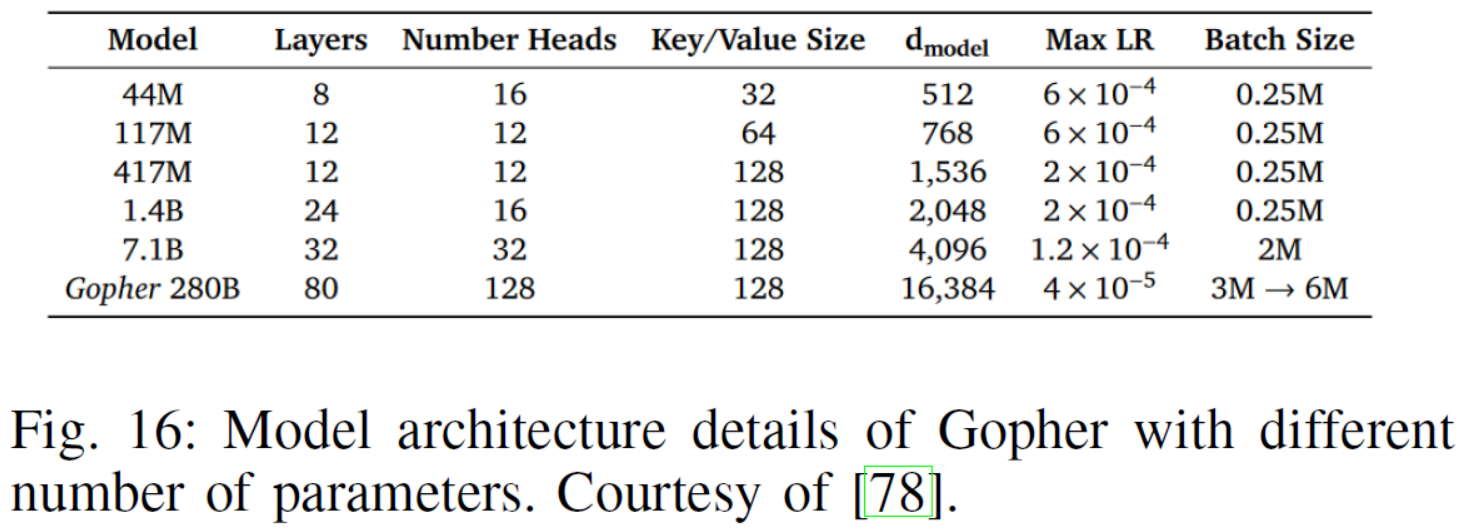
Fig. 17: High-level model architecture of ERNIE 3.0. Courtesy of [81].
Fig. 18: Retro architecture. Left: simplified version where a sequence of length n = 12 is split into l = 3 chunks of size m = 4. For each chunk, we retrieve k = 2 neighbours of r = 5 tokens each. The retrieval pathway is shown on top. Right: Details of the interactions in the CCA operator. Causality is maintained as neighbours of the first chunk only affect the last token of the first chunk and tokens from the second chunk. Courtesy of [82].
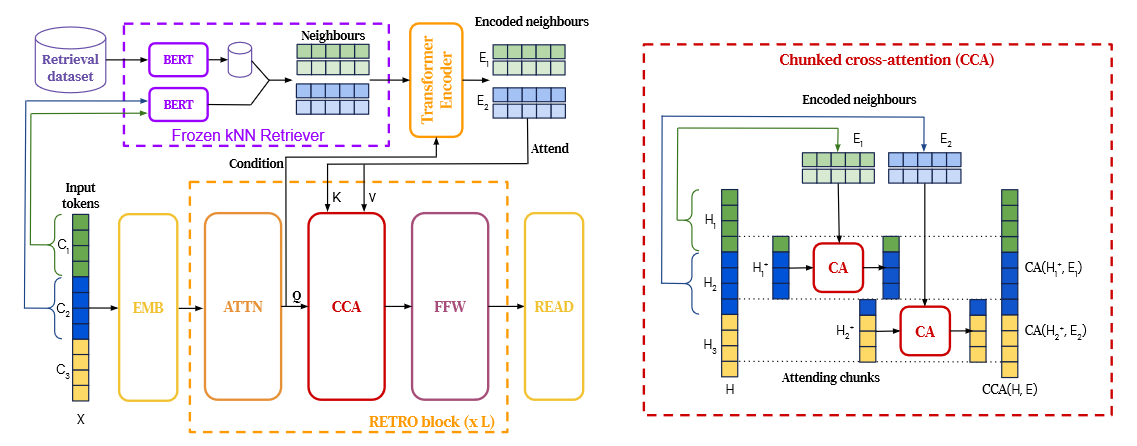
Fig. 19: GLaM model architecture. Each MoE layer (the bottom block) is interleaved with a Transformer layer (the upper block). Courtesy of [84].
Fig. 20: Different OPT Models’ architecture details. Courtesy of [86].
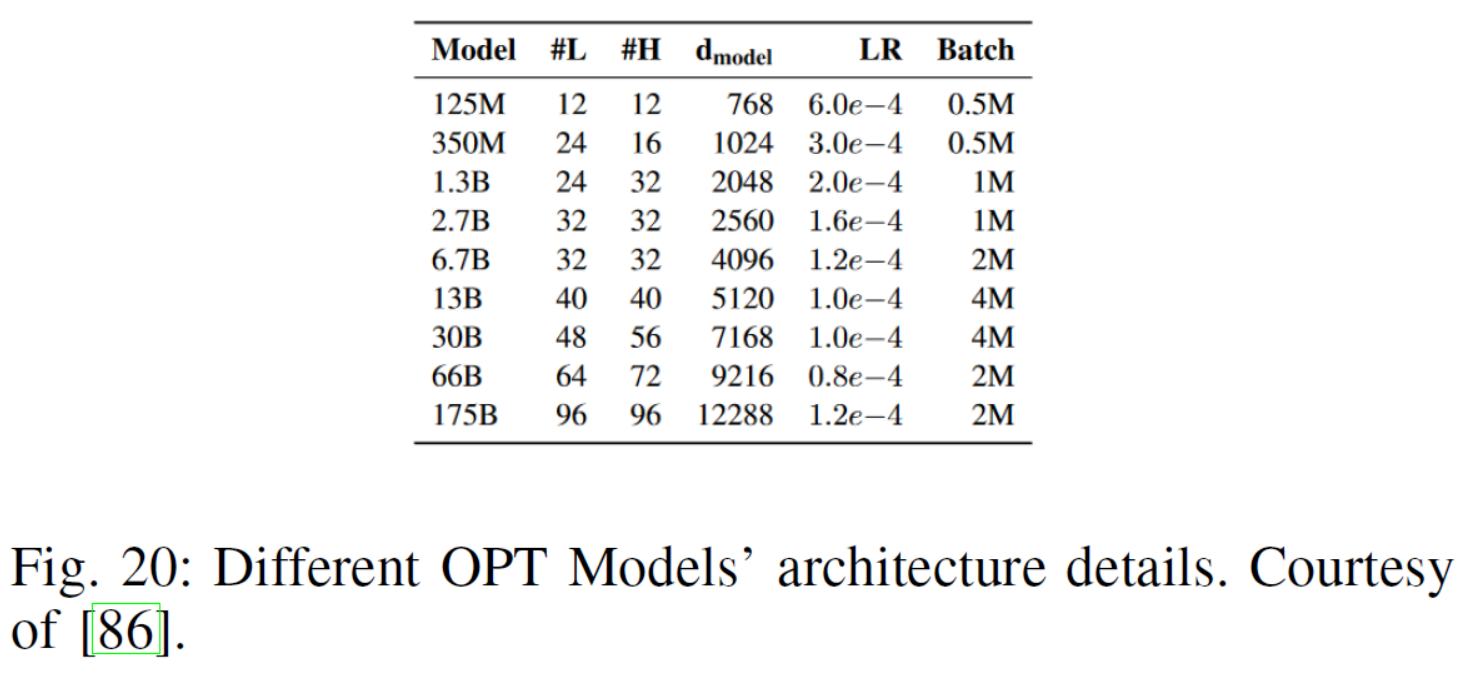
Fig. 21: Sparrow pipeline relies on human participation to continually expand a training set. Courtesy of [90].
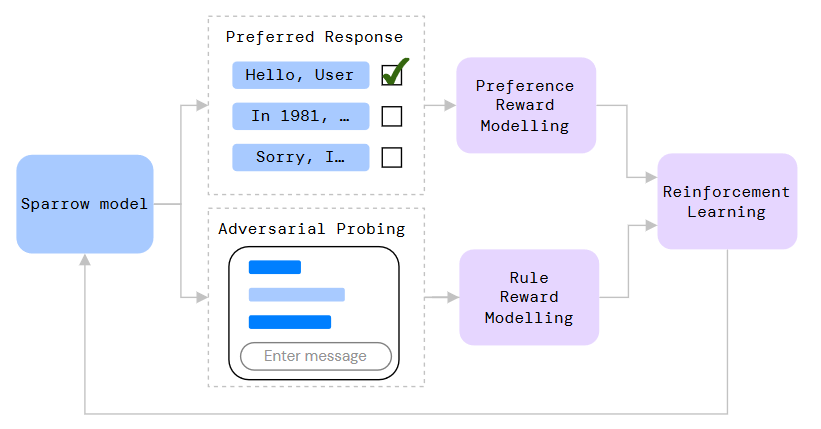
Fig. 22: An overview of UL2 pretraining paradigm. Courtesy of [92].
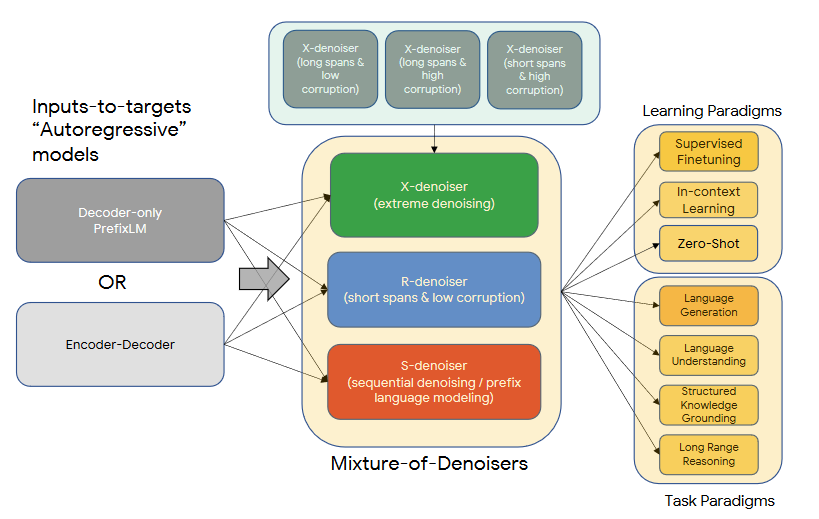
Fig. 23: An overview of BLOOM architecture. Courtesy of [93].
FLAN(通过指令调优来提高语言模型的零样本性能)、Gopher(探索基于Transformer的不同模型尺度上的性能+采用152个任务评估,280B个参数)、T0(将任何自然语言任务映射到人类可读提示形式)
| FLAN: In [78], Wei et al. explored a simple method for improving the zero-shot learning abilities of language models. They showed that instruction tuning language models on a collection of datasets described via instructions substantially improves zero-shot performance on unseen tasks. They take a 137B parameter pretrained language model and instruction tune it on over 60 NLP datasets verbalized via natural language instruction templates. They call this instruction-tuned model FLAN. Fig 15 provides a comparison of instruction tuning with pretrain–finetune and prompting. | FLAN:在[78]中,Wei等人探索了一种改进语言模型零样本学习能力的简单方法。他们表明,在通过指令描述的数据集集合上的指令调优语言模型大大提高了未见任务的零样本性能。他们采用了一个137B参数的预训练语言模型,并在60多个NLP数据集上进行了指令调整,这些数据集是通过自然语言指令模板口头描述的。他们称这个经过指令调整的模型为FLAN。图15比较了指令调整、预训练微调和提示之间的差异。 |
| Gopher: In [79], Rae et al. presented an analysis of Transformer-based language model performance across a wide range of model scales — from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models were evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. The number of layers, the key/value size, and other hyper-parameters of different model sizes are shown in Fig 16. | Gopher:在[79]中,Rae等人对基于Transformer的语言模型在各种模型尺度上的性能进行了分析——从具有数千万个参数的模型到一个名为Gopher的2800亿个参数的模型。这些模型在152个不同的任务上进行了评估,大多数任务的性能达到了最先进水平。图16显示了不同模型规模的层数、键/值大小和其他超参数。 |
| T0: In [80], Sanh et al. developed T0, a system for easily mapping any natural language tasks into a human-readable prompted form. They converted a large set of supervised datasets, each with multiple prompts with diverse wording. These prompted datasets allow for benchmarking the ability of a model to perform completely held-out tasks. Then, a T0 encoder-decoder model is developed to consume textual inputs and produces target responses. The model is trained on a multitask mixture of NLP datasets partitioned into different tasks. | T0:在[80]中,Sanh等人开发了T0,这是一个可以轻松地将任何自然语言任务映射到人类可读提示形式的系统。他们转换了一大批有监督数据集,每个数据集都有多个具有不同措辞的提示。这些提示数据集允许对模型执行完全未见任务的能力进行基准测试。然后,开发了一个T0编码器-解码器模型来处理文本输入并生成目标响应。该模型在多任务的NLP数据集上进行训练,这些数据集被分成不同的任务。 |
ERNIE 3.0(知识增强模型+融合了自回归网络和自编码网络+可轻松地适应自然语言理解和生成任务,4TB语料库/10B参数)、RETRO(基于与先前token的局部相似性,调节语料库中检索的文档块,增强了自回归语言模型,2T的token)、GLaM(采用一种稀疏激活的专家混合架构来扩展模型容量+1.2T参数)
| ERNIE 3.0: In [81], Sun et al. proposed a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and autoencoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks using zero-shot learning, few-shot learning or fine-tuning. They have trained ERNIE 3.0 with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Fig 17 illustrates the model architecture of Ernie 3.0. | ERNIE 3.0:在[81]中,Sun等人提出了一个统一的框架ERNIE 3.0,用于预训练大规模的知识增强模型。它融合了自回归网络和自编码网络,以便训练后的模型可以轻松地适应自然语言理解和生成任务,使用零样本学习、少样本学习或微调。他们在由纯文本和大规模知识图组成的4TB语料库上训练了100亿个参数的ERNIE 3.0。图17展示了Ernie 3.0的模型架构。 |
| RETRO: In [82], Borgeaud et al. enhanced auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. Using a 2-trillion-token database, the RetrievalEnhanced Transformer (Retro) obtains comparable performance to GPT-3 and Jurassic-1 [83] on the Pile, despite using 25% fewer parameters. As shown in Fig 18, Retro combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. | RETRO:在[82]中,Borgeaud等人基于与先前标记的局部相似性,通过对从大型语料库中检索的文档块进行调节,增强了自回归语言模型。使用2万亿令牌数据库,检索增强Transformer (Retro)在Pile上获得与GPT-3和Jurassic-1[83]相当的性能,尽管使用的参数减少了25%。如图18所示,Retro结合了一个冻结的Bert检索器、一个可微的编码器和一个分块的交叉注意机制,以基于比训练期间典型消耗的数据量大一个数量级的数据来预测token。 |
| GLaM: In [84], Du et al. proposed a family of LLMs named GLaM (Generalist Language Model), which use a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero, one and few-shot performance across 29 NLP tasks. Fig 19 shows the high-level architecture of GLAM. | GLaM:在[84]中,Du等人提出了一系列名为GLaM(通用语言模型)的LLM,它们使用了一种稀疏激活的专家混合架构来扩展模型容量,同时与密集变体相比,训练成本大大降低。最大的GLaM具有1.2万亿参数,大约比GPT3大7倍。它的能耗仅为训练GPT-3所用能量的1/3,并且需要一半的计算FLOPS进行推断,同时在29个NLP任务中实现了更好的零、一和少样本性能。图19显示了GLAM的高级架构。 |
LaMDA(基于transformer的专门用于对话+能够查找外部知识来源+显著改善安全性和事实,137B参数/1.56T个单词)、OPT(仅解码器+与研究人员共享这些模型)、Chinchilla(提出模型大小与token个数的规模定律,70B参数)
| LaMDA: In [85], Thoppilan et al. presented LaMDA, a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. They showed that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. | LaMDA:在[85]中,Thoppilan等人提出了LaMDA,这是一组基于transformer的专门用于对话的神经语言模型,该模型具有多达137B个参数,并对公共对话数据和网络文本的1.56T个单词进行了预训练。 他们表明,使用带注释的数据进行微调,并使模型能够查找外部知识来源,可以显著改善安全性和事实基础这两个关键挑战。 |
| OPT: In [86], Zhang et al. presented Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which they share with researchers. The OPT models’ parameters are shown in 20 | OPT:在[86]中,Zhang等人提出了开放预训练Transformer(OPT),这是一套仅解码器的预训练Transformer,参数范围从125M到175B,他们与研究人员共享这些模型。OPT模型参数见20 |
| Chinchilla: In [2], Hoffmann et al. investigated the optimal model size and number of tokens for training a transformer language model under a given compute budget. By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, they found that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. They tested this hypothesis by training a predicted compute-optimal model, Chinchilla, that uses the same compute budget as Gopher but with 70B parameters and 4% more more data. | Chinchilla:在[2]中,Hoffmann等人研究了在给定计算预算下训练transformer语言模型的最佳模型大小和toekn数量。通过在5B至500B个toekn上训练超过400个语言模型,这些模型的参数范围从7000万到超过16B,他们发现,对于计算最优的训练,应该等比例地缩放模型大小和训练标记数量:模型大小每增加一倍,训练标记数量也应该增加一倍。他们通过训练一个预测的计算最优模型Chinchilla来验证这一假设,Chinchilla使用与Gopher相同的计算预算,但仅有70B个参数和多4%的数据。 |
Galactica(存储、组合和推理科学知识+训练数据【论文/参考资料/知识库等】)、CodeGen(基于自然语言和编程语言数据,16B参数+一个开放基准MTPB【由115个不同的问题集组成】)、AlexaTM(证明了多语言的seq2seq在混合去噪和因果语言建模(CLM)任务上比仅解码器更有效地少样本学习)
| Galactica: In [87], Taylor et al. introduced Galactica, a large language model that can store, combine and reason about scientific knowledge. They trained on a large scientific corpus of papers, reference material, knowledge bases and many other sources. Galactica performed well on reasoning, outperforming Chinchilla on mathematical MMLU by 41.3% to 35.7%, and PaLM 540B on MATH with a score of 20.4% versus 8.8% | Galactica: Taylor等人在[87]中介绍了Galactica,这是一个可以存储、组合和推理科学知识的大型语言模型。他们在大量科学论文、参考资料、知识库和许多其他来源上进行了训练。Galactica在推理方面表现出色,数学MMLU的表现超过Chinchilla,分别为41.3%和35.7%,在数学MATH方面与PaLM 540B相比,得分为20.4%对8.8%。 |
| CodeGen: In [88], Nijkamp et al. trained and released a family of large language models up to 16.1B parameters, called CODEGEN, on natural language and programming language data, and open sourced the training library JAXFORMER. They showed the utility of the trained model by demonstrating that it is competitive with the previous state-ofthe-art on zero-shot Python code generation on HumanEval. They further investigated the multi-step paradigm for program synthesis, where a single program is factorized into multiple prompts specifying sub-problems. They also constructed an open benchmark, Multi-Turn Programming Benchmark (MTPB), consisting of 115 diverse problem sets that are factorized into multi-turn prompts. | CodeGen:在[88]中,Nijkamp等人在自然语言和编程语言数据上训练并发布了一系列多达16.1B个参数的大型语言模型,称为CodeGen,并开源了训练库JAXFORMER。他们展示了经过训练的模型的实用性,证明它在HumanEval上的零样本Python代码生成方面与之前最先进的模型具有竞争力。他们进一步研究了程序合成的多步范式,其中一个程序被分解为指定子问题的多个提示。他们还构建了一个开放基准,名为多轮编程基准(MTPB),由115个不同的问题集组成,这些问题集被分解为多轮提示。 |
| AlexaTM: In [89], Soltan et al. demonstrated that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various task. They trained a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and showed that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM consist of 46 encoder layers, 32 decoder layers, 32 attention heads, and dmodel = 4096. | AlexaTM:在[89]中,Soltan等人证明了多语言大规模序列到序列(seq2seq)模型,在混合去噪和因果语言建模(CLM)任务上进行预训练,比仅解码器模型在各种任务上更有效地进行少样本学习。他们训练了一个200亿个参数的多语言seq2seq模型,称为Alexa教师模型(AlexaTM 20B),并表明它在单样本总结任务上达到了最先进的(SOTA)性能,优于更大的540B PaLM解码器模型。AlexaTM由46个编码器层,32个解码器层,32个注意头组成,dmodel = 4096。 |
Sparrow(一种信息搜索对话代理+更有帮助/更正确/更无害+RLHF+帮助人类评价代理行为)、Minerva(在通用自然语言数据上预训练+在技术内容上进一步训练+解决定量推理的困难)、MoD(将各种预训练范式结合在一起的预训练目标,即UL2框架)
| Sparrow: In [90], Glaese et al. presented Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. They used reinforcement learning from human feedback to train their models with two new additions to help human raters judge agent behaviour. The high-level pipeline of Sparrow model is shown in Fig 21. | Sparrow:在[90]中,Glaese等人提出了Sparrow,这是一种信息搜索对话代理,与提示语言模型基线相比,它被训练得更有帮助、更正确、更无害。他们从人类反馈中使用强化学习来训练他们的模型,并添加了两个新功能,以帮助人类评价代理行为。Sparrow模型的高级流程如图21所示。 |
| Minerva: In [91], Lewkowycz et al. introduced Minerva, a large language model pretrained on general natural language data and further trained on technical content, to tackle previous LLM struggle with quantitative reasoning (such as solving mathematics, science, and engineering problems). | Minerva:在[91]中,Lewkowycz等人引入了Minerva,这是一个在通用自然语言数据上预训练,并在技术内容上进一步训练的大型语言模型,以解决以前LLM在定量推理方面的困难(如解决数学、科学和工程问题)。 |
| MoD: In [92], Tay et al. presented a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. They proposed Mixture-of-Denoisers (MoD), a pretraining objective that combines diverse pre-training paradigms together. This framework is known as Unifying Language Learning (UL2). An overview of UL2 pretraining paradigm is shown in Fig 21. | MoD:在[92]中,Tay等人对NLP中的自监督提出了一个广义和统一的视角,并展示了不同的预训练目标是如何相互作用的,以及不同目标之间的插值是如何有效的。他们提出了混合去噪器(MoD),这是一种将各种预训练范式结合在一起的预训练目标。这个框架被称为统一语言学习(UL2)。UL2预训练范式概述如图21所示。 |
BLOOM(基于ROOTS语料库+仅解码器的Transformer,176B)、GLM(双语(中英文)预训练语言模型+对飙100B级别的GPT-3,130B)、Pythia(由16个LLM组成的套件)
| BLOOM: In [93], Scao et al. presented BLOOM, a 176B parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). An overview of BLOOM architecture is shown in Fig 23. | BLOOM:在[93]中,Scao等人提出了BLOOM,这是一个由数百名研究人员合作设计和构建的176B参数的开放获取语言模型。BLOOM是在ROOTS语料库上训练的仅解码器的Transformer语言模型,ROOTS语料库是一个包含46种自然语言和13种编程语言(总共59种)的数百个源的数据集。BLOOM架构的概述如图23所示。 |
| GLM: In [94], Zeng et al. introduced GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It was an attempt to open-source a 100B-scale model at least as good as GPT-3 (davinci) and unveil how models of such a scale can be successfully pretrained. | GLM: Zeng等人在[94]中介绍了GLM- 130b,这是一个包含130B个参数的双语(中英文)预训练语言模型。它试图开源至少与GPT-3(davinci)一样好的100B规模的模型,并揭示这种规模的模型如何成功地进行预训练。 |
| Pythia: In [95], Biderman et al. introduced Pythia, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. | Pythia:在[95]中,Biderman等人介绍了Pythia,这是一个由16个LLM组成的套件,它们都是在完全相同的顺序上看到的公共数据上训练的,大小从70M到12B个参数不等。我们为16个模型中的每个模型提供154个检查点的公共访问,以及下载和重建其精确训练数据加载器的工具,以供进一步研究。 |
Orca(从GPT-4丰富的信号中学习+解释痕迹+多步思维过程,13B)、StarCoder(8K上下文长度,15B参数/1T的toekn)、KOSMOS(多模态大型语言模型+任意交错的模态数据)
| Orca: In [96], Mukherjee et al. develop Orca, a 13-billion parameter model that learns to imitate the reasoning process of large foundation models. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. | Orca:在[96]中,Mukherjee等人开发了Orca,这是一个13B个参数的模型,可以学习模仿大型基础模型的推理过程。Orca从GPT-4丰富的信号中学习,包括解释痕迹;一步一步的思维过程;以及其他复杂的指导,由ChatGPT的教师协助指导。 |
| StarCoder: In [97], Li et al. introduced StarCoder and StarCoderBase. They are 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on one trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. They fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. They performed the most comprehensive evaluation of Code LLMs to date and showed that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model | StarCoder:在[97]中,Li等人介绍了StarCoder和StarCoderBase。它们是15.5B参数模型,具有8K上下文长度,填充能力和通过多查询注意机制实现的快速大批量推理。StarCoderBase是在来自The Stack的1T的toekn上进行培训练的,The Stack是一个具有检查工具和选择退出过程的许可许可GitHub存储库的大型集合。他们在35B Python令牌上对StarCoderBase进行了微调,从而创建了StarCoder。他们对迄今为止最全面的代码LLM进行了评估,结果表明,StarCoderBase优于所有支持多种编程语言的开放代码LLM,并匹配或优于OpenAI代码-cushman-001模型。 |
| KOSMOS: In [98], Huang et al. introduced KOSMOS-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e. zero-shot). Specifically, they trained KOSMOS-1 from scratch on web-scale multi-modal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. Experimental results show that KOSMOS1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). | KOSMOS:在[98]中,Huang等人介绍了KOSMOS-1,这是一种多模态大型语言模型(MLLM),可以感知一般模态,在上下文中学习(即few-shot),并遵循指令(即zero-shot)。具体来说,他们在网络规模的多模态语料库上从头开始训练KOSMOS-1,包括任意交错的文本和图像、图像-标题对和文本数据。实验结果表明,KOSMOS1在以下方面取得了令人印象深刻的表现: (i)语言理解、生成,甚至是无OCR的NLP(直接使用文档图像), (ii)感知语言任务,包括多模态对话、图像字幕、视觉问答,以及 (iii)视觉任务,如带有描述的图像识别(通过文本指令指定分类)。 |
Gemini(多模态模型,基于Transformer解码器+支持32k上下文长度,多个版本)
| Gemini: In [99], Gemini team introduced a new family of multimodal models, that exhibit promising capabilities across image, audio, video, and text understanding. Gemini family includes three versions: Ultra for highly-complex tasks, Pro for enhanced performance and deployability at scale, and Nano for on-device applications. Gemini architecture is built on top of Transformer decoders, and is trained to support 32k context length (via using efficient attention mechanisms). | Gemini:在[99]中,Gemini团队引入了一系列新的多模态模型,这些模型在图像、音频、视频和文本理解方面表现出了很好的能力。Gemini系列包括三个版本: Ultra用于高度复杂的任务, Pro用于增强性能和大规模部署能力,Nano用于设备上应用。 Gemini架构建立在Transformer解码器之上,经过训练支持32k上下文长度(通过使用有效的注意力机制)。 |
| Some of the other popular LLM frameworks (or techniques used for efficient developments of LLMs) includes InnerMonologue [100], Megatron-Turing NLG [101], LongFormer [102], OPT-IML [103], MeTaLM [104], Dromedary [105], Palmyra [106], Camel [107], Yalm [108], MPT [109], ORCA2 [110], Gorilla [67], PAL [111], Claude [112], CodeGen 2 [113], Zephyr [114], Grok [115], Qwen [116], Mamba [30], Mixtral-8x7B [117], DocLLM [118], DeepSeek-Coder [119], FuseLLM-7B [120], TinyLlama-1.1B [121], LLaMA-Pro-8B [122]. | 其他一些流行的LLM框架(或用于有效开发LLM的技术)包括InnerMonologue [100], Megatron-Turing NLG [101], LongFormer [102], OPT-IML [103], MeTaLM [104], Dromedary [105], Palmyra [106], Camel [107], Yalm [108], MPT [109], ORCA2 [110], Gorilla [67], PAL [111], Claude [112], CodeGen 2 [113], Zephyr [114], Grok [115], Qwen [116], Mamba [30], Mixtral-8x7B [117], DocLLM [118], DeepSeek-Coder [119], FuseLLM-7B [120], TinyLlama-1.1B [121], LLaMA-Pro-8B [122]. |
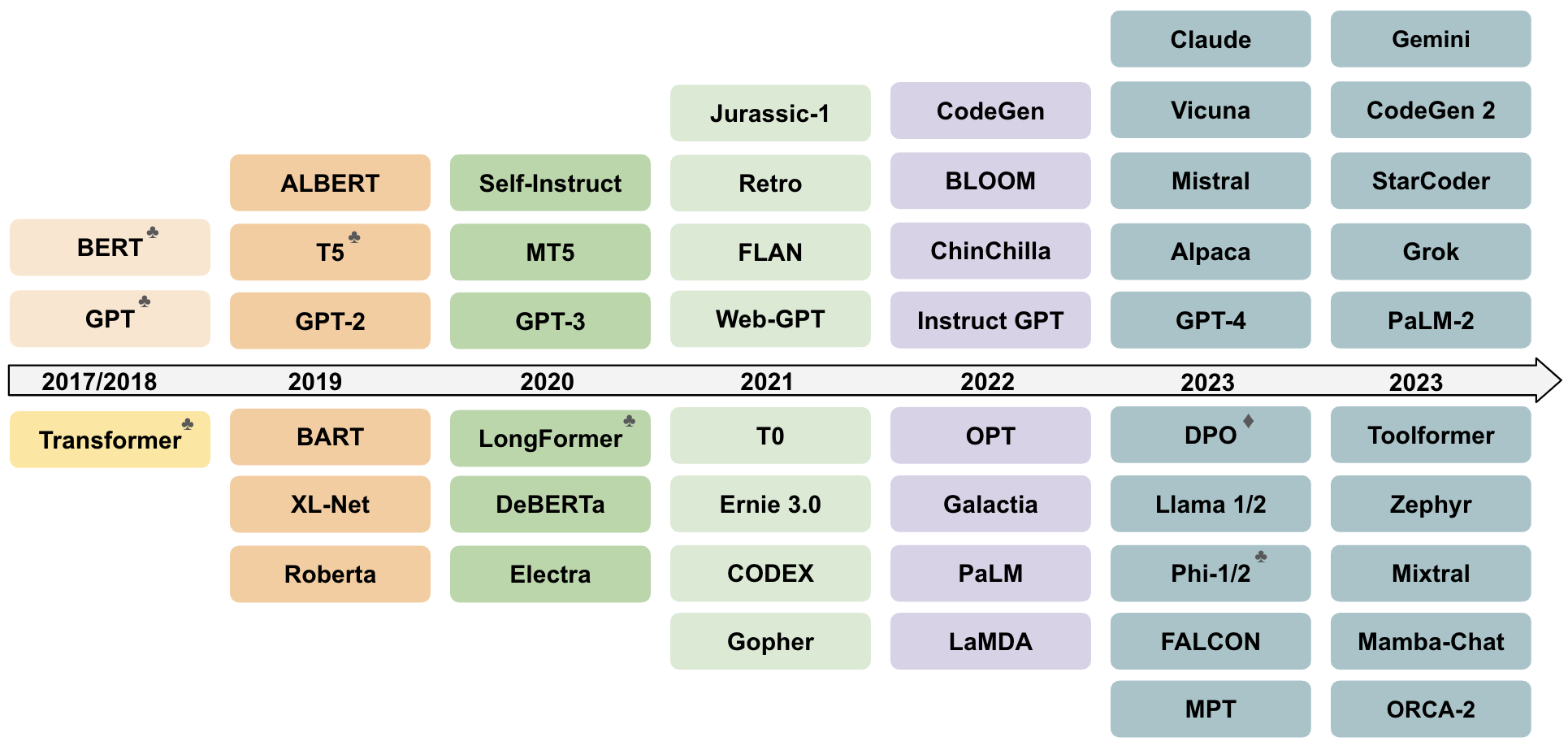
| Fig 24 provides an overview of some of the most representative LLM frameworks, and the relevant works that have contributed to the success of LLMs and helped to push the limits of LLMs. | 图24概述了一些最具代表性的LLM框架,以及为LLM的成功做出贡献并帮助突破LLM极限的相关工作。 |
III. HOW LLMS ARE BUILT如何构建LLMs
数据准备(收集、清理、去重等)→分词→模型预训练(以自监督的学习方式)→指令调优→对齐
| In this section, we first review the popular architectures used for LLMs, and then discuss data and modeling techniques ranging from data preparation, tokenization, to pre-training, instruction tuning, and alignment. Once the model architecture is chosen, the major steps involved in training an LLM includes: data preparation (collection, cleaning, deduping, etc.), tokenization, model pretraining (in a self-supervised learning fashion), instruction tuning, and alignment. We will explain each of them in a separate subsection below. These steps are also illustrated in Fig 25. | 在本节中,我们首先回顾用于LLM的流行架构,然后讨论从数据准备、分词到预训练、指令调优和对齐的数据和建模技术。一旦选择了模型架构,训练LLM所涉及的主要步骤包括:数据准备(收集、清理、去重等)、分词、模型预训练(以自监督的学习方式)、指令调优和对齐。我们将在下面单独的小节中解释它们。图25也说明了这些步骤。 |
Fig. 25: This figure shows different components of LLMs.
A. Dominant LLM Architectures主流LLM架构(即基于Transformer)
| The most widely used LLM architectures are encoder-only, decoder-only, and encoder-decoder. Most of them are based on Transformer (as the building block). Therefore we also review the Transformer architecture here. | 最广泛使用的LLM架构是仅编码器、仅解码器和编码器-解码器。它们中的大多数都基于Transformer(作为构建块)。因此,我们也在这里回顾一下Transformer架构。 |
Fig. 24: Timeline of some of the most representative LLM frameworks (so far). In addition to large language models with our #parameters threshold, we included a few representative works, which pushed the limits of language models, and paved the way for their success (e.g. vanilla Transformer, BERT, GPT-1), as well as some small language models. ♣ shows entities that serve not only as models but also as approaches. ♦ shows only approaches.
1) Transformer
最初是为使用GPU进行有效的并行计算而设计,核心是(自)注意机制,比递归和卷积机制更有效地捕获长期上下文
| 1) Transformer: in a ground-breaking work [44], Vaswani et al. proposed the Transformer framework, which was originally designed for effective parallel computing using GPUs. The heart of Transformer is the (self-)attention mechanism, which can capture long-term contextual information much more effectively using GPUs than the recurrence and convolution mechanisms. Fig 26 provides a high-level overview of transformer work. In this section we provide an overview of the main elements and variants, see [44], [123] for more details. | 1) Transformer:在一项开创性的工作[44]中,Vaswani等人提出了Transformer框架,该框架最初是为使用GPU进行有效的并行计算而设计的。Transformer的核心是(自)注意机制,它可以使用GPU比递归和卷积机制更有效地捕获长期上下文信息。图26提供了Transformer工作的高级概述。在本节中,我们提供了主要元素和变体的概述,参见[44],[123]了解更多细节。 |
Fig. 26: High-level overview of transformer work. Courtesy of [44].
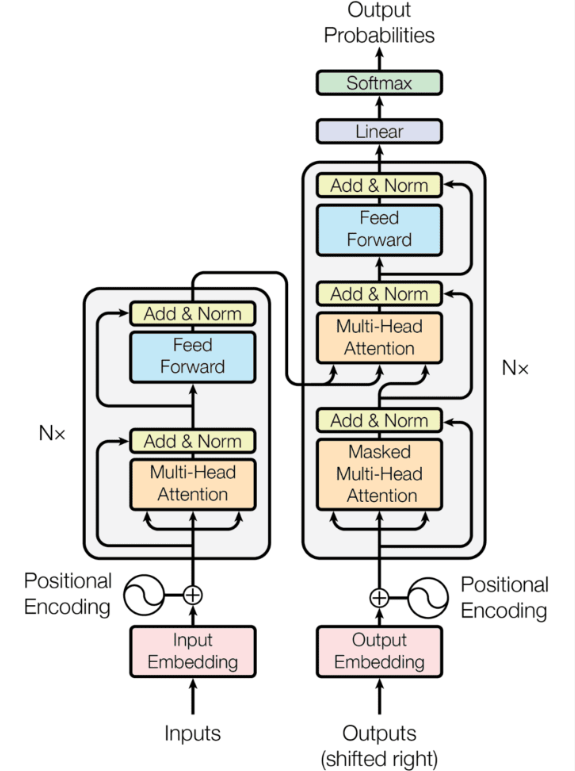
最初用于机器翻译,由一个编码器和一个解码器组成
| The Transformer language model architecture, originally proposed for machine translation, consists of an encoder and a decoder. The encoder is composed of a stack of N = 6 identical Transformer layers. Each layer has two sub-layers. The first one is a multi-head self-attention layer, and the other one is a simple position-wise fully connected feed-forward network. The decoder is composed of a stack of 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder has a third sub-layer, which performs multi-head attention over the output of the encoder stack. The attention function can be described as mapping a query and a set of keyvalue pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. Instead of performing a single attention function with dmodel dimensional keys, values and queries, it is found to be beneficial to linearly project the queries, keys and values h with different, learned linear projections to dk, dk and dv dimensions, respectively. Positional encoding is incorporated to fuse information about the relative or absolute position of the tokens in the sequence. | Transformer语言模型架构最初是为机器翻译提出的,它由一个编码器和一个解码器组成。 >> 编码器由N = 6个相同的Transformer层堆叠而成。每一层有2个子层。第一个是多头自注意层,另一个是简单的位置全连接前馈网络。 >> 解码器由6个相同的层堆栈组成。除了每个编码器层中的两个子层之外,解码器还有第三个子层,该子层对编码器堆栈的输出执行多头注意。 注意函数可以被描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的。与使用d维键、值和查询执行单一的注意函数不同,我们发现将查询、键和值h分别用不同的学习过的线性投影线性投影到dk、dk和dv维是有益的。采用位置编码来融合有关序列中令牌的相对或绝对位置的信息。 |
2) Encoder-Only:注意层都可以访问初始句子中的所有单词,适合需要理解整个序列的任务,例如句子分类、命名实体识别和抽取式问答,比如BERT
| 2) Encoder-Only: For this family, at each stage, the attention layers can access all the words in the initial sentence. The pre-training of these models usually consist of somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence. Encoder models are great for tasks requiring an understanding of the full sequence, such as sentence classification, named entity recognition, and extractive question answering. One prominent encoder only model is BERT (Bidirectional Encoder Representations from Transformers), proposed in [24]. | 2) Encoder-Only:对于这个家族,在每个阶段,注意层都可以访问初始句子中的所有单词。这些模型的预训练通常包括以某种方式破坏给定的句子(例如,通过屏蔽其中的随机单词),并将寻找或重建初始句子的任务交给模型。编码器模型非常适合需要理解整个序列的任务,例如句子分类、命名实体识别和抽取式问答。一个著名的编码器模型是BERT(来自Transformer的双向编码器表示),在[24]中提出。 |
3) Decoder-Only(也被称为自回归模型):注意层只能访问句子中位于其前面的单词,最适合涉及文本生成的任务,比如GPT
| 3) Decoder-Only: For these models, at each stage, for any word, the attention layers can only access the words positioned before that in the sentence. These models are also sometimes called auto-regressive models. The pretraining of these models is usually formulated as predicting the next word (or token) in the sequence. The decoder-only models are best suited for tasks involving text generation. GPT models are prominent example of this model category. | 3) Decoder-Only:对于这些模型,在每个阶段,对于任何单词,注意层只能访问句子中位于其前面的单词。这些模型有时也被称为自回归模型。这些模型的预训练通常被表述为预测序列中的下一个单词(或标记)。只有解码器的模型最适合涉及文本生成的任务。GPT模型是这类模型的突出例子。 |
4) Encoder-Decoder(也被称为序列到序列模型): 最适合基于给定输入生成新句子的任务,比如摘要、翻译或生成式问答
| 4) Encoder-Decoder: These models use both encoder and decoder, and are sometimes called sequence-to-sequence models. At each stage, the attention layers of the encoder can access all the words in the initial sentence, whereas the attention layers of the decoder only accesses the words positioned before a given word in the input. These models are usually pretrained using the objectives of encoder or decoder models, but usually involve something a bit more complex. For instance, some models are pretrained by replacing random spans of text (that can contain several words) with a single mask special word, and the objective is then to predict the text that this mask word replaces. Encoder-decoder models are best suited for tasks about generating new sentences conditioned on a given input, such as summarization, translation, or generative question answering. | 4)编码器-解码器:这些模型同时使用编码器和解码器,有时被称为序列到序列模型。在每个阶段,编码器的注意层可以访问初始句子中的所有单词,而解码器的注意层只能访问输入中位于给定单词之前的单词。这些模型通常使用编码器或解码器模型的目标进行预训练,但通常涉及一些更复杂的东西。例如,一些模型是通过用单个掩码特殊词替换文本的随机跨度(可以包含几个词)来预训练的,然后目标是预测这个掩码词取代的文本。编码器-解码器模型最适合基于给定输入生成新句子的任务,例如摘要、翻译或生成式问答。 |
B. Data Cleaning数据清理
Fig. 27: Subsequent stages of Macrodata Refinement remove nearly 90% of the documents originally in CommonCrawl. Courtesy of [124].

Falcon40B已证明仅对web数据进行适当过滤和去重就可以产生强大的模型,从CommonCrawl获得了5T的token+从REFINEDWEB数据集中提取了600B个token
| Data quality is crucial to the performance of language models trained on them. Data cleaning techniques such as filtering, deduplication, are shown to have a big impact on the model performance. | 数据质量对于在其上训练的语言模型的性能至关重要。数据清理技术(如过滤、去重)对模型性能有很大影响。 |
| As an example, in Falcon40B [124], Penedo et al. showed that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, they were able to obtain five trillion tokens from CommonCrawl. They also released an extract of 600 billion tokens from our REFINEDWEB dataset, and 1.3/7.5B parameters language models trained on it. 27 shows the Refinement process of CommonCrawl data by this work. | 例如,在Falcon40B[124]中,Penedo等人表明,仅对web数据进行适当过滤和去重就可以产生强大的模型;甚至明显超过了在the Pile上训练的最先进的模型。尽管进行了广泛的过滤,他们还是从CommonCrawl获得了5T的token。他们还从REFINEDWEB数据集中提取了600B个token,并在其上训练了1.3/7.5B个参数语言模型。27所示为本工作对CommonCrawl数据的细化过程。 |
数据过滤:目的(数据的高质量+模型的有效性),去除噪声、处理异常值、解决不平衡、文本预处理、处理歧义
| 1) Data Filtering: Data filtering aims to enhance the quality of training data and the effectiveness of the trained LLMs. Common data filtering techniques include: Removing Noise: refers to eliminating irrelevant or noisy data that might impact the model’s ability to generalize well. As an example, one can think of removing false information from the training data, to lower the chance of model generating false responses. Two mainstream approaches for quality filtering includes: classifier-based, and heuristic-based frameworks. Handling Outliers: Identifying and handling outliers or anomalies in the data to prevent them from disproportionately influencing the model. Addressing Imbalances: Balancing the distribution of classes or categories in the dataset to avoid biases and ensure fair representation. This is specially useful for responsible model training and evaluation. Text Preprocessing: Cleaning and standardizing text data by removing stop words, punctuation, or other elements that may not contribute significantly to the model’s learning. Dealing with Ambiguities: Resolving or excluding ambiguous or contradictory data that might confuse the model during training. This can help the model to provide more definite and reliable answers. | 1)数据过滤:数据过滤的目的是提高训练数据的质量和训练出来的LLM的有效性。常见的数据过滤技术包括: >> 去除噪声:指去除可能影响模型泛化能力的不相关或有噪声的数据。例如,可以考虑从训练数据中删除错误信息,以降低模型生成错误响应的可能性。质量过滤的两种主流方法包括:基于分类器的和基于启发式的框架。 >> 处理异常值:识别和处理数据中的异常值或异常,以防止它们对模型产生不成比例的影响。 >> 解决不平衡:平衡数据集中类或类别的分布,以避免偏见并确保公平表示。这对于负责任的模型训练和评估特别有用。。 >> 文本预处理:通过删除停用词、标点符号或其他可能对模型学习没有显著贡献的元素来清理和标准化文本数据。 >> 处理歧义:解决或排除可能在训练期间使模型困惑的歧义或矛盾数据。这可以帮助模型提供更明确和可靠的答案。 |
去重:可提高泛化能力,NLP任务需要多样化和代表性的训练数据,主要依赖于高级特征之间的重叠比率来检测重复样本
| 2) Deduplication: De-duplication refers to the process of removing duplicate instances or repeated occurrences of the same data in a dataset. Duplicate data points can introduce biases in the model training process and reduce the diversity, as the model may learn from the same examples multiple times, potentially leading to overfitting on those particular instances. Some works [125] have shown that de-duplication improves models’ ability to generalize to new, unseen data The de-duplication process is particularly important when dealing with large datasets, as duplicates can unintentionally inflate the importance of certain patterns or characteristics. This is especially relevant in NLP tasks, where diverse and representative training data is crucial for building robust language models. The specific de-duplication method can vary based on the nature of the data and the requirements of the particular language model being trained. It may involve comparing entire data points or specific features to identify and eliminate duplicates. At the document level, existing works mainly rely on the overlap ratio of high-level features (e.g. n-grams overlap) between documents to detect duplicate samples. | 2)重复数据删除:重复数据删除是指删除数据集中重复的实例或重复出现的相同数据的过程。重复的数据点可能会在模型训练过程中引入偏差,并减少多样性,因为模型可能会多次从相同的示例中学习,从而可能导致对这些特定实例的过拟合。一些研究[125]表明,去重可以提高模型对新的、未见过的数据的泛化能力。 在处理大型数据集时,去重过程尤为重要,因为重复数据可能会无意中增加某些模式或特征的重要性。这在NLP任务中尤其重要,在NLP任务中,多样化和代表性的训练数据对于构建健壮的语言模型至关重要。 具体的重复数据删除方法可以根据数据的性质和所训练的特定语言模型的要求而有所不同。它可能涉及比较整个数据点或特定特征,以识别和消除重复项。在文档层面,现有的工作主要依靠文档之间高级特征的重叠比例(如n-grams重叠)来检测重复样本。 |
C. Tokenizations分词:分词器依赖于词典、常用的是基于子词但存在OOV问题,三种流行的分词器
Tokenization是将文本序列分割成较小单元(token)的过程,对自然语言处理任务至关重要
| Tokenization referes to the process of converting a sequence of text into smaller parts, known as tokens. While the simplest tokenization tool simply chops text into tokens based on white space, most tokenization tools rely on a word dictionary. However, out-of-vocabulary (OOV) is a problem in this case because the tokenizer only knows words in its dictionary. To increase the coverage of dictionaries, popular tokenizers used for LLMs are based on sub-words, which can be combined to form a large number of words, including the words unseen in training data or words in different languages. In what follows, we describe three popular tokenizers. | 分词是指将文本序列转换成较小部分的过程,称为标记。虽然最简单的分词工具只是根据空格将文本分成标记,但大多数分词工具依赖于词典。但是,在这种情况下,词汇表外(OOV)是一个问题,因为分词器只知道其词典中的单词。为了增加词典的覆盖率,LLM常用的分词器是基于子词的,子词可以组合成大量的词,包括训练数据中未见的词或不同语言中的词。接下来,我们将介绍三种流行的分词器。 |
BytePairEncoding:最初是一种数据压缩算法,主要是保持频繁词的原始形式,对不常用的词进行分解。通过识别字节级别的频繁模式来压缩数据,有效管理词汇表大小,同时很好地表示常见单词和形态形式
| 1) BytePairEncoding: BytePairEncoding is originally a type of data compression algorithm that uses frequent patterns at byte level to compress the data. By definition, this algorithm mainly tries to keep the frequent words in their original form and break down ones that are not common. This simple paradigm keeps the vocabulary not very large, but also good enough to represent common words at the same time. Also morphological forms of the frequent words can be represented very well if suffix or prefix is also commonly presented in the training data of the algorithm. | 1) BytePairEncoding: BytePairEncoding最初是一种数据压缩算法,它使用字节级的频繁模式来压缩数据。从定义上看,该算法主要是保持频繁词的原始形式,对不常用的词进行分解。这种简单的范例使词汇表不会很大,但同时也足以表示常用词。此外,如果在算法的训练数据中也经常出现后缀或前缀,则可以很好地表示频繁词的形态。 |
WordPieceEncoding:比如BERT和Electra等,确保训练数据中的所有字符都包含在词汇表中,以防止未知token,并根据频率进行标记化
| 2) WordPieceEncoding: This algorithm is mainly used for very well-known models such as BERT and Electra. At the beginning of training, the algorithm takes all the alphabet from the training data to make sure that nothing will be left as UNK or unknown from the training dataset. This case happens when the model is given an input that can not be tokenized by the tokenizer. It mostly happens in cases where some characters are not tokenizable by it. Similar to BytePairEncoding, it tries to maximize the likelihood of putting all the tokens in vocabulary based on their frequency. | 2) WordPieceEncoding:该算法主要用于BERT和Electra等非常知名的模型。在训练开始时,算法从训练数据中提取所有的字母,以确保不会有任何来自训练数据集的未知(UNK)。当给模型一个不能被分词器分词的输入时,就会发生这种情况。这主要发生在一些字符无法被分词器分词的情况下。与BytePairEncoding类似,它试图根据它们的频率最大化将所有标记放入词汇表中。 |
SentencePieceEncoding:解决了具有嘈杂元素或非传统词边界的语言中的分词问题,不依赖于空格分隔
| 3) SentencePieceEncoding: Although both tokenizers described before are strong and have many advantages compared to white-space tokenization, they still take assumption of words being always separated by white-space as granted. This assumption is not always true, in fact in some languages, words can be corrupted by many noisy elements such as unwanted spaces or even invented words. SentencePieceEncoding tries to address this issue. | 3) SentencePieceEncoding:尽管前面描述的两种分词器都很强大,并且与空格分词相比有许多优点,但它们仍然假设单词始终由空格分隔。这种假设并不总是正确的,事实上,在某些语言中,单词可能会被许多噪音元素破坏,例如不需要的空格或甚至是虚构的单词。SentencePieceEncoding试图解决这个问题。 |
D. Positional Encoding位置编码
Fig. 28: Various positional encodings are employed in LLMs.
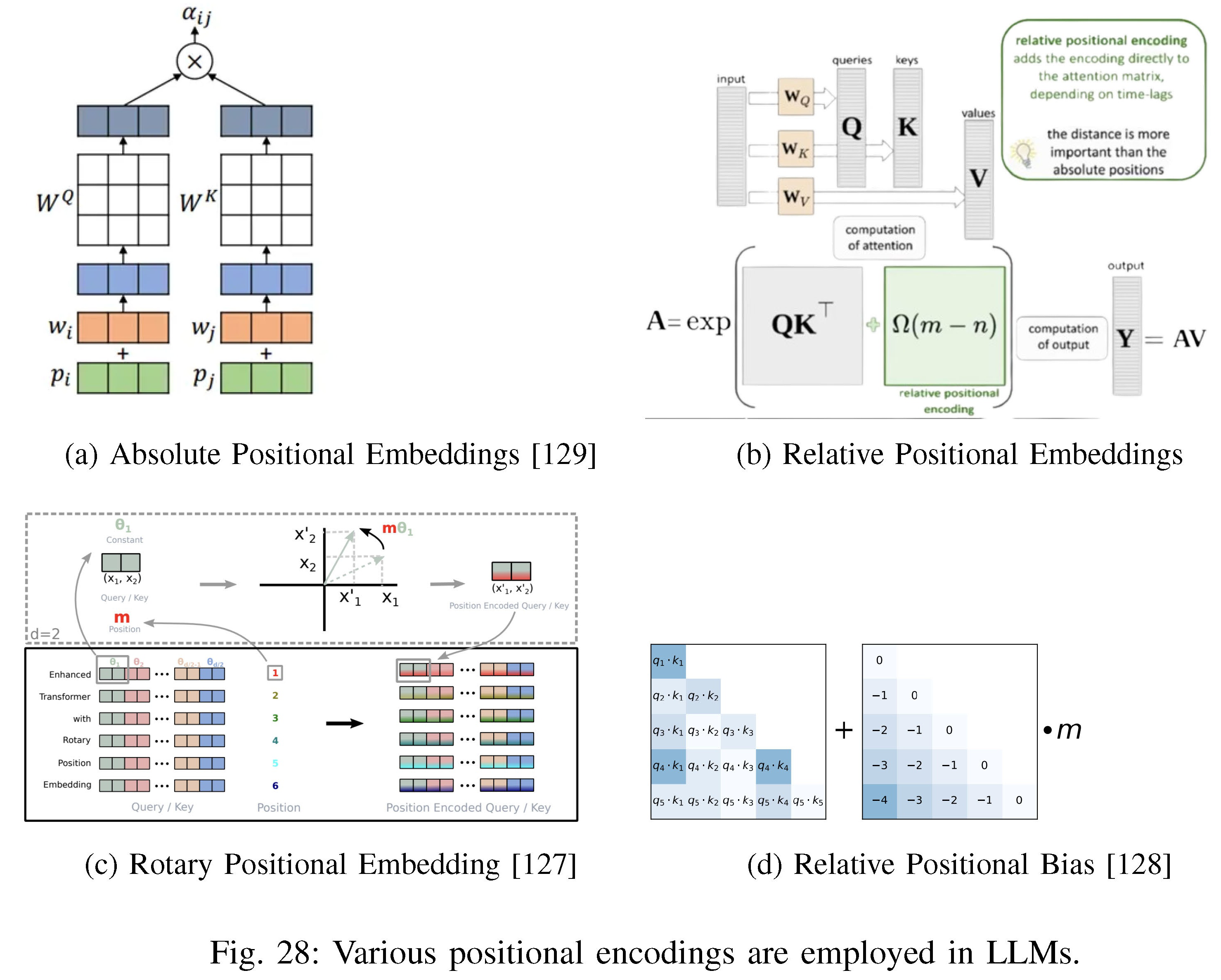
Fig. 29: : Illustration of a Switch Transformer encoder block. They replaced the dense feed forward network (FFN) layer present in the Transformer with a sparse Switch FFN layer (light blue). . Courtesy of [131].
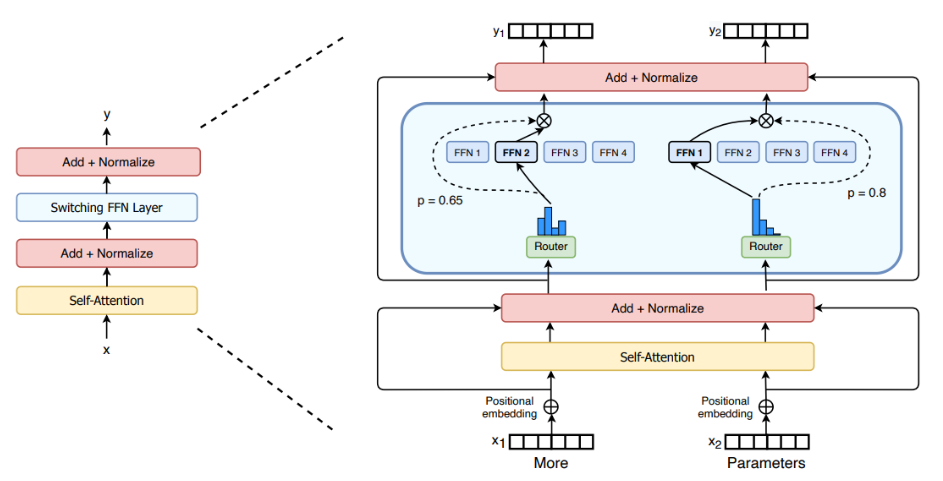
绝对位置编码 (APE):在Transformer模型中被用来保留序列顺序信息,通过在编码器和解码器堆栈底部将词的位置信息添加到输入嵌入中
| 1) Absolute Positional Embeddings: (APE) [44] has been used in the original Transformer model to preserve the information of sequence order. Therefore, the positional information of words is added to the input embeddings at the bottom of both the encoder and decoder stacks. There are various options for positional encodings, either learned or fixed. In the vanilla Transformer, sine and cosine functions are employed for this purpose. The main drawback of using APE in Transformers is the restriction to a certain number of tokens. Additionally, APE fails to account for the relative distances between tokens | 1)绝对位置嵌入:(APE)[44]在原始Transformer模型中被用于保存序列顺序信息。因此,单词的位置信息被添加到编码器和解码器堆栈底部的输入嵌入中。位置编码有多种选择,有的是习得的,有的是固定的。在普通Transformer中,正弦和余弦函数用于此目的。在transformer中使用APE的主要缺点是对一定数量令牌的限制。此外,APE无法解释令牌之间的相对距离 |
相对位置编码(RPE):扩展了自注意力机制,考虑了输入元素之间的成对链接,以及作为密钥的附加组件和值矩阵的子组件。RPE将输入视为具有标签和有向边的完全连接图,并通过限制相对位置来进行预测
| 2) Relative Positional Embeddings: (RPE) [126] involves extending self-attention to take into account the pairwise links between input elements. RPE is added to the model at two levels: first as an additional component to the keys, and subsequently as a sub-component of the values matrix. This approach looks at the input as a fully-connected graph with labels and directed edges. In the case of linear sequences, edges can capture information about the relative position differences between input elements. A clipping distance, represented as k 2 ≤ k ≤ n − 4, specifies the maximum limit on relative locations. This allows the model to make reasonable predictions for sequence lengths that are not part of the training data. | 2)相对位置嵌入:(RPE)[126]涉及扩展自我注意,以考虑输入元素之间的成对链接。RPE在两个级别上被添加到模型中:首先作为键的附加组件,然后作为值矩阵的子组件。这种方法将输入视为具有标签和有向边的全连接图。在线性序列的情况下,边可以捕获输入元素之间相对位置差异的信息。用k2≤k≤n−4表示的裁剪距离表示相对位置的最大限制。这允许模型对不属于训练数据的序列长度做出合理的预测。 |
旋转位置编码(RoPE)通过使用旋转矩阵对词的绝对位置进行编码,并在自注意力中同时包含显式的相对位置细节,提供了灵活性、降低了词之间的依赖性,并能够改进线性自注意力
| 3) Rotary Position Embeddings: Rotary Positional Embedding (RoPE) [127] tackles problems with existing approaches. Learned absolute positional encodings can lack generalizability and meaningfulness, particularly when sentences are short. Moreover, current methods like T5’s positional embedding face challenges with constructing a full attention matrix between positions. RoPE uses a rotation matrix to encode the absolute position of words and simultaneously includes explicit relative position details in self-attention. RoPE brings useful features like flexibility with sentence lengths, a decrease in word dependency as relative distances increase, and the ability to improve linear self-attention with relative position encoding. GPT-NeoX-20B, PaLM, CODEGEN, and LLaMA are among models that take advantage of RoPE in their architectures. | 3)旋转位置嵌入:旋转位置嵌入(RoPE)[127]解决了现有方法的问题。习得的绝对位置编码可能缺乏泛化性和意义,特别是在句子很短的时候。此外,当前的方法,如T5的位置嵌入,面临着在位置之间构建完整注意力矩阵的挑战。RoPE使用旋转矩阵来编码单词的绝对位置,同时在自我注意中包含明确的相对位置细节。RoPE带来了一些有用的特性,比如句子长度的灵活性,随着相对距离的增加而减少单词依赖性,以及通过相对位置编码提高线性自我注意的能力。gpt - neo - 20b、PaLM、CODEGEN和LLaMA都是在其架构中利用RoPE的模型。 |
相对位置偏差(RPA,如ALiBi):旨在在推理时为解决训练中遇到的更长的序列进行外推。ALiBi在注意力分数中引入了一个偏差,对查询-键对的距离施加罚项,以促进在训练中未遇到的序列长度的外推
| 4) Relative Positional Bias: The concept behind this type of positional embedding is to facilitate extrapolation during inference for sequences longer than those encountered in training. In [128] Press et al. proposed Attention with Linear Biases (ALiBi). Instead of simply adding positional embeddings to word embeddings, they introduced a bias to the attention scores of query-key pairs, imposing a penalty proportional to their distance. In the BLOOM model, ALiBi is leveraged. | 4)相对位置偏差:这种类型的位置嵌入背后的概念是在推断比训练中遇到的序列更长的序列时促进外推。Press等人在[128]中提出了线性偏差注意(Attention with Linear Biases, ALiBi)。他们不是简单地在词嵌入中添加位置嵌入,而是引入了对查询键对的注意分数的偏差,并根据它们的距离按比例施加惩罚。在BLOOM模型中,利用了ALiBi。 |
E. Model Pre-training预训练:LLM中的第一步,自监督训练,获得基本的语言理解能力
| Pre-training is the very first step in large language model training pipeline, and it helps LLMs to acquire fundamental language understanding capabilities, which can be useful in a wide range of language related tasks. During pre-training, the LLM is trained on a massive amount of (usually) unlabeled texts, usually in a self-supervised manner. There are different approaches used for pre-training like next sentence prediction [24], two most common ones include, next token prediction (autoregressive language modeling), and masked language modeling. | 预训练是大型语言模型训练管道的第一步,它帮助LLM获得基本的语言理解能力,这在广泛的语言相关任务中是有用的。在预训练期间,LLM通常以自我监督的方式在大量(通常)未标记的文本上进行训练。有不同的方法用于预训练,如下一个句子预测[24],两种最常见的方法包括下一个令牌预测(自回归语言建模)和屏蔽语言建模。 |
T1、自回归语言建模:模型尝试以自回归方式预测给定序列中的下一个标记,通常使用预测标记的对数似然作为损失函数
| In Autoregressive Language Modeling framework, given a sequence of n tokens x1, ..., xn, the model tries to predict next token xn+1 (and sometimes next sequence of tokens) in an auto-regressive fashion. One popular loss function in this case is the log-likelihood of predicted tokens as shown in Eq 2 LALM(x) = X N i=1 p(xi+n|xi , ..., xi+n−1) (1) Given the auto-regressive nature of this framework, the decoder-only models are naturally better suited to learn how to accomplish these task. | 在自回归语言建模框架中,给定n个符号序列x1,…, xn,模型试图以自动回归的方式预测下一个标记xn+1(有时是下一个标记序列)。在这种情况下,一个流行的损失函数是预测标记的对数似然,如Eq 2所示LALM(x) = x N i= 1p (xi+ N |xi,…) |
T2、掩码语言建模(或去噪自编码):通过遮蔽一些词,并根据周围的上下文预测被遮蔽的词
| In Masked Language Modeling, some words are masked in a sequence and the model is trained to predict the masked words based on the surrounding context. Sometimes people refer to this approach as denoising autoencoding, too. If we denote the masked/corrupted samples in the sequence x, as x˜, then the training objective of this approach can be written as: | 在掩码语言建模中,将一些词按序列掩码,然后训练模型根据周围的上下文来预测被掩码词。有时人们也把这种方法称为去噪自动编码。如果我们将序列x中的屏蔽/损坏样本表示为x ~,则该方法的训练目标可以写成: |
T3、混合专家:允许用较少的计算资源进行预训练,通过稀疏MoE层和门控网络或路由器来实现,路由器确定将哪些标记发送到哪个专家,并且可以将一个标记发送给多个专家
| And more recently, Mixture of Experts (MoE) [130], [131] have become very popular in LLM space too. MoEs enable models to be pre-trained with much less compute, which means one can dramatically scale up the model or dataset size with the same compute budget as a dense model. MoE consists of two main elements: Sparse MoE layers, which are used instead of dense feed-forward network (FFN) layers, and have a certain number of “experts” (e.g. 8), in which each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks. A gate network or router, that determines which tokens are sent to which expert. It is worth noting that, one can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network. Fig 29 provides an illustration of a Switch Transformer encoder block, which are used in MoE. | 最近,混合专家(MoE)[130],[131]在LLM领域也变得非常流行。MoEs使模型能够用更少的计算进行预训练,这意味着可以使用与密集模型相同的计算预算来显着扩展模型或数据集的大小。MoE由两个主要元素组成:稀疏MoE层,用于代替密集前馈网络(FFN)层,并且具有一定数量的“专家”(例如8个),其中每个专家是一个神经网络。在实践中,专家是ffn,但它们也可以是更复杂的网络。一种网关网络或路由器,它决定将哪个令牌发送给哪个专家。值得注意的是,一个人可以向多个专家发送令牌。如何将令牌路由给专家是使用moe时的重大决策之一-路由器由学习参数组成,并与网络的其余部分同时进行预训练。图29给出了在MoE中使用的开关Transformer编码器块的示意图。 |
F. Fine-tuning and Instruction Tuning微调和指令调优
有监督微调SFT:早期语言模型(如BERT)经过自监督训练后,需要通过有标签数据进行特定任务的微调,以提高性能
初期的语言模型(如BERT)通过自我监督训练,并不能执行特定任务。为了让基础模型发挥作用,需要使用带有标签数据进行微调,即所谓的监督微调(SFT)。比如,在原始的BERT论文中,模型被微调用于11个不同的任务。
| Early language models such as BERT trained using selfsupervision as explained in section III-E were not able to perform specific tasks. In order for the foundation model to be useful it needed to be fine-tuned to a specific task with labeled data (so-called supervised fine-tuning or SFT for short). For example, in the original BERT paper [24], the model was finetuned to 11 different tasks. While more recent LLMs no longer require fine-tuning to be used, they can still benefit from task or data-specific fine-tuning. For example, OpenAI reports that the much smaller GPT-3.5 Turbo model can outperform GPT-4 when fine-tuned with task specific data 2 . | 如第III-E节所述,早期的语言模型,如BERT,使用自我监督进行训练,无法执行特定的任务。为了使基础模型有用,它需要对带有标记数据的特定任务进行微调(所谓的监督微调或简称SFT)。例如,在最初的BERT论文[24]中,模型被微调到11个不同的任务。虽然最近的LLM不再需要使用微调,但它们仍然可以从任务或数据特定的微调中受益。例如,OpenAI报告说,更小的GPT-3.5 Turbo模型在对任务特定数据进行微调后,可以胜过GPT-4。 |
微调的意义:微调不仅可以针对单一任务进行,还可以采用多任务微调的方法,这有助于提高结果并减少提示工程的复杂性
虽然最近的LLMs不再需要微调就能使用,但它们仍然可以从任务或数据特定的微调中受益。微调到一个或多个任务已被证明可以改善结果,并减少提示工程的复杂性,也可以作为检索增强生成的替代方法。
| Fine-tuning does not need to be performed to a single task though, and there are different approaches to multi-task fine-tuning (see e.g. Mahabi et al. [132]). Fine-tuning to one or more tasks is known to improve results and reduce the complexity of prompt engineering, and it can serve as an alternative to retrieval augmented generation. Furthermore, there are other reasons why it might be advisable to fine-tune. For example, one might want to fine-tune to expose the model to new or proprietary data that it has not been exposed to during pre-training. | 然而,微调并不需要对单个任务执行,多任务微调有不同的方法(参见Mahabi等人[132])。已知对一个或多个任务进行微调可以改善结果并降低提示工程的复杂性,并且可以作为检索增强生成的替代方法。此外,还有其他原因可能建议进行微调。例如,可能需要对模型进行微调,以便将其暴露给在预训练期间未暴露的新数据或专有数据。 |
指令微调:对LLMs进行微调的重要原因之一是将其响应与人类通过提示提供的期望进行对齐,比如InstructGPT和Alpaca
对LLMs进行微调的一个重要原因是使其响应与人类在提供提示时的期望一致。这就是所谓的指令微调。指令微调数据集包括任务定义以及其他组件,如正/负样本或需要避免的内容。
对LLMs进行指令微调的具体方法和数据集各不相同,但通常来说,进行指令微调的模型在性能上优于它们所基于的原始基础模型。
指导调整的数据集包括任务定义以及正面/负面示例等其他组件,通常会比其基础模型表现更好,如InstructGPT和Alpaca。Self-Instruct是一种流行的方法,通过引入一个框架来改善预训练语言模型的指导跟随能力,它通过自身生成的指令来微调原始模型
| An important reason to fine-tune LLMs is to align the responses to the expectations humans will have when providing instructions through prompts. This is the so-called instruction tuning [133]. We dive into the details of how to design and engineer prompts in section IV-B, but in the context of instruction tuning, it is important to understand that the instruction is a prompt that specifies the task that the LLM should accomplish. Instruction tuning datasets such as Natural Instructions [134] include not only the task definition but other components such as positive/negative examples or things to avoid. | 对LLM进行微调的一个重要原因是使响应符合人类在通过提示提供指令时的期望。这就是所谓的指令调优[133]。我们将深入研究如何在IV-B节中设计和工程提示的细节,但在指令调优的上下文中,重要的是要理解指令是指定LLM应该完成的任务的提示符。指令调优数据集,如Natural Instructions[134]不仅包括任务定义,还包括其他组件,如正面/负面示例或要避免的事情。 |
| The specific approach and instruction datasets used to instruction-tune an LLM varies, but, generally speaking, instruction tuned models outperform their original foundation models they are based on. For example, InstructGPT [59] outperforms GPT-3 on most benchmarks. The same is true for Alpaca [62] when compared to LLaMA. | 用于指令调优LLM的具体方法和指令数据集各不相同,但是,一般来说,指令调优模型优于它们所基于的原始基础模型。例如,在大多数基准测试中,InstructGPT[59]优于GPT-3。与LLaMA相比,Alpaca也是如此[62]。 |
| Self-Instruct [135], proposed by Wang et al. is also a popular approach along this line, in which they introduced a framework for improving the instruction-following capabilities of pre-trained language models by bootstrapping their own generations. Their pipeline generates instructions, input, and output samples from a language model, then filters invalid or similar ones before using them to fine tune the original model. | Wang等人提出的self - instruction[135]也是这条路线上的一种流行方法,他们引入了一个框架,通过引导自己的代来提高预训练语言模型的指令跟随能力。他们的管道从语言模型生成指令、输入和输出样本,然后过滤无效的或类似的样本,然后使用它们对原始模型进行微调。 |
G. Alignment对齐
背景:AI 对齐是将AI系统引导向人类目标、偏好和原则的过程。LLMs通常被预训练用于单词预测,但往往会展现出意外行为,例如生成有毒、有害、误导性和偏见的内容。指令微调将LLMs进一步接近对齐,但在许多情况下,需要包括进一步的步骤来改进模型的对齐并避免意外行为
| AI Alignment is the process of steering AI systems towards human goals, preferences, and principles. LLMs, pre-trained for word prediction, often exhibit unintended behaviors. For example, they might generate contents that are toxic, harmful, misleading and biased. | AI对齐是指引导AI系统朝着人类的目标、偏好和原则发展的过程。LLM,预先训练单词预测,经常表现出意想不到的行为。例如,他们可能会产生有毒、有害、误导和有偏见的内容。 |
| Instruction tuning, discussed above, gets LLMs a step closer to being aligned. However, in many cases, it is important to include further steps to improve the alignment of the model and avoid unintended behaviors 3 . We review the most popular approaches to alignment in this subsection. | 上面讨论的指令调优使LLM更接近于一致。然而,在许多情况下,包括进一步的步骤来改进模型的一致性和避免意外的行为是很重要的。在本小节中,我们回顾了最流行的对齐方法。 |
RLHF(利用奖励模型从人类反馈中学习对齐)和RLAIF(从AI反馈中学习对齐)
指令微调使LLMs更接近对齐,但通常需要进一步的步骤来改善模型的对齐并避免意外行为。RLHF和RLAIF是两种常见的方法,其中RLHF利用奖励模型从人类反馈中学习对齐,而RLAIF直接将预训练且对齐良好的模型连接到LLM中,并帮助其从更大且对齐的模型中学习。
| RLHF (reinforcement learning from human feedback) and RLAIF (reinforcement learning from AI feedback) are two popular approaches. RLHF uses a reward model to learn alignment from human feedback. This reward model, after being tuned, is able to rate different outputs and score them according to their alignment preferences given by humans. The reward model gives feedback to the original LLM and this feedback is used to tune the LLM further [137]. Reinforcement learning from AI feedback on the other hand, directly connects a pretrained and well-aligned model to the LLM and helps it to learn from larger and more aligned models [138]. | RLHF(基于人类反馈的强化学习)和RLAIF(基于人工智能反馈的强化学习)是两种流行的方法。RLHF使用奖励模型从人类反馈中学习对齐。这个奖励模型经过调整后,能够对不同的输出进行评级,并根据人类给出的对齐偏好对它们进行评分。奖励模型向原始LLM提供反馈,该反馈用于进一步调整LLM[137]。另一方面,来自AI反馈的强化学习直接将预训练的、对齐良好的模型与LLM连接起来,并帮助它从更大、更对齐的模型中学习[138]。 |
DPO(解决了RLHF的稳定性问题):
最近的DPO方法解决了RLHF的稳定性问题,并且无需奖励模型拟合、在微调过程中从LLM中采样或进行大量的超参数调整。
| In another recent work (known as DPO) [139], Rafailov et al. discussed that RLHF is a complex and often unstable procedure, and tried to address this with a new approach. They leveraged a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data. The resulting algorithm, which they called Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during finetuning, or performing significant hyperparameter tuning. They observed that fine-tuning with DPO exceeds RLHF’s ability to control sentiment of generations and improves response quality in summarization. Fig 30 shows the high-level comparison between DPO vs RLHF. | 在最近的另一项工作(称为DPO)[139]中,Rafailov等人讨论了RLHF是一个复杂且通常不稳定的过程,并试图用一种新的方法来解决这个问题。他们利用奖励函数和最优策略之间的映射来表明,这种受限的奖励最大化问题可以通过单一阶段的策略训练精确地优化,本质上解决了人类偏好数据的分类问题。由此产生的算法,他们称之为直接偏好优化(DPO),稳定,高性能,计算量轻,消除了拟合奖励模型,在微调期间从LM采样或执行重要的超参数调整的需要。他们观察到,DPO的微调超过了RLHF控制几代人情绪的能力,并在总结中提高了反应质量。图30显示了DPO与RLHF的高层对比。 |
Fig. 30: DPO optimizes for human preferences while avoiding reinforcement learning. Existing methods for fine-tuning lan-guage models with human feedback first fit a reward model to a dataset of prompts and human preferences over pairs of responses, and then use RL to find a policy that maximizes the learned reward. In contrast, DPO directly optimizes for the policy best satisfying the preferences with a simple classi-fication objective, without an explicit reward function or RL. Courtesy of [139].
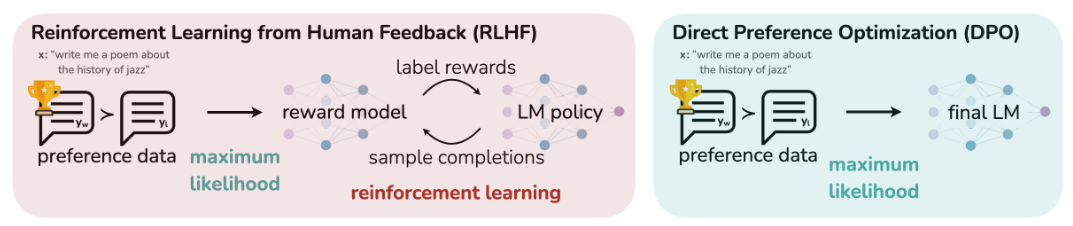
KTO:比DPO更易于在现实世界中使用
Ethayarajh等人提出了一种名为KTO的新的对齐方法,它与现有的最先进方法不同,KTO不需要成对的偏好数据,而是只需要(x,y)以及y是可取或不可取的知识。KTO对齐模型在1B到30B的规模上表现良好,并且比DPO对齐模型更易于在现实世界中使用。
| Even more recently Ethayarajh et al. proposed a new alignment approach called the Kahneman-Tversky Optimization (KTO) [136]. Unlike existing state-of-the-art approaches, KTO does not require paired preference data (x, yw, yl), and it only needs (x,y) and knowledge of whether y is desirable or undesirable. KTO-aligned models are shown to be good or better than DPO-aligned models at scales from 1B to 30B, despite not using paired preferences. KTO is also far easier to use in the real world than preference optimization methods, as the kind of data it needs is far more abundant. As an example, every retail company has a lot of customer interaction data and whether that interaction was successful (e.g., purchase made) or unsuccessful (e.g., no purchase made). However, They have little to no counterfactual data (i.e., what would have made an unsuccessful customer interaction yl into a successful one yw). Fig 31 shows a high-level comparison between KTO and other alignment approaches discussed above. | 最近,Ethayarajh等人提出了一种新的对齐方法,称为Kahneman-Tversky优化(KTO)[136]。与现有的最先进的方法不同,KTO不需要配对的偏好数据(x, yw, yl),它只需要(x,y)和y是否可取的知识。尽管没有使用配对偏好,但在1B到30B的尺度上,kto对齐模型显示出比dpo对齐模型更好或更好。在现实世界中,KTO比偏好优化方法更容易使用,因为它需要的数据种类要丰富得多。例如,每个零售公司都有大量的客户交互数据,以及该交互是否成功(例如,购买)或不成功(例如,未购买)。然而,他们几乎没有反事实数据(也就是说,是什么让一个不成功的客户交互变成了一个成功的客户交互)。图31显示了KTO和上面讨论的其他对准方法之间的高层次比较。 |
Fig. 31: LLM alignment involves supervised finetuning fol-lowed by optimizing a human-centered loss (HALO). How-ever, the paired preferences that existing approaches need are hard-to-obtain. In contrast, KTO uses a far more abundant kind of data, making it much easier to use in the real world. Courtesy of [136].
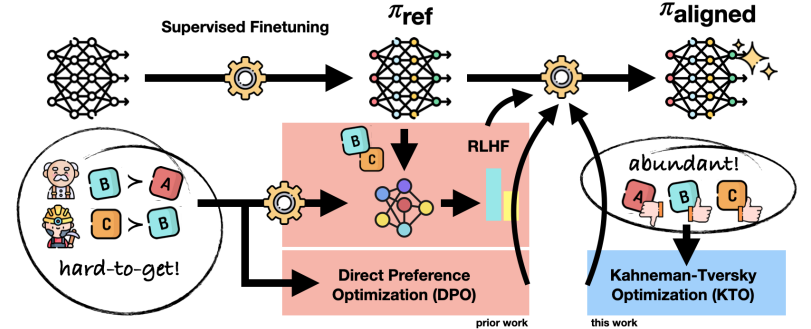
H. Decoding Strategies解码策略
| Decoding refers to the process of text generation using pretrained LLMs. Given an input prompt, the tokenizer translates each token in the input text into a corresponding token ID. Then, the language model uses these token IDs as input and predicts the next most likely token (or a sequence of tokens). Finally, the model generates logits, which are converted to probabilities using a softmax function. Different decoding strategies have been proposed. Some of the most popular ones are greedy search, beam search, as well as different sample techniques such as top-K, top-P (Nucleus sampling). | 解码是指使用预训练的LLM生成文本的过程。给定输入提示,分词器将输入文本中的每个标记转换为相应的标记ID。然后,语言模型使用这些标记id作为输入,并预测下一个最可能的标记(或标记序列)。最后,模型生成logits,使用softmax函数将其转换为概率。人们提出了不同的解码策略。一些最流行的是贪婪搜索,束搜索,以及不同的样本技术,如top-K, top-P(核采样)。 |
贪婪搜索:它在每一步中选择最有可能的标记作为序列的下一个标记,简单快速,但可能失去一些时间连贯性和一致性
| 1) Greedy Search: Greedy search takes the most probable token at each step as the next token in the sequence, discarding all other potential options. As you can imagine, this is a simple approach and can loose a lot of temporal consistency and coherency. It only considers the most probable token at each step, without considering the overall effect on the sequence. This property makes it fast, but it also means that it can miss out on better sequences that might have appeared with slightly less probable next tokens. | 1)贪婪搜索:贪婪搜索将每一步中最可能的令牌作为序列中的下一个令牌,丢弃所有其他可能的选项。可以想象,这是一种简单的方法,可能会失去很多时间一致性和连贯性。它只考虑每一步中最可能的标记,而不考虑对序列的总体影响。这个属性使它更快,但也意味着它可能会错过更好的序列,这些序列可能出现的下一个标记的可能性略低。 |
束搜索:它考虑N个最有可能的标记,直到达到预定义的最大序列长度或出现终止标记,选择具有最高总分数的标记序列作为输出
| 2) Beam Search: Unlike greedy search that only considers the next most probable token, beam search takes into account the N most likely tokens, where N denotes the number of beams. This procedure is repeated until a predefined maximum sequence length is reached or an end-of-sequence token appears. At this point, the sequence of tokens (AKA “beam”) with the highest overall score is chosen as the output. For example for beam size of 2 and maximum length of 5, the beam search needs to keep track of 2 5 = 32 possible sequences. So it is more computationally intensive than greedy search. | 2)束搜索:与贪婪搜索只考虑下一个最可能的标记不同,束搜索考虑了N个最可能的标记,其中N表示束的数量。重复此过程,直到达到预定义的最大序列长度或出现序列结束标记。此时,选择总分最高的令牌序列(又名“beam”)作为输出。例如,对于波束大小为2,最大长度为5,波束搜索需要跟踪2 5 = 32个可能的序列。所以它比贪婪搜索的计算量更大。 |
Top-k 采样:Top-k抽样从k个最可能的选项中随机选择一个标记,以概率分布的形式确定标记的优先级,并引入一定的随机性
| 3) Top-k Sampling: Top-k sampling is a technique that uses the probability distribution generated by the language model to select a token randomly from the k most likely options. Suppose we have 6 tokens (A, B, C, D, E, F) and k=2, and P(A)= 30%, and P(B)= 20%, P(C)= P(D)= P(E)= P(F)= 12.5%. In top-k sampling, tokens C, D, E, F are disregarded, and the model outputs A 60% of the time, and B, 40% of the time. This approach ensures that we prioritize the most probable tokens while introducing an element of randomness in the selection process. The randomness is usually introduced via the concept of temperature. The temperature T is a parameter that ranges from 0 to 1, which affects the probabilities generated by the softmax function, making the most likely tokens more influential. In practice, it simply consists of dividing the input logits by temperature value: A low temperature setting significantly alters the probability distribution (and is commonly used in text generation to control the level of “creativity” in the generated output), while a large temperature prioritizes the tokens with higher probabilities. Top-k is a creative way of sampling, and can be used along with beam search. The sequence chosen by topk sampling may not be the sequence with highest probability in beam search. But it’s important to remember that highest scores do not always lead to more realistic or meaningful sequences. | 3) Top-k 采样: Top-k Sampling是一种利用语言模型生成的概率分布,从k个最可能的选项中随机选择一个token的技术。 假设我们有6个记号(A, B, C, D, E, F), k=2, P(A)= 30%, P(B)= 20%, P(C)= P(D)= P(E)= P(F)= 12.5%。在top-k抽样中,记号C、D、E、F被忽略,模型在60%的时间输出A,在40%的时间输出B。这种方法确保我们优先考虑最可能的标记,同时在选择过程中引入随机性元素。 随机性通常通过温度的概念引入。温度T是一个范围从0到1的参数,它影响softmax函数生成的概率,使最有可能的令牌更有影响力。实际上,它只是由输入对数除以温度值组成: 低温设置会显著改变概率分布(通常用于文本生成,以控制生成输出中的“创造力”水平),而高温设置则优先考虑具有较高概率的标记。Top-k是一种创造性的采样方法,可以与波束搜索一起使用。topk采样所选择的序列不一定是波束搜索中概率最高的序列。但重要的是要记住,高分并不总是带来更现实或更有意义的序列。 |
Top-p抽样:Top-p抽样选择总概率超过阈值p的标记形成的“核心”,这种方法更适合于顶部k标记概率质量不大的情况,通常产生更多样化和创造性的输出
| 4) Top-p Sampling: Top-p sampling, also known as Nucleus sampling, takes a slightly different approach from top-k sampling. Instead of selecting the top k most probable tokens, nucleus sampling chooses a cutoff value p such that the sum of the probabilities of the selected tokens exceeds p. This forms a “nucleus” of tokens from which to randomly choose the next token. In other words, in top-p sampling the language model examines the most probable tokens in descending order and keeps adding them to the list until the sum of probabilities surpasses the threshold p. As you can imagine, this could be better specially for scenarios in which top-k tokens do not have a large probability mass. Unlike top-k sampling, the number of tokens included in the nucleus sampling is not fixed. This variability often results in a more diverse and creative output, making nucleus sampling popular for text generation related tasks. | 4) Top-p抽样:Top-p抽样,也称为核抽样,与top-k抽样的方法略有不同。核抽样不是选择最可能的k个标记,而是选择一个截止值p,使所选标记的概率总和超过p。这形成了一个标记的“核”,从中随机选择下一个标记。换句话说,在top-p采样中,语言模型按降序检查最可能的标记,并不断将它们添加到列表中,直到概率总和超过阈值p。正如您可以想象的那样,这对于top-k标记没有大概率质量的场景可能会更好。与top-k抽样不同,核抽样中包含的令牌数量不是固定的。这种可变性通常会导致更多样化和创造性的输出,使得核采样在文本生成相关任务中很受欢迎。 |
I. Cost-Effective Training/Inference/Adaptation/Compression高效的训练/推理/适应/压缩
| In this part, we review some of the popular approaches used for more cost-friendly (and compute-friendly) training and usage of LLMs. | 在这一部分中,我们回顾了一些用于成本更友好(和计算机友好)的LLM培训和使用的流行方法。 |
优化训练—降存提速:ZeRO(优化内存)和RWKV(模型架构)是优化训练的两个主要框架,能够大幅提高训练速度和效率
| 1) Optimized Training: There are many frameworks developed for optimized training of LLMs, here we introduce some of the prominent ones. | 1)优化训练:针对LLM的优化培训开发了很多框架,这里我们介绍一些比较突出的框架。 |
| ZeRO: In [140], Rajbhandari et al. developed a novel solution, Zero Redundancy Optimizer (ZeRO), to optimize memory, vastly improving training speed of LLMs while increasing the model size that can be efficiently trained. ZeRO eliminates memory redundancies in data- and model-parallel training while retaining low communication volume and high computational granularity, allowing one to scale the model size proportional to the number of devices with sustained high efficiency. | ZeRO:在[140]中,Rajbhandari等人开发了一种新的解决方案ZeRO Redundancy Optimizer (ZeRO)来优化内存,极大地提高了LLM的训练速度,同时增加了可以有效训练的模型大小。ZeRO消除了数据和模型并行训练中的内存冗余,同时保持了低通信量和高计算粒度,允许人们以持续的高效率按比例缩放模型大小。 |
| RWKV: In [141], Peng et al. proposed a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Their approach leverages a linear attention mechanism and allows them to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. RWKV architecture is shown in Fig 32. The Time Complexity comparison of RWKV with different | RWKV:在[141]中,Peng等人提出了一种新的模型架构,即接受加权键值(RWKV),它将Transformer的高效并行训练与RNN的高效推理相结合。他们的方法利用线性注意力机制,并允许他们将模型制定为Transformer或RNN,这可以在训练期间并行计算,并在推理期间保持恒定的计算和内存复杂性,从而使第一个非Transformer架构扩展到数百亿参数。RWKV架构如图32所示。不同RWKV的时间复杂度比较 |
Fig. 32: RWKV architecture. Courtesy of [141].
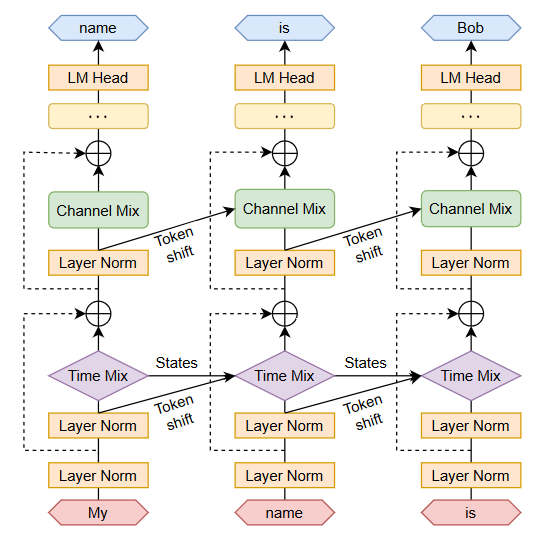
Fig. 33: Time Complexity comparison of RWKV with different Transformers. Here T denotes the sequence length, d the feature dimension, and c is MEGA’s chunk size of quadratic attention. Courtesy of [141].
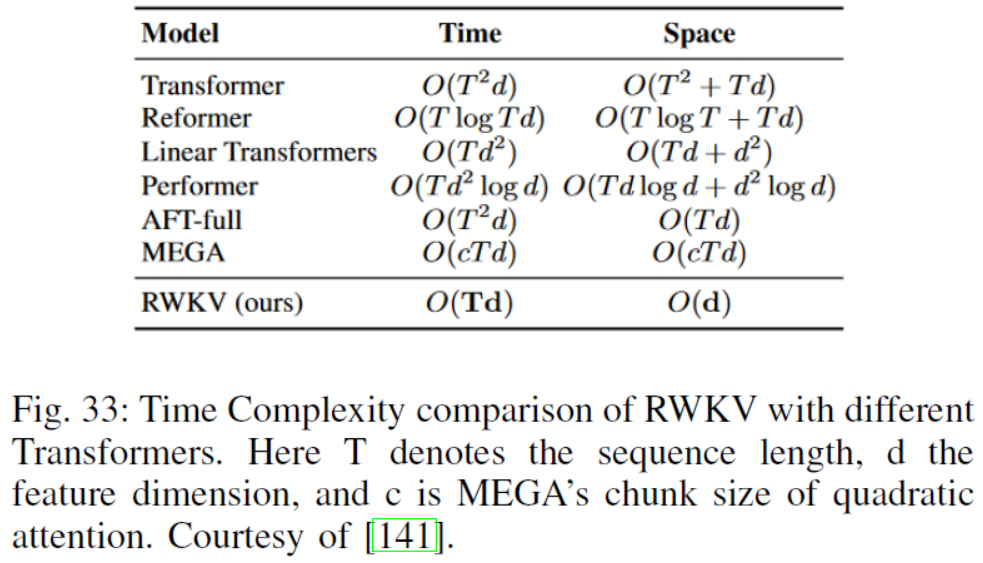
低秩自适应(LoRA)—减参提速:LoRA通过低秩矩阵近似差异化权重,显著减少了可训练参数数量,加快了训练速度,提高了模型效率,同时产生的模型体积更小,易于存储和共享
| 2) Low-Rank Adaption (LoRA): Low-Rank Adaptation is a popular and lightweight training technique that significantly reduces the number of trainable parameters, and is based on a crucial insight that the difference between the finetuned weights for a specialized task and the initial pre-trained weights often exhibits “low intrinsic rank” - meaning that it can be approximated well by a low rank matrix [142]. | 2)低秩自适应(low - rank Adaptation, LoRA):低秩自适应是一种流行的轻量级训练技术,它可以显著减少可训练参数的数量,并且基于一个关键的见解,即特定任务的微调权重与初始预训练权重之间的差异通常表现为“低固有秩”——这意味着它可以通过低秩矩阵很好地近似[142]。 |
| Training with LoRA is much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), that are easier to store and share. One property of low-rank matrices is that they can be represented as the product of two smaller matrices. This realization leads to the hypothesis that this delta between fine-tuned weights and initial pre-trained weights can be represented as the matrix product of two much smaller matrices. By focusing on updating these two smaller matrices rather than the entire original weight matrix, computational efficiency can be substantially improved. | 使用LoRA进行训练速度更快,内存效率更高,并且产生更小的模型权重(几百mb),更容易存储和共享。低秩矩阵的一个性质是它们可以表示为两个较小矩阵的乘积。这种认识导致了一个假设,即微调权重和初始预训练权重之间的增量可以表示为两个小得多的矩阵的矩阵积。通过专注于更新这两个较小的矩阵,而不是整个原始权重矩阵,可以大大提高计算效率。 |
| Specifically, for a pre-trained weight matrix W0 ∈ Rd×k , LoRA constrains its update by representing the latter with a low-rank decomposition W0 + ∆W = W0 + BA, where B ∈ Rd×r , A ∈ Rr×k , and the rank r ≪ min(d, k). During training, W0 is frozen and does not receive gradient updates, while A and B contain trainable parameters. It is worth mentioning that both W0 and ∆W = BA are multiplied with the same input, and their respective output vectors are summed coordinate-wise. For h = W0x, their modified forward pass yields: h = W0x + ∆W x = W0x + BAx. Usually a random Gaussian initialization is used for A, and zero initialization for B, so ∆W = BA is zero at the beginning of training. They then scale ∆W x by αr, where α is a constant in r. This reparametrization is illustrated in Figure 34 | 具体来说,对于一个预训练的权重矩阵W0∈Rd×k, LoRA通过用低阶分解W0 +∆W = W0 + BA来表示它的更新,其中B∈Rd×r, a∈Rr×k,秩r≪min(d, k)。在训练期间,W0被冻结,不接受梯度更新,而a和B包含可训练的参数。值得一提的是,W0和∆W = BA都是用相同的输入相乘,它们各自的输出向量按坐标求和。当h = W0x时,它们的修正前通产率为:h = W0x +∆W x = W0x + BAx。通常对a采用随机高斯初始化,对B采用零初始化,因此在训练开始时∆W = BA为零。然后用αr对∆W x进行缩放,其中α是r中的常数。这种重新参数化如图34所示 |
| It is worth mentioning that LoRA can be applied to any a subset of weight matrices in a neural network to reduce the number of trainable parameters. In the Transformer architecture, there are four weight matrices in the self-attention module (Wq , Wk, Wv , Wo), and two in the MLP module. Most of the time, LoRA is focused on adapting the attention weights only for downstream tasks, and freezes the MLP modules, so they are not trained in downstream tasks both for simplicity and parameter-efficiency | 值得一提的是,LoRA可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。在Transformer架构中,自关注模块中有四个权重矩阵(Wq、Wk、Wv、Wo), MLP模块中有两个权重矩阵。大多数时候,LoRA专注于仅为下游任务调整注意力权重,并冻结MLP模块,因此为了简单性和参数效率,它们不会在下游任务中进行训练 |
Fig. 34: An illustration of LoRA reparametrizan. Only A and B trained during this process. Courtesy of [142].
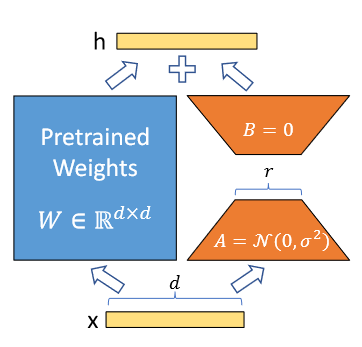
知识蒸馏—轻量级部署提速:知识蒸馏是从更大的模型中学习的过程,通过蒸馏多个模型的知识,创建更小的模型,从而在边缘设备上实现部署,有助于减小模型的体积和复杂度
| 3) Knowledge Distillation: Knowledge distillation is the process of learning from a larger model [143]. Earlier days of best-performing models release have proven that this approach is very useful even if it is used in an API distillation approach. It is also referred to as an approach to distill the knowledge of not a single model but in fact multiple models into a smaller one. Creating smaller models by this approach yields smaller model sizes that can be used even on edge devices. Knowledge distillation as shown in Fig 35, illustrates a general setup of this training scheme. | 3)知识蒸馏:知识蒸馏是从更大的模型中学习的过程[143]。早期发布的最佳性能模型已经证明,即使在API蒸馏方法中使用,这种方法也是非常有用的。它也被称为一种将多个模型的知识提炼成一个更小的模型的方法。通过这种方法创建更小的模型可以产生更小的模型尺寸,甚至可以在边缘设备上使用。图35所示的知识蒸馏说明了该培训方案的总体设置。 |
| Knowledge can be transferred by different forms of learning: response distillation, feature distillation, and API distillation. Response distillation is concerned only with the outputs of the teacher model and tries to teach the student model how to exactly or at least similarly perform (in the sense of prediction) as the teacher. Feature distillation not only uses the last layer but also intermediate layers as well to create a better inner representation for the student model. This helps the smaller model to have a similar representation as the teacher model. | 知识可以通过不同的学习形式进行转移:响应蒸馏、特征蒸馏和API蒸馏。响应蒸馏只关注教师模型的输出,并试图教学生模型如何准确地或至少类似地执行(在预测意义上)作为教师。特征蒸馏不仅使用最后一层,而且还使用中间层来为学生模型创建更好的内部表示。这有助于较小的模型具有与教师模型相似的表示。 |
| API distillation is the process of using an API (typically from an LLM provider such as OpenAI) to train smaller models. In the case of LLMs, it is used to train the model from the direct output of the larger model which makes it very similar to response distillation. Many concerns are raised by this type of distillation because in cases where the model itself is not openly available, a (usually) paid API is exposed for end users. On the other hand, while users pay for each call, how to use the predictions is limited, for example, OpenAI prohibits usage of its API to create LLMs that later will be used to compete with it. The main value in such case is training data. | API蒸馏是使用API(通常来自LLM提供商,如OpenAI)来训练较小模型的过程。在LLM的情况下,它被用来从更大模型的直接输出中训练模型,这使得它非常类似于响应蒸馏。这种类型的蒸馏引起了许多关注,因为在模型本身不是公开可用的情况下,会向最终用户公开(通常)付费API。另一方面,当用户为每次通话付费时,如何使用预测是有限的,例如,OpenAI禁止使用其API创建LLM,这些LLM将被用来与它竞争。在这种情况下,主要的价值是训练数据。 |
Fig. 35: A generic knowledge distillation framework with student and teacher (Courtesy of [144]).
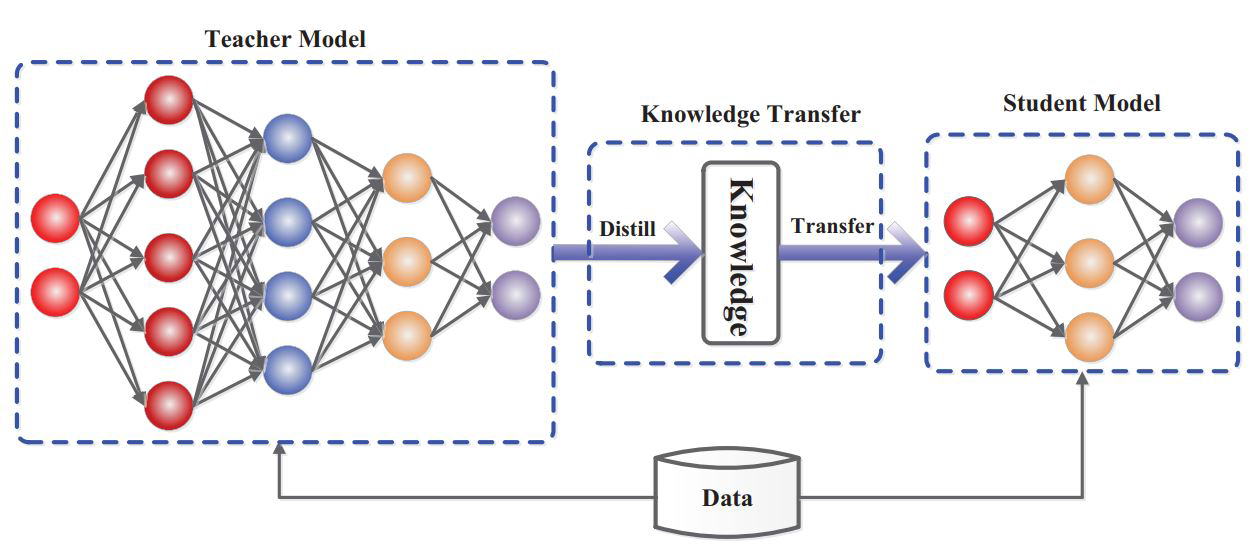
量化—降低精度提速:量化是指减小模型权重的精度,从而减小模型大小并加快推理速度,包括后训练量化和量化感知训练两种方法
| 4) Quantization: deep learning in its core, is a set of mathematical functions applied to matrices, with a specific precision for model weights. Reducing the precision of the weights can be used to reduce the size of the model and also make it faster. As an example, Float-32 operations compared to Int-8 operations are slower. This process, which is called quantization, can be applied in different phases. Main approaches for model quantization can be categorized as: post training quantization and quantization-aware training. Posttraining quantization is concerned with quantized trained models in two well-known methods: dynamic and static. Dynamic post-training quantization computes the range of quantization on the runtime and is slower compared to static. Quantizationaware training adds quantization criteria into training, and a quantized model is trained and optimized during training process. This approach ensures that the end model will have good performance and also does not need to be quantized after training. | 4)量化:深度学习的核心是一组应用于矩阵的数学函数,对模型权重有特定的精度。降低权重的精度可以用来减小模型的大小,并使其更快。例如,与Int-8操作相比,Float-32操作要慢一些。这个过程被称为量化,可以应用于不同的阶段。模型量化的主要方法可分为训练后量化和量化感知训练。训练后量化涉及两种众所周知的方法:动态和静态量化训练模型。动态训练后量化在运行时计算量化的范围,与静态相比速度较慢。量化感知训练在训练中加入量化准则,在训练过程中对量化模型进行训练和优化。这种方法保证了最终模型具有良好的性能,也不需要在训练后进行量化。 |
IV. HOW LLMS ARE USED AND AUGMENTED如何使用和扩展LLMs
| Once the LLMs are trained, we can use them to generate desired outputs for a variety of tasks. LLMs can be used directly through basic prompting. However, in order to exploit their full potential or to address some of the shortcomings, we need to augment the models through some external means. In this section we first provide a brief overview of the main shortcoming of LLMs, with a deeper look at the issue of hallucination. We then describe how prompting and some augmentation approaches can not only address those limitations but also be used to augment the capabilities of LLMs going as far as turning an LLM into a full-blown AI agent with the ability to interface with the external world. | 一旦LLM经过训练,我们就可以使用它们为各种任务生成所需的输出。LLM可以通过基本提示直接使用。然而,为了充分利用它们的潜力或解决一些缺点,我们需要通过一些外部手段来增强模型。在本节中,我们首先简要概述LLM的主要缺点,并深入研究幻觉问题。然后,我们描述了提示和一些增强方法如何不仅可以解决这些限制,还可以用来增强LLM的能力,甚至将LLM转变为具有与外部世界交互能力的成熟AI代理。 |
Fig. 36: How LLMs Are Used and Augmented.
A. LLM limitations局限性
限制:缺乏记忆、随机概率性的、缺乏实时信息、昂贵的GPU、存在幻觉问题
| It is important to remember that LLMs are trained to predict a token. While fine-tuning and alignment improves their performance and adds different dimensions to their abilities, there are still some important limitations that come up, particularly if they are used naively. Some of them include the following: • They don’t have state/memory. LLMs on their own cannot remember even what was sent to them in the previous prompt. That is an important limitation for many of the uses cases that require some form of state. • They are stochastic/probabilistic. If you send the same prompt to an LLM several times, you are likely to get different responses. While there are parameters, and in particular the temperature, to limit the variability in the response, this is an inherent property of their training that can create issues. • They have stale information and, on their own, don’t have access to external data. An LLM on its own does not even know about the current time or day and does not have access to any information that was not present in its training set. • They are generally very large. This means that many costly GPU machines are needed for training and serving. In some cases, largest models have poor SLAs, particularly in terms of latency. • They hallucinate. LLMs do not have a notion of ”truth” and they have usually been trained on a mix of good and bad content. They can produce very plausible but untruthful answers. | 重要的是要记住,LLM是用来预测令牌的。虽然微调和对齐提高了它们的性能,并为它们的能力增加了不同的维度,但仍然存在一些重要的限制,特别是如果它们被天真地使用的话。其中包括以下内容: •它们没有状态/内存。LLM自己甚至不记得在之前的提示中发送给他们的内容。对于许多需要某种形式的状态的用例来说,这是一个重要的限制。 •它们是随机/概率的。如果您多次向LLM发送相同的提示,您可能会得到不同的响应。虽然有参数,特别是温度,来限制反应的可变性,但这是他们训练的固有属性,可能会产生问题。 •他们拥有过时的信息,而且自己无法访问外部数据。LLM本身甚至不知道当前的时间或日期,也无法访问其训练集中不存在的任何信息。 •它们通常非常大。这意味着需要许多昂贵的GPU机器来进行培训和服务。在某些情况下,最大的模型具有较差的sla,特别是在延迟方面。 •他们产生幻觉。LLM没有“真理”的概念,他们通常接受的是好坏参半的培训。他们可以给出看似合理但不真实的答案。 |
探讨幻觉
| While the previous limitations can all become important for some applications, it is worth for us to dive a bit into the last one, hallucinations, since it has gathered a lot of interest over the past few months and it has also sparked many of the prompt approaches and LLM augmentation methods we will later describe | 虽然前面的限制对某些应用程序来说都很重要,但我们有必要深入研究一下最后一个限制,即幻觉,因为在过去的几个月里,它引起了很多人的兴趣,也引发了许多提示方法和LLM增强方法,我们将在后面描述 |
| Hallucination: In the realm of Large Language Models (LLMs), the phenomenon of ”hallucinations” has garnered significant attention. Defined in the literature, notably in the ”Survey of Hallucination in Natural Language Generation” paper [145], hallucination in an LLM is characterized as ”the generation of content that is nonsensical or unfaithful to the provided source.” This terminology, although rooted in psychological parlance, has been appropriated within the field of artificial intelligence. | 幻觉:在大型语言模型(LLM)领域,“幻觉”现象引起了人们的极大关注。在文献中,特别是在“自然语言生成中的幻觉调查”论文[145]中,LLM中的幻觉被定义为“无意义或不忠实于所提供来源的内容的生成”。这个术语虽然源于心理学术语,但在人工智能领域已经被挪用。 |
幻觉的分类:内在幻觉(与源材料直接冲突,引入事实错误或逻辑不一致)、外在幻觉(虽然不矛盾,但无法与源进行验证,包括推测性或不可验证的元素)
| Hallucinations in LLMs can be broadly categorized into two types:
2) Extrinsic Hallucinations: These, while not contradicting, are unverifiable against the source, encompassing speculative or unconfirmable elements. | LLM的幻觉大致可分为两类: 1)内在幻觉:这些与原始材料直接冲突,导致事实不准确或逻辑不一致。 2)外在幻觉:这些虽然不矛盾,但与来源相比是无法证实的,包括推测或无法证实的因素。 |
| The definition of ’source’ in LLM contexts varies with the task. In dialogue-based tasks, it refers to ’world knowledge’, whereas in text summarization, it pertains to the input text itself. This distinction plays a crucial role in evaluating and interpreting hallucinations. The impact of hallucinations is also highly context-dependent. For instance, in creative endeavors like poem writing, hallucinations might be deemed acceptable or even beneficial. | 在LLM环境中,“源”的定义因任务而异。在基于对话的任务中,它指的是“世界知识”,而在文本摘要中,它指的是输入文本本身。这种区别在评估和解释幻觉中起着至关重要的作用。幻觉的影响也是高度依赖于环境的。例如,在创作诗歌等创造性活动中,幻觉可能被认为是可以接受的,甚至是有益的。 |
| LLMs, trained on diverse datasets including the internet, books, and Wikipedia, generate text based on probabilistic models without an inherent understanding of truth or falsity. Recent advancements like instruct tuning and Reinforcement Learning from Human Feedback (RLHF) have attempted to steer LLMs towards more factual outputs, but the fundamental probabilistic nature and its inherent limitations remain. A recent study, “Sources of Hallucination by Large Language Models on Inference Tasks” [146], highlights two key aspects contributing to hallucinations in LLMs: the veracity prior and the relative frequency heuristic, underscoring the complexities inherent in LLM training and output generation. | LLM在不同的数据集上训练,包括互联网、书籍和维基百科,基于概率模型生成文本,而不需要对真假的固有理解。最近的进展,如指导调谐和从人类反馈中强化学习(RLHF),已经试图引导LLM向更真实的输出,但基本的概率性质及其固有的局限性仍然存在。最近的一项研究,“大型语言模型在推理任务上的幻觉来源”[146],强调了LLM中导致幻觉的两个关键方面:准确性先验和相对频率启发,强调了LLM训练和输出生成中固有的复杂性。 |
幻觉的衡量:需要结合统计和基于模型的度量方法,以及人工判断,例如使用ROUGE、BLEU等指标、基于信息提取模型的度量和基于自然语言推理数据集的度量
| Effective automated measurement of hallucinations in LLMs requires a combination of statistical and model-based metrics. Statistical Metrics: • Metrics like ROUGE [147] and BLEU [148] are common for assessing text similarity, focusing on intrinsic hallucinations. • Advanced metrics such as PARENT [149], PARENTT [150], and Knowledge F1 [151] are utilized when structured knowledge sources are available. These metrics, while effective, have limitations in capturing syntactic and semantic nuances. | 在LLM中,有效的幻觉自动测量需要统计和基于模型的度量的结合。统计指标: •ROUGE[147]和BLEU[148]等指标通常用于评估文本相似性,关注内在幻觉。 •高级指标,如PARENT[149]、PARENTT[150]和Knowledge F1[151]在结构化知识来源可用时被使用。这些度量标准虽然有效,但在捕获语法和语义的细微差别方面存在局限性。 |
| Model-Based Metrics: • IE-Based Metrics: Utilize Information Extraction models to simplify knowledge into relational tuples, then compare these with the source. • QA-Based Metrics: Assess the overlap between generated content and the source through a questionanswering framework (see [152]). • NLI-Based Metrics: Use Natural Language Inference datasets to evaluate the truthfulness of a generated hypothesis based on a given premise (see [153]). • Faithfulness Classification Metrics: Offer a refined assessment by creating task-specific datasets for a nuanced evaluation (see [154]). | 基于模型的指标: •基于ie的度量:利用信息提取模型将知识简化为关系元组,然后将其与源进行比较。 •基于qa的度量:通过问答框架评估生成内容和来源之间的重叠(参见[152])。 •基于nli的度量:使用自然语言推理数据集来评估基于给定前提的生成假设的真实性(见[153])。 •忠诚度分类指标:通过创建特定于任务的数据集来提供精细的评估,以进行细致的评估(参见[154])。 |
人类判断
| Despite advances in automated metrics, human judgment remains a vital piece. It typically involves two methodologies:
| 尽管自动化指标取得了进步,但人类的判断仍然是至关重要的一部分。它通常涉及两种方法: 1)评分:人类评估者在预定义的尺度内对幻觉的水平进行评分。 2)比较分析:评估者将生成的内容与基线或基本事实参考进行比较,增加一个基本的主观评估层。 |
FactScore:最近的一个度量标准的例子,它既可以用于人类评估,也可以用于基于模型的评估
| FactScore [155] is a recent example of a metric that can be used both for human and model-based evaluation. The metric breaks an LLM generation into “atomic facts”. The final score is computed as the sum of the accuracy of each atomic fact, giving each of them equal weight. Accuracy is a binary number that simply states whether the atomic fact is supported by the source. The authors implement different automation strategies that use LLMs to estimate this metric. | FactScore[155]是最近的一个度量标准的例子,它既可以用于人类评估,也可以用于基于模型的评估。该指标将LLM生成分解为“原子事实”。最后的分数是计算每个原子事实的准确性的总和,给予每个原子事实相同的权重。精度是一个二进制数,它简单地表示源是否支持原子事实。作者实现了不同的自动化策略,使用LLM来估计这个度量。 |
缓解LLM幻觉的挑战:包括产品设计和用户交互策略、数据管理与持续改进、提示工程和元提示设计,以及模型选择和配置
| Finally, mitigating hallucinations in LLMs is a multifaceted challenge, requiring tailored strategies to suit various applications. Those include: • Product Design and User Interaction Strategies such as use case design, structuring the input/output, or providing mechanisms for user feedback. • Data Management and Continuous Improvement. Maintaining and analyzing a tracking set of hallucinations is essential for ongoing model improvement. • Prompt Engineering and Metaprompt Design. Many of the advanced prompt techniques described in IV-B such as Retrieval Augmented Generation directly address hallucination risks. • Model Selection and Configuration for Hallucination Mitigation. For exemple, larger models with lower temperature settings usually perform better. Also, techniques such as RLHF or domain-sepcific finetuning can mitigate hallucination risks. | 最后,减轻LLM的幻觉是一个多方面的挑战,需要量身定制的策略来适应不同的应用。这些包括: •产品设计和用户交互策略,如用例设计,结构化输入/输出,或为用户反馈提供机制。 •数据管理和持续改进。维护和分析幻觉跟踪集对于正在进行的模型改进至关重要。 •提示工程和元提示设计。IV-B中描述的许多先进提示技术,如检索增强生成,直接解决了幻觉风险。 •缓解幻觉的模型选择和配置。例如,温度设置较低的大型模型通常表现更好。此外,RLHF或特定领域微调等技术可以减轻幻觉风险。 |
B. Using LLMs: Prompt Design and Engineering提示设计和工程
提示工程是塑造LLM及其他生成式人工智能模型交互和输出的迅速发展学科,需要结合领域知识、对模型的理解以及为不同情境量身定制提示的方法论
Prompt是引导生成式AI模型输出的文本输入
| A prompt in generative AI models is the textual input provided by users to guide the model’s output. This could range from simple questions to detailed descriptions or specific tasks. Prompts generally consist of instructions, questions, input data, and examples. In practice, to elicit a desired response from an AI model, a prompt must contain either instructions or questions, with other elements being optional. Advanced prompts involve more complex structures, such as ”chain of thought” prompting, where the model is guided to follow a logical reasoning process to arrive at an answer. | 生成式AI模型中的提示符是用户提供的用于指导模型输出的文本输入。这可以从简单的问题到详细的描述或具体的任务。提示通常由指令、问题、输入数据和示例组成。在实践中,为了从AI模型中引出期望的响应,提示必须包含指令或问题,其他元素是可选的。高级提示包含更复杂的结构,比如“思维链”提示,在这种提示中,模型被引导遵循逻辑推理过程来得出答案。 |
Prompt工程是一门不断发展的学科,通过设计最佳Prompt来实现特定目标
| Prompt engineering is a rapidly evolving discipline that shapes the interactions and outputs of LLMs and other generative AI models. The essence of prompt engineering lies in crafting the optimal prompt to achieve a specific goal with a generative model. This process is not only about instructing the model but also involves some understanding of the model’s capabilities and limitations, and the context within which it operates. | 提示工程是一门快速发展的学科,它塑造了LLM和其他生成式人工智能模型的交互和输出。提示工程的本质在于用生成模型制作最佳提示以实现特定目标。这个过程不仅是关于指导模型,而且还涉及到对模型的能力和限制的一些理解,以及它所处的环境。 |
Prompt工程涉及领域知识、模型能力、以及上下文理解
| Prompt engineering transcends the mere construction of prompts; it requires a blend of domain knowledge, understanding of the AI model, and a methodical approach to tailor prompts for different contexts. This might involve creating templates that can be programmatically modified based on a given dataset or context. For example, generating personalized responses based on user data might use a template that is dynamically filled with relevant user information. | 提示工程超越了提示的单纯构建;它需要混合领域知识、对人工智能模型的理解,以及针对不同上下文定制提示的系统方法。这可能涉及到创建可以基于给定数据集或上下文以编程方式修改的模板。例如,基于用户数据生成个性化响应可能会使用动态填充相关用户信息的模板。 |
| Furthermore, prompt engineering is an iterative and exploratory process, akin to traditional machine learning practices such as model evaluation or hyperparameter tuning. The rapid growth of this field suggests its potential to revolutionize certain aspects of machine learning, moving beyond traditional methods like feature or architecture engineering. On the other hand, traditional engineering practices such as version control and regression testing need to be adapted to this new paradigm just like they were adapted to other machine learning approaches [156]. | 此外,提示工程是一个迭代和探索的过程,类似于传统的机器学习实践,如模型评估或超参数调优。该领域的快速发展表明,它有可能彻底改变机器学习的某些方面,超越传统的方法,如特征或架构工程。另一方面,版本控制和回归测试等传统工程实践需要适应这种新范式,就像它们适应其他机器学习方法一样[156]。 |
主要的Prompt工程方法包括:CoT、ToT、自我一致性、反思、专家提示、链条和轨道
示工程涉及多种方法,包括“思维链”、“思维树”、“自我一致性”、“反思”、“专家提示”、“链”和“规则”,这些方法可以根据任务需求进行选择和应用
| In the following paragraphs we detail some of the most interesting and popular prompt engineering approaches. | 在下面的段落中,我们将详细介绍一些最有趣和最流行的提示工程方法。 |
| 1) Chain of Thought (CoT): The Chain of Thought (CoT) technique, initially described in the paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”[34] by Google researchers, represents a pivotal advancement in prompt engineering for Large Language Models (LLMs). This approach hinges on the understanding that LLMs, while proficient in token prediction, are not inherently designed for explicit reasoning. CoT addresses this by guiding the model through essential reasoning steps. CoT is based on making the implicit reasoning process of LLMs explicit. By outlining the steps required for reasoning, the model is directed closer to a logical and reasoned output, especially in scenarios demanding more than simple information retrieval or pattern recognition. CoT prompting manifests in two primary forms:
Manual CoT is more effective than zero-shot. However, the effectiveness of this example-based CoT depends on the choice of diverse examples, and constructing prompts with such examples of step by step reasoning by hand is hard and error prone. That is where automatic CoT [157] comes into play | 1)思维链(Chain of Thought, CoT):思维链(Chain of Thought, CoT)技术,最初由Google研究人员在论文“思维链提示在大型语言模型中引出推理”[34]中描述,代表了大型语言模型(LLMs)提示工程的关键进步。这种方法取决于这样一种理解,即LLM虽然精通令牌预测,但本质上并不是为显式推理而设计的。CoT通过引导模型完成基本的推理步骤来解决这个问题。 CoT的基础是使LLM的隐式推理过程显化。通过概述推理所需的步骤,模型更接近于逻辑和推理的输出,特别是在需要比简单的信息检索或模式识别更多的场景中。 CoT提示主要有两种形式: >> Zero-Shot CoT:这种形式包括指导LLM“一步一步地思考”,促使其解构问题并阐明推理的每个阶段。 >> Manual CoT:一个更复杂的变体,它需要提供一步一步的推理示例作为模型的模板。虽然产生了更有效的结果,但它在可伸缩性和维护方面提出了挑战。 手动射击比零样本更有效。然而,这种基于示例的CoT的有效性取决于对不同示例的选择,并且用手动逐步推理的示例构建提示很难,而且容易出错。这就是自动CoT[157]发挥作用的地方 |
| 2) Tree of Thought (ToT): The Tree of Thought (ToT) [158] prompting technique is inspired by the concept of considering various alternative solutions or thought processes before converging on the most plausible one. ToT is based on the idea of branching out into multiple ”thought trees” where each branch represents a different line of reasoning. This method allows the LLM to explore various possibilities and hypotheses, much like human cognitive processes where multiple scenarios are considered before determining the most likely one. A critical aspect of ToT is the evaluation of these reasoning paths. As the LLM generates different branches of thought, each is assessed for its validity and relevance to the query. This process involves real-time analysis and comparison of the branches, leading to a selection of the most coherent and logical outcome. ToT is particularly useful in complex problem-solving scenarios where a single line of reasoning might not suffice. It allows LLMs to mimic a more human-like problem-solving approach, considering a range of possibilities before arriving at a conclusion. This technique enhances the model’s ability to handle ambiguity, complexity, and nuanced tasks, making it a valuable tool in advanced AI applications. | 2)思想树(ToT):思想树(ToT)[158]提示技术的灵感来自于在集中于最合理的解决方案之前考虑各种备选解决方案或思维过程的概念。ToT基于分支成多个“思想树”的思想,每个分支代表不同的推理路线。这种方法允许LLM探索各种可能性和假设,就像人类的认知过程一样,在确定最可能的一个之前考虑多个场景。 ToT的一个关键方面是对这些推理路径的评估。当LLM产生不同的思想分支时,每个分支都被评估其有效性和与查询的相关性。这个过程包括对分支的实时分析和比较,从而选择出最连贯和最合乎逻辑的结果。 在单行推理可能不够的复杂问题解决场景中,ToT特别有用。它允许LLM模仿一种更像人类的解决问题的方法,在得出结论之前考虑一系列可能性。该技术增强了模型处理模糊性、复杂性和细微差别任务的能力,使其成为高级AI应用程序中有价值的工具。 |
| 3) Self-Consistency: Self-Consistency [159] utilizes an ensemble-based method, where the LLM is prompted to generate multiple responses to the same query. The consistency among these responses serves as an indicator of their accuracy and reliability. The Self-Consistency approach is grounded in the principle that if an LLM generates multiple, similar responses to the same prompt, it is more likely that the response is accurate. This method involves asking the LLM to tackle a query multiple times, each time analyzing the response for consistency. This technique is especially useful in scenarios where factual accuracy and precision are paramount. The consistency of responses can be measured using various methods. One common approach is to analyze the overlap in the content of the responses. Other methods may include comparing the semantic similarity of responses or employing more sophisticated techniques like BERT-scores or n-gram overlaps. These measures help in quantifying the level of agreement among the responses generated by the LLM. Self-Consistency has significant applications in fields where the veracity of information is critical. It is particularly relevant in scenarios like fact-checking, where ensuring the accuracy of information provided by AI models is essential. By employing this technique, prompt engineers can enhance the trustworthiness of LLMs, making them more reliable for tasks that require high levels of factual accuracy. | 3)自一致性:自一致性[159]采用基于集成的方法,其中LLM被提示对同一查询生成多个响应。这些反应之间的一致性是其准确性和可靠性的一个指标。 自一致性方法的基础原则是,如果LLM对同一提示生成多个类似的响应,则响应更有可能是准确的。这种方法要求LLM多次处理查询,每次都分析响应的一致性。这种技术在事实的准确性和精确性至关重要的情况下特别有用。 响应的一致性可以用不同的方法来测量。一种常见的方法是分析回复内容中的重叠部分。其他方法可能包括比较回答的语义相似性或采用更复杂的技术,如bert分数或n-gram重叠。这些措施有助于量化LLM产生的回应之间的一致程度。 自一致性在信息准确性要求很高的领域有着重要的应用。它在事实核查等场景中尤为重要,在这些场景中,确保人工智能模型提供的信息的准确性至关重要。通过采用这种技术,提示工程师可以提高LLM的可信度,使其在需要高水平事实准确性的任务中更加可靠。 |
| 4) Reflection: Reflection [160] involves prompting LLMs to assess and potentially revise their own outputs based on reasoning about the correctness and coherence of their responses. The concept of Reflection centers on the ability of LLMs to engage in a form of self-evaluation. After generating an initial response, the model is prompted to reflect on its own output, considering factors like factual accuracy, logical consistency, and relevance. This introspective process can lead to the generation of revised or improved responses. A key aspect of Reflection is the LLM’s capacity for self-editing. By evaluating its initial response, the model can identify potential errors or areas of improvement. This iterative process of generation, reflection, and revision enables the LLM to refine its output, enhancing the overall quality and reliability of its responses. | 4)反思:反思[160]涉及促使LLM基于对其回答的正确性和连贯性的推理来评估和潜在地修改他们自己的产出。反思的概念集中在LLM参与自我评估的能力上。在生成初始响应后,会提示模型考虑事实准确性、逻辑一致性和相关性等因素,对自己的输出进行反思。这种内省过程可以导致产生修订或改进的响应。 反思的一个关键方面是LLM的自我编辑能力。通过评估其初始响应,模型可以识别潜在的错误或需要改进的地方。这种生成、反思和修订的迭代过程使LLM能够改进其输出,提高其响应的整体质量和可靠性。 |
| 5) Expert Prompting: Expert Prompting [161] enhances the capabilities of Large Language Models (LLMs) by simulating the responses of experts in various fields. This method involves prompting the LLMs to assume the role of an expert and respond accordingly, providing high-quality, informed answers. A key strategy within Expert Prompting is the multi-expert approach. The LLM is prompted to consider responses from multiple expert perspectives, which are then synthesized to form a comprehensive and well-rounded answer. This technique not only enhances the depth of the response but also incorporates a range of viewpoints, reflecting a more holistic understanding of the subject matter. | 5)专家提示:专家提示[161]通过模拟各个领域专家的响应来增强大型语言模型(LLM)的能力。这种方法包括促使LLM扮演专家的角色,并做出相应的回应,提供高质量的、知情的答案。专家提示中的一个关键策略是多专家方法。LLM被提示考虑来自多个专家角度的回应,然后将其综合起来形成一个全面而全面的答案。这种技术不仅增强了响应的深度,而且还包含了一系列的观点,反映了对主题的更全面的理解。 |
| 6) Chains: Chains refer to the method of linking multiple components in a sequence to handle complex tasks with Large Language Models (LLMs). This approach involves creating a series of interconnected steps or processes, each contributing to the final outcome. The concept of Chains is based on the idea of constructing a workflow where different stages or components are sequentially arranged. Each component in a Chain performs a specific function, and the output of one serves as the input for the next. This end-to-end arrangement allows for more complex and nuanced processing, as each stage can be tailored to handle a specific aspect of the task. Chains can vary in complexity and structure, depending on the requirements. In “PromptChainer: Chaining Large Language Model Prompts through Visual Programming” [162], the authors not only describe the main challenges in designing chains, but also describe a visual tool to support those tasks. | 6)链:链是指用大语言模型(Large Language Models, LLM)将多个组件按顺序连接起来处理复杂任务的方法。这种方法包括创建一系列相互关联的步骤或过程,每个步骤或过程都有助于最终结果。链的概念基于构建工作流的思想,其中不同的阶段或组件按顺序排列。Chain中的每个组件执行一个特定的功能,一个组件的输出作为下一个组件的输入。这种端到端安排允许更复杂和细致的处理,因为每个阶段都可以定制以处理任务的特定方面。链的复杂性和结构可以根据需求而变化。在“PromptChainer:通过可视化编程链接大型语言模型提示符”[162]中,作者不仅描述了设计链的主要挑战,还描述了支持这些任务的可视化工具。 |
| 7) Rails: Rails in advanced prompt engineering refer to a method of guiding and controlling the output of Large Language Models (LLMs) through predefined rules or templates. This approach is designed to ensure that the model’s responses adhere to certain standards or criteria, enhancing the relevance, safety, and accuracy of the output. The concept of Rails involves setting up a framework or a set of guidelines that the LLM must follow while generating responses. These guidelines are typically defined using a modeling language or templates known as Canonical Forms, which standardize the way natural language sentences are structured and delivered. Rails can be designed for various purposes, depending on the specific needs of the application: • Topical Rails: Ensure that the LLM sticks to a particular topic or domain. • Fact-Checking Rails: Aimed at minimizing the generation of false or misleading information. • Jailbreaking Rails: Prevent the LLM from generating responses that attempt to bypass its own operational constraints or guidelines. | 7) Rails:高级提示工程中的Rails是指通过预定义的规则或模板来指导和控制大型语言模型(LLM)输出的方法。该方法旨在确保模型的响应遵循某些标准或标准,从而增强输出的相关性、安全性和准确性。Rails的概念包括建立一个框架或一组指导方针,LLM在生成响应时必须遵循这些框架或指导方针。这些指导方针通常使用称为规范化形式的建模语言或模板来定义,规范化形式标准化了自然语言句子的结构和传递方式。 根据应用程序的具体需求,可以为各种目的设计Rails: •专题Rails:确保LLM坚持一个特定的主题或领域。 •事实核查轨道:旨在最大限度地减少虚假或误导性信息的产生。 •越狱Rails:防止LLM生成试图绕过其自身操作约束或指导方针的响应。 |
8)自动提示工程:旨在自动化生成LLM的提示,利用LLM本身的能力生成和评估提示,进而创建更高质量的提示,更有可能引发期望的响应或结果
| 8) Automatic Prompt Engineering (APE): Automatic Prompt Engineering (APE) [163] focuses on automating the process of prompt creation for Large Language Models (LLMs). APE seeks to streamline and optimize the prompt design process, leveraging the capabilities of LLMs themselves to generate and evaluate prompts. APE involves using LLMs in a self-referential manner where the model is employed to generate, score, and refine prompts. This recursive use of LLMs enables the creation of high-quality prompts that are more likely to elicit the desired response or outcome. The methodology of APE can be broken down into several key steps: • Prompt Generation: The LLM generates a range of potential prompts based on a given task or objective. • Prompt Scoring: Each generated prompt is then evaluated for its effectiveness, often using criteria like clarity, specificity, and likelihood of eliciting the desired response. • Refinement and Iteration: Based on these evaluations, prompts can be refined and iterated upon, further enhancing their quality and effectiveness. | 8)自动提示工程(Automatic Prompt Engineering, APE):自动提示工程(Automatic Prompt Engineering, APE)[163]专注于大型语言模型(LLM)提示创建过程的自动化。APE旨在简化和优化提示设计过程,利用LLM本身的能力来生成和评估提示。APE涉及以自我引用的方式使用LLM,其中使用模型来生成,评分和优化提示。LLM的这种递归使用支持创建高质量的提示,这些提示更有可能引发期望的响应或结果。 APE的方法可以分为几个关键步骤: •提示生成:LLM根据给定的任务或目标生成一系列潜在的提示。•提示评分:然后对每个生成的提示进行有效性评估,通常使用清晰度、特异性和引发预期反应的可能性等标准。 •细化和迭代:基于这些评估,可以对提示进行细化和迭代,进一步提高其质量和有效性。 |
C. Augmenting LLMs through external knowledge - RAG通过外部知识扩充
Fig. 37: An example of synthesizing RAG with LLMs for question answering application [166].
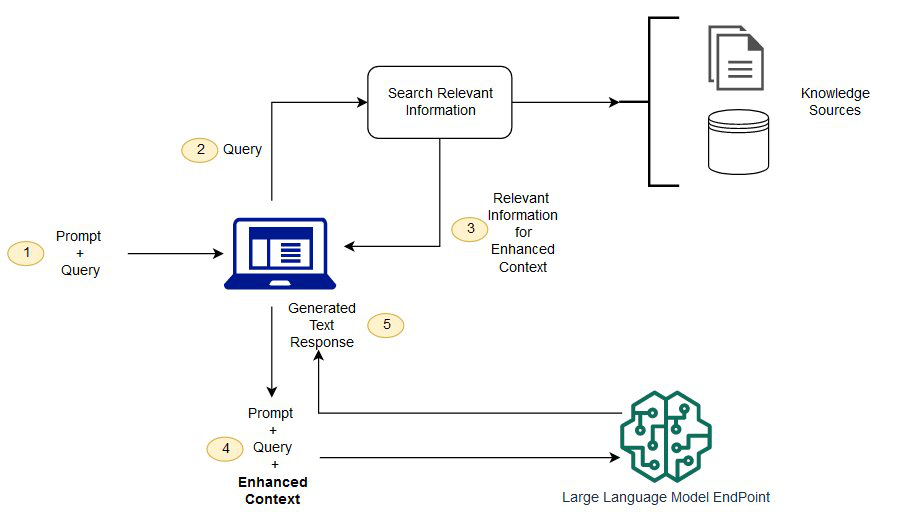
Fig. 38: This is one example of synthesizing the KG as a retriever with LLMs [167].
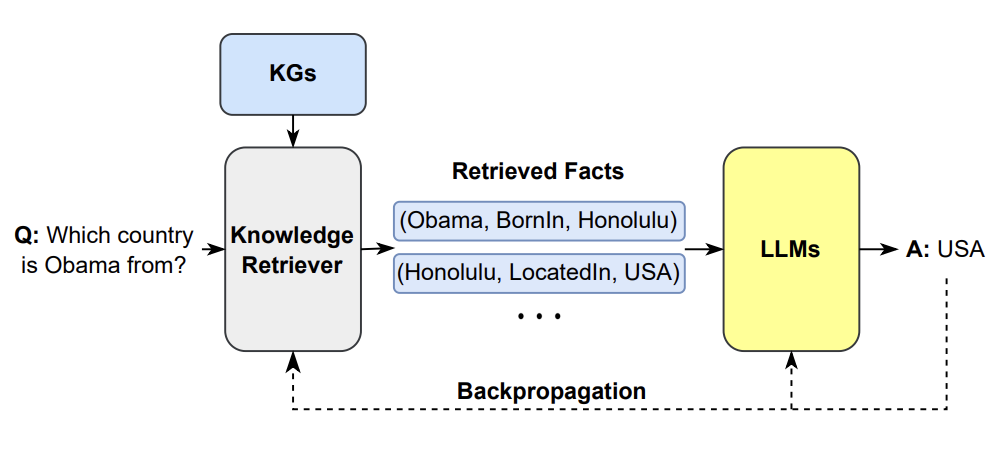
通过外部知识增强LLM:使用外部知识源来生成最终回答
检索增强生成(RAG)是通过从输入提示中提取查询,然后使用该查询从外部知识源(如搜索引擎或知识图谱)检索相关信息,并将其添加到原始提示中,以生成最终响应的方法。
RAG系统包括三个重要组件:检索、生成和增强
| One of the main limitations of pre-trained LLMs is their lack of up-to-date knowledge or access to private or usecase-specific information. This is where retrieval augmented generation (RAG) comes into the picture [164]. RAG, illustrated in figure 37, involves extracting a query from the input prompt and using that query to retrieve relevant information from an external knowledge source (e.g. a search engine or a knowledge graph, see figure 38 ). The relevant information is then added to the original prompt and fed to the LLM in order for the model to generate the final response. A RAG system includes three important components: Retrieval, Generation, Augmentation [165]. | 预训练LLM的主要限制之一是他们缺乏最新的知识或访问私人或特定于用例的信息。这就是检索增强生成(RAG)的由来[164]。如图37所示,RAG涉及从输入提示提取查询,并使用该查询从外部知识来源(例如搜索引擎或知识图,参见图38)检索相关信息。然后将相关信息添加到原始提示中并提供给LLM,以便模型生成最终响应。RAG系统包括三个重要组成部分:检索、生成、增强[165]。 |
RAG感知技术
| a) RAG-aware prompting techniques: Because of the importance of RAG to build advanced LLM systems, several RAG-aware prompting techniques have been developed recently. One such technique is Forward-looking Active Retrieval Augmented Generation (FLARE) | a) RAG感知提示技术:由于RAG对于构建高级LLM系统的重要性,最近开发了几种RAG感知提示技术。其中一项技术是前瞻性主动检索增强生成(FLARE)。重要性,最近开发了几种RAG感知提示技术。其中一项技术是前瞻性主动检索增强生成(FLARE)。 |
FLARE:通过迭代地结合预测和信息检索,提高了大型语言模型的能力
前瞻性主动检索增强生成(FLARE)是一种新型的RAG技术,它通过迭代地结合预测和信息检索,提高了大型语言模型的能力。FLARE采用了动态迭代的方式,在生成过程中不断地预测下一个内容,并将这些预测作为查询用于检索相关信息,从而优化生成的内容,确保响应的准确性和相关性。
| Forward-looking Active Retrieval Augmented Generation (FLARE) [168] enhances the capabilities of Large Language Models (LLMs) by iteratively combining prediction and information retrieval. FLARE represents an evolution in the use of retrieval-augmented generation, aimed at improving the accuracy and relevance of LLM responses. | 前瞻性主动检索增强生成(FLARE)[168]通过迭代地结合预测和信息检索来增强大型语言模型(LLM)的能力。FLARE代表了检索增强生成技术的发展,旨在提高LLM响应的准确性和相关性。 |
| FLARE involves an iterative process where the LLM actively predicts upcoming content and uses these predictions as queries to retrieve relevant information. This method contrasts with traditional retrieval-augmented models that typically retrieve information once and then proceed with generation. In FLARE, this process is dynamic and ongoing throughout the generation phase. In FLARE, each sentence or segment generated by the LLM is evaluated for confidence. If the confidence level is below a certain threshold, the model uses the generated content as a query to retrieve relevant information, which is then used to regenerate or refine the sentence. This iterative process ensures that each part of the response is informed by the most relevant and current information available. | FLARE是一个迭代过程,LLM主动预测即将发布的内容,并使用这些预测作为查询来检索相关信息。这种方法与传统的检索增强模型形成对比,传统的检索增强模型通常只检索一次信息,然后进行生成。在FLARE中,这个过程是动态的,并在整个发电阶段持续进行。在FLARE中,对LLM生成的每个句子或片段进行置信度评估。如果置信度低于某个阈值,则模型使用生成的内容作为查询来检索相关信息,然后使用这些信息来重新生成或精炼句子。这个迭代过程确保响应的每个部分都得到最相关和最新的可用信息。 |
| For more details on RAG framework and its relevant works, we refer the readers to this survey of retrieval augmented generations [165]. | 关于RAG框架及其相关工作的更多细节,我们建议读者参阅检索增强代的调查[165]。 |
D. Using External Tools使用外部工具
使用外部工具是增强LLM功能的一种方式,不仅包括从外部知识源中检索信息,还包括访问各种外部服务或API
| Retrieving information from an external knowledge source as described above is only one of the potential ways to augment an LLM. More generally, an LLM can access any number of external tools (e.g. an API to a service) to augment its functionality. In that regards, RAG can be seen as a specific instance of the broader category of the so called ”tools”. | 如上所述,从外部知识来源检索信息只是增强LLM的一种潜在方法。更一般地说,LLM可以访问任意数量的外部工具(例如服务的API)来增强其功能。在这方面,RAG可被视为所谓“工具”的更广泛类别的一个具体实例。 |
工具是LLM可以利用的外部功能或服务,扩展了LLM的任务范围,从基本的信息检索到与外部数据库或API的复杂交互,比如Toolformer
| Tools in this context are external functions or services that LLMs can utilize. These tools extend the range of tasks an LLM can perform, from basic information retrieval to complex interactions with external databases or APIs. | 在此上下文中,工具是LLM可以利用的外部功能或服务。这些工具扩展了LLM可以执行的任务范围,从基本信息检索到与外部数据库或api的复杂交互。 |
| In the paper ”Toolformer: Language Models Can Teach Themselves to Use Tools” [169], the authors go beyond simple tool usage by training an LLM to decide what tool to use when, and even what parameters the API needs. Tools include two different search engines, or a calculator. In the following examples, the LLM decides to call an external Q&A tool, a calculator, and a Wikipedia Search Engine More recently, researchers at Berkeley have trained a new LLM called Gorilla [67] that beats GPT-4 at the use of APIs, a specific but quite general tool. | 在论文“Toolformer: Language Models Can Teach myself to Use Tools”[169]中,作者通过训练LLM来决定何时使用什么工具,甚至API需要什么参数,从而超越了简单的工具使用。工具包括两个不同的搜索引擎,或者一个计算器。在下面的例子中,LLM决定调用外部问答工具、计算器和维基百科搜索引擎。最近,伯克利的研究人员训练了一个名为Gorilla的新LLM[67],它在使用api(一种特定但非常通用的工具)方面击败了GPT-4。 |
ART是一种将自动化的链式思维提示与外部工具使用相结合的提示工程技术,增强了LLM处理复杂任务的能力,尤其适用于需要内部推理和外部数据处理或检索的任务。
| a) Tool-aware prompting techniques: Similarly to what was described with RAG, several tool-aware prompting approaches have been developed to make usage of tools more scalable. A popular technique is the so called Automatic Multistep Reasoning and Tool-use (ART). | a)工具感知提示技术:与RAG描述的类似,已经开发了几种工具感知提示方法,以使工具的使用更具可伸缩性。一种流行的技术是所谓的自动多步推理和工具使用(ART)。 |
| Automatic Multi-step Reasoning and Tool-use (ART) [170] is a prompt engineering technique that combines automated chain of thought prompting with the use of external tools. ART represents a convergence of multiple prompt engineering strategies, enhancing the ability of Large Language Models (LLMs) to handle complex tasks that require both reasoning and interaction with external data sources or tools. | 自动多步推理和工具使用(ART)[170]是一种将自动思维链提示与外部工具的使用相结合的提示工程技术。ART代表了多种提示工程策略的融合,增强了大型语言模型(LLM)处理复杂任务的能力,这些任务既需要推理,也需要与外部数据源或工具进行交互。 |
| ART involves a systematic approach where, given a task and input, the system first identifies similar tasks from a task library. These tasks are then used as examples in the prompt, guiding the LLM on how to approach and execute the current task. This method is particularly effective when tasks require a combination of internal reasoning and external data processing or retrieval. | ART涉及一种系统方法,在给定任务和输入时,系统首先从任务库中识别类似的任务。然后,这些任务在提示符中用作示例,指导LLM如何处理和执行当前任务。当任务需要内部推理和外部数据处理或检索相结合时,这种方法特别有效。 |
E. LLM Agents代理
LLM代理是基于特定实例化的(增强的)LLM的系统,能够自主执行特定任务,通过与用户和环境的交互来做出决策,通常超出简单响应生成的范围
| The idea of AI agents has been well-explored in the history of AI. An agent is typically an autonomous entity that can perceive the environment using its sensors, make a judgment based on the state it currently is, and accordingly act based on the actions that are available to it. | 在人工智能的历史上,人工智能主体的概念已经得到了很好的探索。代理通常是一个自主实体,它可以使用其传感器感知环境,根据其当前状态做出判断,并根据可用的操作相应地采取行动。 |
LLM代理能够访问和利用工具,并根据输入和目标进行决策
LLM代理的功能包括访问和利用外部工具、进行决策制定,通常涉及复杂的推理过程,可应用于需要自主性和决策制定的任务
LLM代理能够处理需要一定程度自主性和决策能力的任务,远超过简单的响应生成
| In the context of LLMs, an agent refers to a system based on a specialized instantiation of an (augmented) LLM that is capable of performing specific tasks autonomously. These agents are designed to interact with users and environment to make decisions based on the input and the intended goal of the interaction. Agents are based on LLMs equipped with the ability to access and use tools, and to make decisions based on the given input. They are designed to handle tasks that require a degree of autonomy and decision-making, typically beyond simple response generation. | 在LLM上下文中,代理指的是基于(增强的)LLM的专门实例的系统,该系统能够自主执行特定的任务。这些代理被设计用于与用户和环境进行交互,以根据输入和交互的预期目标做出决策。代理基于LLM,具有访问和使用工具的能力,并根据给定的输入做出决策。它们被设计用来处理需要一定程度的自主权和决策的任务,通常不只是简单的响应生成。 |
| The functionalities of a generic LLM-based agent include: • Tool Access and Utilization: Agents have the capability to access external tools and services, and to utilize these resources effectively to accomplish tasks. • Decision Making: They can make decisions based on the input, context, and the tools available to them, often employing complex reasoning processes. | 基于LLM的通用代理的功能包括: •工具访问和利用:代理具有访问外部工具和服务的能力,并有效地利用这些资源来完成任务。 •决策制定:他们可以根据输入、上下文和可用的工具做出决策,通常采用复杂的推理过程。 |
| As an example, an LLM that has access to a function (or an API) such as weather API, can answer any question related to the weather of the specific place. In other words, it can use APIs to solve problems. Furthermore, if that LLM has access to an API that allows to make purchases, a purchasing agent can be built to not only have capabilities to read information from the external world, but also act on it [171]. | 例如,可以访问诸如天气API之类的函数(或API)的LLM可以回答与特定地点的天气相关的任何问题。换句话说,它可以使用api来解决问题。此外,如果LLM可以访问允许进行购买的API,则可以构建采购代理,使其不仅具有从外部世界读取信息的能力,而且还可以对其进行操作[171]。 |
| Fig. 40 shows another example of LLM-based agents for conversational information seeking [36], where an LLM is augmented with a set of plug-and-play modules, including a working memory that tracks the dialog state, a policy that makes an execution plan for the task and selects next system action, an action executor that performs an action selected by the policy (consolidating evidence from external knowledge, or prompting the LLM to generate responses), and a utility that accesses the alignment of the LLM’s responses with user expectations or specific business requirements, and generate feedback to improve agent performance. | 图40显示了另一个基于LLM的对话信息搜索代理的例子[36],其中LLM增加了一组即插即用模块,包括跟踪对话状态的工作记忆、为任务制定执行计划并选择下一个系统动作的策略、执行策略选择的动作执行器(整合来自外部知识的证据,或提示LLM生成响应)。以及访问LLM响应与用户期望或特定业务需求的一致性的实用程序,并生成反馈以提高代理性能。 |
| For more details on LLM-based AI agents see recent survey [172], [173], [174]. | 有关基于LLM的AI代理的更多细节,请参见最近的调查[172],[173],[174]。 |
Prompt工程技术针对LLM代理的需要进行了专门的开发,例如ReWOO、ReAct、DERA等。这些技术旨在增强LLM代理的推理、行动和对话能力,使其能够处理各种复杂的决策和问题解决任务
| a) Prompt engineering techniques for agents: Like RAG and Tools, prompt engineering techniques that specifically address the needs of LLM-based agents have been developed. Three such examples are Reasoning without Observation (ReWOO), Reason and Act (ReAct), and DialogEnabled Resolving Agents (DERA). | a)代理的即时工程技术:像RAG和Tools一样,专门解决基于LLM的代理需求的即时工程技术已经开发出来。三个这样的例子是无观察推理(ReWOO)、理性和行为(ReAct)和对话解决代理(DERA)。 |
ReWOO:目标是将推理过程与直接观察分离,让LLM先制定完整的推理框架与方案,然后在获取必要数据后执行
| Reasoning without Observation (ReWOO) [175] aims to decouple reasoning from direct observations. ReWOO operates by enabling LLMs to formulate comprehensive reasoning plans or meta-plans without immediate reliance on external data or tools. This approach allows the agent to create a structured framework for reasoning that can be executed once the necessary data or observations are available. In ReWOO, the LLM initially develops a plan (a series of steps) that outlines how to approach and solve a given problem. This metaplanning phase is crucial as it sets the stage for the agent to process information once it becomes available. The execution phase then involves integrating actual data or observations into the pre-specified plan, leading to coherent and contextually relevant responses. ReWOO offers significant advantages in terms of token efficiency and robustness to tool failure. It enables LLMs to handle tasks where immediate access to external data is not available, relying instead on a wellstructured reasoning framework. This method is particularly advantageous in scenarios where data retrieval is costly, slow, or uncertain, allowing the LLM-based agent to maintain a high level of performance and reliability. | 无观察推理(ReWOO)[175]旨在将推理与直接观察解耦。ReWOO通过使LLM能够制定全面的推理计划或元计划,而无需立即依赖外部数据或工具。这种方法允许代理创建一个结构化的推理框架,一旦获得必要的数据或观察结果,就可以执行该框架。在ReWOO中,LLM首先制定一个计划(一系列步骤),概述如何处理和解决给定的问题。这个元规划阶段非常重要,因为它为代理在信息可用时处理信息奠定了基础。然后,执行阶段涉及将实际数据或观察结果集成到预先指定的计划中,从而产生连贯且与上下文相关的响应。ReWOO在令牌效率和对工具故障的健壮性方面提供了显著的优势。它使LLM能够处理无法立即访问外部数据的任务,而是依赖于结构良好的推理框架。这种方法在数据检索成本高、速度慢或不确定的情况下特别有利,允许基于LLM的代理保持高水平的性能和可靠性。 |
ReAct:会引导LLM同时产生推理解释与可执行行动,从而提升其动态解决问题的能力
| Reason and Act (ReAct)[176] prompts LLMs to generate not only verbal reasoning but also actionable steps, thus enhancing the model’s dynamic problem-solving capabilities. ReAct is grounded in the principle of integrating reasoning with action. In this approach, the LLM is prompted to alternate between generating reasoning traces (explanations) and taking actions (steps or commands) in an interleaved manner. This approach allows the model to dynamically reason about a problem, and propose and take concrete actions simultaneously. | Reason and Act (ReAct)[176]促使LLM不仅生成口头推理,还生成可操作的步骤,从而增强模型的动态解决问题的能力。ReAct基于推理与行动相结合的原则。在这种方法中,LLM被提示以交错的方式在生成推理痕迹(解释)和采取行动(步骤或命令)之间交替进行。这种方法允许模型对问题进行动态推理,并同时提出和采取具体行动。 |
DERA:利用多个专业化代理交互解决问题和做决定,每个代理有不同角色与职能,这种方式更高效地进行复杂决策
| Dialog-Enabled Resolving Agents (DERA) [177] are specialized AI agents that can engage in dialogue, resolve queries, and make decisions based on interactive exchanges. DERA is developed based on the idea of utilizing multiple agents within a dialog context, each with specific roles and functions. These agents can include Researchers, who gather and analyze information, and Deciders, who make final judgments based on the information provided. This division of roles allows for a well-organized and efficient approach to problem-solving and decision-making. DERA is particularly advantageous in scenarios requiring complex decision-making and problemsolving, such as those in medical diagnostics or customer service. The collaborative and interactive nature of DERA agents allows them to handle intricate queries with a level of depth and nuance that single-agent systems might struggle with. Moreover, this approach aligns well with human decisionmaking processes, making AI reasoning more relatable and trustworthy. | 启用对话的解析代理(DERA)[177]是专门的AI代理,可以参与对话,解决查询,并根据交互式交换做出决策。DERA是基于在对话上下文中使用多个代理的思想开发的,每个代理都具有特定的角色和功能。这些代理人可以包括收集和分析信息的研究人员,以及根据所提供的信息做出最终判断的决策人员。这种角色的划分允许一个组织良好和有效的方法来解决问题和决策。在需要复杂决策和解决问题的情况下,例如医疗诊断或客户服务,DERA尤其具有优势。DERA代理的协作和交互特性使它们能够处理复杂的查询,其深度和细微差别是单代理系统可能难以做到的。此外,这种方法与人类的决策过程非常吻合,使人工智能推理更加可信。 |
Fig. 39: HuggingGPT: An agent-based approach to use tools and planning [image courtesy of [171]]
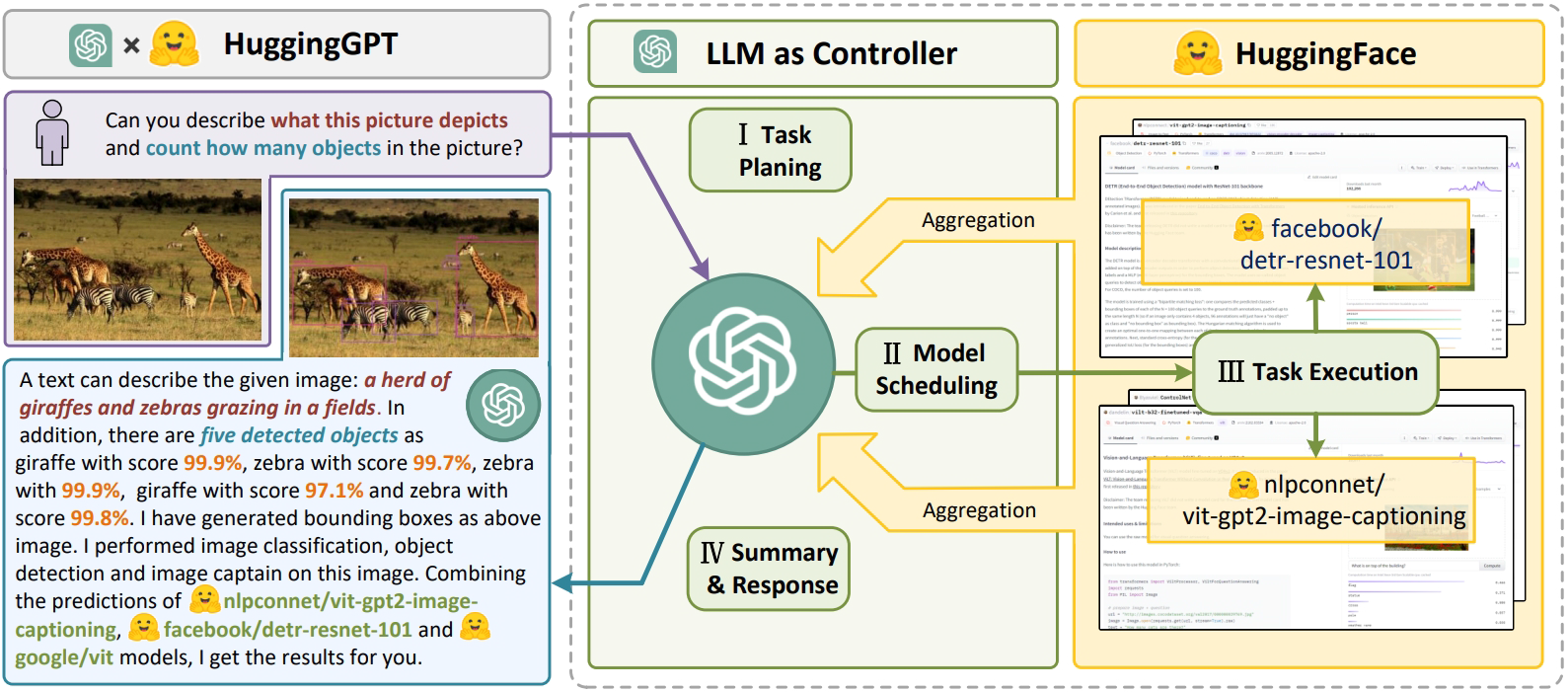
Fig. 40: A LLM-based agent for conversational information seeking. Courtesy of [36].
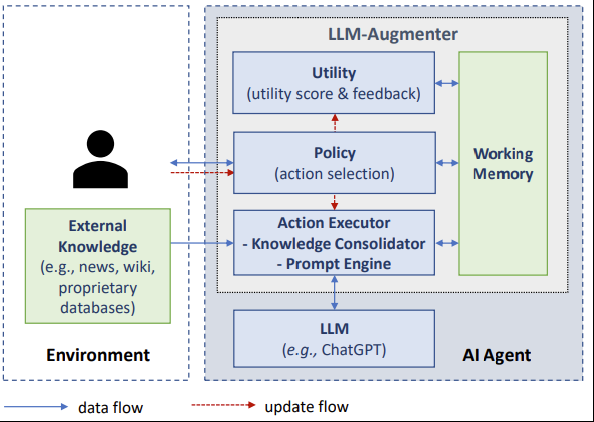
V. POPULAR DATASETS FOR LLMS常用的数据集
| Large language models exhibit promising accomplishments, but the main question that arises is how effectively they function and how their performance can be assessed in specific tasks or applications. | 大型语言模型展示了有希望的成就,但出现的主要问题是它们的功能有多有效,以及如何在特定任务或应用程序中评估它们的性能。 |
| The evaluation of LLMs poses particular challenges due to the evolving landscape of their applications. The original intent behind developing LLMs was to boost the performance of NLP tasks such as translation, summarization, questionanswering, and so on [178]. However, it is evident today that these models are finding utility across diverse domains including code generation and finance. Moreover, the evaluation of LLMs encompasses several critical considerations such as fairness and bias, fact-checking, and reasoning. In this section, we outline the commonly used benchmarks for assessing LLMs. These benchmarks are categorized based on training or evaluating the LLM Capabilities. | LLM的评估提出了特殊的挑战,由于其应用程序的不断发展的景观。开发LLM的初衷是为了提高NLP任务的性能,如翻译、摘要、问答等[178]。然而,今天很明显,这些模型在不同的领域(包括代码生成和财务)中得到了应用。此外,LLM的评估包括几个关键的考虑因素,如公平和偏见,事实核查和推理。在本节中,我们将概述用于评估LLM的常用基准。这些基准是根据培训或评估LLM能力进行分类的。 |
Fig. 41: Dataset applications.
Fig. 42: Datasets licensed under different licenses.
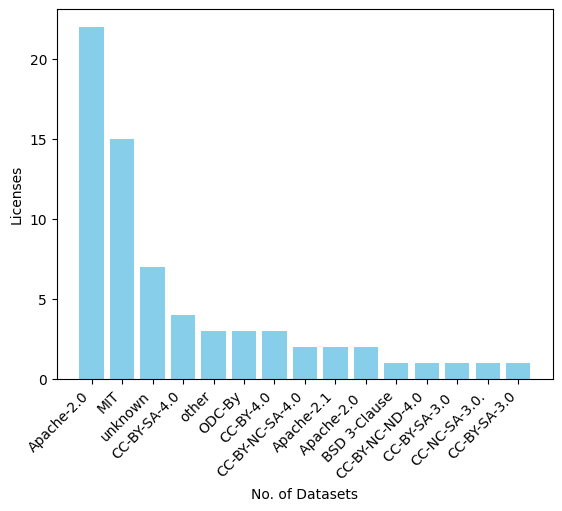
TABLE II: LLM Datasets Overview.

A. Datasets for Basic Tasks: language modeling/understanding/generation基本任务的数据集(语言建模/理解/生成):包括自然语言问答、数学问题、代码生成等任务的数据集,如Natural Questions、MMLU、MBPP、HumanEval等
基本任务数据集:用于评估LLM基本能力的基准和数据集,如自然问题、数学问题、代码生成等任务的数据集,包括Natural Questions、MMLU、MBPP等。
| This section provides an overview of the benchmarks and datasets suited to evaluate the basic abilities of LLMs. • Natural Questions [179] is a QA dataset that consists of real anonymized, aggregated queries submitted to the Google search engine as questions. An annotator is presented with a question along with a Wikipedia page from the top 5 search results, and annotates a long answer (typically a paragraph) and a short answer (one or more entities) if present on the page, or marks null if no long/short answer is present. • MMLU [180] is intended to evaluate the knowledge gained in zero-shot and few-shot scenarios. That means that MMLU assesses both the general knowledge and problem-solving ability of a model. It covers 57 subjects in STEM, humanities, social sciences, and other areas. The benchmark varies in complexity, ranging from elementary to advanced professional. It is worth mentioning that the main contribution of this dataset is for multi-task language understanding, question answering, and arithmetic reasoning. • MBPP [181] stands for “Mostly Basic Python Problems” and provides a benchmark for evaluating the performance of models designed for code generation. The benchmark encompasses 974 short Python programs including a wide range of topics, including fundamental programming concepts and standard library usage, and more. Each challenge comprises a task description, a code solution, and three automated test cases. | 本节概述了适用于评估LLM基本能力的基准和数据集。 •Natural Questions[179]是一个QA数据集,由真实的匿名、聚合的查询作为问题提交给谷歌搜索引擎。注释者会看到一个问题以及前5个搜索结果中的Wikipedia页面,如果页面上出现长答案(通常是一个段落)和短答案(一个或多个实体),则注释者会对其进行注释,如果没有出现长/短答案,则标记为空。 •MMLU[180]旨在评估零弹和少弹场景下获得的知识。这意味着MMLU评估模型的一般知识和解决问题的能力。它涵盖了STEM、人文、社会科学和其他领域的57个学科。基准的复杂程度各不相同,从初级到高级专业。值得一提的是,该数据集的主要贡献是用于多任务语言理解、问题回答和算术推理。 •MBPP[181]代表“大多数基本Python问题”,并为评估为代码生成设计的模型的性能提供基准。该基准测试包含974个简短的Python程序,其中包括广泛的主题,包括基本编程概念和标准库用法等。每个挑战包括一个任务描述、一个代码解决方案和三个自动化测试用例。 |
| • HumanEval [182] is a dataset for code generation task. This dataset consists of 164 hand-crafted programming challenges. Each challenge is accompanied by a function signature, docstring, code body, and multiple unit tests. The main intuition behind developing this dataset is to guarantee the exclusion of its contents from training datasets for code generation models. • APPS [183] is designed for code generation task focusing on the Python programming language. The APPS dataset contains a collection of 232, 444 Python programs. Each program in the dataset has an average of 18 lines of Python code. Additionally, APPS offers access to a repository of 10, 000 unique programming exercises, each with text-based problem descriptions. The final aspect to highlight is that the it includes test cases. • WikiSQL [184] is crafted for code generation task and it has 87,726 carefully labeled pairs of SQL queries and corresponding natural language questions from Wikipedia tables. The SQL queries comprise three subsets: test sets (17, 284 examples), development (9, 145 examples), and training (61, 297 examples). • TriviaQA [185] is designed for QA task. This dataset comprises more than 650, 000 questionanswer-evidence triples. There are 95, 000 questionanswer pairs in this dataset, each authored by trivia enthusiasts and supported by an average of six independently sourced evidence documents. These documents are automatically acquired from Wikipedia or broader web search results. The dataset is categorized into two segments, including those with authentic answers from Wikipedia and web domains, and verified sets embody the accurately answered questions along with their associated documents from both Wikipedia and online. | •HumanEval[182]是一个用于代码生成任务的数据集。这个数据集包含164个手工编写的编程挑战。每个挑战都伴随着函数签名、文档字符串、代码体和多个单元测试。开发此数据集背后的主要直觉是保证将其内容排除在代码生成模型的训练数据集之外。 •APPS[183]专为Python编程语言的代码生成任务而设计。APPS数据集包含232,444个Python程序的集合。数据集中的每个程序平均有18行Python代码。此外,APPS还提供了对10000个独特编程练习的访问,每个练习都有基于文本的问题描述。要强调的最后一个方面是它包含测试用例。 •WikiSQL[184]是为代码生成任务精心制作的,它有87,726对精心标记的SQL查询和相应的自然语言问题,来自维基百科表。SQL查询包含三个子集:测试集(17,284个示例)、开发集(9,145个示例)和训练集(61,297个示例)。 •TriviaQA[185]是为QA任务设计的。该数据集包含超过65万个问题-答案-证据三元组。这个数据集中有95000个问题对,每个问题对都由琐事爱好者撰写,并由平均6个独立来源的证据文件支持。这些文档自动从维基百科或更广泛的网络搜索结果中获取。数据集分为两部分,包括来自维基百科和网络域的真实答案,验证集包含准确回答的问题以及来自维基百科和在线的相关文档。 |
阅读理解数据集:用于阅读理解任务的数据集,如RACE、SQuAD、BoolQ等。
| •RACE [186] suits for reading comprehension task. This dataset is based on English tests completed by Chinese students from middle school and high school, aged 12 to 18, and it contains roughly 28, 000 texts and 100, 000 questions rigorously prepared by human specialists, primarily English instructors. This dataset contains a wide range of subjects that were purposefully chosen to assess students’ comprehension and reasoning abilities. This dataset is available in three subgroups: RACE-M, RACE-H, and RACE. RACEM refers to the middle school examinations, whereas RACE-H denotes the high school tests. Finally, RACE is the synthesis of RACE-M and RACE-H. • SQuAD [187] stands for “Stanford Question Answering Dataset” and is a crowdsourced reading comprehension dataset based on Wikipedia articles. It has approximately 100, 000 question-answer pairs connected to more than 500 articles. The answers to these questions are typically text fragments or spans taken from the corresponding reading passages. The questions may be unanswerable in some cases. The dataset is divided into three sets: an 80% training set, a 10% development set, and a 10% hidden test set. •BoolQ [188] is a yes/no question-answering dataset where the goal is reading comprehension task. BoolQ includes 15, 942 examples. Each example is a triplet that includes a question, a relevant paragraph, and the solution. Although the main intuition behind this dataset is for reading comprehension, it can be used for reasoning, natural language inference, and question-answering tasks. | •RACE[186]适合阅读理解任务。这个数据集是基于12岁到18岁的中国中学生和高中生完成的英语测试,它包含大约28,000个文本和100,000个问题,这些问题是由人类专家(主要是英语教师)严格准备的。这个数据集包含了广泛的主题,这些主题是有目的地选择来评估学生的理解和推理能力的。该数据集分为三个子组:RACE- m、RACE- h和RACE。RACEM指的是初中考试,而RACE-H指的是高中考试。最后,RACE是RACE- m和RACE- h的合成。 •SQuAD[187]代表“斯坦福问答数据集”,是基于维基百科文章的众包阅读理解数据集。它有大约10万个与500多篇文章相关的问答对。这些问题的答案通常是从相应的阅读段落中截取的文本片段或段落。在某些情况下,这些问题可能无法回答。数据集分为三个集:80%的训练集,10%的开发集和10%的隐藏测试集。 •BoolQ[188]是一个是/否问答数据集,目标是阅读理解任务。BoolQ包含15,942个示例。每个例子都是一个三元组,包括一个问题、一个相关段落和解决方案。虽然这个数据集背后的主要直觉是用于阅读理解,但它可以用于推理、自然语言推理和问答任务。•MultiRC[189]是另一个适合阅读理解任务的数据集。 |
阅读推理数据集:包括MultiRC等,适用于需要跨句子推理的阅读理解任务的数据集
| • MultiRC [189] is another dataset that fits reading comprehension task. MultiRC contains brief paragraphs as well as multi-sentence questions that can be answered using the information in the paragraph. The paragraphs in this dataset come from a variety of sources, including news, fiction, historical texts, Wikipedia articles, discussions on society and law, elementary school science textbooks, and 9/11 reports. Each question has many response choices, with one or more of them being correct. Answering the questions requires reasoning across several sentences. MultiRC dataset encompasses around 6, 000 multisentence questions gathered from over 800 paragraphs. On average, each question offers about two valid answer alternatives out of a total of five. | •MultiRC包含简短的段落以及可以使用段落中的信息回答的多句问题。该数据集中的段落来自各种来源,包括新闻、小说、历史文本、维基百科文章、关于社会和法律的讨论、小学科学教科书和9/11报告。每个问题都有多个选项,其中一个或多个选项是正确的。回答这些问题需要跨几个句子进行推理。MultiRC数据集包括从800多个段落中收集的大约6000个多句问题。平均而言,每个问题提供了五个有效答案中的两个。 |
B. Datasets for Emergent: ICL, reasoning (CoT), instruction following新兴任务数据集(ICL/CoT/IF):包括多步数学推理、常识推理、阅读理解等任务的数据集,如GSM8K、HellaSwag、AI2 Reasoning Challenge等
新兴任务数据集:评估LLM新兴能力的基准和数据集,包括GSM8K、MATH等,用于多步数学推理、解决数学问题等任务
| This section centers on the benchmarks and datasets employed to evaluate the emergent abilities of LLMs. • GSM8K [190] is designed to evaluate the model’s ability for multi-step mathematical reasoning. GSM8K includes 8.5K linguistically diverse grade school math word problems written by humans. The dataset is split into two sets: a training set with 7.5K problems, and a test set with 1K problems. These problems need 2 to 8 steps to be solved. Solutions mainly are a series of elementary calculations using basic arithmetic operations. • MATH [191] enables to assess how well models can solve math problems. MATH dataset hast 12, 500 problems from high school math competitions. Each problem in the dataset has a step-by-step solution and a final answer enclosed in a box. The problems cover a wide range of topics and have different levels of complexity. There are seven subjects in total. Furthermore, the difficulty of each problem is rated based on the AoPS standards on a scale from ′1 ′ to ′5 ′ . A ′1 ′ shows the easiest problems in a subject, while ′5 ′ represents the most difficult. In terms of formatting, all problems and solutions are presented using LATEX and the Asymptote vector graphics language. | 本节以评估LLM涌现能力的基准和数据集为中心。 •GSM8K[190]旨在评估模型的多步数学推理能力。GSM8K包括8.5万个由人类编写的语言多样的小学数学单词问题。数据集被分成两个集:一个有7.5个问题的训练集,一个有1K个问题的测试集。这些问题需要2到8个步骤来解决。解主要是用基本的算术运算进行一系列的初等计算。 •MATH[191]能够评估模型解决数学问题的能力。数学数据集有12,500个来自高中数学竞赛的问题。数据集中的每个问题都有一个循序渐进的解决方案和一个框内的最终答案。这些问题涵盖了广泛的主题,具有不同程度的复杂性。总共有七门科目。此外,每个问题的难度都是根据AoPS标准评定的,从1到5。“1”表示一门学科中最简单的问题,而“5”表示最难的问题。在格式方面,使用LATEX和渐近线矢量图形语言给出了所有问题和解决方案。 |
常识推理数据集:如HellaSwag、AI2 Reasoning Challenge (ARC)等,用于评估LLM的常识推理能力,包括常识问题、科学推理等任务
| • HellaSwag [192] is designed to assess commonsense reasoning in LLMs. This benchmark includes 70, 000 multiple-choice questions. Each question is derived from one of two domains: ActivityNet or WikiHow, and presents four answer choices regarding what might happen in the following situation. The correct answer provides an actual statement describing the upcoming event, but the three wrong answers are created to confuse machines. • AI2 Reasoning Challenge (ARC) [193] is used for commonsense reasoning. This benchmark encompasses 7, 787 science examination questions. These questions are in English, and most of them are set up in a multiple-choice format. The questions have been divided into two groups: a Challenge Set with 2, 590 difficult questions and an Easy Set with 5,197 questions. Each collection has also been pre-divided into Train, Development, and Test subsets. | •HellaSwag[192]旨在评估LLM中的常识推理。这个基准包括7万个选择题。每个问题都来自两个领域中的一个:ActivityNet或WikiHow,并针对以下情况提供四个答案选择。正确的答案提供了一个描述即将发生的事件的实际陈述,但三个错误的答案是为了迷惑机器而创造的。 •AI2 Reasoning Challenge (ARC)[193]用于常识推理。这个基准包含了7,787个科学考题。这些问题都是用英语写的,大多数都是选择题。这些问题被分为两组:包含2590个难题的挑战组和包含5197个问题的简单组。每个集合也被预先划分为训练、开发和测试子集。 |
自然常识问题数据集:例如PIQA、SIQA等,旨在评估LLM对社交情境和物理常识的推理能力
| • PIQA [194] is intended to evaluate the language representations on their knowledge of physical commonsense. In this dataset, the focus is on everyday situations with a preference for uncommon solutions. The central task is a multiple-choice question answering, where a question (q) is provided along with two potential solutions (s1, s2). Then, the best solution is chosen by whether a model or a human. For each question, only one of the solutions is the correct answer. • SIQA [195] provides a framework for evaluating models’ ability for commonsense reasoning about social situations. SIQA dataset has 38, 000 multiple-choice questions designed to assess emotional and social intelligence in everyday circumstances. This dataset covers a wide variety of social scenarios. In SIQA, the potential answers is a mixture of human-selected responses and machine-generated ones that have been filtered through adversarial processes. | •PIQA[194]旨在评估他们对物理常识的知识的语言表示。在这个数据集中,重点是日常情况,偏爱不常见的解决方案。中心任务是回答多项选择题,其中提供一个问题(q)以及两个可能的解决方案(s1, s2)。然后,由模型或人来选择最佳解决方案。对于每个问题,只有一个答案是正确的。 •SIQA[195]为评估模型对社会情境的常识性推理能力提供了一个框架。SIQA数据集有38,000个选择题,旨在评估日常环境中的情绪和社交智力。这个数据集涵盖了各种各样的社会场景。在SIQA中,潜在的答案是人类选择的答案和经过对抗过程过滤的机器生成的答案的混合。 |
开放式问题回答数据集:包括OpenBookQA (OBQA)、TruthfulQA等,用于评估LLM在处理开放性问题时的能力。
| • OpenBookQA (OBQA) [196] is a new kind of question-answering dataset where answering its questions requires additional common and commonsense knowledge not contained in the book and rich text comprehension. This dataset includes around 6,000 multiple-choice questions. Each question is linked to one core fact, as well as an additional collection of over 6000 facts. The questions were developed using a multi-stage crowdsourcing and expert filtering procedure. OpenBookQA questions are difficult because they need multi-hop reasoning with limited background. • TruthfulQA [197] is designed specifically to evaluate the truthfulness of language models in generating answers to questions. This dataset includes 817 questions, written by authors, from 38 different categories, including health, law, finance, and politics. These questions are purposefully designed to challenge human responders, as they may contain common misunderstandings that lead to incorrect answers. | •OpenBookQA (OBQA)[196]是一种新型的问答数据集,回答它的问题需要额外的书本中不包含的常见和常识性知识和丰富的文本理解。这个数据集包括大约6000个选择题。每个问题都与一个核心事实相关联,以及6000多个事实的附加集合。这些问题是使用多阶段众包和专家过滤程序开发的。OpenBookQA问题很难,因为它们需要在有限的背景下进行多跳推理。 •TruthfulQA[197]专门用于评估生成问题答案的语言模型的真实性。该数据集包括817个问题,由作者撰写,来自38个不同的类别,包括健康、法律、金融和政治。这些问题是有意设计来挑战人类应答者的,因为它们可能包含导致错误答案的常见误解。 |
指令元学习数据集:OPT-IML Bench,用于评估LLM在指令元学习方面的表现
| • OPT-IML Bench [103] is a comprehensive benchmark for Instruction Meta-Learning. It covers 2000 NLP tasks from 8 existing benchmarks. The OPT-IML Bench consists of a training set with 17.9 M examples, a dev set with 145K samples, and a test set with 321K samples. | •OPT-IML Bench[103]是教学元学习的综合基准。它涵盖了来自8个现有基准的2000个NLP任务。OPT-IML Bench由一个包含17.9 M个样本的训练集、一个包含145K个样本的开发集和一个包含321K个样本的测试集组成。 |
C. Datasets for Augmented: using external knowledge/tools增强能力数据集(使用外部知识/工具):旨在评估LLM使用外部知识和工具的能力,如HotpotQA、ToolQA、GPT4Tools等
HotpotQA: 从英文维基百科中提取的多样化、可解释的问答数据集,需要多跳推理。
ToolQA: 用于评估LLM利用外部工具回答问题的能力的问答基准。
GPT4Tools: 作为一个教学数据集,由高级教师(如ChatGPT)生成,包含与视觉内容和工具描述相关的指令,用于教导LLM如何使用工具。
| This section focuses on datasets designed for the augmented abilities of LLMs. • HotpotQA [198] is designed to cover a diverse and explainable question-answering dataset that necessitates multi-hop reasoning. This dataset is derived from the English Wikipedia. It consists of roughly 113, 000 questions. Each question in the dataset comes with two paragraphs, called gold paragraphs, from two Wikipedia articles. Also, there is a list of sentences in those paragraphs that crowdworkers have picked as important for answering the question. • ToolQA [199] is a question answering benchmark to evaluate LLMs’ ability to use external tools for answering questions. • GPT4Tools serves as an instructional dataset, generated by instructing advanced teachers (such as ChatGPT), with instructions conditioned on visual content and tool descriptions. This process results in the generation of instructions related to the use of tools. There are three versions of this dataset. The first version comprises 71,000 instruction-following data points utilized to fine-tune the GPT4Tools model. The next version consists of manually cleaned instruction data used for validation, covering instructions related to the tools from the first version. The last version is cleaned instruction data used for testing and includes instructions related to some tools that are not present in the first version. | 本节重点介绍为增强LLM能力而设计的数据集。 •HotpotQA[198]旨在涵盖多样化和可解释的问答数据集,需要多跳推理。这个数据集来源于英文维基百科。它由大约113,000个问题组成。数据集中的每个问题都有两个段落,称为黄金段落,来自两篇维基百科文章。此外,在这些段落中有一个句子列表,众包工作者认为这些句子对回答这个问题很重要。 •ToolQA[199]是一个评估LLM使用外部工具回答问题能力的问答基准。 •GPT4Tools作为一个教学数据集,由指导高级教师(如ChatGPT)生成,指令以视觉内容和工具描述为条件。这个过程导致生成与工具使用相关的指令。这个数据集有三个版本。第一个版本包含71,000个指令跟随数据点,用于微调GPT4Tools模型。下一个版本由用于验证的手动清理指令数据组成,涵盖了与第一个版本的工具相关的指令。最后一个版本是用于测试的清理指令数据,包括与第一个版本中不存在的一些工具相关的指令。 |
VI. PROMINENT LLMS’ PERFORMANCE ON BENCHMARKS杰出LLM的基准表现
| In this section we first provide an overview of some of popular metrics used for evaluating the performance of LLMs under different scenarios. We then look at the performance of prominent large language models on some of the popular datasets and benchmarks. | 在本节中,我们首先概述了在不同场景下用于评估LLM性能的一些流行指标。然后,我们将在一些流行的数据集和基准测试上查看突出的大型语言模型的性能。 |
TABLE III: LLM categories and respective definitions.
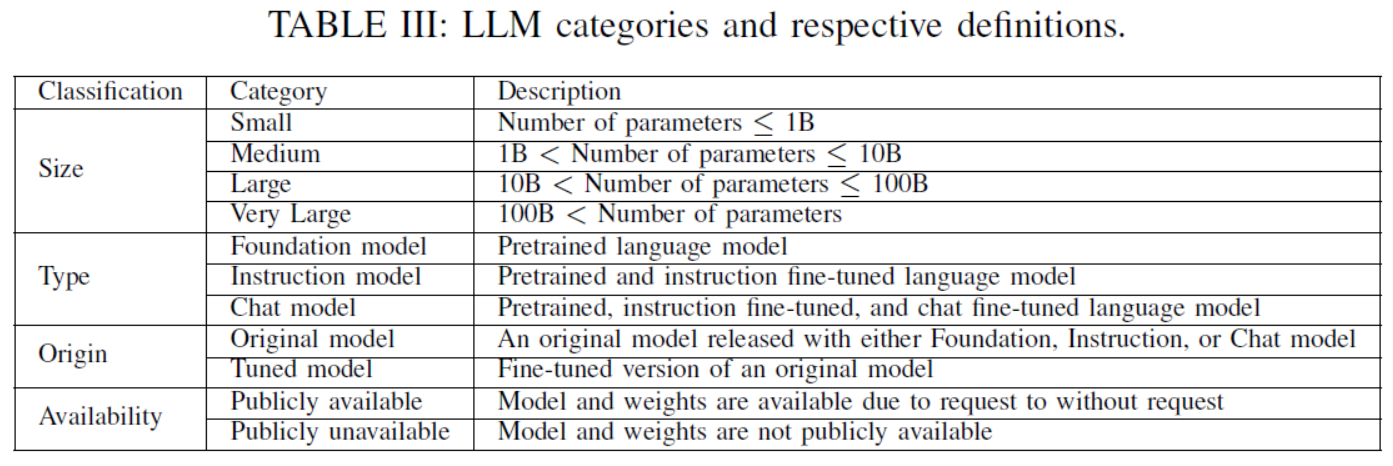
TABLE IV: Different LLM categorization.
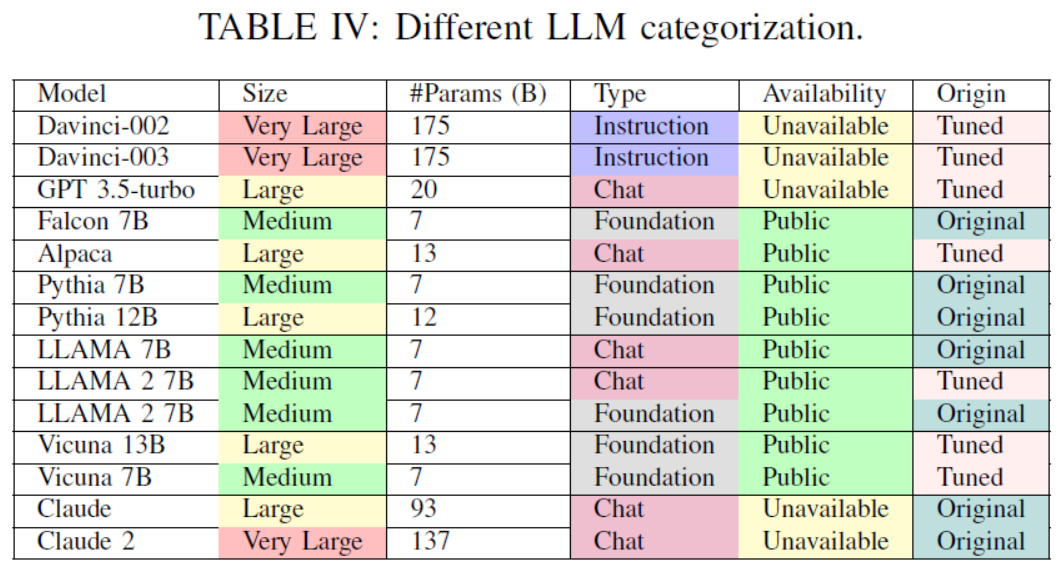
Fig. 43: LLM categorizations.
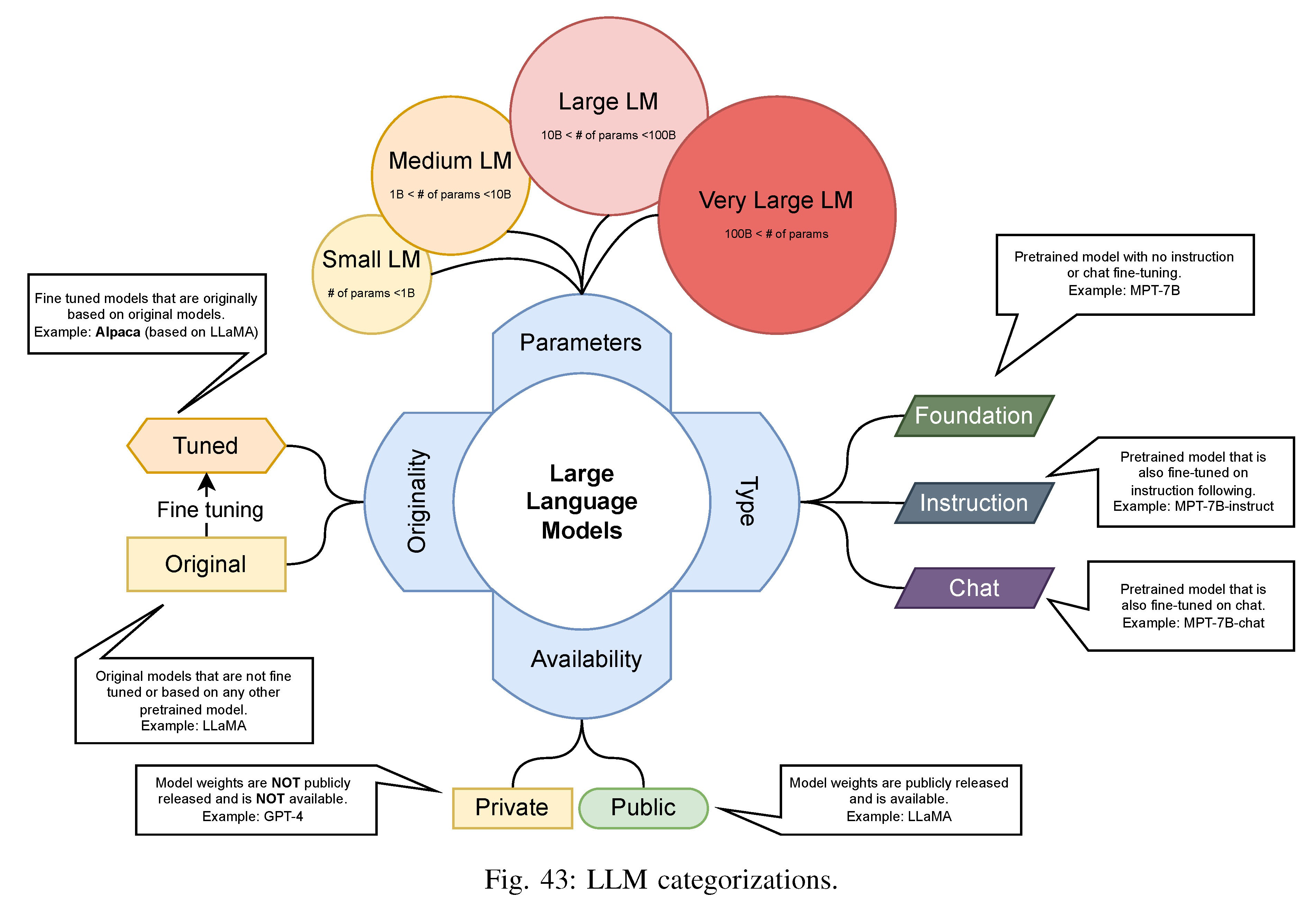
TABLE V: Commonsense reasoning comparison.
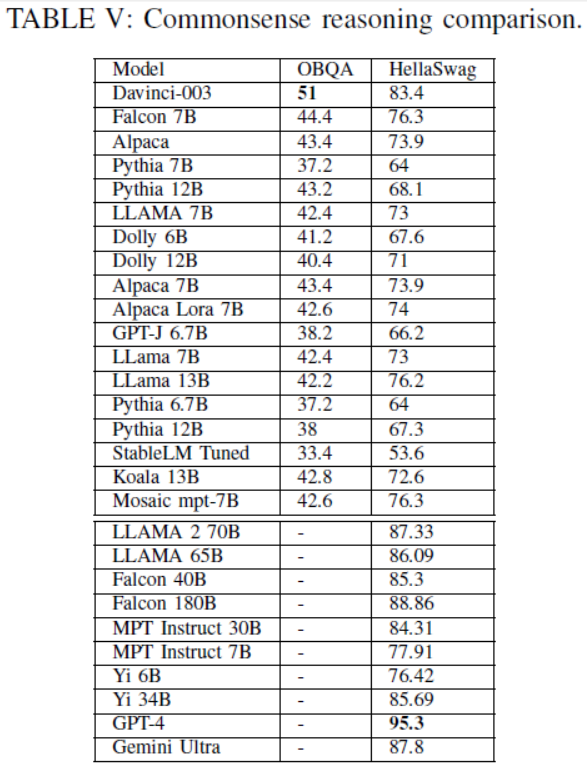
TABLE VI: Symbolic reasoning comparison.
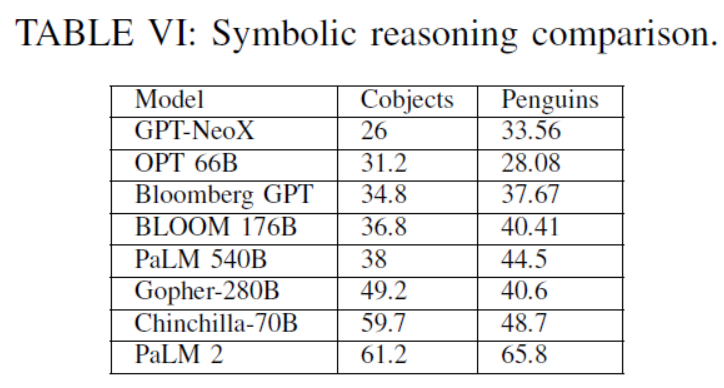
TABLE VII: World knowledge comparison.
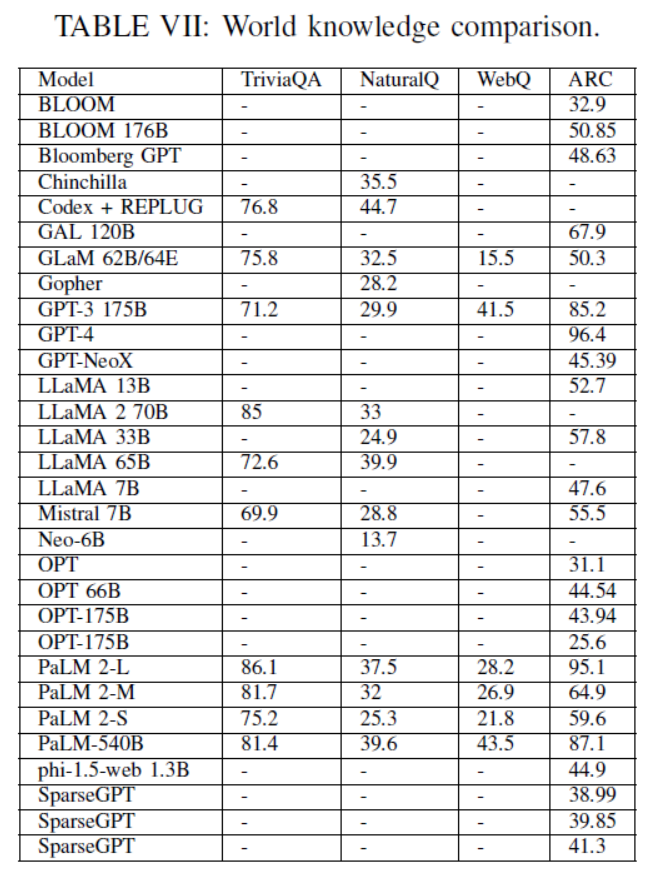
TABLE VIII: Coding capability comparison.
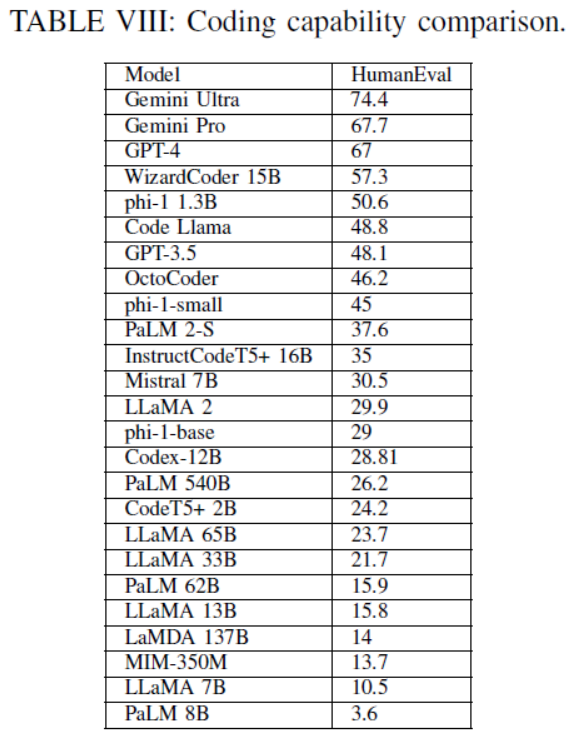
TABLE IX: Arithmetic reasoning comparison.

TABLE X: Hallucination evaluation
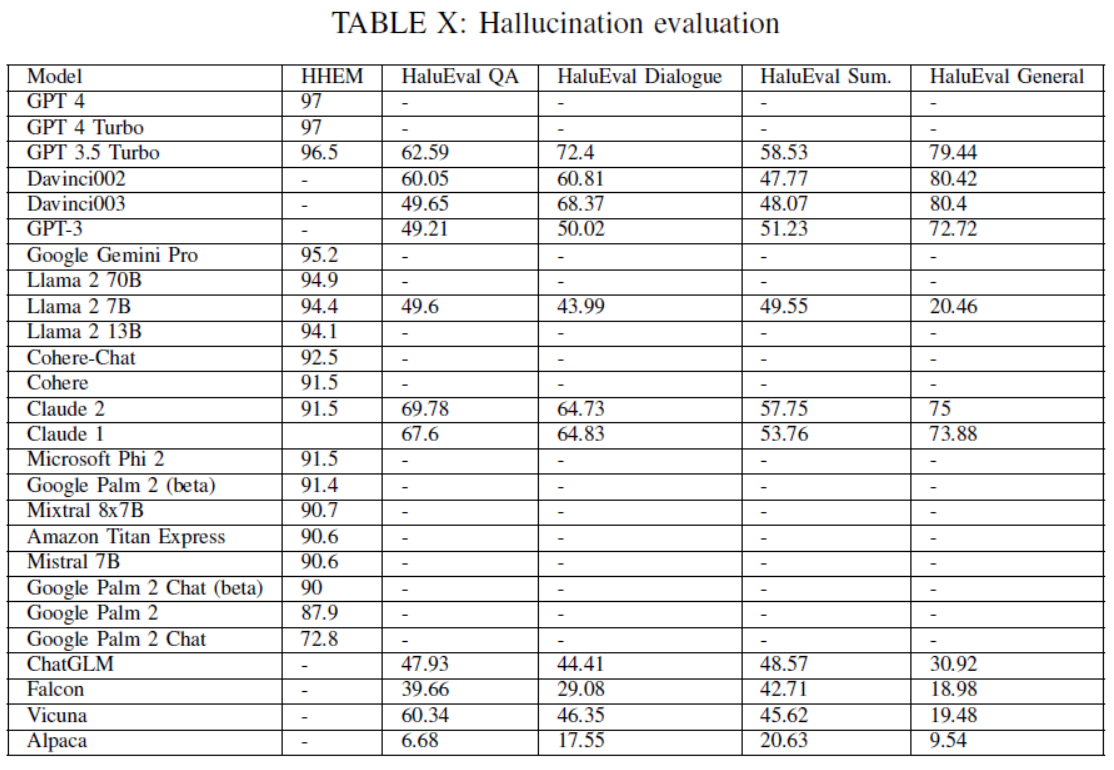
A. Popular Metrics for Evaluating LLMs评估LLM的流行指标
简单的分类任务:准确率、精确率、召回率、F1等
| Evaluating the performance of generative language models depends on the underlying task they are going to be used for. Tasks that are mostly about selecting a choice out of given ones (such as sentiment analysis), can be seen as simple as classification and their performance can be evaluated using classification metrics. Metrics such as accuracy, precision, recall, F1, etc are applicable in this case. It is also important to note that the answers generated by the model for specific tasks such as multi-choice question answering are always either True or False. If the answer is not in a set of options, it can be seen as False as well. | 评估生成语言模型的性能取决于它们将要用于的底层任务。主要是关于从给定选项中选择一个选项的任务(例如情感分析)可以被视为简单的分类,并且可以使用分类指标来评估它们的性能。诸如准确度、精度、召回率、F1等指标都适用于这种情况。同样重要的是要注意,模型为特定任务(如选择题回答)生成的答案总是True或False。如果答案不在一组选项中,它也可以被视为False。 |
纯粹的开放式文本生成任务:需要特定目的的评估使用不同的指标
代码生成需要使用不同的指标,如Pass@k和Exact Match (EM)
| However, some tasks that are purely open-ended text generation cannot be evaluated in the same way as for categorization. Different metrics are required for the specific purpose of the evaluation. Code generation is a very different case in openended generative evaluations. The generated code must pass the test suite but on the other hand, it is also important to understand if a model is capable of generating different solutions as a code, what is the probability of selecting the correct one among them. Pass@k is a very good metric in this case. It works in this manner that given a problem, different solutions as code are generated. They are tested for correctness using different functionality tests. Afterward, from generated n solutions, and the respective c number of them being correct equation 4 provides the final value. | 然而,一些纯粹是开放式文本生成的任务不能以与分类相同的方式进行评估。评估的特定目的需要不同的度量标准。在开放式生成计算中,代码生成是一个非常不同的情况。生成的代码必须通过测试套件,但另一方面,理解模型是否能够作为代码生成不同的解决方案,在其中选择正确的解决方案的概率是多少也很重要。在这种情况下Pass@k是一个非常好的指标。它的工作方式是给定一个问题,生成不同的解决方案作为代码。使用不同的功能测试来测试它们的正确性。之后,从生成的n个解中,分别有c个解是正确的,公式4给出了最终的值。 |
| Exact match (EM) is another metric that is mostly concerned with exact matches from (pre-defined) answers. It counts a prediction as correct if it exactly matches one of more than one desired reference text token by token. In some cases, it can be the same as accuracy and the equation 5 shows the mathematical definition. Here M is total number of correct answers and N is the total number of questions [20 | 精确匹配(EM)是另一个主要关注(预定义)答案的精确匹配的度量。如果一个预测精确匹配一个或多个所需的引用文本,它就会将其视为正确的。在某些情况下,它可以与精度相同,公式5显示了数学定义。其中M为正确答案总数,N为问题总数[20] |
| Human equivalence score (HEQ) on the other hand, is an alternative to F1 score [203]. HEQ-Q represents the precision of individual questions, wherein an answer is deemed correct if the model’s F1 score surpasses the average human F1 score. Likewise, HEQ-D denotes the precision of each dialogue; it is deemed accurate when all questions within the dialogue meet the criteria of HEQ [182] | 另一方面,人类等效分数(HEQ)是F1分数的替代方法[203]。HEQ-Q代表单个问题的精度,其中如果模型的F1分数超过人类的平均F1分数,则认为答案是正确的。同样,HEQ-D表示每个对话的精确度;当对话中的所有问题都符合HEQ标准时,它被认为是准确的。[182] |
评估机器翻译等生成任务时,通常使用Rouge和BLEU等度量标准
| Evaluation of other generative tasks such as machine translation are based on metrics such as Rouge and BLEU. These scores work well when there is a reference text as ground truth (such as translation) and a hypothesis that is generated by the generative model, in our case the LLM. These scores are mostly used for cases where the goal is to detect the similarity of the answer and ground truth in a computation manner. In a computation manner, it meant that nothing more than N-Grams would be used. However, metrics such as BERTScore are also good for these cases but they are also heavi erroneous because another model is used to judge. Still, even today, evaluating purely generated content is very hard and no completely fitting metric is not found, metrics are either looking for simplistic features such as N-Gram, SkipGram, etc, or they are models with unknown accuracy and preciseness [204]. | 其他生成任务(如机器翻译)的评估基于诸如Rouge和BLEU之类的指标。当有参考文本作为基础真理(如翻译)和生成模型生成的假设时,这些分数会很好地工作,在我们的案例中是LLM。这些分数主要用于目标是以计算方式检测答案和基本事实的相似性的情况。在计算方式上,这意味着不会使用超过n个grams的东西。然而,像BERTScore这样的指标也适用于这些情况,但它们也有严重的错误,因为它们使用了另一个模型来判断。尽管如此,即使在今天,评估纯粹生成的内容也是非常困难的,没有找到完全拟合的指标,指标要么寻找简单的特征,如N-Gram、SkipGram等,要么是精度和精确度未知的模型[204]。 |
| Generative evaluation metrics are also another type of evaluation metric for LLMs that use another LLM for evaluating the answer. However, depending on the task itself, evaluation can be possible in this way or not. Another dependency that makes generative evaluation error-prone is reliance on the prompt itself. RAGAS is one of the good examples that incorporate the usage of generative evaluation. | 生成式评估指标也是LLM的另一种评估指标,它使用另一个LLM来评估答案。然而,取决于任务本身,评估可以以这种方式进行,也可以不这样做。另一个使生成式求值容易出错的依赖是对提示符本身的依赖。RAGAS是结合生成评估的使用的一个很好的例子。 |
| Various benchmarks and leaderboards have been proposed to address the most challenging question in the world of large language models: Which one is better? However not a simple answer can address this question. The answer depends on various aspects of large language models. Section V shows the categorical presentation of different tasks and the most important datasets in each category. We will follow the same categorization and provide a comparison based on each category. After providing comparison for each category, we will provide a broad overview of aggregated performance by averaging the reported performance metric on different tasks. | 为了解决大型语言模型中最具挑战性的问题,人们提出了各种基准测试和排行榜:哪个更好?然而,没有一个简单的答案可以解决这个问题。答案取决于大型语言模型的各个方面。第五节展示了不同任务的分类表示以及每个类别中最重要的数据集。我们将遵循相同的分类,并提供基于每个类别的比较。在对每个类别进行比较之后,我们将通过对不同任务报告的性能指标进行平均来提供总体性能的概览。 |
LLM的分类和标签:将LLMs根据参数规模划分为小型、中型、大型和超大型4类;按预训练目的划分为基础模型、指令模型和聊天模型3类。此外,还区分原始模型和调优模型,以及公共模型和私有模型
| Evaluating different LLMs can be seen also from different perspectives. For example, a LLM with a drastically fewer number of parameters is not completely comparable to one with a larger number of parameters. From this perspective, we will categorize LLMs in four categories as well: small (less than or equal to 1 billion parameters), medium (between 1 and 10 billion), large (between 10 and 100 billion), and very large (more than 100 billion). Another classification for the LLMs we use is their primary use case. We consider each LLM to be either: Foundation model (pretrained language model with no instruction fine-tuning and chat fine-tuning), Instruction model (pretrained language model with only instruction finetuning), and Chat model (pretrained language model with instruction and chat fine-tuning). Apart from all the categorization described, another category is required to distinguish between original models and tuned ones. Original models are those that have been released as a foundation model or a finetuned one. Tuned models are those that grasped the original model and tuned it with different datasets or even different training approaches. It is also good to note that original models are usually foundation models that have been fine-tuned on specific datasets or even different approaches. Availability of the model weights regardless of the license is another category in our classification. Models that have their weights publicly available (even through request) are noted as Public models while others are noted as Private. Table III shows all of these definitions and abbreviations used in the rest of the article. Figure 43 illustrate these visually. | 评价不同的LLM也可以从不同的角度来看待。例如,参数数量少得多的LLM与参数数量多的LLM不能完全比较。从这个角度来看,我们也将LLM分为四类:小型(小于或等于10亿个参数),中型(在10到100亿个之间),大型(在100到1000亿个之间)和超大型(超过1000亿个)。我们使用的LLM的另一个分类是它们的主要用例。我们认为每个LLM可以是:基础模型(没有指令微调和聊天微调的预训练语言模型),指令模型(只有指令微调的预训练语言模型)和聊天模型(带有指令和聊天微调的预训练语言模型)。除了所描述的所有分类之外,还需要另一个分类来区分原始模型和经过调整的模型。原始模型是那些作为基础模型或微调模型发布的模型。调优模型是那些掌握原始模型并用不同的数据集甚至不同的训练方法对其进行调优的模型。同样值得注意的是,原始模型通常是在特定数据集甚至不同方法上进行微调的基础模型。与许可证无关的模型权重的可用性是我们分类中的另一个类别。将权重公开(甚至通过请求)的模型标记为公共模型,而将其他模型标记为私有模型。表III显示了本文其余部分中使用的所有这些定义和缩写。图43直观地说明了这些。 |
| According to the provided categorizations, we can categorize and label each notable LLM as shown in table IV. As can be seen from this table, models categorized as very large are also unavailable as well. | 根据提供的分类,我们可以对每个值得注意的LLM进行分类和标记,如表4所示。从表中可以看出,被分类为非常大的模型也不可用。 |
B. LLMs’ Performance on Different Tasks在不同任务上的表现
LLMs在常识推理、世界知识、编码能力、算术推理和幻觉检测等方面表现出不同的性能
根据报告的数据,不同模型在不同任务上的表现存在差异,而且并非所有模型都在所有数据集上报告其性能
| Commonsense reasoning is one of the important capabilities each model can obtain. This capability denotes the ability of the model to use prior knowledge in combination with reasoning skills. In the case of HellaSwag for example, finding the continuation of text is challenging because the given text contains a partial part of the story while the given choices as continuation are tricky to select, and without having prior knowledge about the world it is not possible. This specific kind of reasoning deserves high attention because it is related to utilizing previous knowledge with open text-described scenes or facts. As can be seen from table V not just Unavailable models but also Public ones can achieve good results on various tests. | 常识推理是每个模型都能获得的重要能力之一。这种能力表示模型结合推理技能使用先验知识的能力。以《HellaSwag》为例,寻找文本的延续是具有挑战性的,因为给定文本包含故事的一部分,而作为延续的给定选择是棘手的,如果没有对世界的先验知识,这是不可能的。这种特殊的推理值得高度关注,因为它与利用先前的知识和开放的文本描述的场景或事实有关。从表V可以看出,不仅是Unavailable模型,Public模型也可以在各种测试中取得很好的结果。 |
GPT-4在HellaSwag常识数据集上表现最好;Davinci-003在OBQA问答数据集上表现最佳
| From the results presented in Table V it is clear that GPT-4 achieves best results for HellaSwag while Davinci-003 is best model for OBQA. It is also good to note that results for OBQA are not reported for all of the models and possibly davinci-003 is not the best model achieving highest results on OBQA. | 从表5的结果可以看出,GPT-4对HellaSwag的效果最好,而Davinci-003是OBQA的最佳模型。同样值得注意的是,并不是所有模型都报告了OBQA的结果,davincic -003可能不是在OBQA上获得最高结果的最佳模型。 |
| Not all models report their performance on all datasets, and because of that, the number of models for which performance is reported in different tables varies. | 并非所有模型都在所有数据集上报告其性能,因此,在不同表中报告性能的模型数量各不相同。 |
| World knowledge is mostly about general knowledge questions, for example, in Wikifact dataset questions such as ”Who is the author of a specific well-known book” can be found and references are also provided. Table VII shows the results. | 世界知识主要是关于一般知识的问题,例如,在Wikifact数据集中可以找到诸如“谁是某本知名书籍的作者”这样的问题,并提供参考文献。表7显示了结果。 |
| For some specific use-case models, it is highly demanded to have coding and code-generation capability. Table VIII shows the results of different models on coding capability. | 对于某些特定的用例模型,高度要求具有编码和代码生成功能。表8显示了不同模型对编码能力的结果。 |
| Arithmetic reasoning is another challenging reasoning capability to achieve. GSM8K for example contains grade school mathematical questions with respect to their answers. Table IX provides an insight for different model comparisons. | 算术推理是另一个具有挑战性的推理能力。例如,GSM8K包含有关其答案的小学数学问题。表9提供了对不同模型比较的见解。 |
| Large language models in some cases are hallucinating answers simply because they are next-token prediction machines. Hallucination is one of the important factors in measuring how much a large language model is trustworthy and reliable. Measuring hallucination on the other hand is also not easy as it seems because each fact can be written in different styles and even the smallest changes in writing make it hard to detect. It is fair to assume if any particular LLM is more capable to detect hallucination of false information in text, it is also more trustworthy. HaluEval is one of the datasets that aims to measure hallucination in this field [205]. Evaluation can also be performed by another model judging the response with regard to the actual answer [206]. Table X shows the evaluation of different models based on these datasets. | 在某些情况下,大型语言模型会产生幻觉答案,因为它们是下一个代币预测机器。幻觉是衡量一个大型语言模型可信度和可靠性的重要因素之一。另一方面,测量幻觉也不像看起来那么容易,因为每个事实都可以用不同的风格书写,即使是最小的书写变化也很难察觉。我们可以公平地假设,如果任何特定的LLM更有能力检测文本中虚假信息的幻觉,那么它也更值得信赖。HaluEval是该领域旨在测量幻觉的数据集之一[205]。评估也可以通过另一个模型来判断实际答案的反应[206]。表X显示了基于这些数据集对不同模型的评价。 |
VII. CHALLENGES AND FUTURE DIRECTIONS挑战与未来方向
| As we have seen in the previous sections, large language models have achieved impressive results in the past 1-2 years. | 正如我们在前面章节中看到的,大型语言模型在过去的1-2年中取得了令人印象深刻的成果。 |
| At the same time this is still a new and extremely active research area where the pace of innovation is increasing rather than slowing down. As in any other evolving area though, there are still numerous challenges ahead. Here we briefly mention some of the challenges and main active areas which are known so far. It is worth noting that LLM challenges are discussed in details in a work by Kaddour et al. [207]. | 与此同时,这仍然是一个新的、非常活跃的研究领域,创新的步伐正在加快而不是放缓。然而,就像在任何其他不断发展的领域一样,未来仍有许多挑战。在这里,我们简要地提到迄今为止所知道的一些挑战和主要活跃领域。值得注意的是,LLM面临的挑战在Kaddour等人的著作中有详细讨论[207]。 |
A. Smaller and more efficient Language Models更小、更高效的语言模型:如Phi系列小语言模型
针对大型语言模型的高成本和低效率,出现了对小型语言模型(SLMs)的研究趋势,如Phi-1、Phi-1.5和Phi-2
| This is a survey on large language models, and there has been an initial push towards ”larger is better” that has clearly been rewarded with ever larger models like GPT4 getting better accuracy and performance in benchmarks. However, those large models are costly and inefficient in several dimensions (e.g. high latency). In response to all of this, there is a current research trend to come up with Small Language Models (SLMs) as a cost-effective alternative to LLMs, particularly when used on specific tasks that might not require the full generality of larger models. Prominent works in this direction include Phi-1 [208], Phi-1.5 [209], and Phi-2 from Microsoft. | 这是一项关于大型语言模型的调查,并且已经开始推动“越大越好”,这显然得到了像GPT4这样的更大模型在基准测试中获得更好的准确性和性能的回报。然而,这些大型模型在几个方面(例如高延迟)是昂贵和低效的。作为对所有这些问题的回应,目前的研究趋势是提出小型语言模型(slm)作为LLM的一种经济有效的替代方案,特别是在用于可能不需要大型模型完全通用性的特定任务时。这方面的杰出作品包括微软的Phi-1[208]、Phi-1.5[209]和Phi-2。 |
未来预计将继续研究如何训练更小、更高效的模型,使用参数有效的微调(PEFT)、师生学习和其他形式的蒸馏等技术
| More generally, we should expect many research efforts in this area of how to train smaller and more efficient models. Techniques such as parameter-efficient fine-tuning (PEFT), teacher/student, and other forms of distillation – see section III-I – will continue to be used to build a smaller model out of larger ones. | 更一般地说,我们应该期待在如何训练更小更有效的模型这一领域的许多研究努力。诸如参数有效微调(PEFT)、教师/学生和其他形式的蒸馏(参见第III-I节)等技术将继续用于从大型模型中构建较小的模型。 |
B. New Post-attention Architectural Paradigms新的后注意力机制的架构范式:探索注意力机制之外的新架构,如状态空间模型和MoE混合专家模型
后注意力架构范式
传统的Transformer模块在当前LLM框架中起着关键作用,但越来越多的研究开始探索替代方案,被称为后注意力模型
过去使用的Transformer模块是当前大多数LLM框架的关键部分,但未来可能出现新的架构,如基于状态空间模型(SSM)的后注意力模型,如Mamba和Hyena
预计将在处理更长上下文和设计更高效架构方面进行更多研究。
| Transformer blocks have been a crucial and constant part of most of current LLM frameworks, and it’s a big question mark how much longer this architecture will be in vogue, and what will be the next big architectural break-through in the field of deep learning (and NLP). Since AlexNet in 2012, we have seen many architectures go in and out of fashion, including LSTM, GRU, seq2seq, but Transformers have been the dominant approach since its inception. As described earlier, attention is the main mechanism driving transformers. More recently, there has been promising research in alternative approaches that are being labelled as post-attention. | Transformer模块一直是当前大多数LLM框架的关键和恒定部分,这个架构还会流行多久,以及深度学习(和NLP)领域的下一个重大架构突破是什么,都是一个很大的问号。自2012年AlexNet以来,我们已经看到了许多架构的流行和过时,包括LSTM, GRU, seq2seq,但变形金刚自成立以来一直是主导方法。如前所述,注意力是驱动Transformer的主要机制。最近,在被称为“后注意力”的替代方法方面,有一些很有前途的研究。 |
结构状态空间模型(SSM)是一类重要的后注意力模型,如Mamba、Hyena和Striped Hyena
| An important class of such class of post-attention models are the so called State Space Models (SSMs). While the notion of State Space Models has a long history in machine learning, it should be noted that in the context of language models, SSM is usually used in reference to the newer Structure State Space Model architecture or S4 for short (see Gu et al. [29]). Some recent models in this category are Mamba [30], Hyena [210], and Striped Hyena [211]. | 这类后注意模型的一个重要类别是所谓的状态空间模型(ssm)。虽然状态空间模型的概念在机器学习中有着悠久的历史,但应该注意的是,在语言模型的上下文中,SSM通常用于参考较新的结构状态空间模型架构或简称S4(参见Gu等人[29])。这一类最近的一些模型是Mamba [30]、Hyena [210]和Striped Hyena[211]。 |
后注意力模型解决了传统基于注意力的架构在支持更大上下文窗口方面的挑战,为处理更长上下文提供了更有效的方法
| While all of those models are very competitive in terms of performance in leaderboards and efficiency, they also address an important challenge in more traditional attention-based architectures: the lack of support for larger context windows. | 虽然所有这些模型在排行榜的表现和效率方面都很有竞争力,但它们也解决了传统的基于注意力的架构所面临的一个重要挑战:缺乏对更大上下文窗口的支持。 |
| Having a good answer to many prompts requires context. For example, the response to ”Recommend some good movies for me” requires a lot of context about ”me” as well as what movies are available and which ones I have not watched. Context length is especially important for RAG, where large portions of text might be retrieved and injected into the prompt for generation (see section IV-C. | 对许多提示要有一个好的答案需要上下文。例如,“给我推荐一些好电影”的回答需要很多关于“我”的背景,以及哪些电影是可用的,哪些是我没有看过的。上下文长度对于RAG尤其重要,因为在RAG中可能会检索大量文本并将其注入生成提示符(参见第IV-C节)。 |
| The longer the context length, the more tokens we can squeeze into the context. The more information the model has access to, the better its response will be. But on the other hand, with very long context, it would be hard for the model to remember everything and efficiently process all the information. Attention-based models are highly inefficient for longer contexts and that is why we should expect more research in different mechanisms that enable processing longer contexts and generally come up with more efficient architectures. | 上下文长度越长,我们可以在上下文中挤入的令牌就越多。模型获得的信息越多,它的响应就越好。但另一方面,在非常长的上下文中,模型很难记住所有的内容并有效地处理所有的信息。基于注意力的模型对于较长的上下文是非常低效的,这就是为什么我们应该期待在不同的机制上进行更多的研究,以处理较长的上下文,并通常提出更有效的架构。 |
| That being said, new architectures might not only propose alternatives for the attention mechanism but rather rethink the whole Transformer architecture. As an early example of this, Monarch Mixer [212] proposes a new architecture that uses the same sub-quadratic primitive that achieves high hardware efficiency on GPUs – Monarch matrices – along both sequence length and model dimension. | 也就是说,新的架构可能不仅会为注意力机制提出替代方案,还会重新思考整个Transformer架构。作为一个早期的例子,Monarch Mixer[212]提出了一种新的架构,该架构使用相同的次二次基元,在GPU上实现高硬件效率-君主矩阵-沿序列长度和模型维度。 |
专家混合(MoE)机制
MoE机制已经存在多年,但近年来在Transformer模型和LLMs中越来越受欢迎,被应用于最先进和最具性能的模型中
| On the other end of the spectrum, it is worth mentioning that there are some attention-compatible architectural mechanisms that have been recently gaining steam and proving their value in creating better and more powerful LLMs. Probably the best example of such mechanism is Mixture of Experts (MoE). MoEs have been around in machine learning for years, even before the Deep Learning Era [213], but they have been gaining popularity since then, and particularly in the context of Transformer models and LLMs. | 另一方面,值得一提的是,最近有一些注意力兼容的架构机制获得了关注,并证明了它们在创建更好、更强大的LLM方面的价值。这种机制的最好例子可能是专家混合(MoE)。 |
MoEs允许训练极大的模型,而在推理过程中只部分实例化,其中一些专家被关闭。 MoEs已成为最先进LLMs的重要组成部分,例如GPT-4、Mixtral、GLaM
| In LLMs, MoEs allow to train an extremely large model than is then only partially instantiated during inference when some of the experts are turned off wherever the gating/weighting function has a low weight assigned to them. As an example, the GLaM model has 1.2 trillion parameters, but during inference only 2 out of the 64 experts are used [84]. | 在LLM中,moe允许训练一个非常大的模型,然后在推理期间只有部分实例化,当一些专家在门控/加权函数分配给他们的权重较低时关闭。例如,GLaM模型有1.2万亿个参数,但在推理过程中,64位专家中只有2位被使用[84]。 |
| MoEs are nowadays an important component of the socalled frontier LLMs (i.e. the most advanced and capable models). GPT-4 itself is rumored to be based on a MoE architecture, and some of the best performing LLMs such as Mixtral [117], are basically an MoE version of pre-existing LLMs. | moe现在是所谓的前沿LLM(即最先进和最有能力的模型)的重要组成部分。传闻GPT-4本身基于MoE架构,一些性能最好的LLM,如Mixtral[117],基本上是已有LLM的MoE版本。 |
| Finally, it is important to note that MoEs can be used as a component of any architecture regardless of whether it is based on attention or not. In fact, MoEs have also been applied to SSM-based LLMs like Mamba citepioro2024moemamba. We should continue to see MoE-driven improvements in the future regardless of the underlying architecture. | 最后,值得注意的是,moe可以作为任何架构的组件使用,而不管它是否基于注意力。事实上,MoEs也被应用于基于ssm的LLM,如Mamba citepioro2024moemamba。无论底层架构如何,我们都应该在未来继续看到由moe驱动的改进。 |
C. Multi-modal Models多模态模型:研发多模态语言模型,融合文本、图片、视频等多种数据类型
未来的LLMs预计将是多模态的,能够统一处理文本、图像、视频、音频等多种数据类型,如LLAVA、GPT-4等
| Future LLMs are expected to be multi-modal and handle a variety of data types, such as text, images, and videos, audio, in a unified manner. This opens up possibilities for more diverse applications in fields like question answering, content generation, creative arts, and healthcare, robotics, and beyond. There are already several prominent multi-modal LLMs out there, including: LLAVA [214], LLAVA-Plus [215], GPT-4 [33], Qwen-vl [116], Next-GPT [216], but the trend is expected to be continued. Evaluation of these models also is a new research topic, especially conversational generative vision models [217]. Multi-modal LLMs can unlock huge potentials in a variety of tasks, and there has already been a descent progress in this direction, which needs a dedicated paper to discuss all its details. | 未来的LLM预计将是多模态的,并以统一的方式处理各种数据类型,如文本、图像和视频、音频。这为问答、内容生成、创意艺术、医疗保健、机器人等领域的更多样化应用提供了可能性。目前已经有几个著名的多模式LLM,包括:LLAVA[214]、LLAVA- plus[215]、GPT-4[33]、Qwen-vl[116]、Next-GPT[216],但这一趋势预计将继续下去。对这些模型的评价也是一个新的研究课题,尤其是会话生成视觉模型[217]。多模式LLM可以在各种任务中释放出巨大的潜力,并且在这个方向上已经有了一个下降的进展,需要专门的论文来讨论它的所有细节。 |
D. Improved LLM Usage and Augmentation techniques改进LLM的使用和增强技术
通过高级提示工程(提升问答引导)、工具使用或其他增强技术,可以解决LLMs的一些缺陷和限制,如幻觉等
| As we described in sectionIV, many of the shortcomings and limitations of LLMs such as hallucination can be addressed through advanced prompt engineering, use of tools, or other augmentation techniques. We should expect not only continued, but accelerated research in this area. It is worth mentioning that, in the specific case of software engineering, some works ([218]) tried to automatically eliminate this issue from the overall software engineering workflow | 正如我们在第四节中所描述的,LLM的许多缺点和局限性,如幻觉,可以通过先进的快速工程、工具的使用或其他增强技术来解决。我们期望在这一领域的研究不仅会继续,而且会加速。值得一提的是,在软件工程的具体案例中,一些作品([218])试图从整个软件工程工作流程中自动消除这个问题 |
| LLM-based systems are already starting to replace machine learning systems that were until recently using other approaches. As a clear example of this, LLMs are now being deployed to better understand people preference and interests, and provide more personalized interactions, whether in customer service, content recommendation, or other applications. This involves better understanding of user preferences, and analyzing their past interactions and using them as the context. We will continue to see research in the application and usage of LLMs for not only personalization and recommendations, but many other application areas using other machine learning techniques. | 基于LLM的系统已经开始取代不久前还在使用其他方法的机器学习系统。作为一个明显的例子,LLM现在被用来更好地了解人们的偏好和兴趣,并提供更多个性化的互动,无论是在客户服务、内容推荐还是其他应用程序中。这包括更好地理解用户偏好,分析他们过去的交互并将其作为上下文。我们将继续看到LLM在个性化和推荐方面的应用和使用研究,以及使用其他机器学习技术的许多其他应用领域。 |
预计将在LLMs的应用和使用方面进行持续和加速的研究,如个性化推荐、多代理系统等
| Finally, another important area of research we expect to gather increased attention is that of LLM-based agents and multi-agent systems [172], [173], [174]. The development of LLM systems with access to external tools and decisionmaking capabilities is both exciting and challenging. We will see continued research and progress in this important area that some argue could lead to Artificial General Intelligence (AGI). | 最后,另一个值得关注的重要研究领域是基于LLM的智能体和多智能体系统[172],[173],[174]。具有外部工具和决策能力的LLM系统的开发既令人兴奋又具有挑战性。我们将看到这一重要领域的持续研究和进展,一些人认为这可能会导致人工通用智能(AGI)的出现。 |
E. Security and Ethical/Responsible AI安全和道德/负责任的人工智能:保障LLM模型安全性,减少对抗攻击,并注重LLM的公平性和负责任
需要研究确保LLMs对抗攻击和其他漏洞的稳健性和安全性,以防止它们被用于操纵人们或传播错误信息
| Ensuring the robustness and security of LLMs against adversarial attacks and other vulnerabilities is a critical area of research [219]. As LLMs are increasingly deployed in realworld applications, they need to be protected from potential threats, to prevent them being used to manipulate people or spread mis-information. | 确保LLM对对抗性攻击和其他漏洞的鲁棒性和安全性是一个关键的研究领域[219]。随着LLM越来越多地部署在现实世界的应用程序中,需要保护它们免受潜在威胁,以防止它们被用来操纵人或传播错误信息。 |
正在努力解决LLMs的道德关切和偏见问题,以确保它们公平、无偏见,并能够负责任地处理敏感信息
| Addressing ethical concerns and biases in LLMs is another active area of research. Efforts are being made to ensure that LLMs are fair, unbiased, and capable of handling sensitive information responsibly. As LLMs are being used more and more by a large number of people on a daily basis, making sure they are unbiased and behave responsibly is crucial. | 解决LLM中的伦理问题和偏见是另一个活跃的研究领域。我们正在努力确保LLM公平、公正,并能够负责任地处理敏感信息。随着越来越多的人每天都在使用LLM课程,确保他们公正、负责任的行为是至关重要的。 |
VIII. CONCLUSION结论
| This paper present a survey of LLMs developed in the past few years. We first provide an overview of early pretrained language models (e.g., as BERT), then review three popular LLM families (GPT, LLaMA, PaLM), and other representative LLMs. We then survey methods and techniques of building, augmenting, and using LLMs. We review popular LLM datasets and benchmarks, and compare performance of a set of prominent models on public benchmarks. Finally, we present open challenges and future research directions. | 本文对过去几年中开发的大型语言模型进行了调查。我们首先概述了早期预训练语言模型(如BERT),然后回顾了三个流行的大型语言模型系列(GPT、LLaMA、PaLM)以及其他代表性的大型语言模型。然后我们调查了构建、增强和使用大型语言模型的方法和技术。我们回顾了流行的大型语言模型数据集和基准,并在公共基准测试中比较了一组突出模型的性能。最后,提出了未来的研究方向和面临的挑战。 |
APPENDIX附录
Open Source Toolkits For LLM Development and Deployment用于LLM开发和部署的开源工具包
| There are various frameworks and libraries developed for LLM training, evaluation, and deployment, and covering every single framework is out of this paper’s scope. But we try to provide a brief introduction of some of the most popular ones, grouped into different categories. | 有各种各样的框架和库被开发用于LLM的训练、评估和部署,而覆盖每一个框架超出了本文的范围。但我们试图提供一些最流行的工具的简要介绍,并将其分成不同的类别。 |
A. LLM Training/Inference Frameworks训练/推理框架
| Some of the popular frameworks which are useful for LLM training includes (note that some of them can be used beyond LLM training too): | 一些对LLMs训练有用的流行框架包括(请注意,其中一些框架也可以在LLMs训练之外使用): |
DeepSpeed、Transformers、Megatron-LM、BMTrain
| DeepSpeed [220] is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. DeepSpeed enables world’s most powerful lan-guage models like MT-530B and BLOOM. It is an easy-to-use deep learning optimization software suite that powers unprecedented scale and speed for both training and inference. With DeepSpeed you can: Transformers [221] is library by HuggingFace which provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio. Using pretrained models one can reduce compute costs, carbon footprint, and save the time and resources required to train a model from scratch. Megatron-LM [222] is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA. It contains efficient, model-parallel (tensor, se-quence, and pipeline), and multi-node pre-training of trans-former based models such as GPT, BERT, and T5 using mixed precision. BMTrain [223] is an efficient large model training toolkit that can be used to train large models with tens of billions of parameters. It can train models in a distributed manner while keeping the code as simple as stand-alone training. | DeepSpeed[220]是一个深度学习优化库,它使分布式训练和推理变得简单、高效和有效。DeepSpeed使MT-530B和BLOOM等世界上最强大的语言模型成为可能。它是一个易于使用的深度学习优化软件套件,为训练和推理提供了前所未有的规模和速度。使用DeepSpeed,您可以: Transformers[221]是HuggingFace的库,它提供了数千个预训练模型来执行不同模式的任务,如文本、视觉和音频。使用预训练模型可以减少计算成本、碳足迹,并节省从头开始训练模型所需的时间和资源。 Megatron-LM[222]是由NVIDIA应用深度学习研究团队开发的大型强大变压器。它包含了高效的、模型并行的(张量、序列和管道),以及使用混合精度的基于transformer的模型(如GPT、BERT和T5)的多节点预训练。 BMTrain[223]是一个高效的大型模型训练工具包,可用于训练具有数百亿参数的大型模型。它可以以分布式的方式训练模型,同时保持代码像独立训练一样简单。 |
GPT-NeoX、LoRA、ColossalAI
| GPT-NeoX [224] leverages many of the same features and technologies as the popular Megatron-DeepSpeed library but with substantially increased usability and novel optimizations. LoRA [225] library provides the support for Low-Rank Adaptation of Large Language Models. It reduces the number of trainable parameters by learning pairs of rank-decompostion matrices while freezing the original weights. This vastly reduces the storage requirement for large language models adapted to specific tasks and enables efficient task-switching during deployment all without introducing inference latency. LoRA also outperforms several other adaptation methods in-cluding adapter, prefix-tuning, and fine-tuning. ColossalAI library [226] provides a collection of parallel components. It aims to support developers to write their distributed deep learning models just like how they write their model on their laptop. They provide user-friendly tools to kickstart distributed training and inference in a few lines. In terms of Parallelism strategies, they support: Data Parallelism, Pipeline Parallelism, Sequence Parallelism, Zero Redundancy Optimizer (ZeRO) [140], and Auto-Parallelism. | GPT-NeoX[224]利用了许多与流行的Megatron-DeepSpeed库相同的功能和技术,但大大提高了可用性和新颖的优化。 LoRA[225]库为大型语言模型的低秩自适应提供了支持。它通过学习秩分解矩阵对来减少可训练参数的数量,同时冻结原始权重。这大大减少了适应特定任务的大型语言模型的存储需求,并在部署期间实现了高效的任务切换,而不会引入推理延迟。LoRA还优于其他几种自适应方法,包括适配器、前缀调优和微调。 ColossalAI库[226]提供了一组并行组件。它旨在支持开发人员编写分布式深度学习模型,就像他们在笔记本电脑上编写模型一样。它们提供了用户友好的工具,只需几行就可以启动分布式训练和推理。在并行策略方面,它们支持:数据并行、管道并行、序列并行、零冗余优化器(Zero)[140]和自动并行。 |
B. Deployment Tools部署工具
| We provide an overview of some of the most popular LLM deployment tools here. | 我们在这里概述了一些最流行的LLM部署工具。 |
FastChat、Skypilot、vLLM、text-generation-inference、LangChain、Are context-aware
| FastChat [227] is an open platform for training, serv-ing, and evaluating large language model based chatbots. FastChat’s core features include: The training and evaluation code for state-of-the-art models (e.g., Vicuna, MT-Bench), and a distributed multi-model serving system with web UI and OpenAI-compatible RESTful APIs. Skypilot [228] is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. vLLM [229] is a fast and easy-to-use library for LLM in-ference and serving. vLLM seamlessly supports many Hugging Face models, including the following architectures: Aquila, Baichuan, BLOOM, ChatGLM, DeciLM, Falcon, GPT Big-Code, LLaMA, LLaMA 2, Mistral, Mixtral, MPT, OPT, Qwen, Yi, and many more. text-generation-inference [230] is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and more. LangChain [231] is a framework for developing applica-tions powered by language models. It enables applications that: Are context-aware: connect a language model to sources of context (prompt instructions, few shot ex-amples, content to ground its response in, etc.) Reason: rely on a language model to reason (about how to answer based on provided context, what ac-tions to take, etc.) | FastChat[227]是一个开放式平台,用于训练、服务和评估基于大型语言模型的聊天机器人。FastChat的核心功能包括:最先进的模型(例如,Vicuna, MT-Bench)的训练和评估代码,以及具有WebUI和OpenAI兼容的RESTful API的分布式多模型服务系统。 Skypilot[228]是一个在任何云上运行LLMs、AI和批处理作业的框架,提供最大的成本节约、最高的GPU可用性和管理执行。 vLLM[229]是一个快速且易于使用的用于LLM引用和服务的库。vLLM无缝支持多种Hugging Face模型,包括以下架构:Aquila, Baichuan, BLOOM, ChatGLM, DeciLM, Falcon, GPT Big-Code, LLaMA, LLaMA 2, Mistral, Mixtral, MPT, OPT, Qwen, Yi等等。 text-generation-inference[230]是一个用于部署和服务大型语言模型(LLMs)的工具包。TGI为最流行的开源LLMs(包括Llama、Falcon、StarCoder、BLOOM、GPT-NeoX等)提供高性能文本生成。 LangChain[231]是一个用于开发由语言模型驱动的应用程序的框架。它使应用程序能够: 具有上下文感知能力:连接语言模型到上下文源(提示指令、少量示例、内容以在其回应中进行梳理等)。 推理:依赖语言模型进行推理(根据提供的上下文来回答如何、采取什么行动等)。 |
OpenLLM、Embedchain、Autogen、BabyAGI
| OpenLLM [232] is an open-source platform designed to facilitate the deployment and operation of large language mod-els (LLMs) in real-world applications. With OpenLLM, you can run inference on any open-source LLM, deploy them on the cloud or on-premises, and build powerful AI applications. Embedchain [233] is an Open Source RAG Framework that makes it easy to create and deploy AI apps. Embedchain streamlines the creation of RAG applications, offering a seam-less process for managing various types of unstructured data. It efficiently segments data into manageable chunks, generates relevant embeddings, and stores them in a vector database for optimized retrieval. Autogen [234] is a framework that enables the devel-opment of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools. BabyAGI [235] is an autonomous Artificial Intelligence agent, that is designed to generate and execute tasks based on given objectives. It harnesses cutting-edge technologies from OpenAI, Pinecone, LangChain, and Chroma to automate tasks and achieve specific goals. In this blog post, we will dive into the unique features of BabyAGI and explore how it can streamline task automation. | OpenLLM[232]是一个开源平台,旨在促进大型语言模型(llm)在实际应用中的部署和操作。使用OpenLLM,您可以在任何开源LLM上运行推理,将它们部署在云端或本地,并构建强大的人工智能应用程序。 Embedchain[233]是一个开源的RAG框架,可以很容易地创建和部署AI应用程序。Embedchain简化了RAG应用程序的创建,为管理各种类型的非结构化数据提供了无缝的过程。它有效地将数据分割成可管理的块,生成相关的嵌入,并将它们存储在矢量数据库中以进行优化检索。 Autogen[234]是一个框架,它允许使用多个代理开发LLM应用程序,这些代理可以相互交谈以解决任务。AutoGen代理是可定制的、可对话的,并且无缝地允许人类参与。它们可以在各种模式下运行,这些模式结合了LLMs、人工输入和工具。 BabyAGI[235]是一种自主的人工智能代理,旨在根据给定的目标生成和执行任务。它利用来自OpenAI, Pinecone, LangChain和Chroma的尖端技术来自动化任务并实现特定目标。在这篇博文中,我们将深入研究BabyAGI的独特功能,并探索它如何简化任务自动化。 |
C. Prompting Libraries提示库
Guidance、PromptTools、PromptBench、Promptfoo
| Guidance [236] is a programming paradigm that offers superior control and efficiency compared to conventional prompting and chaining. It allows users to constrain generation (e.g. with regex and CFGs) as well as to interleave control (conditional, loops) and generation seamlessly. PromptTools [237] offers a set of open-source, self-hostable tools for experimenting with, testing, and evaluating LLMs, vector databases, and prompts. The core idea is to enable developers to evaluate using familiar interfaces like code, notebooks, and a local playground. PromptBench [?] is a Pytorch-based Python package for Evaluation of Large Language Models (LLMs). It provides user-friendly APIs for researchers to conduct evaluation on LLMs. Promptfoo [238] is a tool for testing and evaluating LLM output quality. It systematically test prompts, models, and RAGs with predefined test cases. | Guidance [236]是一种编程范式,与传统的提示和链接相比,它提供了更好的控制和效率。它允许用户约束生成(例如使用regex和CFGs)以及无缝地交错控制(条件,循环)和生成。 PromptTools[237]提供了一组开源的、自托管的工具,用于实验、测试和评估LLM、矢量数据库和提示符。其核心思想是使开发人员能够使用熟悉的界面(如代码、笔记本和本地游乐场)进行评估。 PromptBench [?是一个基于pytorch的Python包,用于评估大型语言模型(llm)。它提供了用户友好的API,供研究人员对llm进行评估。 Promptfoo[238]是一个测试和评估LLM输出质量的工具。它用预定义的测试用例系统地测试提示、模型和RAG。 |
D. VectorDB
Faiss、Milvus、Qdrant、Weaviate、LlamaIndex、Pinecone
| Faiss [239] is a library developed by Facebook AI Re-search that provides efficient similarity search and clustering of dense vectors. It is designed for use with large-scale, high-dimensional data and supports several index types and algorithms for various use cases. Milvus [240] is an open-source vector database built to power embedding similarity search and AI applications. Mil-vus makes unstructured data search more accessible, and pro-vides a consistent user experience regardless of the deployment environment. Qdrant [241] is a vector similarity search engine and vector database. It provides a production-ready service with a convenient API to store, search, and manage points—vectors with an additional payload Qdrant is tailored to extended filtering support. environment. Weaviate [242] is an open-source, GraphQL-based vec-tor search engine that enables similarity search on high-dimensional data. While it is open-source, the commercial ver-sion offers additional features, support, and managed services. Some of the other popular options includes LlamaIndex [243] and Pinecone. | Faiss[239]是由Facebook AI research开发的库,提供高效的相似性搜索和密集向量聚类。它是为使用大规模、高维数据而设计的,并支持针对各种用例的多种索引类型和算法。 Milvus[240]是一个开源矢量数据库,旨在为嵌入相似度搜索和人工智能应用提供动力。Mil-vus使非结构化数据搜索更容易访问,并且无论部署环境如何,都提供一致的用户体验。 Qdrant[241]是一个矢量相似度搜索引擎和矢量数据库。它提供了一个生产就绪的服务,提供了一个方便的API来存储、搜索和管理点向量,并提供了一个额外的有效负载Qdrant专为扩展过滤支持的环境而定制。 Weaviate[242]是一个开源的、基于GraphQL的向量搜索引擎,它支持在高维数据上进行相似度搜索。虽然它是开源的,但商业版本提供了额外的特性、支持和托管服务。 其他一些流行的选择包括LlamaIndex[243]和Pinecone。 |



















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











