









MLM之Llama-3:Llama 3.2的简介、安装和使用方法、案例应用之详细攻略
目录
LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略
LLMs之LLaMA-2:LLaMA 2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之Llama-3:Llama 3的简介、安装和使用方法、案例应用之详细攻略
LLMs之llama3-from-scratch:llama3-from-scratch(从头开始利用pytorch来实现并解读LLaMA-3模型的每层代码)的简介、核心思路梳理
LLMs之Llama-3.1:Llama 3.1的简介、安装和使用方法、案例应用之详细攻略
MLM之Llama-3:Llama 3.2的简介、安装和使用方法、案例应用之详细攻略
T1、采用Docker部署本地LLM:直接使用Docker命令
第二步,基于OpenAI Python SDK实现与本地LLM服务进行交互
T1、基于Ollama实现本地部署并启用llama3.2:1b模型服务
相关文章
LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略
LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略_chinese_calendar每年手动更新-CSDN博客
LLMs之LLaMA-2:LLaMA 2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_llama2-CSDN博客
LLMs之Llama-3:Llama 3的简介、安装和使用方法、案例应用之详细攻略
LLMs之Llama 3:Llama 3的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
LLMs之llama3-from-scratch:llama3-from-scratch(从头开始利用pytorch来实现并解读LLaMA-3模型的每层代码)的简介、核心思路梳理
LLMs之llama3-from-scratch:llama3-from-scratch(从头开始利用pytorch来实现并解读LLaMA-3模型的每层代码)的简介、核心思路梳理-CSDN博客
LLMs之Llama-3.1:Llama 3.1的简介、安装和使用方法、案例应用之详细攻略
LLMs之Llama 3.1:Llama 3.1的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
MLM之Llama-3:Llama 3.2的简介、安装和使用方法、案例应用之详细攻略
MLM之Llama-3:Llama 3.2的简介、安装和使用方法、案例应用之详细攻略_llama 3.2安装教程-CSDN博客
Llama 3.2 简介
2024年9月26日,Meta发布Llama 3.2,这是一款开源的大规模语言模型(LLM)集合,支持多种版本,覆盖从 1B、3B、11B 到 90B 参数规模。Llama 3.2 具有多模态能力,其中 1B 和 3B 版本仅支持文本处理,而 11B 和 90B 版本则能够处理文本和图像输入,并生成文本输出。通过 Llama 3.2,开发者可以在各种平台上进行模型的微调、蒸馏和部署,使其在多场景下得以应用。
Llama 3.2 是一个强大且灵活的开源 AI 模型家族,涵盖从小规模轻量模型到多模态巨型模型,适合广泛的场景和设备应用。通过其灵活的工具链和丰富的生态系统,开发者能够更快速地开发和部署高效的 AI 应用。
1、Llama 3.2 的特点
>> 多版本支持:提供从 1B 到 90B 参数规模的模型。较小的模型(1B、3B)可以在移动设备和边缘设备上高效运行,而较大的多模态模型(11B、90B)则可以处理图像输入,并在视觉推理等场景中表现优异。
>> 多模态能力:11B 和 90B 版本支持图像和文本输入,能够在高分辨率图像上进行推理和转换,如图像生成或信息提取。
>> 轻量高效:1B 和 3B 模型设计轻量化,适合在手机等本地设备上运行,可用于诸如会议摘要、调用本地日历等应用场景。
>> 多样的开发环境支持:开发者可以使用 Python、Node、Kotlin 和 Swift 等编程语言,在任意环境中构建和部署 Llama 3.2。
>> 开源生态系统:Llama Stack 工具链提供流畅的开发体验,原生支持代理工具调用、安全防护、增强生成等功能,并与开源社区高度兼容。
>> 广泛的基准测试:Llama 3.2 在超过 150 个数据集上进行评估,涵盖多种语言和任务领域,并在人类评估中表现出优异的性能。
2、模型评估
轻量级指令调优基准

视觉指令调整基准

Llama 3.2 的安装和使用方法
1、安装
(1)、下载模型
>> 可从 Hugging Face 或官方提供的资源中下载 Llama 3.2 模型。
>> 根据需要选择合适的模型大小,如轻量级的 1B 和 3B 模型,或者支持多模态的 11B 和 90B 模型。
(2)、开发环境准备
>> 安装 Llama 相关的开发工具链,如 Llama Stack,它能提供优化的开发和部署体验。
>> 支持多种编程语言,如 Python、Node.js、Kotlin 和 Swift,开发者可以根据需求选择合适的语言进行开发。
(3)、使用模型进行推理和微调
>> 在设备上运行轻量化模型,可以进行文本摘要、信息检索等任务。
>> 在需要图像处理的场景中,使用 11B 和 90B 模型进行多模态推理,如图像生成和识别。
(4)、部署
>> Llama 3.2 支持本地部署、边缘部署和云部署,开发者可以选择合适的环境进行部署。
>> 配合 Llama Stack,开发者可以通过标准化 API 更快地进行模型部署和迭代。
2、使用方法
第一步,采用Docker和VLLM部署并开启服务
提供了两种部署方式,一种是直接使用Docker命令,另一种是使用Docker Compose。两种方式都需要映射端口、挂载缓存目录,并设置环境变量。
| Docker | Docker Compose | |
| 简介 | Docker是一种容器化技术,它允许开发者打包应用程序及其依赖环境到一个可移植的容器中,然后这个容器可以在任何支持Docker的环境中运行。在代码中,使用Docker的命令行工具来直接运行一个容器。 | Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。它使用YAML文件来配置应用程序的服务。在代码中,Docker Compose的使用是通过创建一个docker-compose.yml文件来定义服务,然后通过运行docker-compose up命令来启动所有定义的服务。 |
| 区别 | >> 复杂性:Docker命令行工具通常用于运行单个容器,而Docker Compose用于运行多服务应用程序。 >> 配置方式:Docker命令行工具直接在命令中指定容器选项,而Docker Compose通过YAML文件来配置容器和服务。 >> 功能范围:Docker Compose提供了更多的功能,如服务依赖管理、服务启动顺序控制等。 | |
| 关系 | >> Docker Compose实际上是在Docker之上的一个抽象层,它依赖于Docker来运行容器。 >> Docker Compose通过读取docker-compose.yml文件中的配置来决定如何使用Docker运行容器。 >> 使用Docker Compose时,你仍然是在使用Docker容器,但是是通过更高级别的抽象来管理它们。 | |
T1、采用Docker部署本地LLM:直接使用Docker命令
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-- env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model AMead10/Llama-3.2-3B-Instruct-AWQ \
--quantization awq \
--max-model-len 2048T2、采用Docker Compose部署本地LLM
services:
vllm:
image: vllm/vllm-openai:latest
command: ["--model", "AMead10/Llama-3.2-3B-Instruct-AWQ", "--max-model-len", "2048", "--quantization", "awq"]
ports:
- 8000:8000
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
environment:
- "HUGGING_FACE_HUB_TOKEN=<secret>"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]第二步,基于OpenAI Python SDK实现与本地LLM服务进行交互
需修改base_url、api_key和model变量
%pip install openai
from openai import OpenAI
client = OpenAI(
base_url= "http://localhost:8000/v1" ,
api_key= "None" ,
)
chat_completion = client.chat.completions.create(
messages=[
{
"role" : "user" ,
"content" : "Say this is a test" ,
}
],
model= "AMead10/Llama-3.2-3B-Instruct-AWQ" ,
)第三步,交互测试:是否按照预期进行
通过发送一个测试消息并打印回复,来验证本地LLM服务是否正常运行。
print(chat_completion.choices[ 0 ].message.content)3、在线测试
4、基于Ollama等框架实现推理
T1、基于Ollama实现本地部署并启用llama3.2:1b模型服务
ollama run llama3.2:1b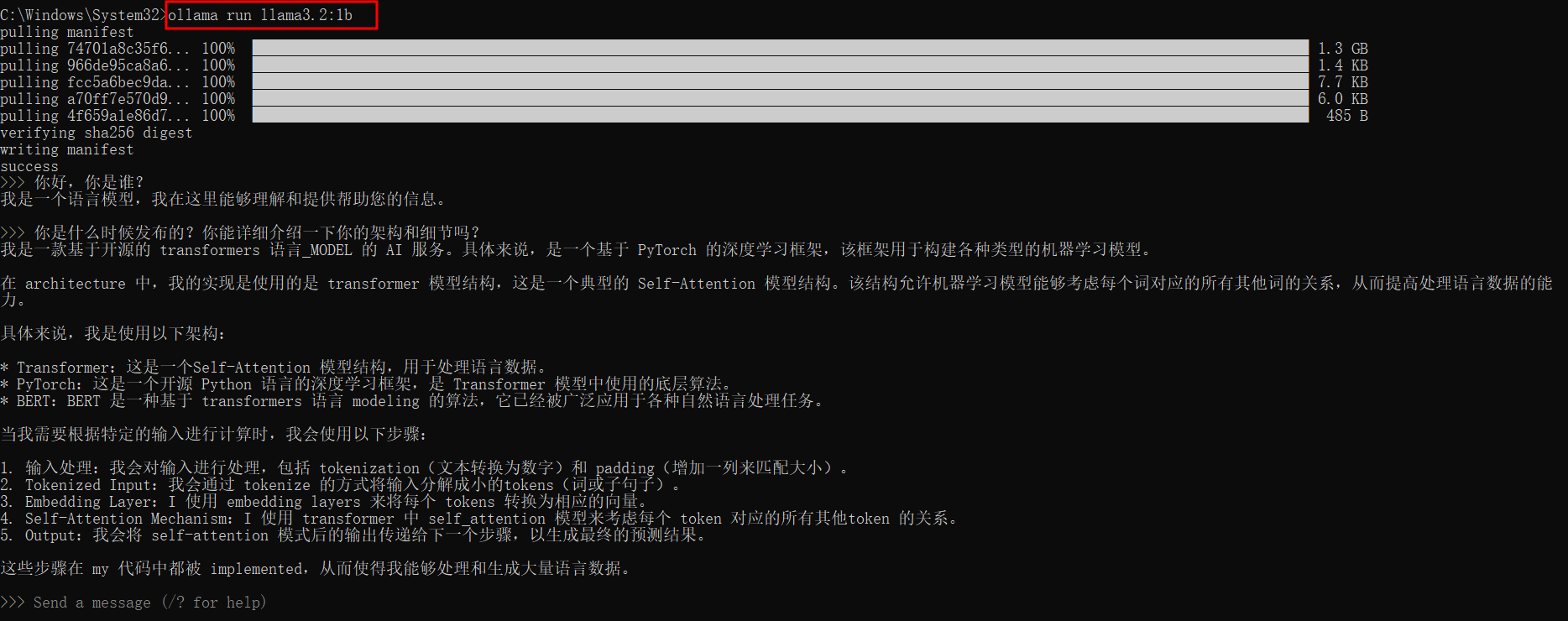
Llama 3.2 的案例应用
1、移动设备上的本地智能应用
- 通过 1B 和 3B 模型,用户可以在手机上运行本地智能助手,实现会议摘要、调用日历等功能,而不需要依赖云端处理,提升隐私保护。
2、图像生成与分析
- 利用 11B 和 90B 模型的多模态能力,用户可以对高分辨率图像进行推理,如将输入图像转化为全新的图像,或从周围环境的图像中提取详细信息。
3、增强现实和虚拟现实
- 在增强现实(AR)和虚拟现实(VR)应用中,Llama 3.2 的多模态模型可以用于图像理解和生成,帮助用户更深入地与虚拟环境互动。
4、企业级应用
- 媒体公司和大企业可以通过 Llama Stack 部署 Llama 3.2 来优化工作流、开发高效的智能工具。例如,使用 90B 模型进行复杂的数据分析和视觉推理,提高业务效率。



















 2470
2470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











