







《原始论文:Gradient-Based Learning Applied to Document Recognition》
LeNet是卷积网络做识别的开山之作,虽然LeNet5的网络结构现在已经很少使用,但是它对后续卷积网络的发展起到了奠基作用,打下了很好的理论基础。
LeNet-5是卷积网络的开上鼻祖,它是用来识别手写邮政编码的,论文可以参考Haffner. Gradient-based learning applied to document recognition.
LeNet5 这个网络虽然很小,但是它包含了神经网络的基本模块:卷积层,池化层,全链接层。是其他神经网络模型的基础。
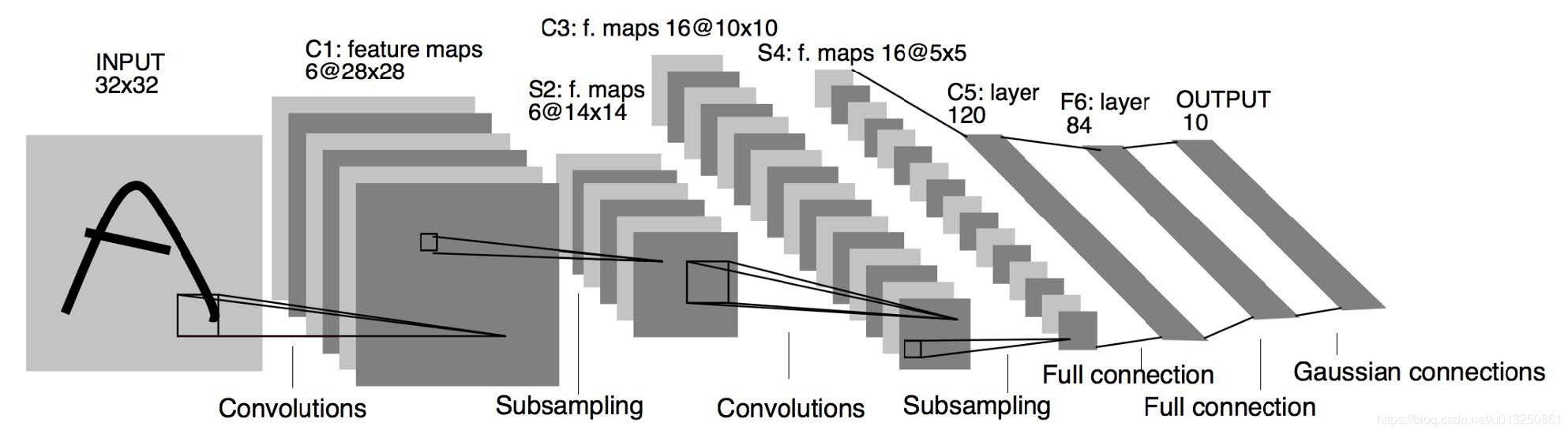
- 大名鼎鼎的LeNet5诞生于1994年,是最早的深层卷积神经网络之一,并且推动了深度学习的发展。
- 从1988年开始,在多次成功的迭代后,这项由Yann LeCun完成的开拓性成果被命名为LeNet5。
- LeCun认为,可训练参数的卷积层是一种用少量参数在图像的多个位置上提取相似特征的有效方式,这和直接把每个像素作为多层神经网络的输入不同。像素不应该被使用在输入层,因为图像具有很强的空间相关性,而使用图像中独立的像素直接作为输入则利用不到这些相关性。
- LeNet-5 共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
- LeNet-5的特点:
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样(Subsample)的平均池化层(Average Pooling)
- 双曲正切(Tanh)或S型(Sigmoid)的激活函数 MLP作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂度
1、INPUT层-输入层
- 首先是数据 INPUT 层,输入图像的尺寸统一归一化为32×32。
- 注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
- 输入图片: 32 × 32 32×32 32×32
- 卷积核大小: 5 × 5 5×5 5×5
- 卷积核种类:6
- 输出featuremap大小: ( 32 − 5 + 1 ) × ( 32 − 5 + 1 ) = 28 × 28 (32-5+1)×(32-5+1) =28×28 (32−5+1)×(32−5+1)=28×28
- 神经元数量: 28 × 28 × 6 28×28×6 28×28×6
- 可训练参数: ( 5 × 5 + 1 ) × 6 (5×5+1)× 6 (5×5+1)×6(每个滤波器 5 × 5 = 25 5×5=25 5×5=25 个unit参数和一个bias参数,一共6个滤波器)
- 连接数: ( 5 × 5 + 1 ) × 6 × 28 × 28 = 122304 (5×5+1)×6×28×28=122304 (5×5+1)×6×28×28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5 × 5 5×5 5×5 的卷积核),得到6个C1特征图(6个大小为28×28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5×5,总共就有6×(5×5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5×5个像素和1个bias有连接,所以总共有156×28×28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
- 输入:28×28
- 采样区域:2×2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:6
- 输出featureMap大小: 28 2 × 28 2 = 14 × 14 \cfrac{28}{2}×\cfrac{28}{2}=14×14 228×228=14×14
- 神经元数量:14×14×6
- 连接数:(2×2+1)×6×14×14
- S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2×2核 进行池化,于是得到了S2,6个14×14的 特征图(28/2=14)。S2这个pooling层是对C1中的2×2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有5x14x14x6=5880个连接。
4、C3层-卷积层
- 输入:S2中所有6个或者几个特征map组合
- 卷积核大小:5×5
- 卷积核种类:16
- 输出featureMap大小:10×10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)=1516
连接数:10×10×1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5×5. 我们知道S2 有6个 14×14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:

C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5×5,所以总共有6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)=1516个参数。而图像大小为10×10,所以共有151600个连接。

C3与S2中前3个图相连的卷积结构如下图所示:
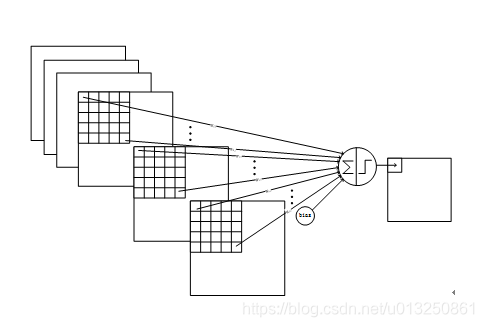
上图对应的参数为 3×5×5+1,一共进行6次卷积得到6个特征图,所以有6×(3×5×5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
- 输入:10×10
- 采样区域:2×2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:16
- 输出featureMap大小:5×5(10/2)
- 神经元数量:5×5×16=400
- 连接数:16×(2×2+1)×5×5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是2×2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
- 输入:S4层的全部16个单元特征map(与s4全相连)
- 卷积核大小:5×5
- 卷积核种类:120
- 输出featureMap大小:1×1(5-5+1)
- 可训练参数/连接:120×(16×5×5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
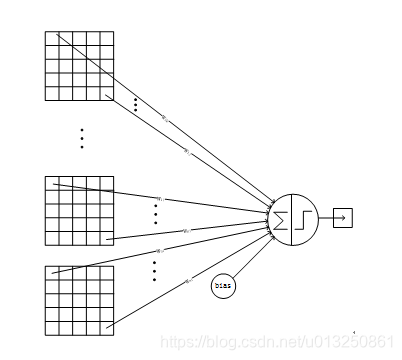
7、F6层-全连接层
- 输入:c5 120维向量
- 计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
- 可训练参数:84×(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

F6层的连接方式如下:

8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:

上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7×12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
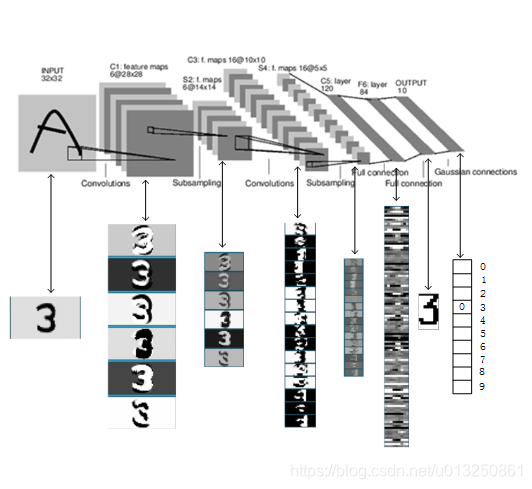
上图是LeNet-5识别数字3的过程。
9、LeNet5案例-cifar10分类数据集【Pytorch】
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
class Lenet5(nn.Module):
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 16, *, *]
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# x: [b, 16, *, *] => [b, 32, *, *]
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# flatten
self.fc_unit = nn.Sequential(
nn.Linear(32 * 5 * 5, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
batch_size = x.size(0) # [2000, 3, 32, 32]
x = self.conv_unit(x) # [b, 3, 32, 32] => [b, 32, 5, 5]
x = x.view(batch_size, 32 * 5 * 5) # [32, 16, 5, 5] => [b, 32*5*5]
logits = self.fc_unit(x) # [b, 16*5*5] => [b, 10]
return logits
def main():
batch_size = 5000
# 一、获取cifar10训练数据集
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
# 二、设置GPU
device = torch.device('cuda')
# 三、实例化Lenet5神经网络模型
model = Lenet5().to(device)
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 六、训练
for epoch in range(3):
# **********************************************************训练**********************************************************
print('**************************训练模式:开始**************************')
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(cifar_train):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch, batch_index, loss.item()))
print('**************************训练模式:结束**************************')
# **********************************************************模型评估**********************************************************
print('**************************验证模式:开始**************************')
model.eval() # 切换至验证模式
with torch.no_grad(): # torch.no_grad()所包裹的部分不需要参与反向传播
# test
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(cifar_test):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
acc = total_correct / total_num
print('epoch = {0}, batch_index = {1}, test acc = {2}'.format(epoch, batch_index, acc))
print('**************************验证模式:结束**************************')
if __name__ == '__main__':
main()
打印结果:
Files already downloaded and verified
Files already downloaded and verified
model = Lenet5(
(conv_unit): Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc_unit): Sequential(
(0): Linear(in_features=800, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
)
)
**************************训练模式:开始**************************
epoch = 0, batch_index = 0, loss.item() = 2.3143210411071777
epoch = 0, batch_index = 1, loss.item() = 2.287487268447876
epoch = 0, batch_index = 2, loss.item() = 2.2606987953186035
epoch = 0, batch_index = 3, loss.item() = 2.226912498474121
epoch = 0, batch_index = 4, loss.item() = 2.1867635250091553
epoch = 0, batch_index = 5, loss.item() = 2.1441078186035156
epoch = 0, batch_index = 6, loss.item() = 2.109809398651123
epoch = 0, batch_index = 7, loss.item() = 2.093820810317993
epoch = 0, batch_index = 8, loss.item() = 2.043757438659668
epoch = 0, batch_index = 9, loss.item() = 2.004603862762451
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 0, batch_index = 0, test acc = 0.2954
epoch = 0, batch_index = 1, test acc = 0.2912
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 1, batch_index = 0, loss.item() = 1.9749507904052734
epoch = 1, batch_index = 1, loss.item() = 1.9384398460388184
epoch = 1, batch_index = 2, loss.item() = 1.9332951307296753
epoch = 1, batch_index = 3, loss.item() = 1.9169594049453735
epoch = 1, batch_index = 4, loss.item() = 1.892669677734375
epoch = 1, batch_index = 5, loss.item() = 1.8858933448791504
epoch = 1, batch_index = 6, loss.item() = 1.857857584953308
epoch = 1, batch_index = 7, loss.item() = 1.8486536741256714
epoch = 1, batch_index = 8, loss.item() = 1.8345849514007568
epoch = 1, batch_index = 9, loss.item() = 1.808337688446045
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 1, batch_index = 0, test acc = 0.3732
epoch = 1, batch_index = 1, test acc = 0.3739
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 2, batch_index = 0, loss.item() = 1.7996269464492798
epoch = 2, batch_index = 1, loss.item() = 1.787319540977478
epoch = 2, batch_index = 2, loss.item() = 1.7761077880859375
epoch = 2, batch_index = 3, loss.item() = 1.7711927890777588
epoch = 2, batch_index = 4, loss.item() = 1.7415823936462402
epoch = 2, batch_index = 5, loss.item() = 1.7422986030578613
epoch = 2, batch_index = 6, loss.item() = 1.7195093631744385
epoch = 2, batch_index = 7, loss.item() = 1.7159980535507202
epoch = 2, batch_index = 8, loss.item() = 1.6884196996688843
epoch = 2, batch_index = 9, loss.item() = 1.6863059997558594
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 2, batch_index = 0, test acc = 0.408
epoch = 2, batch_index = 1, test acc = 0.4128
**************************验证模式:结束**************************
Process finished with exit code 0
参考资料:
CNN模型合集 | 1 LeNet
【DeepLearning】LeNet-5
卷积神经网络Lenet-5实现
图像分类丨ILSVRC历届冠军网络「从AlexNet到SENet」















 2402
2402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









