







 超级会员免费看
超级会员免费看
搜索推荐场景下的模型训练,经常面临数据量大、特征维度高且稀疏化、实时性高等问题。以千亿特征规模点击率预估模型、万亿边图模型为例,它们相比视觉、自然语言处理模型有以下特点:
搜索推荐线上服务预测样本的数据分布会随时间产生变化,如果使用固定数据集训练模型,在数据分布变化的情况下,模型不能很好的匹配线上数据,其效果会明显降低。为提升模型准确性,需要将线上服务产生的数据流式地加入到训练过程中去,让模型不断拟合最近的线上数据。
一个典型的推荐场景点击率预估模型的训练、推理全流程示意图如下:
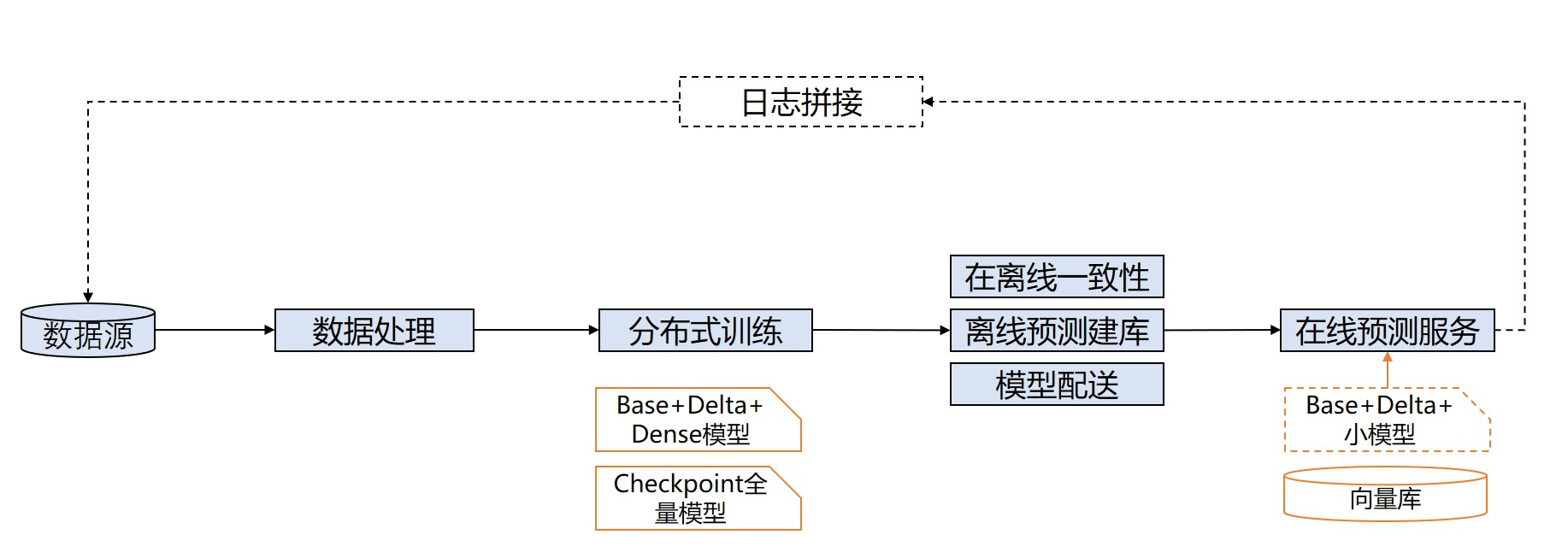
图 1 点击率预估模型的训练、推理全流程
图中的分布式训练方式称为流式训练(也称在线学习),即模型训练数据集并非固定,而是随时间流式地加入到训练过程中,实时更新模型并配送到线上推理服务中,因此对训练时间和模型保存、配送时间有严格要求。
除此之外,该场景下的模型训练还有以下两个特点:
-
稀疏参数量大:模型特征中包含大量的 id 类特征(例如 userid、itemid),这些 id 类特征会对应大量的 embedding(称为稀疏参数),通常参数量在百亿级别及以上,

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









