










目录
一、提要
如果现在有一个包含剪辑语音和对应的文本,我们不知道如何将语音片段与文本进行对应,这样对于训练一个语音识别器增加了难度。
如下图,存在图片与文本的对齐不易,语音声波对文本的对齐不易。

以上构成如下事实:
输入(如音频信号)用符号序列 和标签
,为了方便训练这些数据我们希望能够找到输人X与输出Y 之间精确的映射关系。
先梳理一下有几个难点:
- X的长度是不固定的。
- 当固定X长度,对应的Y长度是不固定的。
- X中任意元素和Y中任意元素
和
之间对应是不固定的。
使用CTC算法能克服上述问题。到这里可以知道CTC就是可以解决输入输出对应问题的一种算法。
二、算法原理
这里我们首先需要明确的是,还拿语音识别来说,现在使用的CTC常用的场景是RNN后接CTC算法,RNN模型输入是一个个音频片段,输出个数与输入的维度一样,有T个音频片段,就输出T个维度的概率向量,每个向量又由字典个数的概率组成。例如网络输入音频个数定为T,字典中不同字的个数为N,那么RNN输出的维度为T × N 。根据这个概率输出分布,我们就能得到最可能的输出结果。在接下来的讨论中可以把RNN+CTC看成一个整体,当然也可以将RNN替换成其他的提取特征算法。
2.1 损失函数的定义
对于给定的输入X,我们训练模型希望最大化Y 的后验概率P(Y|X),P(Y|X)应该是可导的,这样我们就能利用梯度下降训练模型了。
2.2 测试和验证
当我们已经训练好一个模型后,输入X,我们希望输出Y 的条件概率最高即而且我们希望尽量快速的得到
值,利用CTC我们能在低投入情况下迅速找到一个近似的输出。
2.3 CTC对齐算法
CTC算法对于输入的X能给出非常多的Y的条件概率输出(可以想象RNN输出概率分布矩阵,所以通过矩阵中元素的组合可以得到很多Y值作为最终输出),在计算输出过程的一个关键问题就是CTC算法如何将输入和输出进行对齐的。在接下来的部分中,我们先来看一下对齐的解决方法,然后介绍损失函数的计算方法和在测试阶段中找到合理输出的方法。
CTC算法并不要求输入输出是严格对齐的。但是为了方便训练模型我们需要一个将输入输出对齐的映射关系,知道对齐方式才能更好的理解之后损失函数的计算方法和测试使用的计算方法。
为了更好的理解CTC的对齐方法,先举个简单的对齐方法。假设对于一段音频,我们希望的输出是Y = [ c , a , t ] 这个序列,一种将输入输出进行对齐的方式如下图所示,先将每个输入对应一个输出字符,然后将重复的字符删除。
上述对齐方式有两个问题:
通常这种对齐方式是不合理的。比如在语音识别任务中,有些音频片可能是无声的,这时候应该是没有字符输出的
对于一些本应含有重复字符的输出,这种对齐方式没法得到准确的输出。例如输出对齐的结果为[ h , h , e , l , l , l , o ],通过去重操作后得到的不是“hello”而是“helo”
为了解决上述问题,CTC算法引入的一个新的占位符用于输出对齐的结果。这个占位符称为空白占位符,通常使用符号ϵ \epsilonϵ,这个符号在对齐结果中输出,但是在最后的去重操作会将所有的ϵ \epsilonϵ删除得到最终的输出。利用这个占位符,可以将输入与输出有了非常合理的对应关系,如下图所示。 
在这个映射方式中,如果在标定文本中有重复的字符,对齐过程中会在两个重复的字符当中插入ϵ \epsilonϵ占位符。利用这个规则,上面的“hello”就不会变成“helo”了。
回到上面Y = [ c , a , t ] 这个例子来,下图中有几个示列说明有效的对齐方式和无效的对齐方式,在无效的对齐方式中举了三种例子,占位符插入位置不对导致的输出不对,输出长度与输入不对齐,输出缺少字符a

2.4 CTC算法的对齐方式有下列属性:
- 输入与输出的对齐方式是单调的,即如果输入下一输入片段时输出会保持不变或者也会移动到下一个时间片段
- 输入与输出是多对一的关系
- 输出的长度小于等于输入
三、CTC损失函数
这里要明确一点,对于一个标定好的音频片段,训练该片段时,我们希望的输出就是标定的文本,如下图所示,音频说的一个hello,RNN或者其他模型输出的是相同数量的向量,向量里是每个字母的概率。
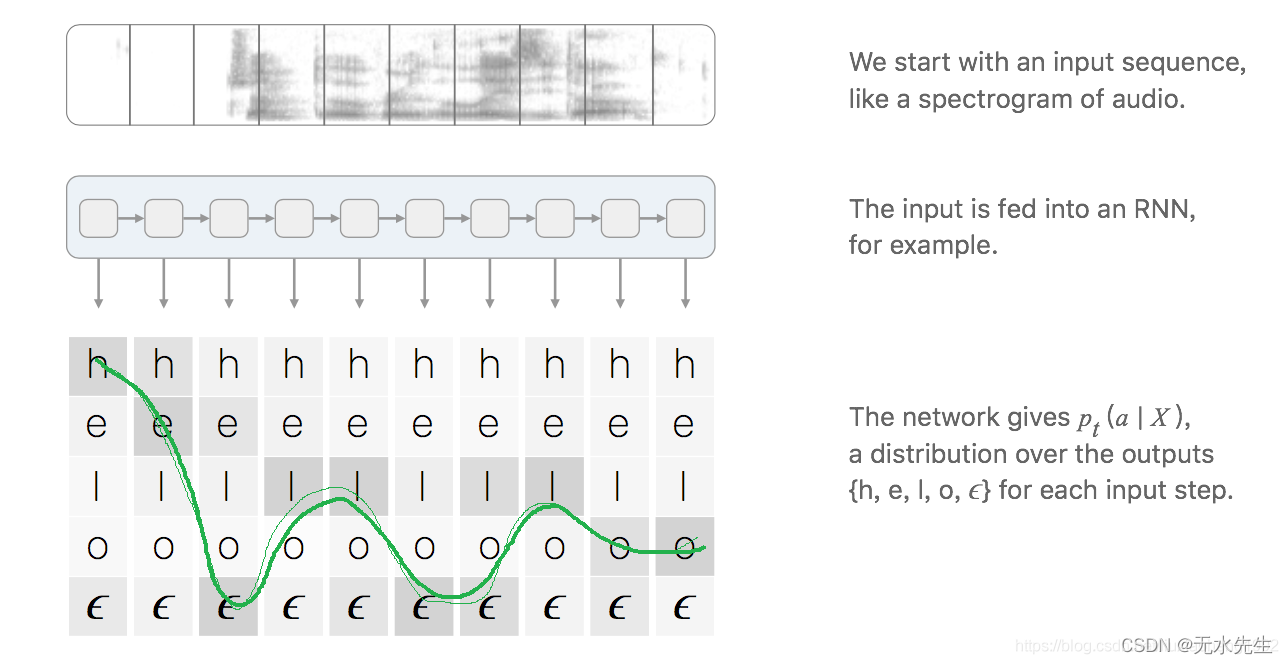
对于一对输入输出( X , Y ) 来说,CTC的目标是将下式概率最大化:
解释一下,对于RNN+CTC模型来说,RNN输出的就是概率,t表示的是RNN里面的时间的概念。乘法表示一条路径的所有字符概率相乘,加法表示多条路径。因为上面说过CTC对齐输入输出是多对一的,例如heϵlϵloϵ与h e e ϵ l ϵ l o对应的都是“hello”,这就是输出的其中两条路径,要将所有的路径相加才是输出的条件概率.
但是对于一个输出,路径会非常的多,这样直接计算概率是不现实的,CTC算法采用动态规划的思想来求解输出的条件概率,如下图所示,该图想说明的是通过动态规划来进行路径的合并(看不懂也没关系,下面有详细的解释)

这里有必要将动态规划分开另外讲述:《动态规划原理》。
四、CTC的特征
- 条件独立假设:
CTC的一个非常不合理的假设是其假设每个时间片都是相互独立的,这是一个非常不好的假设。在OCR或者语音识别中,各个时间片之间是含有一些语义信息的,所以如果能够在CTC中加入语言模型的话效果应该会有提升。
- 单调对齐:
CTC的另外一个约束是输入X与输出Y之间的单调对齐,在OCR和语音识别中,这种约束是成立的。但是在一些场景中例如机器翻译,这个约束便无效了。
- 多对一映射:
CTC的又一个约束是输入序列X的长度大于标签数据 Y的长度,但是对于X XX的长度大于Y YY的长度的场景,CTC便失效了。


















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











