






一、说明
开始都本文之前,需要读者预先知道两个概念,方差分析、混淆矩阵;本文将对两者的异同点进行分析。
二、混淆矩阵、方差分析
2.1 混淆矩阵
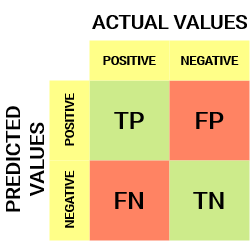
混淆矩阵就像一个图表,可以帮助我们了解机器学习模型的表现如何。想象一下,我们有一个希望机器识别的东西列表,比如猫和狗的图片。混淆矩阵显示了机器做对了多少次(例如,它正确地将猫的图片识别为猫),以及它弄错了多少次(例如,它认为猫的图片实际上是狗)。
2.2 方差分析
方差分析分数就像一个数字,告诉我们机器学习模型的表现如何。它代表“方差分析”,基本上意味着我们正在查看我们希望机器识别的事物(如猫和狗的图片)之间的差异,并查看机器是否能够正确区分它们。方差分析分数越高,机器学习模型就越能识别我们希望它识别的事物之间的差异。
混淆矩阵和方差分析分数是数据分析和机器学习中使用的统计度量。
混淆矩阵用于通过将预测值与实际值进行比较来评估分类模型的性能。它是一个包含四个单元格的表,这些单元格表示真阳性、误报、真负和假阴性的数量。在现实生活中,混淆矩阵可用于评估医学测试的性能,其中真阳性率表示测试的敏感性,真阴率表示测试的特异性。
三、python代码
3.1 创建混淆矩阵的 Python 代码示例
from sklearn.metrics import confusion_matrix
# Actual values
y_true = [1, 0, 1, 0, 1, 0, 0, 1]
# Predicted values
y_pred = [1, 1, 1, 0, 1, 0, 1, 1]
# Create confusion matrix
confusion_matrix = confusion_matrix(y_true, y_pred)
print(confusion_matrix)输出将是:
[[2 2]
[1 3]]这意味着有 2 个真阳性、2 个假阳性、1 个假阴性和 3 个真阴性。
方差分析(ANOVA)分数用于确定两个或多个组的均值之间是否存在显著差异。它衡量组之间的方差量与组内的方差量相比。在现实生活中,方差分析可用于确定不同工作类别之间的平均工资是否存在显着差异。
3.2 下面是用于执行方差分析的 Python 代码示例:
import pandas as pd
from scipy.stats import f_oneway
# Create data
data = {'job_category': ['Manager', 'Engineer', 'Technician', 'Clerk', 'Sales'],
'salary': [50000, 60000, 45000, 35000, 55000]}
# Convert data to dataframe
df = pd.DataFrame(data)
# Perform ANOVA analysis
f_statistic, p_value = f_oneway(df[df['job_category'] == 'Manager']['salary'],
df[df['job_category'] == 'Engineer']['salary'],
df[df['job_category'] == 'Technician']['salary'],
df[df['job_category'] == 'Clerk']['salary'],
df[df['job_category'] == 'Sales']['salary'])
print("F-Statistic:", f_statistic)
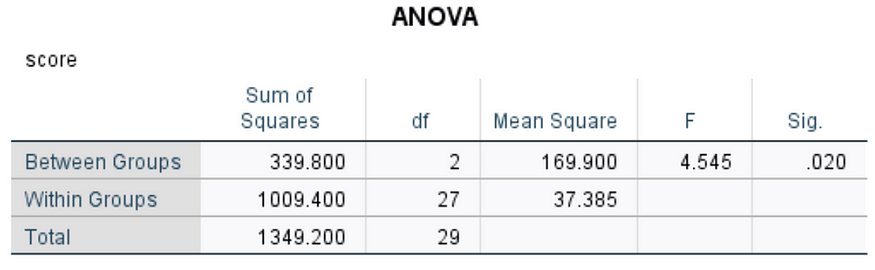
print("P-Value:", p_value)输出将是:
F-Statistic: 3.713874345549738
P-Value: 0.038005024491026634这意味着不同工作类别之间的平均工资存在显着差异。
输出与统计分析中的 F 检验及其关联的 p 值相关。
F 检验是比较两个或多个组或样本方差的统计检验。检验计算组间方差与组内方差的比率。F 统计量就是此比率,用于确定组的均值是否显著不同。
p 值是获得观测值 F 统计量或更极端值的概率的度量,假设原假设为真。换句话说,它告诉我们组之间的差异是由于偶然或随机变化的可能性。
在输出中,F 统计量值为 3.71,p 值为 0.038。这意味着组之间的差异在 0.05 的显著性水平上具有统计显著性(即,如果我们假设犯类型 I 错误的几率为 5%)。
简单来说,这意味着有证据表明被比较的组之间存在真正的差异,并且这种差异不太可能是由于偶然或随机变化造成的。
如果没有有关正在执行的统计分析的更多上下文,则很难提供更具体的信息或对这些结果的解释。
让我用一个简单的例子来解释 F 统计量和 p 值。
假设你有两组朋友,A组和B组,你想找出哪一组的平均身高更高。为此,您需要测量两组中每个人的身高并计算每组的平均身高。现在,您要检验两组之间的平均身高差异在统计意义上是否显著,或者仅仅是偶然性。
在这里,F 统计量是衡量两组在平均身高方面差异程度的指标。它告诉您差异是否大到足以被视为显著。另一方面,p 值是观察到的平均身高差异与您观察到的平均身高差异一样大的概率,假设两组之间没有真正的差异。换句话说,它告诉您观察到的差异只是由于偶然性的可能性有多大。
假设您计算的 F 统计量为 3.71,p 值为 0.038。这意味着两组之间的平均身高差异在统计意义上显著,因为 F 统计量大于 1,p 值小于 0.05(统计显著性的常用阈值)。换句话说,偶然观察到如此大的平均身高差异的概率仅为3.8%,低于5%的阈值。
在数据分析中,F 统计量和 p 值通常用于统计检验,例如 ANAVA(方差分析)以确定组之间是否存在显著差异。例如,在上面的示例中,您可以使用方差分析来检验 A 组和 B 组之间的平均身高差异是否显著。方差分析计算 F 统计量和 p 值,这有助于您得出有关两组之间差值的结论。
四、什么是交叉验证分数、ROC AUC 分数和 F1 分数?
4.1 交叉验证分数:
想象一下,你有很多不同的谜题,你想知道你有多擅长解决谜题。你可以尝试解决每个谜题一次,并计算你正确解决了多少个谜题,但这可能不会让你很好地了解你的整体情况。相反,您可以尝试解决一些难题,然后要求其他人解决相同的难题并比较您的结果。如果你们的分数相似,那么这可以让您更好地了解自己在解决难题方面的表现。在数据科学中,我们使用类似的想法,称为交叉验证。我们获取数据的子集,根据该数据训练模型,然后在另一个子集上对其进行测试。我们使用不同的子集多次执行此操作,并获取平均分数以更好地了解我们的模型的性能。
4.2 ROC AUC 分数:
ROC AUC 是一种衡量模型区分两类(如健康和患病患者)的能力的方法。想象一下,你是一名医生,你想知道测试能多好地检测某人是否生病。你可以给一群健康人和一群病人做测试,看看他们之间的区别有多大。如果测试良好,它将给病人打高分,给健康人打低分。ROC AUC 是衡量测试能做到这一点的程度的指标。
4.3 F1 比分:
想象一下,你是一名老师,你想根据学生在考试中的表现对他们进行评分。你可以根据他们答对了多少题给他们打分,但这并不能告诉你他们总体上做得有多好。例如,一个学生可能答对了大部分简单的问题,但错过了困难的问题,而另一个学生可能答对了一半的问题,但它们都是困难的问题。F1 分数是一种将精度和召回率结合起来的方法,以更好地了解模型的整体性能。精度度量预测的阳性数中有多少是实际正数,而召回率衡量实际阳性数中有多少被预测为正数。F1 分数是两种度量的组合,可以更好地了解模型的整体表现。
4.4 以下是使用 scikit-learn 库计算交叉验证分数、ROC AUC 分数和 F1 分数的 Python 代码:
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score, f1_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# Generate some example data
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# Initialize a Random Forest Classifier model
rfc = RandomForestClassifier(random_state=42)
# Calculate the Cross Validation Score
cv_score = cross_val_score(rfc, X, y, cv=5)
# Calculate the ROC AUC Score
y_pred_prob = rfc.predict_proba(X)[:, 1]
roc_auc = roc_auc_score(y, y_pred_prob)
# Calculate the F1 Score
y_pred = rfc.predict(X)
f1 = f1_score(y, y_pred)
# Print the results
print(f"Cross Validation Score: {cv_score}")
print(f"ROC AUC Score: {roc_auc}")
print(f"F1 Score: {f1}") 我们首先使用scikit-learn中的函数生成一些示例数据。然后,我们使用该类初始化随机森林分类器模型。make_classificationRandomForestClassifier
我们使用scikit-learn的函数计算交叉验证分数,该函数将模型,数据和交叉验证折叠的数量作为输入。我们设置执行 5 倍交叉验证。cross_val_scorecv=5
接下来,我们使用scikit-learn的函数计算ROC AUC分数,该函数将真实标签()和预测概率()作为输入。roc_auc_scoreyy_pred_prob
最后,我们使用scikit-learn的函数计算F1分数,该函数将真实标签()和预测标签()作为输入。f1_scoreyy_pred
我们使用函数将结果打印到控制台。print
















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











