









为什么选择 Hive?
- 基于Hadoop的大数据的计算/扩展能力
- 支持SQL like查询语言
- 统一的元数据管理
- 简单编程
Hive 是一种客户端工具,无所谓伪分布式/分布式;
对于开发人员,直接使用Java APIs可能是乏味或容易出错的,同时也限制了Java程序员在Hadoop上编程的运用灵活性。于是Hadoop提供了两个解决方案(Pig & Hive),使得Hadoop编程变得更加容易。
Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS(hive superimposes structure on data in HDFS),并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
Hive 基础
(1)在hadoop生态圈中属于数据仓库的角色。他能够管理hadoop中的数据,同时可以查询hadoop中的数据。
a) 所谓 hadoop 中的数据,是指存储在 hdfs 文件系统上的数据,MapReduce用于数据处理
b) hive 的最大优势便在于其对数据管理和数据查询功能的支持;
(2)本质上讲,hive是一个SQL解析引擎。Hive可以把SQL查询转换为MapReduce中的job来运行。
(3)hive有一套映射工具,可以把SQL转换为MapReduce中的job,可以把SQL中的表、字段转换为HDFS中的文件(夹)以及文件中的列。这套映射工具称之为metastore,一般存放在derby、mysql中。
- a) 表 ⇒ 文件(文件夹)
- b) 字段 ⇒ 文件中的列
Hive 的系统架构
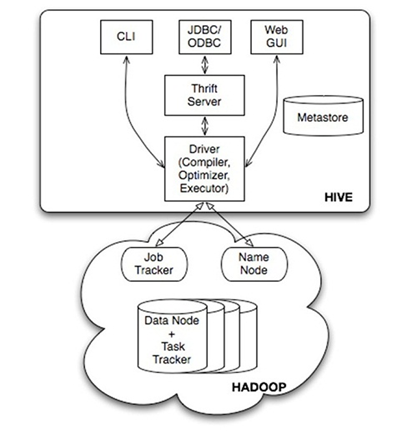
上图可知:
(1)是一个二层的分层结构:Hive 是建立在 Hadoop 上的数据仓库基础架构;
(2)Hive 提供了三个用户接口:
- a) CLI:command line interface,命令行接口,
- b) JOBC/ODBC:
- c) WebGUI:web 接口
(3)不同的接口在连接在(编译器、优化器、执行器)构成的驱动上,通过driver驱动,将三个接口得到的SQL语句转换为hadoop的mapreduce 执行,也即对hdfs 的操纵;
(4)驱动的转换工作需要 metastore 的参与,metastore是hive的转换工具嘛;
安装
(1)下载、解压缩、配置环境变量
(2) 修改配置文件
(1)重命名文件
mv hive-default.xml.default hive-site.xml
mv hive-env.sh.template hive-env.sh(2)修改 hadoop 的hadoop-env.sh(否则启动hive会报找不到类的错误)
export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:$HADOOP_HOME/bin(3)修改$HIVE_HOME/bin的 hive-config.sh,增加以下三行
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











