







相关信息
- 标题 FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
- 作者 Nvidia (Bowen Wen Wei Yang Jan Kautz Stan Birchfield)
- 主页 https://nvlabs.github.io/FoundationPose/
- 链接 https://arxiv.org/abs/2312.08344
- 代码 https://github.com/NVlabs/FoundationPose
简要介绍
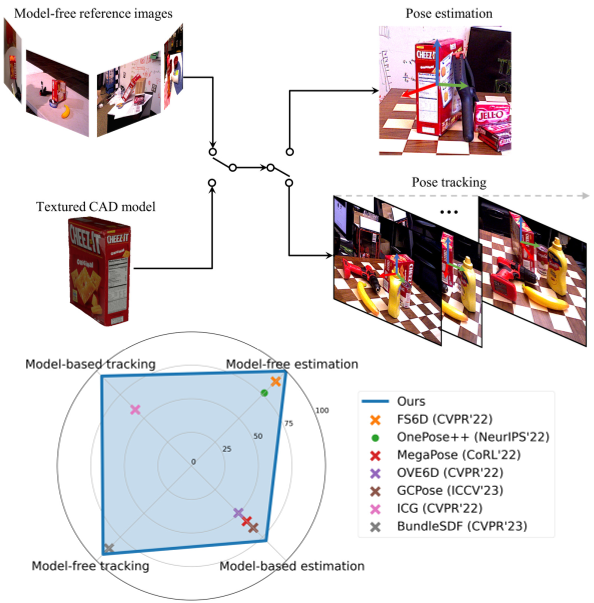
FoundationPose是一个统一的基础模型,用于6D对象姿态估计和跟踪,支持基于模型和无模型的设置。在测试时可以立即应用于未见过的新对象,无需微调,只要给出其CAD模型,或者捕获少量RGBD参考图像。
得益于统一框架,下游姿态估计模块在两种3D模型设置中都是相同的,当没有CAD模型时,使用神经隐式表示进行高效的新视角合成。通过大规模合成训练,辅以大型语言模型(LLM)、一种基于transformer的新架构和对比学习公式,实现了强大的泛化能力。
在多个公共数据集上的广泛评估,涉及具有挑战性的场景和对象,表明统一方法以大幅度超越了专为每个任务设计的现有方法,屠榜 BOP leaderboard 小半年。此外,尽管假设更少,它甚至实现了与实例级方法相当的结果。
代码复现
下载相关资产
- 下载仓库
# Download repo
git clone https://github.com/NVlabs/FoundationPose.git
- 下载权重
前往此处下载权重,放在weights/目录下。 - 下载测试数据
前往此处下载测试数据,解压到demo_data/目录下。 - 下载训练数据(可选)
如果要自己train的话,前往此处下载大规模训练数据 - 下载经过预处理的参考视图(可选)
如果要跑model-free的少样本学习版本, 前往此处下载,解压到demo_data/目录下。 - 下载YCB-Video数据集(可选)
如果需要YCB-Video数据集,这是一个200G+的数据集,BOP版做了筛选,在100G左右,前往此处下载,解压到demo_data/目录下。
具体的下载操作为:
# Download data
pip install -U "huggingface_hub[cli]"
export LOCAL_DIR=<your_path_to>/FoundationPose/demo_data/
export NAME=ycbv
cd <your_path_to>/FoundationPose/demo_data/ycbv
# Extract
# Specify the directory
directory="."
# Iterate through all zip files in the directory
for file in "$directory"/*.zip; do
# Check if the file exists
if [ -e "$file" ]; then
# Get the filename (without extension)
filename=$(basename "$file" .zip)
# Create a directory with the same name as the file
mkdir -p "$filename"
# Unzip the file into the newly created directory
unzip -q "$file" -d "$filename"
echo "Extracting $file to $filename"
fi
done
echo "Extraction complete"
环境配置
- 安装eigen 3.4.0到系统
cd $HOME && wget -q https://gitlab.com/libeigen/eigen/-/archive/3.4.0/eigen-3.4.0.tar.gz && \
tar -xzf eigen-3.4.0.tar.gz && \
cd eigen-3.4.0 && mkdir build && cd build
cmake .. -Wno-dev -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_FLAGS=-std=c++14 ..
sudo make install
cd $HOME && rm -rf eigen-3.4.0 eigen-3.4.0.tar.gz
- 创建Conda环境
# Create conda environment
conda create -n foundationpose python=3.9
- 安装依赖
# Activate conda environment
conda activate foundationpose
# Install dependencies
python -m pip install -r requirements.txt
# Install NVDiffRast
python -m pip install --quiet --no-cache-dir git+https://github.com/NVlabs/nvdiffrast.git
# Install Kaolin (Optional, needed if running model-free setup)
python -m pip install --quiet --no-cache-dir kaolin==0.15.0 -f https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-2.0.0_cu118.html
# Install PyTorch3D
python -m pip install --quiet --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py39_cu118_pyt200/download.html
# Build and install extensions in repo
CMAKE_PREFIX_PATH=$CONDA_PREFIX/lib/python3.9/site-packages/pybind11/share/cmake/pybind11 bash build_all_conda.sh
运行测试
basic demo
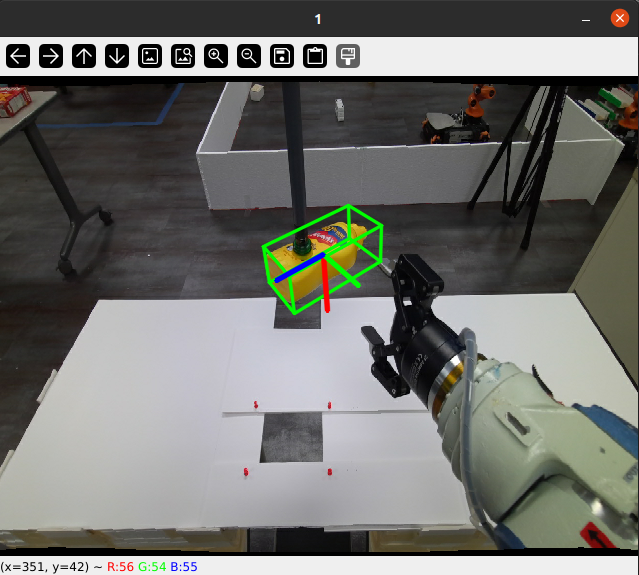
python run_demo.py
当各路径正确时,应当有如下画面显示:
ycbv demo
如果下载了BOP的YCB-Video数据集,可以试试泡一下ycbv的demo
注意:将以下代码的路径替换成到ycbv文件夹的路径
python run_ycb_video.py --ycbv_dir /home/hermanye20/Documents/FoundationPose/demo_data/ycbv/ycbv_test_bop19 --use_reconstructed_mesh 0
跑完后的最终结果在/FoundationPose/debug中可以看到。
注意: 如果缺失models,则复制 ycbv_models/models 到ycbv_test_bop19,将ycbv_models也复制到ycbv_test_bop19,否则路径不匹配
注意: 因为作者在datareader.py中直接读取大写字符串"BOP"作为判断条件,若名称不带,则读取目录下的keyframes.txt,需要采取以下措施。
注意: BOP所选图像是原始数据集中“YCB_Video_Dataset/image_sets/keyframe.txt”中列出的图像的子集,如果缺少keyframe.txt,则在YCBV原数据集下载YCB-Video-Base.zip,解压到demo_data/ycbv/ycbv_test_bop19,将image_sets/keyframe.txt放在demo_data/ycbv/ycbv_test_bop19目录下
model-free demo
要运行model-free的少样本版本,首先需要训练神经对象场。ref_view_dir 基于你在上面的 “数据准备” 部分下载的位置(此处为<your_foundationpose_dir>/demo_data/ref_views_16)。将数据集标志设置为你感兴趣的数据集(此处以ycbv为例)。
注意:请替换以下命令里的路径和数据集为你需要的。
python bundlesdf/run_nerf.py --ref_view_dir /home/hermanye20/Documents/FoundationPose/demo_data/ref_views_16 --dataset ycbv
这个脚本通过bundlesdf获取了物品的3D模型。

随后执行:
注意:将以下代码的路径替换成你的路径。
python run_ycb_video.py --ycbv_dir /home/hermanye20/Documents/FoundationPose/demo_data/ycbv/ycbv_test_bop19 --use_reconstructed_mesh 1 --ref_view_dir /home/hermanye20/Documents/FoundationPose/demo_data/ref_views_16
迁移应用
当需要在其他机器人项目中使用时,需要对示例代码进行一些修改,此处以realsense相机为例,通过物体的模型或重建得到的物体模型作为init时的输入参数,获取相机内参、色彩图像、深度图像、掩码图作为输入,输出绘制了物体位姿的视频流。
TODO: Before 2024-05-01
论文翻译
注意:以下论文翻译可能存在事实性错误,请谨慎甄别。
摘要 (Abstract)
我们提出了 FoundationPose,这是一个统一的基础模型,用于6D对象姿态估计和跟踪,支持基于模型和无模型的设置。我们的方法可以在测试时立即应用于新对象,无需微调,只要给出其CAD模型,或者捕获少量参考图像。得益于统一框架,下游姿态估计模块在两种设置中都是相同的,当没有CAD模型时,使用神经隐式表示进行高效的新视角合成。通过大规模合成训练,辅以大型语言模型(LLM)、一种基于变换器的新颖架构和对比学习公式,实现了强大的泛化能力。在多个公共数据集上的广泛评估,涉及具有挑战性的场景和对象,表明我们的统一方法以大幅度超越了专为每个任务设计的现有方法。此外,尽管假设减少,它甚至实现了与实例级方法相当的结果。项目页面:https://nvlabs.github.io/FoundationPose/
1. 引言 (1. Introduction)
计算从对象到相机的刚性6D变换,也称为对象姿态估计,对于各种应用至关重要,例如机器人操作[30, 69, 70]和混合现实[43]。经典方法[20, 21, 31, 50, 68]被称为实例级方法,因为它们只在训练时确定的特定对象实例上工作。这些方法通常需要一个带纹理的CAD模型来生成训练数据,并且它们不能在测试时应用于未见过的新对象。尽管类别级方法[5, 34, 60, 64, 75]消除了这些假设(实例级训练和CAD模型),但它们仅限于在它们上面训练的预定义类别中的对象。此外,获取类别级训练数据众所周知是困难的,部分原因是必须应用额外的姿态规范化和检查步骤[64]。为了解决这些限制,最近的一些努力集中在任意新对象的即时姿态估计问题上[19, 32, 40, 55, 58]。根据测试时可用的信息,考虑了两种不同的设置:基于模型的,其中提供对象的纹理化3D CAD模型;无模型的,其中提供一组对象的参考图像。尽管在这两种设置上都取得了很大进展,但仍需要一种单一方法以统一的方式解决这两种设置,因为不同的现实世界应用提供了不同类型的信息。与单帧对象姿态估计正交,姿态跟踪方法[8, 29, 36, 39, 56, 63, 67, 72]利用时间线索,使视频序列上的姿态估计更有效、平滑和准确。这些方法与它们在姿态估计中的对应方法有相似的问题,这取决于它们对对象知识的假设。在本文中,我们提出了一个名为FoundationPose的统一框架,用于新对象的姿态估计和跟踪,使用RGBD图像,在基于模型和无模型的设置中。如图1所示,我们的方法在这两种设置中的四个任务上都超越了专门为这些任务设计的最新技术方法。我们的强泛化能力是通过大规模合成训练实现的,辅以大型语言模型(LLM),以及一种基于变换器的新颖架构和对比学习。我们使用面向对象的神经隐式表示来有效地进行新视角合成,用少量(约16张)参考图像桥接了基于模型和无模型的设置之间的差距,实现了比以前的渲染和比较方法[32, 36, 67]更快的渲染速度。我们的贡献可以总结如下:
- 我们提出了一个统一的框架,用于新对象的姿态估计和跟踪,支持基于模型和无模型的设置。一个面向对象的神经隐式表示,用于有效的新视角合成,桥接了两种设置之间的差距。
- 我们提出了一个LLM辅助的合成数据生成管道,通过多样化的纹理增强扩展了3D训练资产的多样性。
- 我们新颖的基于变换器的网络架构设计和对比学习公式,在仅使用合成数据训练时,导致了强大的泛化能力。
- 我们的方法在多个公共数据集上大幅度超越了专为每个任务设计的方法。尽管假设减少,它甚至实现了与实例级方法相当的结果。我们将发布在这项工作中开发的代码和数据。
2. 相关工作 (2. Related Work)
基于CAD模型的对象姿态估计。实例级姿态估计方法[20, 21, 31, 50]假设给定对象的带纹理CAD模型。在完全相同的实例上进行训练和测试。对象姿态通常是通过直接回归[37, 73]解决的,或者通过构建2D-3D对应关系然后PnP[50, 61],或者3D-3D对应关系然后最小二乘拟合[20, 21]。为了放宽对对象知识的假设,类别级方法[5, 34, 60, 64, 75, 77]可以应用于同一类别的新对象实例,但它们不能推广到预定义类别之外的任意新对象。为了解决这个限制,最近的努力[32, 55]旨在只要在测试时提供CAD模型,就对任意新对象进行即时姿态估计。少样本无模型对象姿态估计。无模型方法去除了对显式纹理模型的需求。相反,提供了一组捕获目标对象的参考图像[19, 22, 51, 58]。RLLG[3]和NeRF-Pose[35]提出了不需要对象CAD模型的实例级训练。特别是,[35]构建了一个神经辐射场,以提供对对象坐标图和掩码的半监督。不同地,我们引入了建立在SDF表示之上的神经对象场,以实现高效的RGB和深度渲染,从而桥接了基于模型和无模型场景之间的差距。此外,我们还专注于在这项工作中对新对象进行泛化姿态估计,这与[3, 35]的情况不同。为了处理新对象,Gen6D[40]设计了一个检测、检索和细化管道。然而,为了避免与分布外测试集的困难,它需要微调。OnePose[58]及其扩展OnePose++[19]利用结构从运动(SfM)进行对象建模,并预训练2D-3D匹配网络以解决对应关系的姿态。FS6D[22]采用了类似的方案,专注于RGBD模式。然而,当应用于无纹理对象或在严重遮挡下时,依赖于对应关系变得脆弱。对象姿态跟踪。6D对象姿态跟踪的目标是利用时间线索,使视频序列上的姿态预测更加高效、平滑和准确。通过神经渲染,我们的方法可以轻易地扩展到姿态跟踪任务,并具有高效率。类似于单帧姿态估计,现有的跟踪方法可以根据它们对对象知识的假设分为它们的对应类别。这些包括实例级方法[8, 11, 36, 67],类别级方法[39, 63],基于模型的新对象跟踪[29, 56, 72]和无模型的新对象跟踪[66, 71]。在基于模型和无模型的设置下,我们在公共数据集上都设定了新的基准记录,甚至超越了需要实例级训练的最新技术方法[8, 36, 67]。
3. 方法 (3. Approach)
我们的系统整体如图2所示,展示了各个组件之间的关系,以下小节将进行描述。
3.1. 大规模语言辅助数据生成
为了实现强大的泛化能力,训练需要大量多样化的对象和场景。在现实世界中获取这样的数据,并注释准确的地面真实6D姿态,是时间和成本禁止的。另一方面,合成数据通常缺乏3D资产的规模和多样性。我们开发了一个新的合成数据生成管道,用于训练,由最近的新兴资源和技术提供支持:大规模3D模型数据库[6, 10],大型语言模型(LLM)和扩散模型[4, 24, 53]。这种方法与以前的工作[22, 26, 32]相比,大幅扩展了数据的数量和多样性。
3D资产。我们从最近的大规模3D数据库中获取训练资产,包括Objaverse[6]和GSO[10]。对于Objaverse[6],我们选择了ObjaverseLVIS子集中的对象,该子集包含超过40K个属于1156个LVIS[13]类别的对象。该列表包含最相关的日常生活对象,具有合理的质量、形状和外观的多样性。它还为每个对象提供了一个标签,描述其类别,这有利于自动语言提示的生成,如下一步骤中的LLM辅助纹理增强。
LLM辅助纹理增强。虽然大多数Objaverse对象具有高质量的形状,但其纹理保真度变化显著。FS6D[22]提出了通过随机粘贴ImageNet[7]或MS-COCO[38]中的图像来增强对象纹理的方法。然而,由于随机UV映射,这种方法产生了接缝等伪影(见图3顶部);将整体场景图像应用于对象导致不真实的结果。相比之下,我们探索了如何利用最近的大语言模型和扩散模型的进步,实现更现实(和完全自动化)的纹理增强。具体来说,我们提供了一个文本提示、一个对象形状和一个随机初始化的嘈杂纹理给TexFusion[4],以产生增强的纹理模型。当然,如果我们要增强大量多样化风格的对象,手动提供这样的提示是不可行的。因此,我们引入了一个两级层次化的提示策略。如图2左上角所示,我们首先提示ChatGPT,询问它描述一个对象可能的外观;这个提示是模板化的,这样每次我们只需要替换与对象配对的标签,这是由Objaverse-LVIS列表给出的。然后,ChatGPT的回答成为提供给扩散模型进行纹理合成的文本提示。
数据生成。我们的合成数据生成是在NVIDIA Isaac Sim中实现的,利用路径追踪实现高保真照片级真实感渲染。我们执行重力和物理模拟以产生物理上合理的场景。在每个场景中,我们随机采样对象,包括原始和纹理增强版本的对象。对象的大小、材料、相机姿态和照明也是随机的;更多细节可以在附录中找到。
3.2. 神经对象建模 (3.2. Neural Object Modeling)
对于无模型设置,当3D CAD模型不可用时,一个关键挑战是表示对象以有效地渲染图像,以便为下游模块提供足够的质量。神经隐式表示对于新视角合成和在GPU上并行化都很有效,因此在渲染多个姿态假设时提供了高计算效率,如文中图2所示。为此,我们引入了一个以对象为中心的神经场表示法来建模对象,受到之前工作的启发[45, 65, 71, 74]。场表示法。我们通过两个函数[74]来表示对象,如图2所示。首先,几何函数Ω:x → s将输入的3D点x ∈ R^3输出为带符号的距离值s ∈ R。其次,外观函数Φ:(fΩ(x), n, d) → c将中间特征向量fΩ(x)从几何网络、点法线n ∈ R^3和视图方向d ∈ R^3作为输入,并输出颜色c ∈ R^3+。在实践中,我们在将x传递给网络之前应用多分辨率哈希编码[45]。n和d都由一组固定的二阶球谐系数嵌入。隐式对象表面通过取带符号距离场(SDF)的零水平集获得:S = {x ∈ R^3 | Ω(x) = 0}。与NeRF[44]相比,SDF表示Ω提供了更高的深度渲染质量,同时消除了手动选择密度阈值的需要。场学习。对于纹理学习,我们遵循在截断近表面区域上的体积渲染[71]:
[ c® = \int_{z®+0.5λ}^{z®−λ} w(xi) Φ(fΩ(xi), n(xi), d(xi)) dt, ]
[ w(xi) = \frac{1}{1 + e^{-αΩ(xi)}}, ]
其中w(xi)是依赖于点到隐式对象表面的带符号距离Ω(xi)的钟形概率密度函数,α调整分布的软度。概率在表面交点处达到峰值。在方程(1)中,z®是从深度图像的射线的深度值,λ是截断距离。我们忽略来自距离表面超过λ的空空间的贡献,以更有效地训练,并只集成到0.5λ的穿透距离,以模拟自遮挡[65]。在训练期间,我们将这个量与参考RGB图像进行比较,进行颜色监督:
[ L_c = \frac{1}{|R|} \sum_{r \in R} |c® - \bar{c}®|^2, ]
其中( \bar{c}® )表示射线r穿过的像素处的真实颜色。
对于几何学习,我们采用了混合SDF模型[71],通过将空间划分为两个区域来学习SDF,从而得到空空间损失和近表面损失。我们还对近表面SDF应用了eikonal正则化[12]:
[ L_e = \frac{1}{|X_e|} \sum_{x \in X_e} |\Ω(x) - λ|, ]
[ L_s = \frac{1}{|X_s|} \sum_{x \in X_s} (Ω(x) + dx - d_D)^2, ]
[ L_{eik} = \frac{1}{|X_s|} \sum_{x \in X_s} (|∇Ω(x)|^2 - 1)^2, ]
其中x表示沿射线采样的3D点;dx和dD分别是从射线原点到样本点和观察到的深度点的距离。我们不使用不确定的自由空间损失[71],因为模板图像在无模型设置中是预先捕获的。总训练损失是:
[ L = w_c L_c + w_e L_e + w_s L_s + w_{eik} L_{eik}. ]
学习针对每个对象进行优化,无需先验知识,可以在几秒钟内高效完成。神经场只需要为新对象训练一次。
渲染。一旦训练完成,神经场可以作为传统图形管道的替代品,用于高效渲染对象,以便进行后续的渲染和比较迭代。除了原始NeRF[44]中的颜色渲染外,我们还需要深度渲染,以便于基于RGBD的姿态估计和跟踪。为此,我们执行Marching Cubes[41]从SDF的零水平集中提取带纹理的网格,结合颜色投影。这只需要为每个对象执行一次。在推理中,给定一个对象姿态,我们按照光栅化过程渲染RGBD图像。或者,我们可以直接使用球体追踪[14]在线渲染深度图像;然而,我们发现这在效率上较差,特别是当需要并行渲染大量姿态假设时。
3.3. 姿态假设生成 (3.3. Pose Hypothesis Generation)
姿态初始化。给定RGBD图像,使用现成的方法(例如Mask RCNN[18]或CNOS[47])检测对象。我们使用位于检测到的2D边界框内中位深度的3D点来初始化平移。为了初始化旋转,我们从以对象为中心、相机面向中心的icosphere上均匀采样Ns个视点。这些相机姿态进一步通过Ni个离散的平面内旋转增强,得到Ns·Ni个全局姿态初始化,作为输入发送给姿态细化器。
姿态细化。由于前一步中的粗略姿态初始化通常相当嘈杂,因此需要一个细化模块来提高姿态质量。具体来说,我们构建了一个姿态细化网络,它接受基于粗略姿态的条件渲染的对象,以及从相机裁剪的输入观察窗口;网络输出一个姿态更新,以提高姿态质量。与MegaPose[32]不同,后者通过在粗略姿态周围渲染多个视图来找到锚点,我们观察到渲染与粗略姿态对应的单个视图就足够了。对于输入观察,我们不是根据2D检测进行裁剪,这是恒定的,我们执行基于姿态的裁剪策略,以便为平移更新提供反馈。具体来说,我们将对象原点投影到图像空间以确定裁剪中心。然后,我们将略微放大的对象直径(对象表面上任意两点之间最大距离)投影以确定裁剪大小,该裁剪大小包含对象及其周围的上下文。因此,这个裁剪是基于粗略姿态的,并鼓励网络更新平移,使裁剪更好地与观察对齐。细化过程可以通过将最新更新的姿态作为输入到下一次推断中重复多次,从而逐步提高姿态质量。
细化网络架构如图2所示;详细信息在附录中。我们首先使用单个共享CNN编码器从两个RGBD输入分支提取特征图。将特征图连接起来,送入具有残差连接的CNN块[17],并通过对补丁[9]进行分割和位置嵌入进行标记化。最后,网络预测平移更新Δt ∈ R^3和旋转更新ΔR ∈ SO(3),每个都由变换器编码器[62]单独处理,并通过线性投影到输出维度。更具体地说,Δt表示对象在相机框架中的平移偏移,ΔR表示在相机框架中表示的对象的方向更新。在实践中,旋转采用轴角表示法。我们还尝试了6D表示法[78],取得了相似的结果。输入的粗略姿态[R | t] ∈ SE(3)随后更新为:
[ t^+ = t + \Delta t ]
[ R^+ = \Delta R \otimes R, ]
其中⊗表示在SO(3)上的更新。与使用单一的齐次姿态更新不同,这种解耦表示法消除了在应用平移更新时更新方向的依赖性。这统一了两者的更新和输入观察,使学习过程简化。网络训练由L2损失监督:
[ L_{refine} = w_1 |\Delta t - \bar{\Delta t}|^2 + w_2 |\Delta R - \bar{\Delta R}|^2, ]
其中¯t和¯R是真实值;w1和w2是平衡损失的权重,经验设置为1。
3.4. 姿态选择 (3.4. Pose Selection)
给定一系列细化的姿态假设,我们使用一个层次化的姿态排名网络来计算它们的分数。得分最高的姿态被选为最终估计。层次化比较。网络使用两级比较策略。首先,对于每个姿态假设,渲染的图像与裁剪的输入观察进行比较,使用在第3.3节中引入的姿态条件裁剪操作。这个比较(图2左下角)是使用姿态排名编码器进行的,利用与细化网络相同的主干架构进行特征提取。提取的特征被连接、标记化,并送入多头自注意力模块,以便更好地利用全局图像上下文进行比较。姿态排名编码器执行平均池化,输出一个特征嵌入F ∈ R^512,描述渲染和观察之间的对齐质量(图2中下中间)。此时,我们可以像通常做的那样将F投影到相似性标量[2, 32, 46]。然而,这将忽略其他姿态假设,迫使网络输出一个绝对的分数分配,这可能很难学习。为了利用所有姿态假设的全局上下文以做出更明智的决策,我们引入了所有K个姿态假设之间的第二级比较。多头自注意力在连接的特征嵌入F = [F0, …, FK−1]^⊤ ∈ R^(K×512)上执行,它编码了所有姿态的姿态对齐信息。通过将F视为序列,这种方法自然地推广到变化的K长度[62]。我们不对F应用位置编码,以便对排列不变。然后,被注意的特征被线性投影到分数S ∈ R^K上,分配给姿态假设。这种层次化比较策略的有效性在图4中的一个典型示例中显示。对比验证。为了训练姿态排名网络,我们提出了一个姿态条件的三重损失:
[ L(i^+, i^-) = \max(S(i^-) - S(i^+) + α, 0), ]
其中α表示对比边界;i-和i+分别表示负姿态样本和正姿态样本,通过使用真实地面真相计算ADD指标[73]来确定。请注意,与标准三重损失[27]不同,我们的情况下锚点样本在正样本和负样本之间不是共享的,因为输入是根据每个姿态假设进行裁剪的,以考虑平移。虽然我们可以在列表中的每对之间计算这个损失,但当两个姿态都远离真实情况时,比较变得模糊。因此,我们只保留正样本来自足够接近真实情况的视点的样本对,以使比较有意义:
[ V^+ = {i : D(R_i, \bar{R}) < d} ]
[ V^- = {0, 1, 2, …, K - 1} ]
[ L_{rank} = \sum_{i^+ \in V^+, i^- \in V^-} L(i^+, i^-) ]
其中求和是在i^+ ∈ V+,i- ∈ V-,i+ = i^-上进行的;R_i和( \bar{R} )分别是假设和真实的姿态;D(·)表示旋转之间的测地距离;d是预定义的阈值。我们还尝试了InfoNCE损失[49],如[46]中所用,但观察到性能更差(第4.5节)。我们认为这是因为[46]中做出的完美平移假设在我们的设置中并非如此。
4. 实验 (4. Experiments)
4.1. 数据集和设置
我们考虑了5个数据集:LINEMOD[23]、OccludedLINEMOD[1]、YCB-Video[73]、T-LESS[25]和YCBInEOAT[67]。这些涉及各种具有挑战性的场景(密集杂乱、多实例、静态或动态场景、桌面或机器人操作)和具有不同属性的对象(无纹理、闪亮、对称、大小不一)。由于我们的框架是统一的,我们考虑了两种设置(无模型和基于模型)和两个姿态预测任务(6D姿态估计和跟踪)的组合,总共有4个任务。对于无模型设置,从数据集的训练分割中选择了一些参考图像,这些图像捕捉了新对象,并配备了对象姿态的真实注释,遵循[22]。对于基于模型的设置,为新对象提供了CAD模型。除了消融研究外,在所有评估中,我们的方法总是使用相同的训练模型和配置进行推理,而不需要对目标数据集进行微调。
4.2. 指标
为了密切遵循每个设置的基线协议,我们考虑以下指标:
- ADD和ADD-S的曲线下面积(AUC)[73]。
- 如[19, 22]中使用的,对象直径小于0.1的ADD的召回率(ADD-0.1d)。
- BOP挑战赛中引入的VSD、MSSD和MSPD指标的平均召回率(AR)[26]。
4.3. 姿态估计比较
无模型。表1展示了我们在YCB-Video数据集上与最先进的RGBD方法[22, 28, 57]的比较结果。基线结果采用自[22]。遵循[22],所有方法都给出了被扰动的真实边界框作为2D检测,以进行公平比较。表2展示了在LINEMOD数据集上的比较结果。基线结果采用自[19, 22]。基于RGB的方法[19, 40, 58]被赋予了更多的参考图像,以补偿缺乏深度的信息。在RGBD方法中,FS6D[22]需要在目标数据集上进行微调。我们的方法在两个数据集上的性能显著优于现有方法,无需对目标数据集进行微调或ICP细化。图5可视化了定性比较。我们无法获得FS6D[22]的姿态预测进行定性结果,因为它的代码没有公开发布。严重自我遮挡和胶水缺乏纹理大大挑战了OnePose++[19]和LatentFusion[51],而我们的方法成功估计了姿态。
方法 未见数据集 平均对象 LM-O T-LESS YCB-V
SurfEmb[15] + ICP ✗ 75.8 82.8 80.6 79.7
OSOP[55] + ICP ✓ 48.2 57.2 (PPF, Sift) + Zephyr[48] ✓ 59.8 51.6
MegaPose-RGBD[32] ✓ 58.3 54.3 63.3 58.6
OVE6D[2] ✓ 49.6 52.3
GCPose[76] ✓ 65.2 67.9
Ours ✓ 78.8 83.0 88.0 83.3
表3展示了在BOP的3个核心数据集上,RGBD方法之间的比较结果:Occluded-LINEMOD[1]、YCB-Video[73]和TLESS[25]。所有方法都使用Mask R-CNN[18]进行2D检测。我们的方法在处理新对象方面大幅度超越了现有的基于模型的方法,以及实例级方法[15]。
4.4. 姿态跟踪比较
表4展示了在YCBInEOAT[67]数据集上,RGBD方法在模型基础上的姿态跟踪结果,通过ADD和ADD-S的AUC进行测量。除非另有说明,在跟踪丢失的情况下,对评估方法不应用重新初始化,以评估长期跟踪的鲁棒性。我们推迟到补充材料中展示定性结果。为了全面比较突然的平面外旋转、动态外部遮挡和解耦的相机运动的挑战,我们在YCBInEOAT[67]数据集上评估了姿态跟踪方法,该数据集包括动态机器人操作的视频。在基于模型的设置下,我们的方法实现了最佳性能,甚至超越了具有真实姿态初始化的实例级训练方法[67]。此外,我们的统一框架还允许端到端的姿态估计和跟踪,而不需要外部姿态初始化,这是唯一具有此能力的方法,在表中标记为Ours†。表5展示了在YCB-Video[73]数据集上的姿态跟踪比较结果。在基线中,DeepIM[36]、se(3)-TrackNet[67]和PoseRBPF[8]需要在同一对象实例上进行训练,而Wüthrich等人[72]、RGF[29]、ICG[56]和我们的方法可以在提供CAD模型时立即应用于新对象。
4.5. 分析
消融研究。表6展示了关键设计选择的消融研究。结果通过在YCB-Video数据集上测量ADD和ADD-S指标的AUC进行评估。Ours (proposed)是在无模型(16个参考图像)设置下的默认版本。W/o LLM texture augmentation去除了合成训练中的LLM辅助纹理增强。在W/o transformer中,我们将基于变换器的架构替换为卷积和线性层,同时保持相似数量的参数。W/o hierarchical comparison仅使用姿态条件的三重损失(方程11)训练,而不进行两级层次化比较。在测试时,它独立地将每个姿态假设与输入观察进行比较,并输出得分最高的姿态。图4展示了定性结果的例子。Ours-InfoNCE将对比验证的成对损失(方程14)替换为[46]中使用的InfoNCE损失。参考图像数量的影响。我们研究了参考图像数量对在YCB-Video数据集上通过ADD和ADD-S指标的AUC测量的结果的影响,如图6所示。总体而言,我们的方法对参考图像数量特别在ADD-S指标上具有鲁棒性,并且在两个指标上在12张图像时饱和。值得注意的是,即使只提供4张参考图像,我们的方法仍然比配备了16张参考图像的FS6D[22]具有更强的性能(见表1)。训练数据规模法则。理论上,可以为训练产生无限数量的合成数据。图7展示了训练数据量对在YCB-Video数据集上通过ADD和ADD-S指标的AUC测量的结果的影响。增益在大约1M时饱和。运行时间。我们在Intel i9-10980XE CPU和NVIDIA RTX 3090 GPU硬件上测量运行时间。姿态估计大约需要1.3秒来处理一个对象,其中姿态初始化需要4毫秒,细化需要0.88秒,姿态选择需要0.42秒。跟踪运行得更快,大约为32 Hz,因为只需要姿态细化,而且没有多个姿态假设。在实践中,我们可以运行一次姿态估计进行初始化,然后切换到跟踪模式以实现实时性能。
5. 结论
我们提出了一个用于新对象的6D姿态估计和跟踪的统一基础模型,支持基于模型和无模型的设置。在4种不同任务的组合上的广泛实验表明,它不仅多功能,而且大幅度超越了专门为每个任务设计的现有最先进方法。它甚至实现了与需要实例级训练的方法相当的结果。在未来的工作中,探索超越单个刚性对象的状态估计将是有趣的。
文章作者: Herman Ye @Auromix
测试环境: Ubuntu20.04 AnaConda
更新日期: 2024/04/22
注1: @Auromix 是一个机器人方向爱好者组织。
注2: 由于笔者水平有限,本篇内容可能存在事实性错误。
注3: 本篇直接引用的其他来源图片/文字素材,版权为原作者所有。

















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









