







概念:
游戏中的batch数
在游戏开发中,“batch数”(Batch Count)通常指的是在一帧渲染过程中,GPU执行的渲染批次的数量。每个批次代表一组几何图形和材质属性,它们被一次性提交给GPU进行渲染。以下是对游戏中的batch数的详细解释:
一、批次的定义
-
基本概念:
- 批次是渲染管线中的一个基本单元,包含了一组具有相同材质和纹理的图形对象。
-
合并渲染:
- 通过将多个相似的对象合并到一个批次中进行渲染,可以减少CPU与GPU之间的通信开销。
二、批次的作用
-
性能优化:
- 减少渲染调用的次数,从而降低CPU的开销。
-
提高GPU利用率:
- 允许GPU更高效地执行渲染任务,充分利用其计算能力。
-
降低延迟:
- 快速处理多个对象有助于减少每帧的渲染时间,提高帧率。
三、影响batch数的因素
-
场景复杂度:
- 场景中包含的对象越多,需要的批次可能也越多。
-
对象的材质和纹理:
- 使用相同材质和纹理的对象可以被合并到一个批次中。
-
渲染顺序:
- 合理的渲染顺序有助于提高批次的合并效率。
-
游戏引擎优化:
- 不同的游戏引擎有不同的批处理策略和技术实现。
-
硬件性能:
- GPU的性能和内存带宽也会影响批次的处理能力。
四、监控和优化batch数
-
性能分析工具:
- 使用专门的性能分析工具(如Unity Profiler、Unreal Engine的Stat命令等)来监控每帧的batch数。
-
优化策略:
- 通过合并网格、减少材质变化、调整渲染顺序等方法来增加有效的batch数。
结语
在游戏中,合理控制和优化batch数是提升渲染性能的关键环节之一。开发者需要综合考虑场景需求、硬件限制以及引擎特性等因素,以实现最佳的视觉效果和流畅体验。
来自nvidia文章:
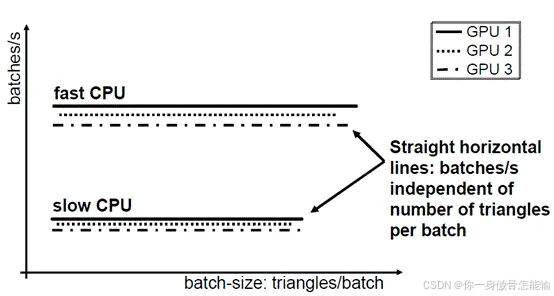
图中可见,每个drawcall提交多少个三角形,对cpu压力变化不大,但是每帧有多少个drawcall则影响很明显。
所以我们得出以下结论
每帧允许的batch数,由以下几个条件决定:
平台的cpu性能
希望达到的帧数
排除其他模块对cpu的消耗,一帧内能够有多少cpu时间用于提交batch。
如果每帧的batch数超过了允许值,必然会导致帧数下降
优化方法
很明显参考上面nvidia文章给出的图,我们应该选择一次drawcall提交越多的三角形,也就是这样我们就可以快速的将我们需要渲染的游戏物体提交过去,从而每秒的drawcall就高,也就是帧率越高。
即为了减少batch数,我们要想办法让不同的游戏物体能够尽量合在一起被渲染出来。
那么我们首先要保证渲染状态的一致性就可以进行合并了。
合并贴图和材质
如果不同的物体所用材质不同,自然要分开来渲染,那就不能合并了。如果美术输出2棵树,他们除了高度或者粗细不同,其他都是一样的,但形态不同,这里可以要求美术对他们使用同样的材质和贴图,这样就有了以下优化的可能性了。进行这一步骤需要让美术理解不同物体应该尽量复用同样的贴图和材质,能合并的尽可能合并。
Dynamic batching
在Unity3D中,Dynamic Batching(动态批处理)是一种优化技术,它可以将多个相似的渲染对象合并成一个批次进行渲染,从而减少CPU与GPU之间的通信开销,提高渲染性能。以下是Unity3D中实现Dynamic Batching的一些要求和条件:
一、基本要求
-
相同的材质:
- 所有参与动态批处理的对象必须使用相同的材质实例(Material Instance)。
-
顶点数限制:
- 每个批次的最大顶点数通常限制在900顶点以内(具体数值可能因Unity版本而异)。
-
索引数限制:
- 每个批次的最大索引数通常限制在2000索引以内。
-
变换矩阵:
- 对象的世界变换矩阵(World Matrix)需要在CPU端进行计算并传递给GPU。
二、几何形状和顶点属性
-
静态或动态对象:
- 动态批处理可以应用于静态(Static)或动态(Dynamic)对象,但动态对象有一些额外的限制。
-
顶点属性:
- 对象的顶点数据必须包含位置、法线、UV坐标等基本属性。
- 不支持复杂的顶点属性(如骨骼权重、切线空间等)。
为了能够利用这一特性,需要美术帮助控制模型的顶点数,对于简单小物件,远景上精度低的模型等等,是可以减面到要求范围以内的。
Static batching
在Unity3D中,Static Batching(静态批处理)是一种优化技术,用于将多个静态(不会移动或改变)的网格合并成一个批次进行渲染,从而减少CPU与GPU之间的通信开销,提高渲染性能。以下是关于Static Batching的详细解释和实现条件:
一、基本概念
-
静态对象:
- 静态批处理仅适用于标记为“Static”的游戏对象,这些对象在运行时不会移动或改变。
-
合并网格:
- Unity会将所有符合条件的静态网格合并成一个或多个大的网格,然后一次性提交给GPU渲染。
二、实现条件
-
标记为Static:
- 在Unity编辑器中,将不需要移动的对象或其父对象标记为“Static”(通过勾选“Static”复选框)。
-
相同的材质:
- 虽然静态批处理不要求所有对象使用完全相同的材质实例,但使用相同材质可以进一步优化性能。
-
顶点数和索引数限制:
- 合并后的网格仍然受到顶点数和索引数的限制,通常最大顶点数为65,536,最大索引数为49,152。
3. 光照和阴影
- 静态批处理支持静态光照烘焙(Baked Lighting),可以生成高质量的光照贴图。
- 静态对象可以投射和接收静态阴影。
三、优缺点
优点:
-
性能提升:
- 大幅度减少Draw Call(渲染调用),从而降低CPU的开销。
-
简化资源管理:
- 合并后的网格可以更高效地利用GPU资源。
-
高质量光照:
- 支持静态光照烘焙,提供更真实的光照效果。
缺点:
-
内存占用:
- 合并后的网格可能会占用更多的内存空间。
-
灵活性差:
- 静态对象无法移动或改变,适用于场景中固定的元素。
-
初始加载时间较长:
- 合并网格的过程可能会增加游戏的初始加载时间。
四、优化技巧
-
合理划分静态区域:
- 将场景划分为多个静态区域,避免一次性合并过大的网格。
-
使用LOD(细节层次):
- 对于远处的静态对象,可以使用较低细节层次的网格进行渲染。
Static batching是在什么阶段进行
Static Batching(静态批处理)在Unity3D中的执行过程可以分为以下几个阶段:
一、标记阶段
- 开发者操作:在Unity编辑器中,开发者需要手动将不需要移动或改变的游戏对象或其父对象标记为“Static”。这通常是通过选中对象并勾选Inspector面板中的“Static”复选框来完成的。
- 静态批处理设置:确保在Project Settings中的Graphics设置里启用了“Static Batching”。
二、构建阶段
- 场景烘焙:Unity在构建过程中会对标记为“Static”的对象进行光照烘焙(如果启用了光照烘焙),生成光照贴图。
- 网格合并:Unity会在后台自动合并符合条件的静态网格。这个过程发生在构建阶段,具体来说是在资源导入和场景准备阶段。
三、运行时阶段
- 渲染优化:在游戏运行时,Unity引擎会利用预先合并好的大网格进行渲染。由于这些网格已经合并,渲染调用(Draw Call)会大大减少,从而提高渲染性能。
- 静态光照应用:预先烘焙的光照贴图会在运行时应用到相应的静态对象上,提供高质量的光照效果。
详细流程
-
资源导入:
- Unity导入场景中的所有资源,包括网格、材质、纹理等。
- 对于标记为“Static”的网格,Unity会进行预处理,准备进行批处理。
-
场景准备:
- Unity分析场景中的所有对象,识别出标记为“Static”的对象。
- 这些对象会被分组并合并成大的网格。合并过程中会尽量减少材质切换,以提高批处理效率。
-
光照烘焙(可选):
- 如果启用了静态光照烘焙,Unity会在这一阶段生成光照贴图,并将其应用到相应的静态对象上。
-
运行时渲染:
- 在游戏运行时,Unity引擎会读取预先合并好的大网格,并进行渲染。
- 由于大部分渲染调用已经被合并成一个或少数几个批次,CPU的开销大大降低,GPU可以更高效地执行渲染任务。
结语
Static Batching的主要工作是在构建阶段完成的,开发者需要在编辑器中进行相应的设置和标记。运行时阶段则充分利用了构建阶段生成的优化结果,实现高效的渲染。通过这种方式,Static Batching显著提升了大型静态场景的渲染性能。
如果场景地形是动态生成的呢??
但是好在动态生成的树也同样是不要求移动的,因此我们可以在运行期进行动态Static batching。在生成场景的时候,可以将需要Static batching的物体放在一起,这里叫StaticRoot,等所有物体都生成好了,
调用unity3d的工具函数:
StaticBatchingUtility.Combine(StaticBatchingRoot);
这样就能在运行期实现动态Static batching。
改变场景设计
如何场景中存在小草是是透明,所以不能batching。如果场景里有很多这种透明草,会导致大量drawcall,可以和策划对齐后,对远处不明显的树,都可以去掉,或使用其他替代方法,只留下沙滩上最明显树。这种设计改变对效果影响不大,但非常有效的减少了batch,提升了性能。
经验总结
其他性能优化是一门团队协作的活,我们需要和部门其他合作互相配合。
程序员:找出性能瓶颈
修改自己解决的性能问题
如果涉及需要美术的地方就需要合理的沟通协作
美术:制作前尽量了解所需满足的规范,如材质如何合并,mesh顶点限制等。
性能优化开始后,合理安排好时间,配合参与性能优化。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











