







 本文深入探讨了基因本体论(GO)的概念和分类,包括细胞组分、分子功能和生物过程三个基本分类。通过实例展示了如何使用R语言的clusterProfiler等包进行基因功能注释和富集分析,以及如何绘制和解释GO富集结果的各种图形,如气泡图、柱状图和网络图。此外,还对比了GO与其他分类系统如COG和KEGG的区别。
本文深入探讨了基因本体论(GO)的概念和分类,包括细胞组分、分子功能和生物过程三个基本分类。通过实例展示了如何使用R语言的clusterProfiler等包进行基因功能注释和富集分析,以及如何绘制和解释GO富集结果的各种图形,如气泡图、柱状图和网络图。此外,还对比了GO与其他分类系统如COG和KEGG的区别。
全网最全 GO 注释结果绘图,直击 SCI 绘图标注,关注我,您最好的选择!
前言
1. GO 原理
基因组测序已经表明,大部分指定核心生物学功能的基因是所有真核生物共有的。这种共享蛋白质在一个有机体中的生物作用的知识,往往可以转移到其他有机体。基因本体论联盟的目标是产生一个动态的、可控的词汇表,可以应用于所有真核生物,即使基因和蛋白质在细胞中作用的知识正在积累和变化。为此,可以在全世界的Web上访问三种独立的本体。
我们在拿到一个非模式生物或者无参考基因组的项目的时候,经常需要进行基因的功能注释,才能够进行生物信息学的数据分析工作。虽然啊,序列相似的基因在不同物种中,其功能往往保守的,但是以前往往会存在不同的实验室对相同的基因的功能的描述因为我们的自然语言的模糊性而不尽相同的问题。显然,我们需要一个统一的术语用于描述这些跨物种的同源基因及其基因产物的功能,否则这种模糊性将会极大限制不同的科研人员间的学术的交流。
随着生物信息学数据的积累,出现了不同的应用于描述基因功能的分类数据库。这些分类系统的目标都是希望能够用于阐述这些跨物种的同源基因的生物学功能。但是因为分类系统之间的基因功能注释结果可能在自然语言描述上都不尽相同,存在都相互为各自的方言的情况,大部分分类结果都几乎无法在分类系统之间直译。Gene Ontology (GO) 项目正是为了能够使对各种数据库中基因获基因产物功能描述相一致的努力结果。
在GO分类系统中,有三大基础分类(官方的称呼为词条的命名空间):
-
细胞组分(cellular component):细胞的每个部分和细胞外环境。
-
分子功能(molecular function):可以描述为分子水平的活性(activity),如催化(catalytic)或结合(binding)活性。
-
生物过程(biological process):生物学过程系指由一个或多个分子功能有序组合而产生的系列事件。
与GO分类相似的,尝试进行阐明生物学功能的本质的还有比较早诞生的非常经典的NCBI的直系同源蛋白簇,即COG分类(COG还分为4大版本:原核细菌分支为COG,真核分支为KOG,古细菌分支为arCOG,噬菌体分支为POG)。COG分类系统中有下面的4大基础分类:
-
遗传信息存储以及遗传信息处理相关的(INFORMATION STORAGE AND PROCESSING)
-
胞内过程以及信号转导相关的(CELLULAR PROCESSES AND SIGNALING)
-
代谢相关的(METABOLISM)
-
难以分类的(POORLY CHARACTERIZED)
而另一个系统领域内非常重要的进行基因功能分类的KEGG直系同源相对于COG分类则是更加细分为7大基础功能分类:
-
代谢相关的(Metabolism)
-
遗传信息处理相关的(Genetic Information Processing)
-
环境信息处理相关的(Environmental Information Processing)
-
胞内生命过程相关的(Cellular Processes)
-
有机体生命系统组成相关的(Organismal Systems)
-
人类疾病相关的(Human Diseases)
-
无法进一步分类的(Not Included in Pathway or Brite)
基因本体单单从GO的全称Gene Ontology,GO注释系统是以阐述生物大分子的本质属性而建立的分类系统,在这里本质属性就是指的是生物学功能。GO分类使用4种元素来描述基因单元的本质信息:
-
概念(concepts):一个本质的概念就是我们对某一个基因其产物的功能注释结果的描述,在GO注释中,一个概念就是一个具体到某一个GO id编号的Term词条。
-
关系(relationship):在Go注释系统中,两个词条之间可以存在有is_a,part_of,has_part以及regulates这4种关系。如果将词条看作为一个节点,词条间的关系看作为两个节点之间的一条边连接的话,我们就可以在许多个节点的基础上构建出一个有向无环图,也可以看作为一个关系网络。
-
实例(instances):实例就是在生命活动中发挥具体的生物学功能的,具有GO注释信息的蛋白之类的实际存在的现实世界中的生物大分子物质了。在UniProt蛋白数据库中所有具有uniprot编号的蛋白序列都是一个GO注释的目标实例对象。
-
公理(axioms):公理推断规则是在GO注释系统中最重要的一个本质概念阐述过程的规则。公理指的是词条与词条之间的关系推断的规则,例如A is_a B,并且B is_a C,那么我们就可以推断出A is_a C,将A推断为C的一个过程中所使用的推断规则信息,就是一个公理。因为我们根据关系推断出A is_a C,所以C就是A的本质,同样的,C也是B的本质。
2. 实例解析
1. 数据读取
数据的读取我们仍然使用的是 TCGA-COAD 的数据集,表达数据的读取以及临床信息分组的获得我们上期已经提过,我们使用的是edgeR 软件包计算出来的差异表达结果,提取上调基因 2832 的 ENSEMBL 号,
###########基因列表
DEG=read.table("DEG-resdata.xls",sep="\t",check.names=F,header = T)
geneList<-DEG[DEG$sig=="Up",]$Row.names
table(DEG$sig)
##
## Down Up
## 1296 2832
读取样本分组信息,41个正常组织,478个癌症组织,如下:
######样本分组信息
group<-read.table("DEG-group.xls",sep="\t",check.names=F,header = T)
table(group$Group)
##
## NT TP
## 41 478
2. GO 注释结果
首先我们同样需要安装软件包并加载,这里面主程序就是 clusterProfiler 软件包,如下:
if(!require(clusterProfiler)){
BiocManager::install("clusterProfiler")
}
if(!require(org.Hs.eg.db)){
BiocManager::install("org.Hs.eg.db")
}
if(!require(DOSE)){
BiocManager::install("DOSE")
}
if(!require(topGO)){
BiocManager::install("topGO")
}
if(!require(pathview)){
BiocManager::install("pathview")
}
library(org.Hs.eg.db)
library(clusterProfiler)
library(DOSE)
library(topGO)
library(pathview)
根据数据比对我们找到1726 个GO数据中有的基因,同时我们获得到一个基因的三种命名方式,即"ENTREZID", “ENSEMBL”, ‘SYMBOL’,如下:
eg <- bitr(geneList,
fromType="ENSEMBL",
toType=c("ENTREZID","ENSEMBL",'SYMBOL'),
OrgDb="org.Hs.eg.db")
## 'select()' returned 1:many mapping between keys and columns
## Warning in bitr(geneList, fromType = "ENSEMBL", toType = c("ENTREZID",
## "ENSEMBL", : 39.51% of input gene IDs are fail to map...
dim(eg)
## [1] 1726 3
head(eg)
## ENSEMBL ENTREZID SYMBOL
## 1 ENSG00000062038 1001 CDH3
## 2 ENSG00000175832 2118 ETV4
## 3 ENSG00000167767 144501 KRT80
## 4 ENSG00000164283 11082 ESM1
## 5 ENSG00000120254 25902 MTHFD1L
## 6 ENSG00000129474 84962 AJUBA
对获得的基因进行GO注释,ont 参数有四种选择模式,ALL, MF, CC, BP,其中(MF, CC, BP)就是我们上面讲过的在GO分类系统中,有三大基础分类,而 ALL 就是对这三种分类同时注释,我们这里选择 “ALL”,阈值分别为 pvalueCutoff = 0.01 和 qvalueCutoff = 0.05, 注释的时候我们可以选择参数 keyType 中三种不同的基因名称,如下:
# Run GO enrichment analysis
go <- enrichGO(eg$SYMBOL,
OrgDb = org.Hs.eg.db,
ont='ALL',
keyType = "SYMBOL",
pAdjustMethod = 'BH',
pvalueCutoff = 0.01,
qvalueCutoff = 0.05,
#keyType = 'ENTREZID'
)
dim(go)
## [1] 232 10
看下最后的结果,并保持其结果,我们看到 BP, CC, MF 分别为193,10,29,如下:
head(go@result)
## ONTOLOGY ID
## GO:0007389 BP GO:0007389
## GO:0019730 BP GO:0019730
## GO:0061844 BP GO:0061844
## GO:0003002 BP GO:0003002
## GO:0048568 BP GO:0048568
## GO:0045165 BP GO:0045165
## Description
## GO:0007389 pattern specification process
## GO:0019730 antimicrobial humoral response
## GO:0061844 antimicrobial humoral immune response mediated by antimicrobial peptide
## GO:0003002 regionalization
## GO:0048568 embryonic organ development
## GO:0045165 cell fate commitment
## GeneRatio BgRatio pvalue p.adjust qvalue
## GO:0007389 64/927 436/18722 4.639425e-15 2.023253e-11 1.787888e-11
## GO:0019730 31/927 122/18722 2.490775e-14 5.431135e-11 4.799330e-11
## GO:0061844 24/927 79/18722 2.963461e-13 4.307885e-10 3.806748e-10
## GO:0003002 51/927 331/18722 4.507505e-13 4.914307e-10 4.342625e-10
## GO:0048568 57/927 427/18722 8.233615e-12 6.338388e-09 5.601042e-09
## GO:0045165 42/927 258/18722 8.720552e-12 6.338388e-09 5.601042e-09
## geneID
## GO:0007389 WNT2/SIM2/OTX1/MDFI/XRCC2/GRHL3/WNT3/MSX1/FEZF1/CFAP45/SHH/WNT7B/LEF1/NKD1/AXIN2/GBX2/TDGF1/SIX1/STC1/WT1/DNAH5/HOXB8/RIPPLY3/BMP7/CITED1/FOLR1/DMRTA2/TDGF1P3/DMRT3/WNT8B/IRX3/SP8/RIPPLY1/HES7/WNT11/SOX1/ROBO2/DLL3/FGF8/DKK1/FOXD1/SIX2/EYA1/GSC/LRP2/TBX20/NODAL/NKX2-1/SIX3/GATA4/PAX2/WNT3A/FEZF2/LHX1/IRX2/NKX2-5/EN1/LHX3/TBX5/WNT7A/NTF4/FOXG1/TBR1/IRX4
## GO:0019730 KLK7/CXCL3/CXCL1/SLC11A1/CXCL2/PGC/CXCL8/CXCL5/PPBP/WFDC10A/F2/WFDC10B/CXCL6/KRT6A/CXCL11/PGLYRP3/H2BC10/H2BC6/PRSS2/H2BC7/S100A7/IL36RN/FGB/PGLYRP4/IL17A/H2BC11/SEMG1/KLK5/SEMG2/REG3A/IL17F
## GO:0061844 KLK7/CXCL3/CXCL1/CXCL2/PGC/CXCL8/CXCL5/PPBP/F2/CXCL6/KRT6A/CXCL11/PGLYRP3/H2BC10/H2BC6/H2BC7/S100A7/PGLYRP4/IL17A/H2BC11/SEMG1/KLK5/REG3A/IL17F
## GO:0003002 WNT2/OTX1/MDFI/XRCC2/WNT3/MSX1/FEZF1/SHH/WNT7B/LEF1/NKD1/AXIN2/GBX2/TDGF1/SIX1/WT1/HOXB8/DMRTA2/TDGF1P3/DMRT3/WNT8B/IRX3/SP8/RIPPLY1/HES7/WNT11/SOX1/ROBO2/DLL3/FGF8/DKK1/FOXD1/SIX2/GSC/LRP2/TBX20/NODAL/NKX2-1/SIX3/GATA4/PAX2/WNT3A/FEZF2/LHX1/IRX2/EN1/LHX3/WNT7A/NTF4/FOXG1/TBR1
## GO:0048568 MTHFD1L/WNT2/OTX1/MDFI/TEAD4/COL11A1/CTHRC1/STRA6/GRHL3/MSX1/ASCL2/IRX5/APELA/SHH/WNT7B/MFAP2/LEF1/GBX2/TFAP2A/SIX1/TBX15/PTK7/HOXB8/BMP7/EN2/CXCL8/SIX4/CSF2/CITED1/FOLR1/GJB5/TH/IGF2/MYCN/WNT11/DLX6/FGF8/ATP6V1B1/SIX2/EYA1/GSC/TBX4/TBX20/NODAL/SHOX2/SIX3/DLX5/GATA4/GJB6/GCM1/PAX2/WNT3A/LHX1/HPN/NKX2-5/EN1/FOXG1
## GO:0045165 WNT2/EPOP/WNT3/SHH/WNT7B/IL23A/SIX1/WT1/TBX15/ONECUT2/DMRTA2/DMRT3/WNT8B/POU3F2/WNT11/SOX1/FGF8/DKK1/POU4F1/SIX2/EYA1/GSC/TBX4/TBX20/NODAL/PTF1A/NKX2-1/GATA4/GCM1/PAX2/WNT3A/GSX1/FEZF2/POU6F2/TLX3/LHX3/TBX5/WNT7A/NTF4/FOXG1/TBR1/NKX6-3
## Count
## GO:0007389 64
## GO:0019730 31
## GO:0061844 24
## GO:0003002 51
## GO:0048568 57
## GO:0045165 42
table(go@result$ONTOLOGY)
##
## BP CC MF
## 193 10 29
3. 结果展示
针对 GO 注释结果我们这里给出了多种展示方式,根据自己的需求以及文章的设计,选择适合自己的即可。
library(stringr)
library(cowplot)
library(ggplot2)
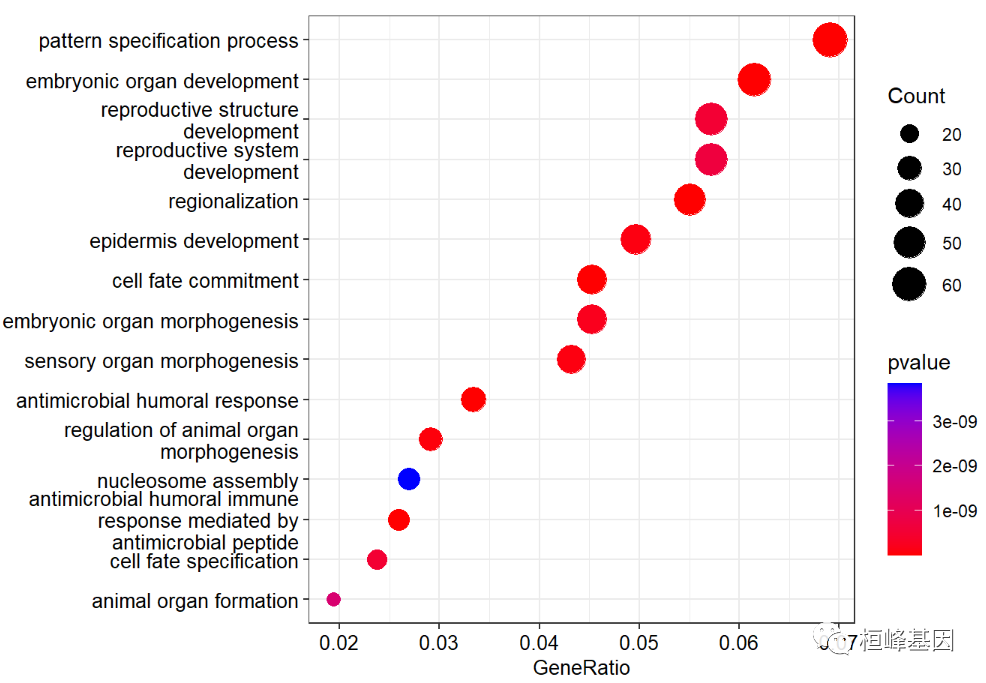
绘制气泡图,气泡图解读需要说明一下,GO富集程度通过Gene ratio、Pvalue和富集到此GO term上的基因个数来衡量。
-
横坐标是Gene ratio,数值越大表示富集程度越大。Count 位于该GO term下的差异表达基因数
-
纵坐标是富集程度较高的GO term(一般选取富集最显著的20条进行展示,不足20条则全部列出)。
-
Pvalue取值范围[0, 1],以颜色表示,越红表示Pvalue越小,说明富集越明显。
-
点的大小表示该term下差异基因的个数,点越大表示基因数越多。
dotplot(go,
showCategory=15,
font.size=10,
color ="pvalue")
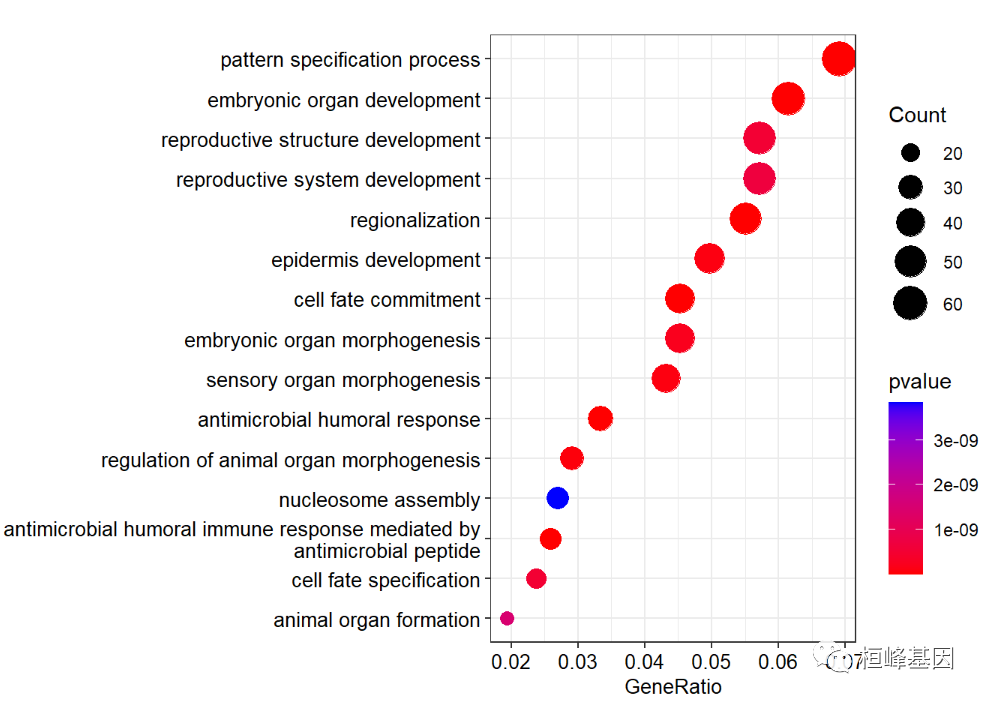
由于 GO的 描述字体重合,故我们利用scale_y_discrete设置,避免字体彼此重合,如下:
dotplot(go,
showCategory=15,
font.size=10,
color ="pvalue")+
scale_y_discrete(labels=function(x) stringr::str_wrap(x, width=60))
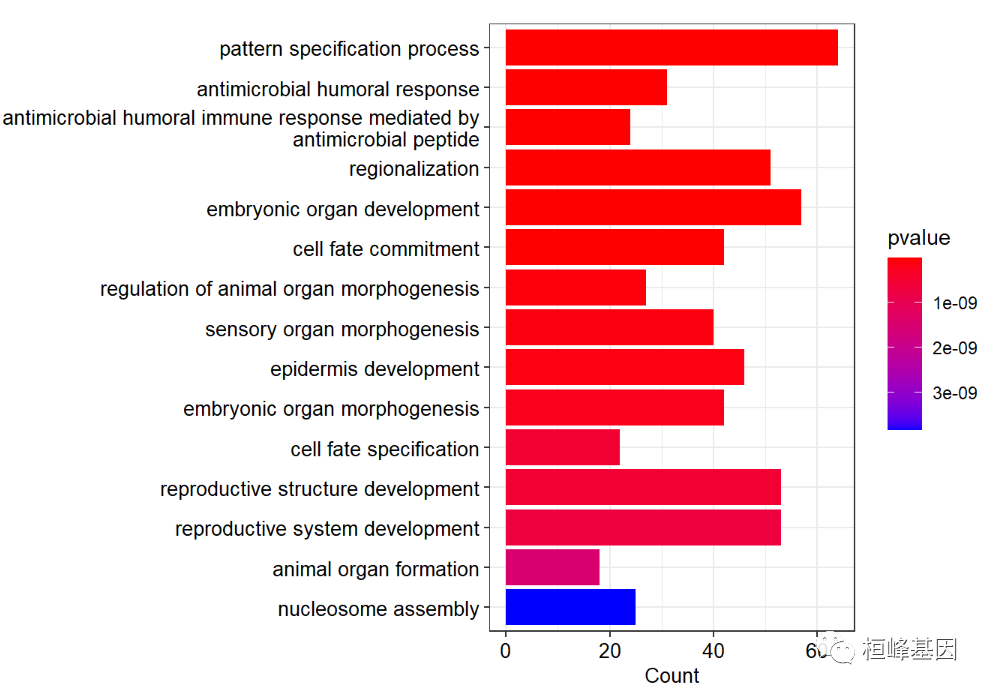
绘制柱状图,如下:
barplot(go,
showCategory=15,
font.size=10,
color ="pvalue")+
scale_y_discrete(labels=function(x) stringr::str_wrap(x, width=60))
## Scale for 'y' is already present. Adding another scale for 'y', which
## will replace the existing scale.
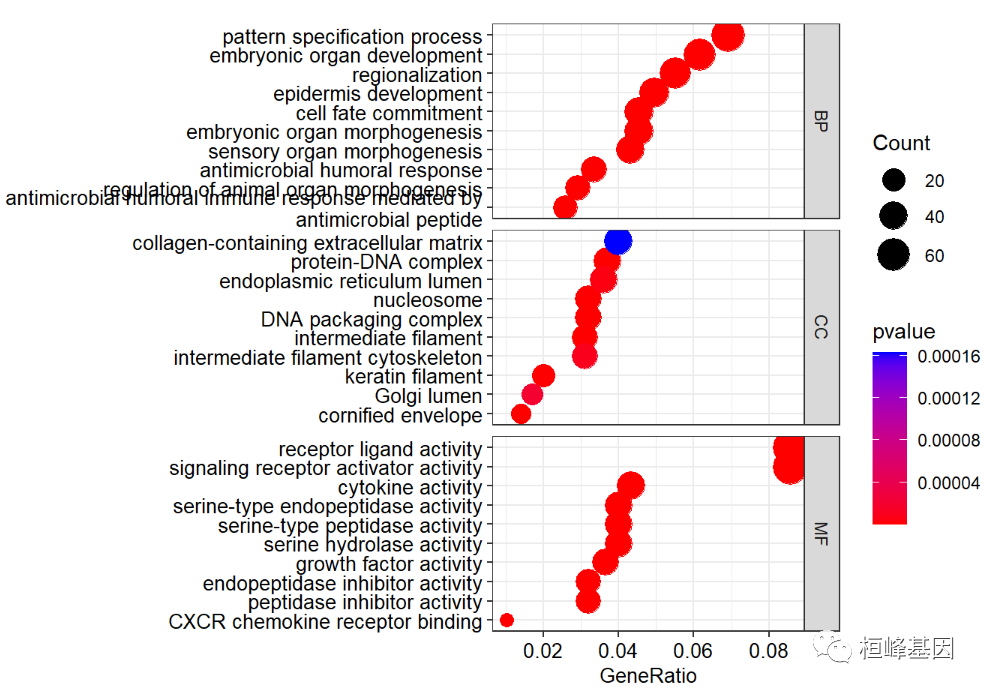
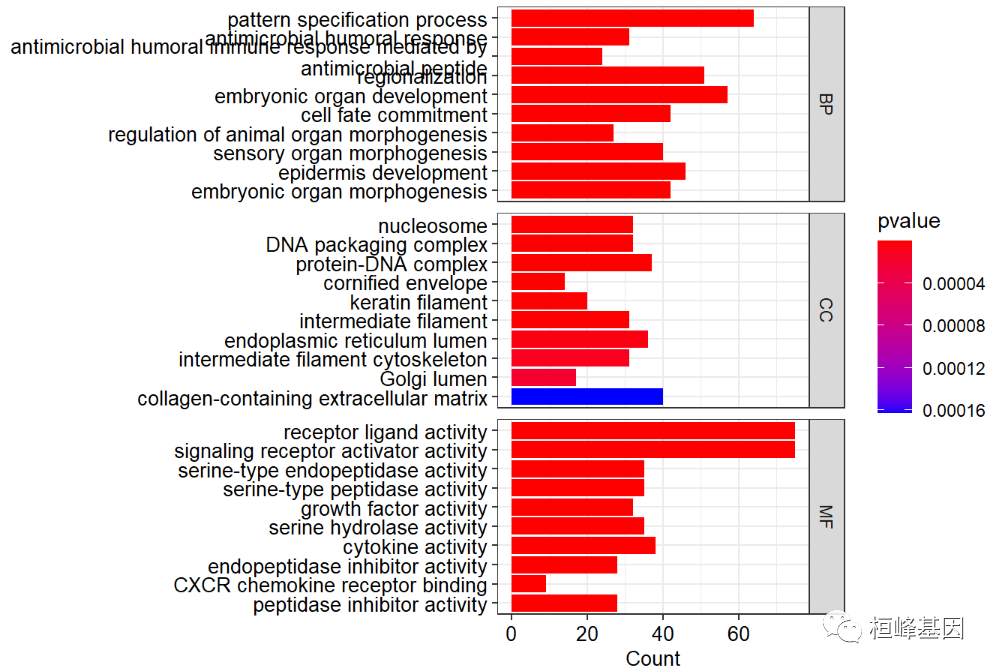
我们可以利用 split=“ONTOLOGY” 方式,将三种生物学分类分开绘制到一张图上,如下:
dotplot(go,showCategory=10,
font.size=10,
split="ONTOLOGY",
color ="pvalue")+
facet_grid(ONTOLOGY~.,scale="free")+
scale_y_discrete(labels=function(x) str_wrap(x, width=60))
## Scale for 'y' is already present. Adding another scale for 'y', which
## will replace the existing scale.
我们可以利用 split=“ONTOLOGY” 方式,将三种生物学分类分开绘制到一张图上,如下:
barplot(go,showCategory=10,
font.size=10,
split="ONTOLOGY",
color ="pvalue")+
facet_grid(ONTOLOGY~.,scale="free")+
scale_y_discrete(labels=function(x) str_wrap(x, width=60))
## Scale for 'y' is already present. Adding another scale for 'y', which
## will replace the existing scale.
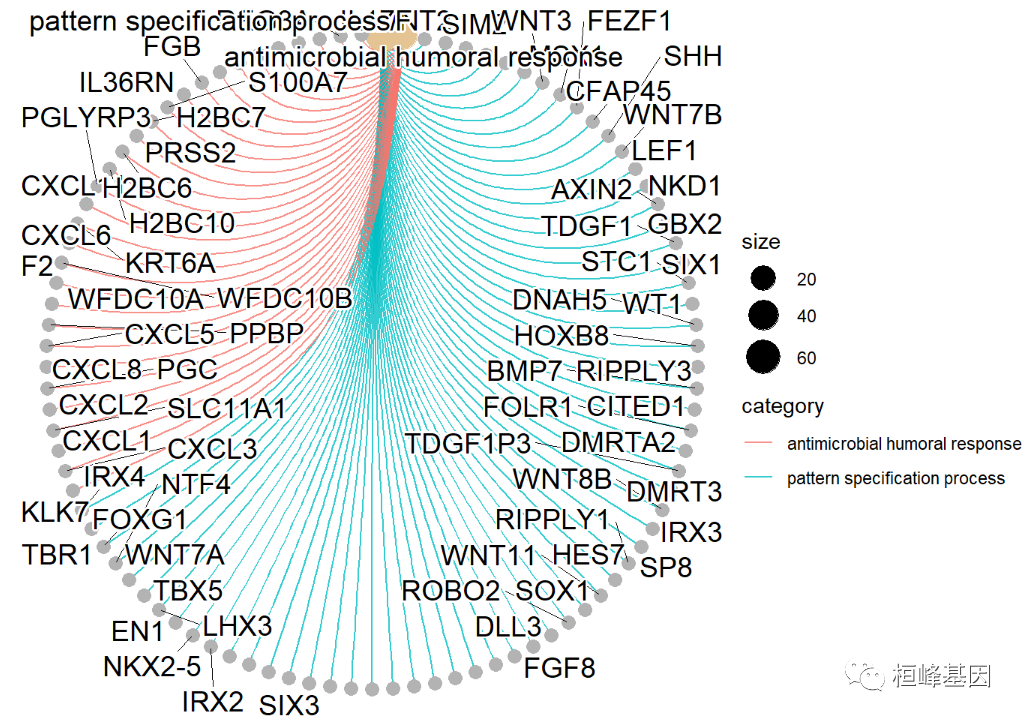
绘制基因概念的网络图,GO term与差异基因关系网络图 Gene-Concept Network,对于基因和富集的GO terms之间的对应关系进行展示说明:图中灰色的点代表基因,黄色的点代表富集到的GO terms;如果一个基因位于一个GO Terms下,则将该基因与GO连线;黄色节点的大小对应富集到的基因个数,top2富集到的GO terms,如下:
cnetplot(go,showCategory=2,circular=TRUE,colorEdge=TRUE)
## Warning: ggrepel: 14 unlabeled data points (too many overlaps). Consider
## increasing max.overlaps
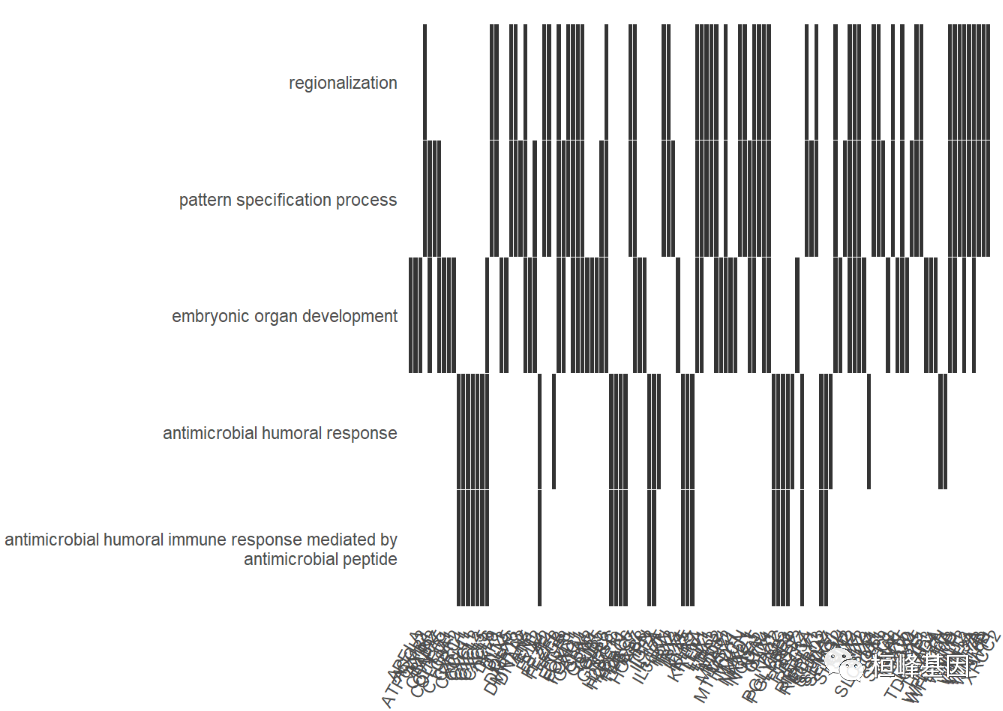
热图可以看到哪些基因富集到哪些 GO term,如下:
heatplot(go,showCategory=5)+
scale_y_discrete(labels=function(x) stringr::str_wrap(x, width=60))
## Scale for 'y' is already present. Adding another scale for 'y', which
## will replace the existing scale.
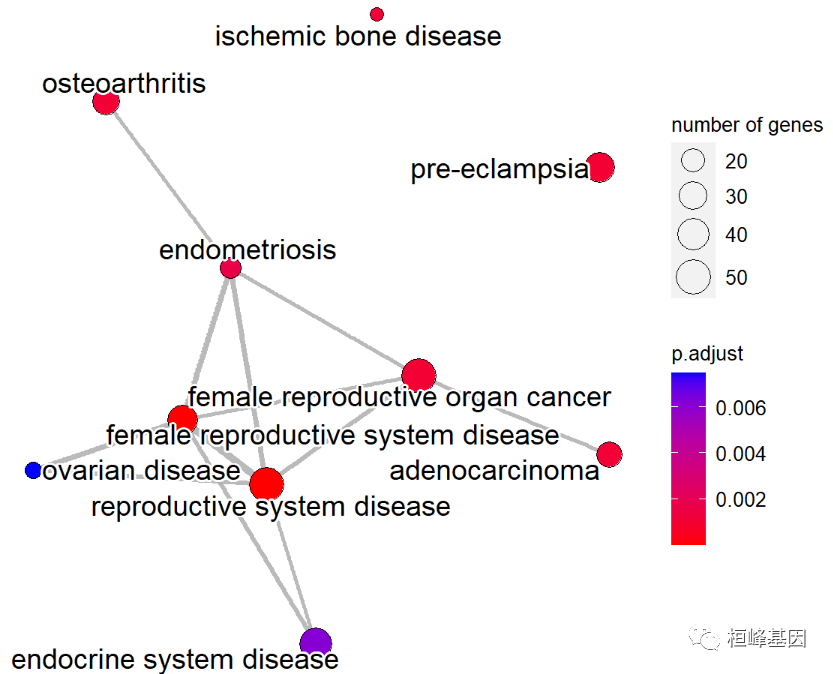
软件安装并加载,如下:
if(!require(ggnewscale)){
install.packages("ggnewscale")
}
library(enrichplot)
library(ggnewscale)
可以选择更加漂亮的网络图,如下:
ed = enrichDO(eg$ENTREZID, pvalueCutoff=0.05)
met <- pairwise_termsim(ed)
emapplot(met,showCategory = 10)
我们再看 GO term的树形图的几种画法,首先我们现在 BP 类型进行 GO 注释,如下:
###########BP分类展示
BP <- enrichGO(eg$SYMBOL,
OrgDb = org.Hs.eg.db,
ont='BP',
keyType = "SYMBOL",
pAdjustMethod = 'BH',
pvalueCutoff = 0.01,
qvalueCutoff = 0.05,
#keyType = 'ENTREZID'
)
dim(BP)
## [1] 193 9
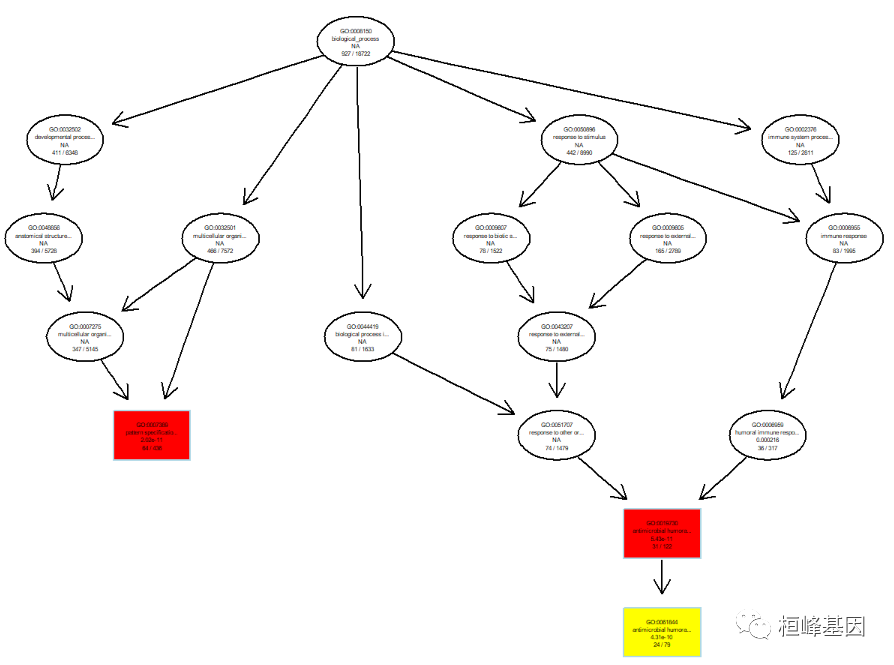
有向无环图 GO DAG graph,调用 topGO 软件包,我们发现,这个图上的字体非常小,后期需要我们自己进行修改,如下:
plotGOgraph(BP, sigForAll =FALSE,firstSigNodes = 3)
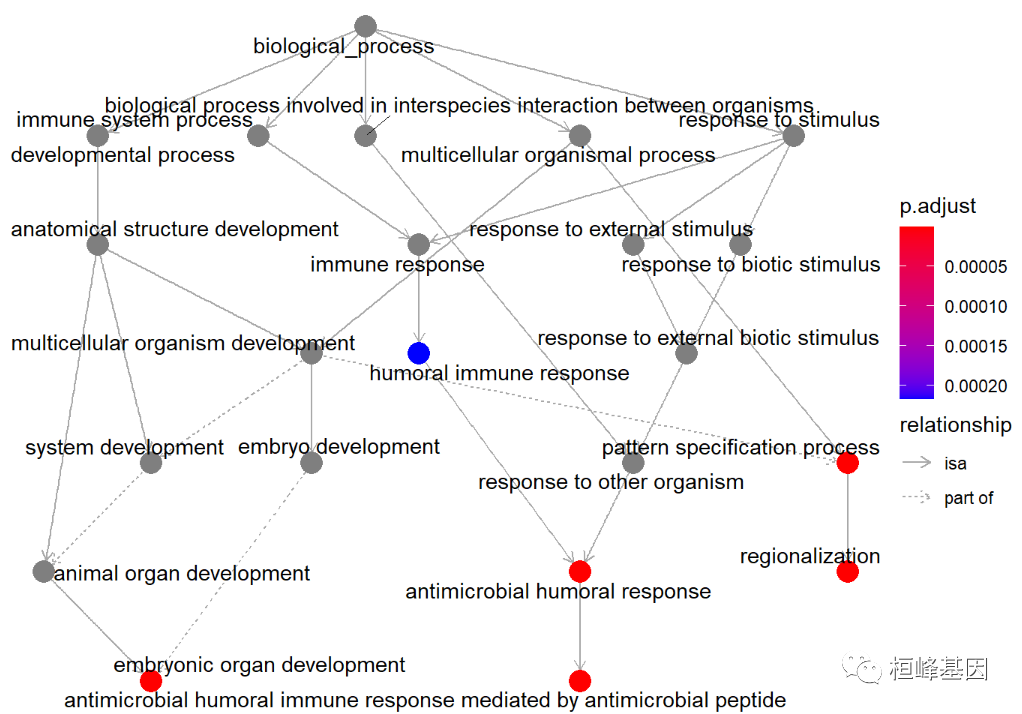
利用 enrichPlot 软件包来作图,如下:
goplot(BP, showCategory = 5)
GO 注释结果的展示形式多样,个人感觉总结的已经非常全面了,若有考虑不到的,大家指出,我来修改,基于自己的文章选好模式既可。
关注公众号,每日更新,扫码进群交流不停歇,马上就出视频版,关注我,您最佳的选择!

桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
46篇原创内容
公众号
References:
-
Ashburner M, Ball CA, Blake JA, et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet. 2000;25(1):25-29.
-
Yu G, Wang L, Han Y and He Q*. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS: A Journal of Integrative Biology. 2012, 16(5):284-287.

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









