







 本文介绍了天鹰优化算法的设计灵感来源于天鹰的捕食行为,详细阐述了其包含的4种搜索策略:扩展探索、缩小探索、扩大开发和缩小开发阶段。通过数学模型模拟不同阶段的动态调整,旨在提供一种高效的问题求解方法。
本文介绍了天鹰优化算法的设计灵感来源于天鹰的捕食行为,详细阐述了其包含的4种搜索策略:扩展探索、缩小探索、扩大开发和缩小开发阶段。通过数学模型模拟不同阶段的动态调整,旨在提供一种高效的问题求解方法。

1.背景
2021年,L Abualigah等人受到天鹰猎食过程启发,提出了天鹰优化算法(Aquila Optimizer,AO)。
2.算法原理
2.1算法思想
AO模拟天鹰 4 种不同的捕食策略建立数学模型,根据搜索空间内解的不同特性,灵活应用不同的搜索策略。
2.2算法过程
扩展探索阶段:
在第 1 个阶段,天鹰通过垂直俯身的高空翱翔搜索猎物并选择搜索区域:
X
1
(
t
+
1
)
=
X
b
e
s
t
(
t
)
×
(
1
−
t
T
)
+
(
X
M
(
t
)
−
X
b
e
s
t
(
t
)
×
r
a
n
d
)
.
X
M
(
t
)
=
1
N
∑
i
=
1
N
X
i
(
t
)
.
(1)
X_{1}\left(t+1\right)=X_{\mathrm{best}}\left(t\right)\times\left(1-\frac{t}{T}\right)+\left(X_{\mathrm{M}}\left(t\right)-X_{\mathrm{best}}\left(t\right)\times\mathrm{rand}\right).\\\\X_{\mathrm{M}}\left(t\right)=\frac{1}{N}\sum_{i=1}^{N}X_{i}\left(t\right).\tag{1}
X1(t+1)=Xbest(t)×(1−Tt)+(XM(t)−Xbest(t)×rand).XM(t)=N1i=1∑NXi(t).(1)
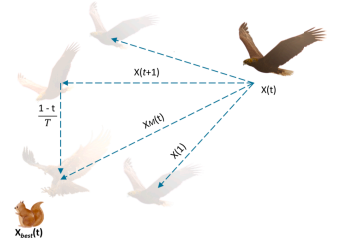
缩小探索阶段:
模拟天鹰短滑翔攻击行为:
X
2
(
t
+
1
)
=
X
b
e
s
t
(
t
)
×
L
e
v
y
(
D
)
+
X
R
(
t
)
+
(
y
−
x
)
×
r
a
n
d
×
1.
(2)
X_{2}\left(t+1\right)=X_{\mathrm{best}}\left(t\right)\times\mathrm{Levy}\left(D\right)+X_{\mathrm{R}}\left(t\right)+\left(y-x\right)\times\mathrm{rand}\times1.\tag{2}
X2(t+1)=Xbest(t)×Levy(D)+XR(t)+(y−x)×rand×1.(2)
x,y代表螺旋飞行:
y
=
r
c
o
s
(
θ
)
x
=
r
s
i
n
(
θ
)
r
=
r
1
+
U
D
1
θ
=
−
ω
D
1
+
3
π
/
2
(3)
y = rcos(\theta)\\x=rsin(\theta) \\ r = r1+UD_1\\ \theta = -\omega D_1+3\pi/2\tag{3}
y=rcos(θ)x=rsin(θ)r=r1+UD1θ=−ωD1+3π/2(3)
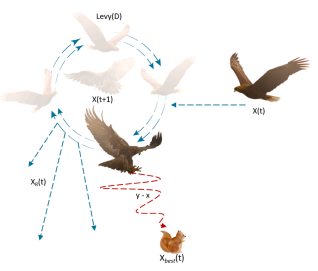
扩大开发阶段:
模拟天鹰的低空慢降攻击:
X
3
(
t
+
1
)
=
α
(
X
b
e
s
t
(
t
)
−
X
M
(
t
)
)
−
r
a
n
d
×
1
+
δ
(
(
U
−
L
)
×
r
a
n
d
+
L
)
×
1.
(4)
\begin{gathered} \boldsymbol{X}_{3}(t+1) =\alpha\left(\boldsymbol{X}_{\mathrm{best}}\left(t\right)-\boldsymbol{X}_{\mathrm{M}}\left(t\right)\right)-\mathrm{rand}\times\mathbf{1}+ \delta((U-L)\times\mathrm{rand}+L)\times\mathbf{1}. \end{gathered}\tag{4}
X3(t+1)=α(Xbest(t)−XM(t))−rand×1+δ((U−L)×rand+L)×1.(4)
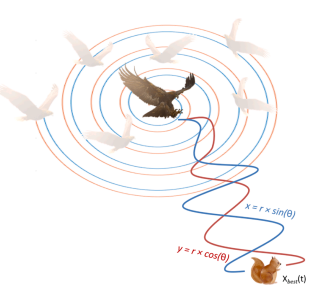
缩小开发阶段:
模拟天鹰行走及狩猎地面上移速较慢的生物:
X
4
(
t
+
1
)
=
Q
F
×
X
b
e
s
t
(
t
)
−
G
1
×
X
ˉ
(
t
)
×
r
a
n
d
−
G
2
×
L
e
v
y
(
D
)
×
1
+
r
a
n
d
×
G
1
×
1.
(5)
\begin{array}{c}{X_{4}\left(t+1\right)=Q_{\mathrm{F}}\times X_{\mathrm{best}}\left(t\right)-G_{1}\times\bar{X}\left(t\right)\times\mathrm{rand}-}{G_{2}\times\mathrm{Levy}\left(D\right)\times\mathbf{1}+\mathrm{rand}\times G_{1}\times\mathbf{1}.}\\\end{array}\tag{5}
X4(t+1)=QF×Xbest(t)−G1×Xˉ(t)×rand−G2×Levy(D)×1+rand×G1×1.(5)
其中,参数表述为:
Q
F
(
t
)
=
t
(
2
×
m
n
d
−
1
)
/
(
1
−
T
)
2
.
G
1
=
2
×
r
a
n
d
=
1.
G
2
=
2
×
(
1
−
t
/
T
)
.
(6)
Q_{\mathrm{F}}(t)=t^{(2\times\mathrm{mnd}-1)/(1-T)^{2}}.\\ G_{1}=2\times\mathrm{rand}=1.\\ G_{2}=2\times(1-t/T).\tag{6}
QF(t)=t(2×mnd−1)/(1−T)2.G1=2×rand=1.G2=2×(1−t/T).(6)
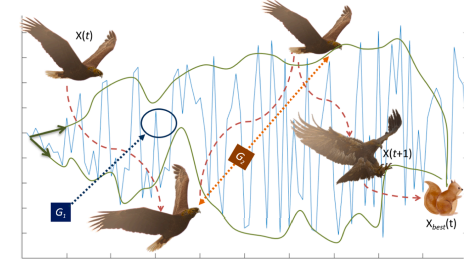
伪代码:

3.结果展示
4.参考文献
[1] Abualigah L, Yousri D, Abd Elaziz M, et al. Aquila optimizer: a novel meta-heuristic optimization algorithm[J]. Computers & Industrial Engineering, 2021, 157: 107250.


















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











